本文主要是介绍Delta lake with Java--将数据保存到Minio,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天看了之前发的文章,居然有1条评论,看到我写的东西还是有点用。
今天要解决的问题是如何将 Delta产生的数据保存到Minio里面。
1、安装Minio,去官网下载最新版本的Minio,进入下载目录,运行如下命令,曾经尝试过用docker来安装,不过数据无法保存成功。
minio.exe server D:\bigdata\miniodata --console-address ":9001",运行结果如下图:
2、登录Minio,建立用来存放数据的桶,记得要设为public访问
3、修改pom.xml增加hadoop-aws依赖,这里要注意版本号,不知道如何确定版本号,去spark下载目录里面的jar目录,找hadoop-client-api-***.jar,其中***就是版本号了
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>detla-lake-with-java</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.13</artifactId><version>3.5.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.13</artifactId><version>3.5.1</version></dependency><dependency><groupId>io.delta</groupId><artifactId>delta-spark_2.13</artifactId><version>3.1.0</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.15.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-aws</artifactId><version>3.3.4</version></dependency></dependencies></project>4、新建一个类,命名为DeltaLakeOnMinio,具体代码如下,注意:
config("spark.hadoop.fs.s3a.fast.upload.buffer", "bytebuffer")这一行一定要添加,否则会报错
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
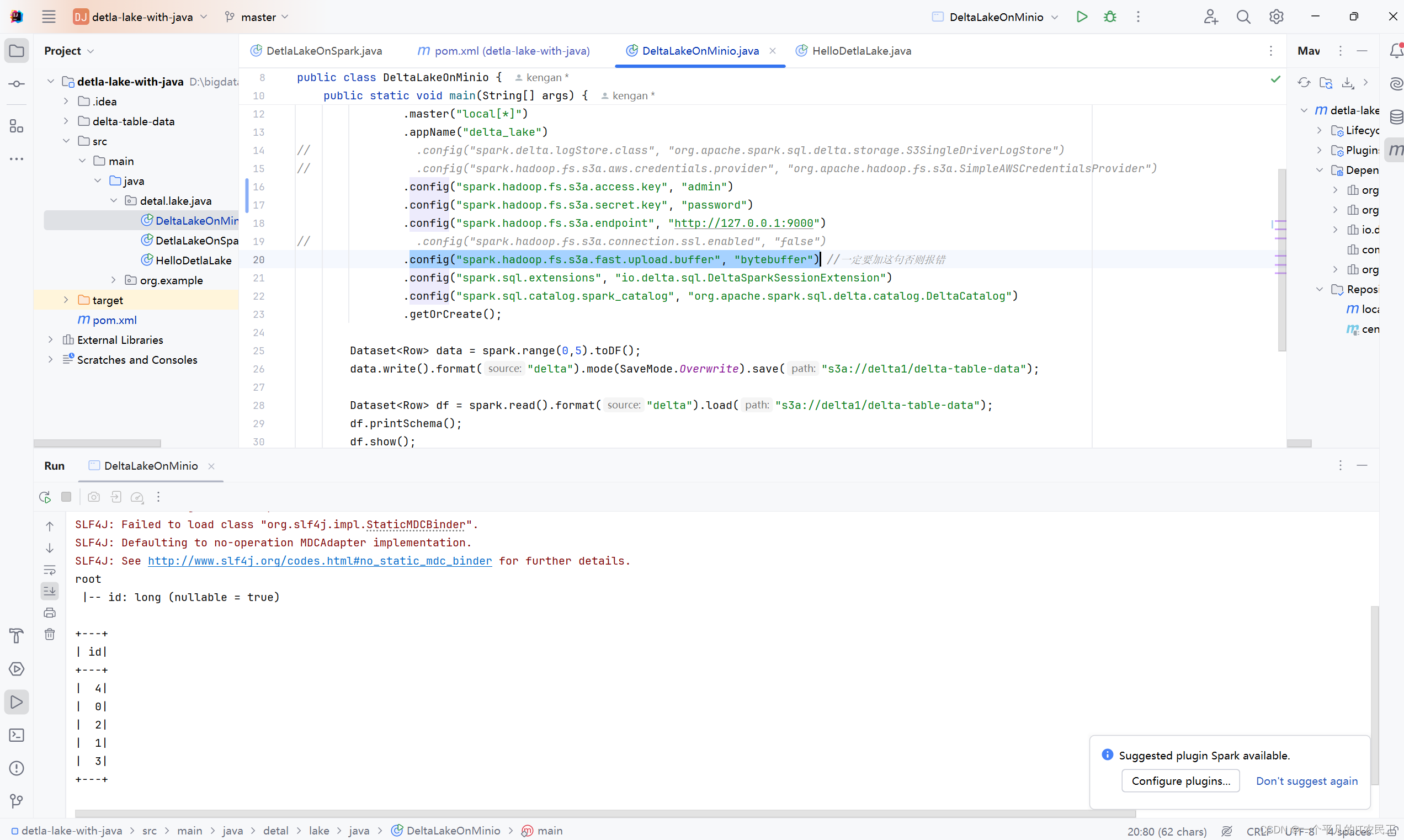
import org.apache.spark.sql.SparkSession;public class DeltaLakeOnMinio {public static void main(String[] args) {SparkSession spark = SparkSession.builder().master("local[*]").appName("delta_lake")
// .config("spark.delta.logStore.class", "org.apache.spark.sql.delta.storage.S3SingleDriverLogStore")
// .config("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider").config("spark.hadoop.fs.s3a.access.key", "admin").config("spark.hadoop.fs.s3a.secret.key", "password").config("spark.hadoop.fs.s3a.endpoint", "http://127.0.0.1:9000")
// .config("spark.hadoop.fs.s3a.connection.ssl.enabled", "false").config("spark.hadoop.fs.s3a.fast.upload.buffer", "bytebuffer") //一定要加这句否则报错.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension").config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog").getOrCreate();Dataset<Row> data = spark.range(0,5).toDF();data.write().format("delta").mode(SaveMode.Overwrite).save("s3a://delta1/delta-table-data");Dataset<Row> df = spark.read().format("delta").load("s3a://delta1/delta-table-data");df.printSchema();df.show();}}5、在IDEA运行结果如下图:
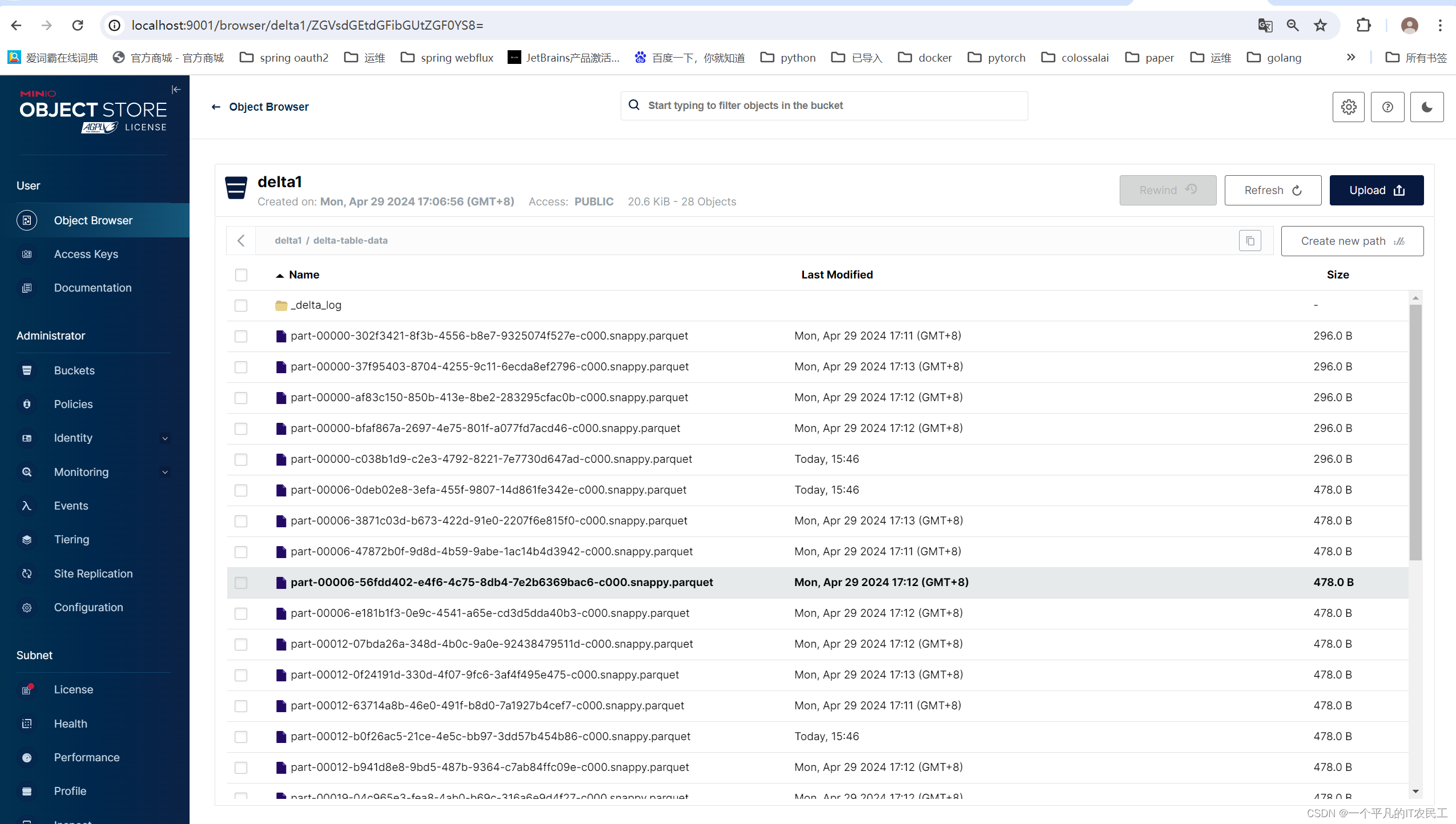
Minio看到的结果如下图:
这篇关于Delta lake with Java--将数据保存到Minio的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




