本文主要是介绍一文读懂Delta Lake:大数据时代的数据湖框架新选择!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍:Delta Lake是一个开源存储层,为Apache Spark和大数据工作负载提供了ACID事务能力。这个存储层由Databricks公司推出,并已成为数据湖方案的重要组成部分。
Delta Lake的核心特性包括:
ACID事务:通过不同等级的隔离策略,Delta Lake支持多个pipeline的并发读写;
数据版本管理:Delta Lake通过Snapshot等来管理、审计数据及元数据的版本,并进而支持time-travel的方式查询历史版本数据或回溯到历史版本;
开源文件格式:Delta Lake通过parquet格式来存储数据,以此来实现高性能的压缩等特性;
批流一体:Delta Lake支持数据的批量和流式读写;
元数据演化:Delta Lake允许用户合并schema或重写schema,以适应不同时期数据结构的变更;
丰富的DML:Delta Lake支持Upsert,Delete及Merge来适应不同场景下用户的使用需求,比如CDC场景。
总的来说,Delta Lake不仅提供了强大的数据处理能力,还具有优秀的兼容性和扩展性,可以满足各种类型和规模的大数据处理需求。
1、Delta Lake官方网站
网址:https://delta.io/
1.1 介绍
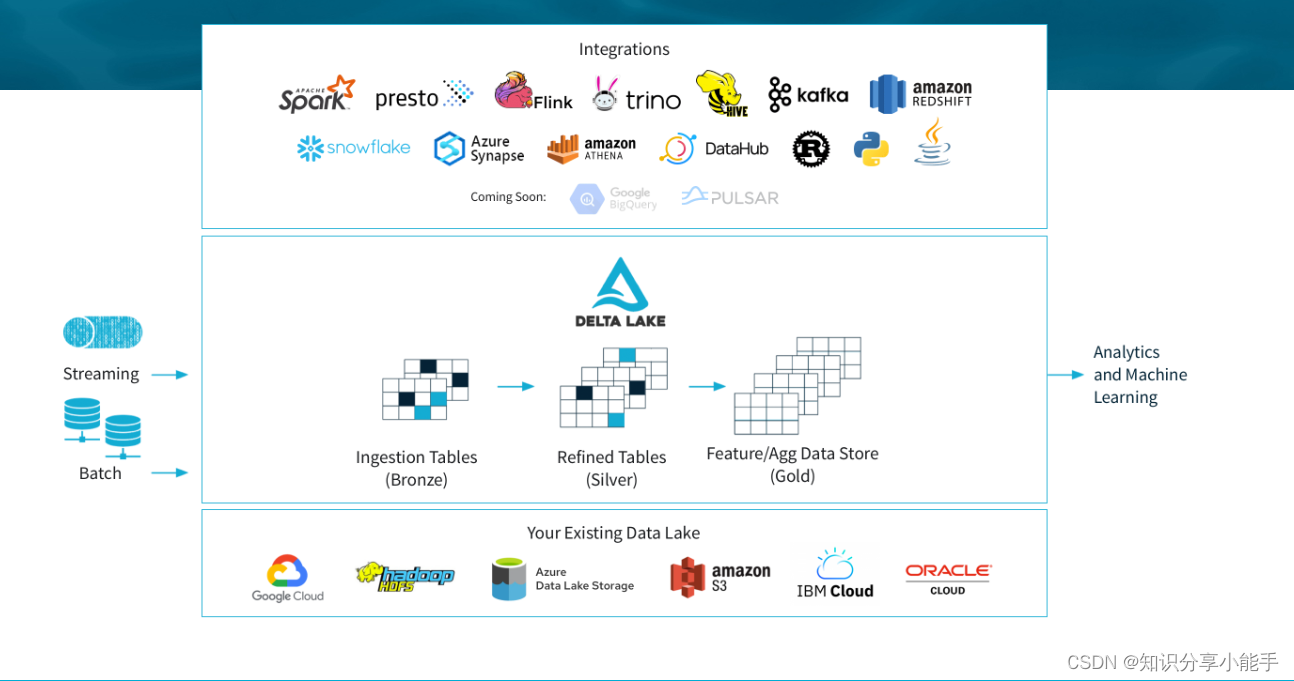


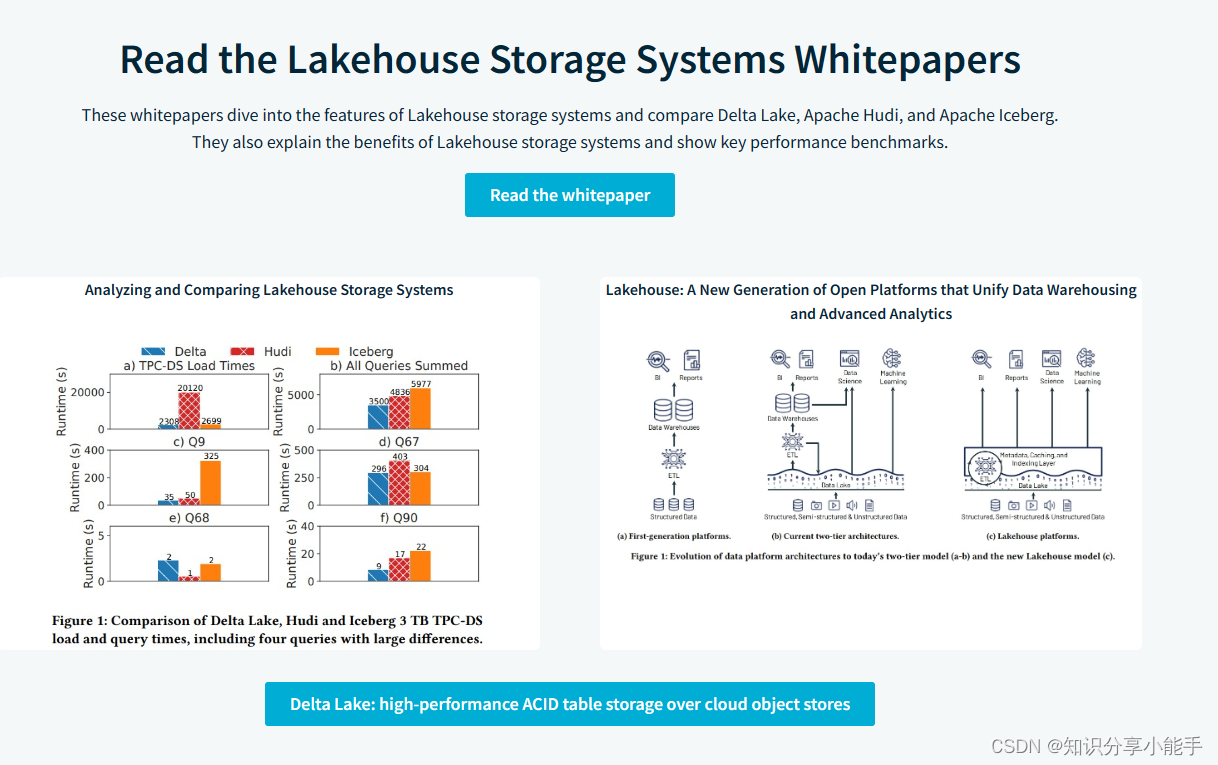
1.2 学习文档

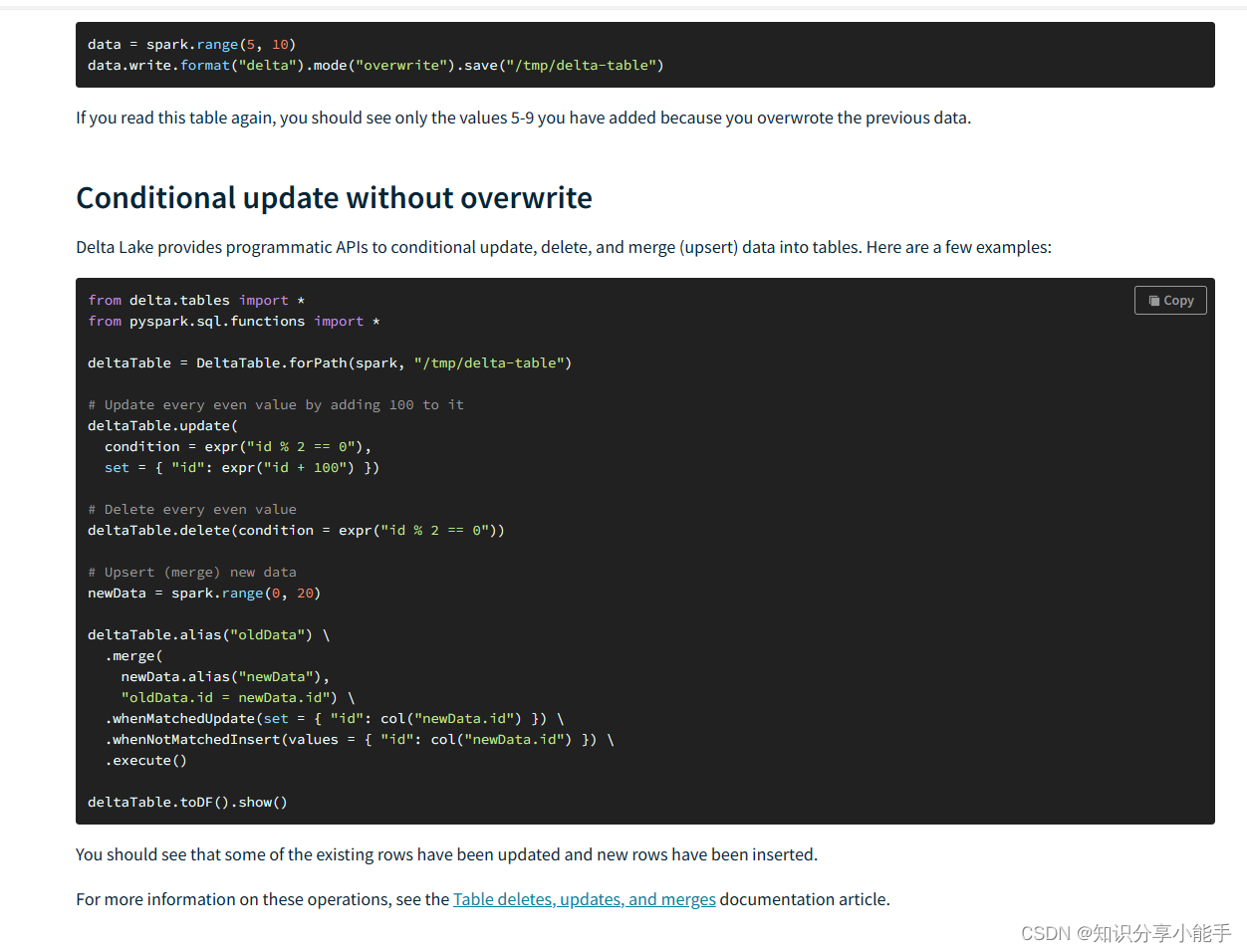
2、书籍推荐
网址:https://delta.io/
2.1 书籍下载
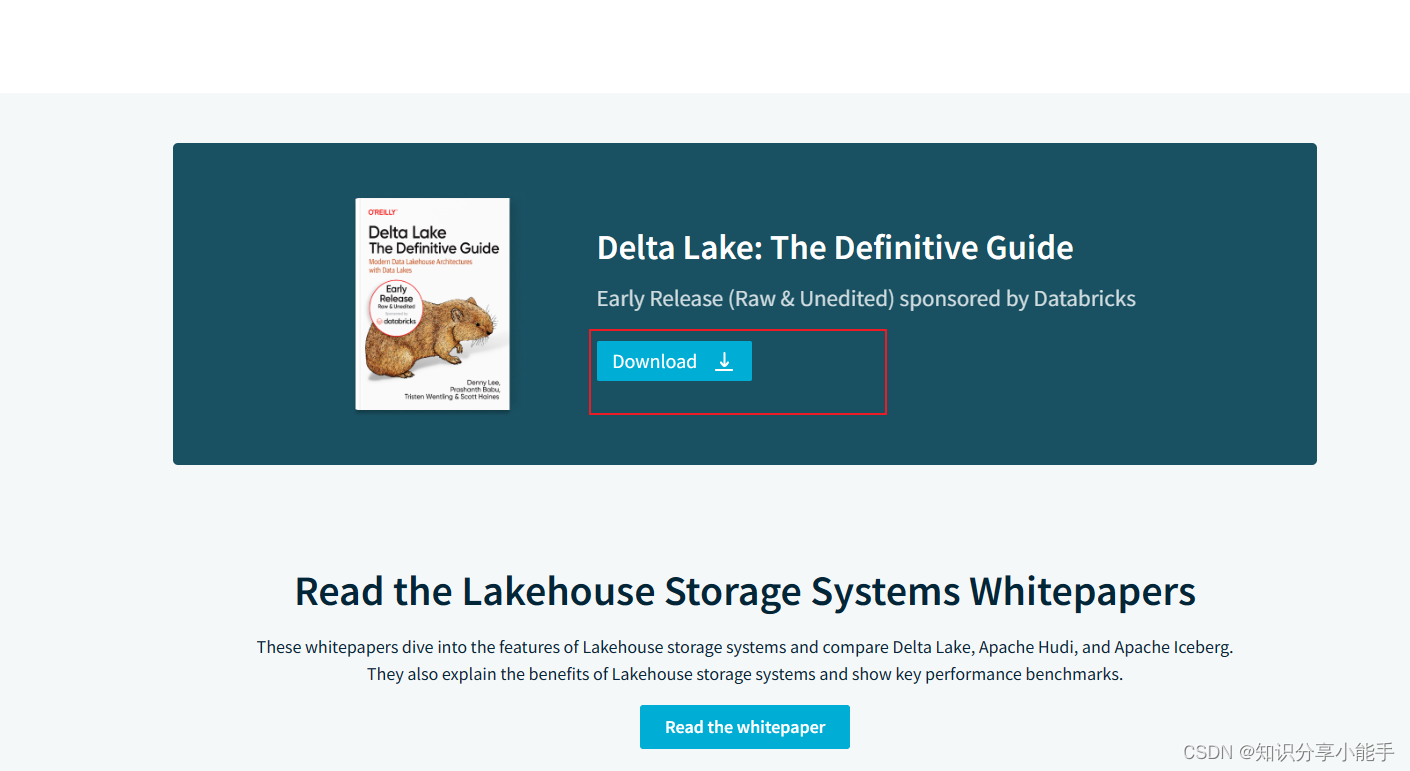

2.2 内容


3、微软官网
网址:https://learn.microsoft.com/zh-cn/azure/databricks/delta/
3.1 学习文档

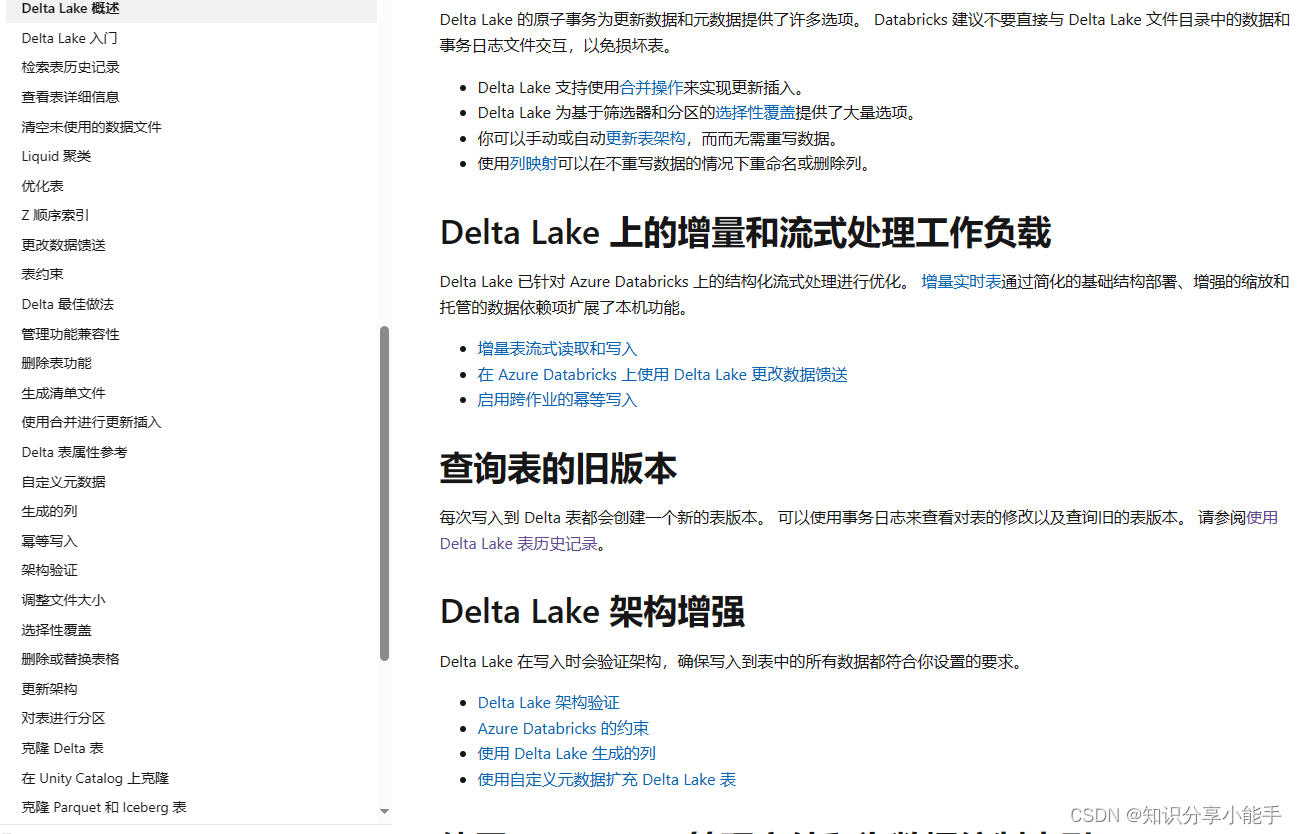

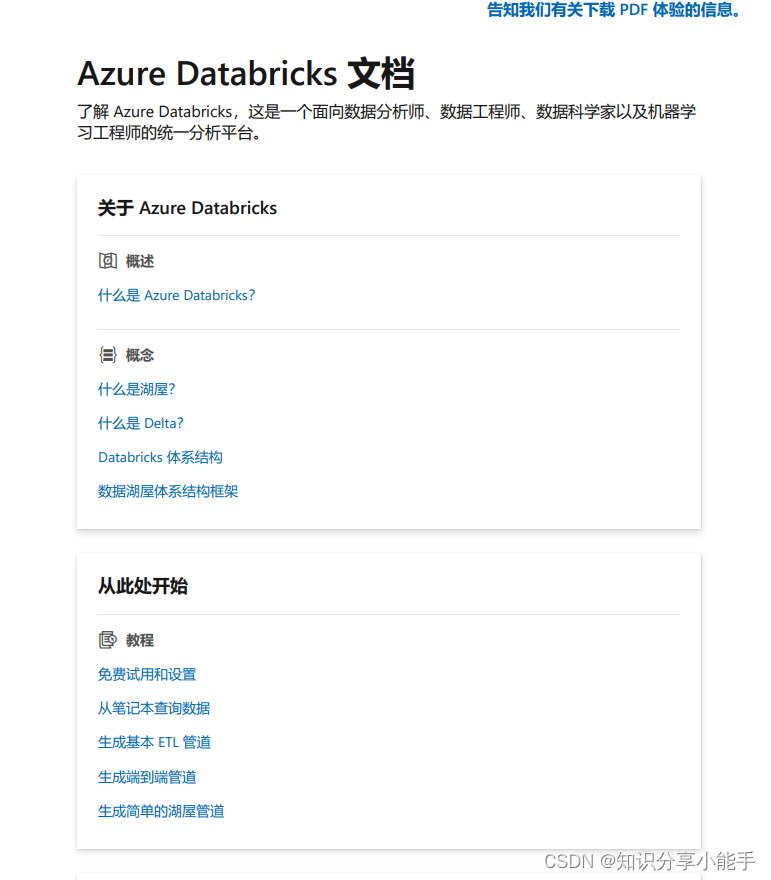
3.2 学习文档下载
网址:https://learn.microsoft.com/pdf?url=https%3A%2F%2Flearn.microsoft.com%2Fzh-cn%2Fazure%2Fdatabricks%2Ftoc.json
4、学习视频推荐
1、大数据新概念数据湖架构开发,大数据新技术Delta Lake
网址:https://www.bilibili.com/video/BV18z4y1f7JY/?spm_id_from=333.337.search-card.all.click&vd_source=849186cc0cbe77dd51dcd8d1dc63a69b


以上就是个人觉得不错的学习网站,希望能帮到学习大数据的人!
这篇关于一文读懂Delta Lake:大数据时代的数据湖框架新选择!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




