本文主要是介绍Delta lake with Java--数据增删改查,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前写的关于spark sql 操作delta lake表的,总觉得有点混乱,今天用Java结合真实的数据来进行一次数据的CRUD操作,所涉及的数据来源于Delta lake up and running配套的 GitGitHub - benniehaelen/delta-lake-up-and-running: Companion repository for the book 'Delta Lake Up and Running'
要实现的效果是新建表,导入数据,然后对表进行增删改查操作,具体代码如下:
package detal.lake.java;import io.delta.tables.DeltaTable;
import org.apache.spark.sql.SparkSession;import java.text.SimpleDateFormat;
import io.delta.tables.DeltaTable;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.HashMap;public class DeltaLakeCURD {//将字符串转换成java.sql.Timestamppublic static java.sql.Timestamp strToSqlDate(String strDate, String dateFormat) {SimpleDateFormat sf = new SimpleDateFormat(dateFormat);java.util.Date date = null;try {date = sf.parse(strDate);} catch (Exception e) {e.printStackTrace();}java.sql.Timestamp dateSQL = new java.sql.Timestamp(date.getTime());return dateSQL;}public static void main(String[] args) {SparkSession spark = SparkSession.builder().master("local[*]").appName("delta_lake").config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension").config("spark.databricks.delta.autoCompact.enabled", "true").config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog").getOrCreate();SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");String savePath="file:///D:\\\\bigdata\\\\detla-lake-with-java\\\\YellowTaxi";String csvPath="D:\\bookcode\\delta-lake-up-and-running-main\\data\\YellowTaxisLargeAppend.csv";String tableName = "taxidb.YellowTaxis";spark.sql("CREATE DATABASE IF NOT EXISTS taxidb");//定义表DeltaTable.createIfNotExists(spark).tableName(tableName).addColumn("RideId","INT").addColumn("VendorId","INT").addColumn("PickupTime","TIMESTAMP").addColumn("DropTime","TIMESTAMP").location(savePath).execute();//加载csv数据并导入delta表var df=spark.read().format("delta").table(tableName);var schema=df.schema();System.out.println(schema.simpleString());var df_for_append=spark.read().option("header","true").schema(schema).csv(csvPath);System.out.println("记录总行数:"+df_for_append.count());System.out.println("导入数据,开始时间"+ sdf.format(new Date()));df_for_append.write().format("delta").mode(SaveMode.Overwrite).saveAsTable(tableName);System.out.println("导入数据,结束时间" + sdf.format(new Date()));DeltaTable deltaTable = DeltaTable.forName(spark,tableName);//插入数据List<Row> list = new ArrayList<Row>();list.add(RowFactory.create(-1,-1,strToSqlDate("2023-01-01 10:00:00","yyyy-MM-dd HH:mm:ss"),strToSqlDate("2023-01-01 10:00:00","yyyy-MM-dd HH:mm:ss")));List<StructField> structFields = new ArrayList<>();structFields.add(DataTypes.createStructField("RideId", DataTypes.IntegerType, true));structFields.add(DataTypes.createStructField("VendorId", DataTypes.IntegerType, true));structFields.add(DataTypes.createStructField("PickupTime", DataTypes.TimestampType, true));structFields.add(DataTypes.createStructField("DropTime", DataTypes.TimestampType, true));StructType structType = DataTypes.createStructType(structFields);var yellowTaxipDF=spark.createDataFrame(list,structType); //建立需要新增数据并转换成dataframeSystem.out.println("插入数据,开始时间"+ sdf.format(new Date()));yellowTaxipDF.write().format("delta").mode(SaveMode.Append).saveAsTable(tableName);System.out.println("插入数据,结束时间"+ sdf.format(new Date()));System.out.println("插入后数据");deltaTable.toDF().select("*").where("RideId=-1").show(false);//更新数据System.out.println("更新前数据");deltaTable.toDF().select("*").where("RideId=999994").show(false);System.out.println("更新数据,开始时间"+ sdf.format(new Date()));deltaTable.updateExpr("RideId = 999994",new HashMap<String, String>() {{put("VendorId", "250");}});System.out.println("更新数据,结束时间"+ sdf.format(new Date()));System.out.println("更新后数据");deltaTable.toDF().select("*").where("RideId=999994").show(false);//查询数据System.out.println("查询数据,开始时间"+ sdf.format(new Date()));var selectDf= deltaTable.toDF().select("*").where("RideId=1");selectDf.show(false);System.out.println("查询数据,结束时间" + sdf.format(new Date()));//删除数据System.out.println("删除数据,开始时间"+ sdf.format(new Date()));deltaTable.delete("RideId=1");System.out.println("删除数据,结束时间"+ sdf.format(new Date()));deltaTable.toDF().select("*").where("RideId=1").show(false);}
}
里面涉及spark的TimestampType类型,如何将字符串输入到TimestampType列,找了几个小时才找到答案,具体参考了如下连接,原来直接将string转成java.sql.Timestamp即可,于是在网上找了一个方法,实现了转换,转换代码非原创,也是借鉴其他大牛的。
scala - How to create TimestampType column in spark from string - Stack Overflow
最后运行结果
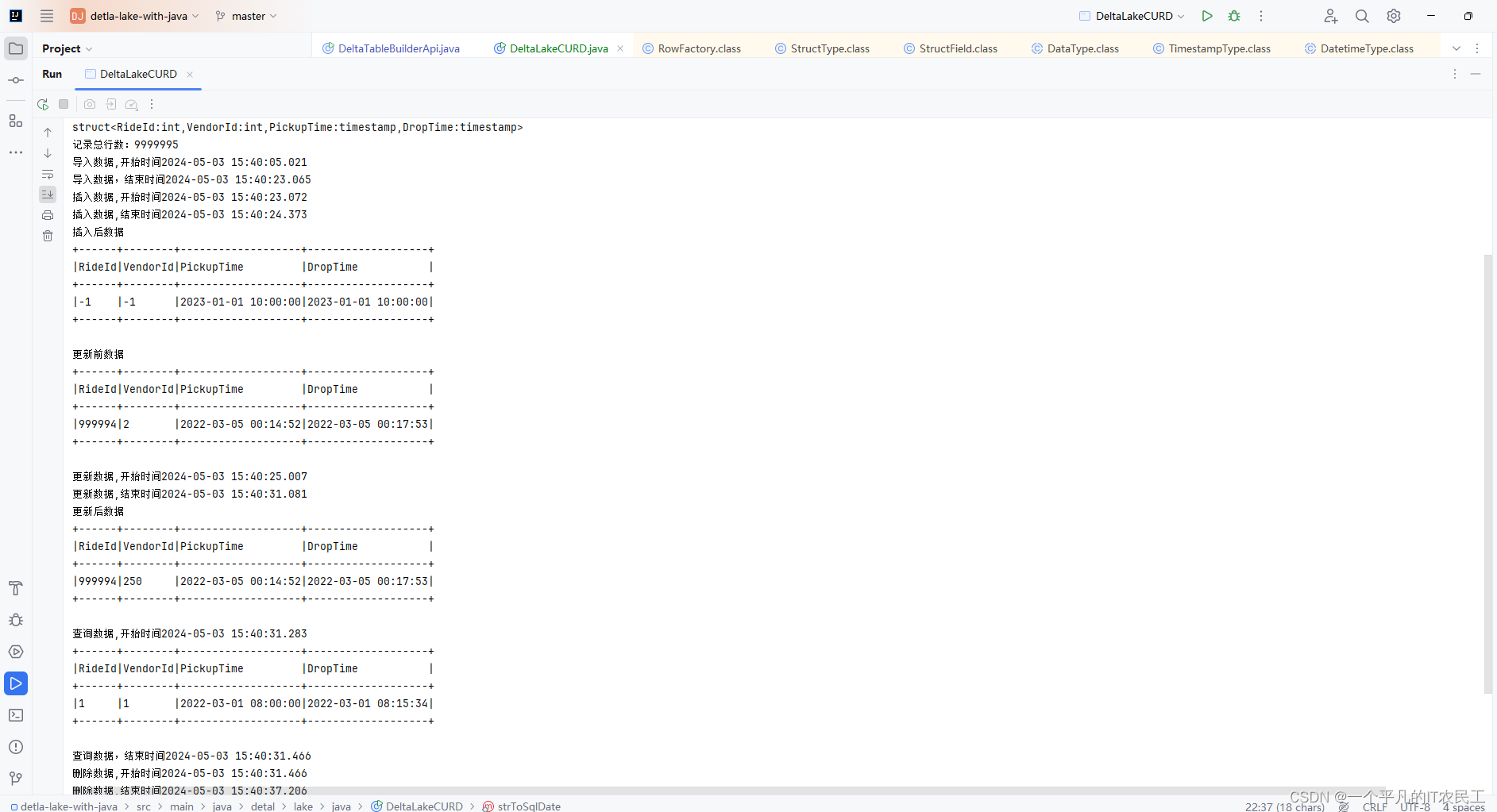
这篇关于Delta lake with Java--数据增删改查的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





