本文主要是介绍湖仓一体平台构建实践 (基于 Iceberg ),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 背景
0) 数据管理架构演进
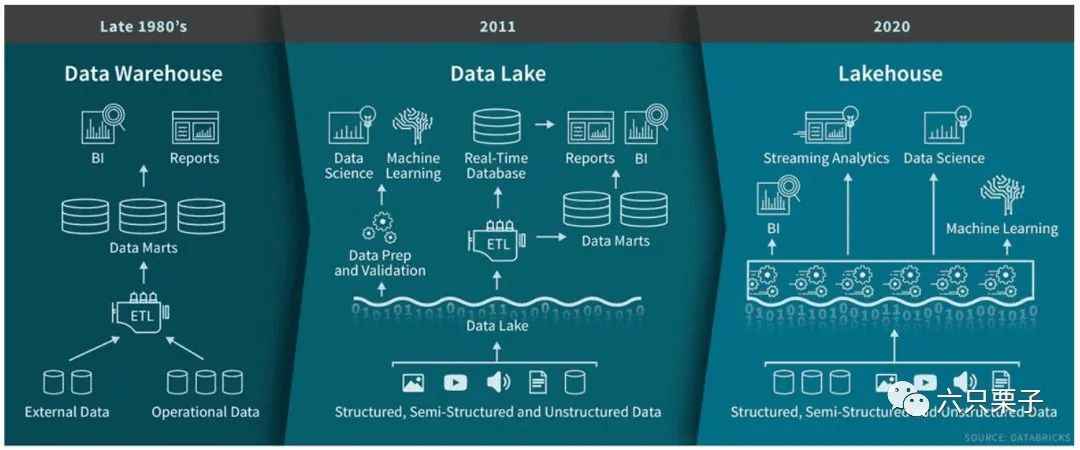
1)数据仓库(1990)
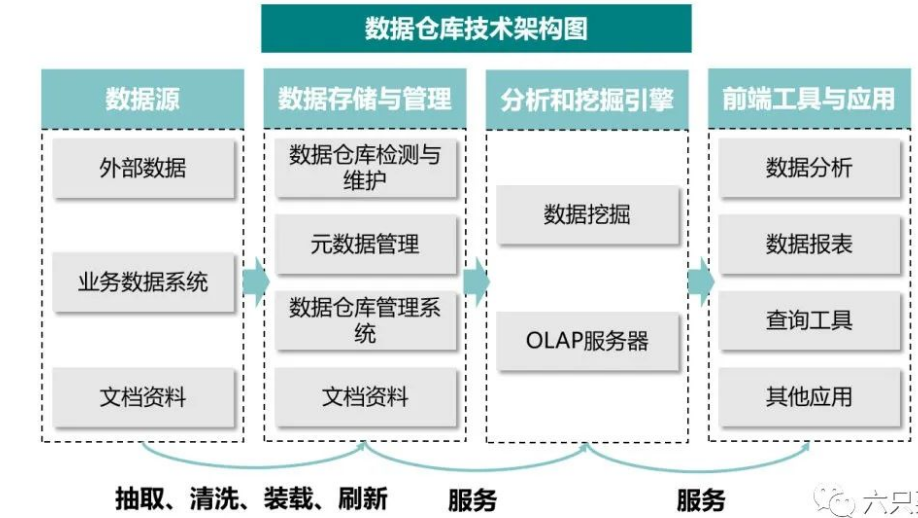
从数据仓库架构图可以看出,数据仓库的主要功能,是将企业信息化管理系统中联机事务处理所积累的大量数据,通过数据仓库特有的信息存储架构,系统化分析整理,进而支持如决策支持系统、主管资讯系统的创建,帮助决策者快速有效的从大量数据中分析出有价值的信息,以利于后期决策拟定及对外在环境变化的快速回应,帮助其构建商业智能。
需要进行数据处理的公司在湖仓演进的架构选择上都十分相似。起初,首选方式是数仓架构,比如teradata 、greenplum或Oracle等。通常数据处理的流程是把一些业务数据库,如Transactional Database等,通过ETL的方式加载到Data Warehouse中,再在前端接入一些报表或者BI的工具去展示。
但是随着业务类型增多,我们需要扩展更多的业务场景,如数据科学或机器科学领域等。数据类型和数量也随之增多,结构化数据在互联网领域只占很小的一部分,还有很多半结构化、非结构化的埋点日志和音视频数据等。
我们的数仓已经无法处理更多数据,一些新技术,尤其是开源等多个领域的大数据技术开始涌现。
2)数据湖——数仓两层架构(2010)
在大数据时代数据量剧增背景下,催生了数据湖技术。数据湖是一个存储企业各种各样原始数据的大型仓库,可供数据存取、处理、分析以及传输,可看作一种大型数据存储库和处理引擎。相比于数据仓库而言,数据湖存储容量更大,数据类型更为丰富,增加了对半结构化数据和非结构化数据的支持,同时对所有数据进行集中式存储。并具有庞大的PB级数据存储规模以及计算能力,提供多元化数据信息交叉分析,及大容量高速度的数据管道。
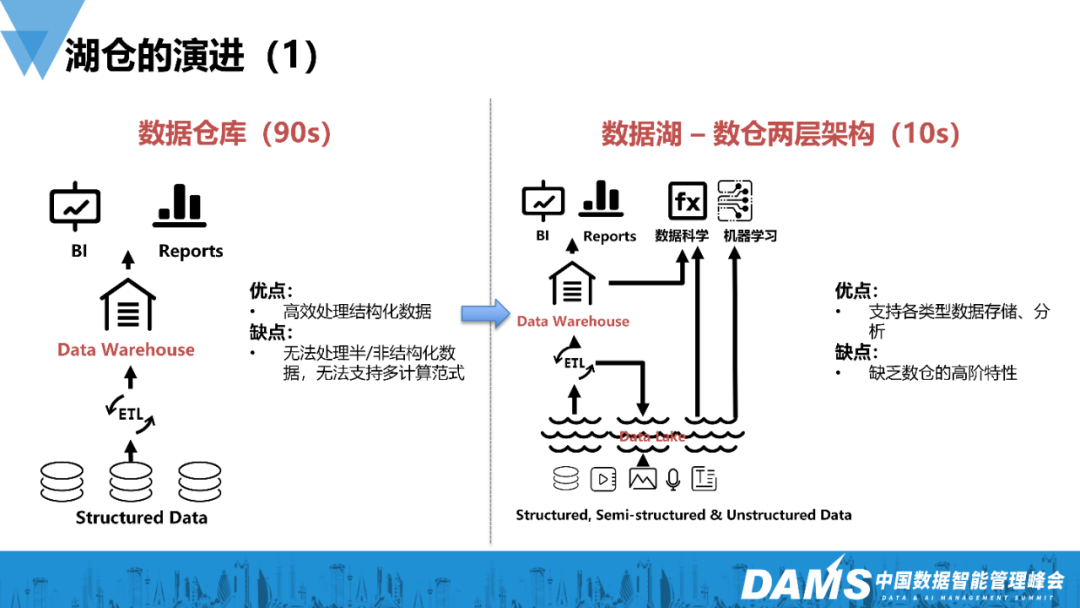
我们逐渐将架构划分为数仓和数据库的双层架构,把数据先加载到数据湖中,通常我们会选择Hadoop数据库作为自建数据湖。如果要做高效的查询或者报表的输出,我们会对数据再加工,放入高性能的数仓中,如ClickHouse或Doris等。
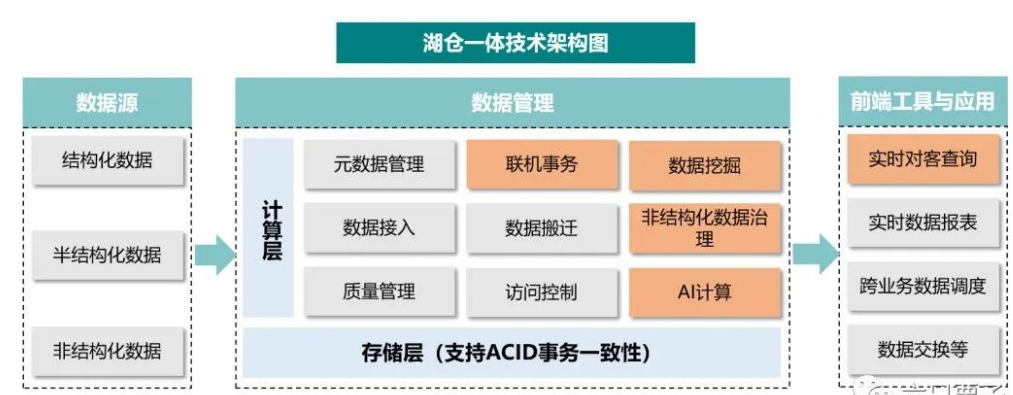
3)湖仓一体(2010)
湖仓一体则是一种新型的开放式架构,打通了数据仓库和数据湖,并融合了两种架构的优势。其底层支持多种数据类型并存,且实现数据间的相互共享。上层可以通过统一封装的接口进行访问,可同时支持实时查询和分析。湖仓一体使得数据入湖后可原地进行数据处理加工,避免数据多份冗余以及流动导致的算力、网络及成本开销,可作为超大型的数据存储资源池,实现对全量数据的实时处理。
需要具备几个条件:
-
湖上可靠的数据管理:即需要一种开放的高性能的数据组织方式。采用传统方式定义表时,缺乏一种高效的表的组织方式。我们通常用 Hive表,它就是一个目录,没有特殊的能力。我们需要一种更高效的组织能力,兼顾一些仓的特性。
-
支持机器学习和数据科学:湖仓一体的技术需要有一套开放的标准或者开放的接口。大家在用数仓的时候,会发现它是存算一体的数仓,存储就是为了计算所定制。虽然性能很好,但不开放,也就是所有的生态都要建立在上面,但数据湖则是天然开放,Flink和Spark等其他引擎都能使用这些数据。
-
最先进的SQL性能:若湖仓一体只是湖,那么很轻易就能办到,但是它的性能会比较差。如果要使表具备仓的性能,比如能够匹敌类似Snowflake或者Redshift这样的性能,则需要一个高性能的SQL引擎,这也是Databricks做了Photon引擎的原因,有了这些,我们就可以真正在湖上构建出一个高性能的数仓,也就是“湖仓一体”。
为什么要引入湖仓一体

我们的数据主要来自于三个方面:来自APP/网页端等的埋点数据,服务端的日志数据以及业务系统数据库中的数据,经过我们数据采集端的工具和服务,采集到大数据平台中,包括离线的HDFS数据和实时的Kafka数据
进入大数据平台后,我们的数据开发人员按照数据需求对数据进行加工处理,分层数据建模。主要是用Hive和Spark进行离线的数据处理,使用Flink进行实时的数据处理。用户可以使用Spark或者Trino直接访问数据开发同学建模好的数据表,但是很多时候,为了更好地支持业务在数据探索/BI报表/数据服务/全文检索等方面的实际需求,我们还需要将数据从HDFS上的Hive表导出到外部存储,从而更高效地满足用户需求,比如ClickHouse/Redis/ES等。

当前的这套架构可以基本满足我们对于数据分析的需求,但是也存在许多不足之处,主要问题在于:
第一,从Hive表导出到外部存储,需要额外的数据同步和数据存储成本,整个数据加工的链路也变长了,可靠性降低。
第二,各个存储之间实际上是数据孤岛,跨源查询的成本高,效率低,基本不太可行。
第三,我们内部基于Hadoop/Hive生态构建的数据质量/数据血缘/安全/元数据管理等平台服务工具链很难完整覆盖各个外部存储计算引擎。
我们使用 Iceberg 构建湖仓一体平台的初衷是希望解决业务方在使用 Hive 数仓时的一些痛点。数据湖和数据仓库,但是二者都有自己的偏重,都在各自的领域熠熠生辉,一旦跨领域,可能效果就大打折扣了。主要包括以下几大方面:
- Hive 的时效性不好,即使用 FIink 流式的引擎写入,延迟也会在小时级别。
- Hive 的查询性能达不到交互式分析的要求,所以经常需要把 Hive 的数据储存到其它引擎当中。
- Hive 出仓链路越来越多,越来越复杂,维护成本高。
- 出仓的数据容易形成数据孤岛,多份数据造成数据冗余,导致存储成本上涨。
我们希望我们的湖仓一体平台能够解决这些痛点,我们的目标是:
- 数据统一存储与分析,避免数据孤岛和多份数据的出现。
- 查询要高效,以满足交互式分析的要求。
- 使用要尽可能的便捷,尽可能降低业务方的门槛。
- 待完善…………
2 湖仓一体
湖仓一体是一种新的数据管理模式,将数据仓库和数据湖两者之间的差异进行融合,并将数据仓库构建在数据湖上,从而有效简化了企业数据的基础架构,提升数据存储弹性和质量的同时,还能降低成本,减小数据冗余。
湖仓一体的关键特性
-
支持多种数据类型(结构化、非结构化):
Lakehouse可为许多应用程序提供数据的入库、转换、分析和访问。数据类型包括图像、视频、音频、半结构化数据和文本等。 -
极低成本实现数据的存储;
-
实现数据治理和数据高质量的保证,因为一份数据,相互之间的冗余减少了,互相不一致性自然就大幅度的降低了。
-
事务支持:在企业中,数据往往要为业务系统提供并发的读取和写入。对事务的ACID支持,可确保数据并发访问的一致性、正确性,尤其是在
SQL的访问模式下。 -
数据的模型化和数据治理:可以支持各类数据模型的实现和转变,支持
DW模式架构,例如星型模型、雪花模型等。该系统应当保证数据完整性,并且具有健全的治理和审计机制。 -
存算分离:存算分离的架构,也使得系统能够扩展到更大规模的并发能力和数据容量。具有良好的可扩展性与敏捷性。
-
开放性:采用开放、标准化的存储格式,提供丰富的
API支持,各种工具和引擎(包括机器学习和Python R库)可以高效地对数据进行直接访问。支持包括数据科学、机器学习、SQL查询、分析等多种负载类型 -
统一平台支持多样化的工作负载,无论是批处理、即时查询,还是AI、BI都可以在一个平台上统一负载支撑。持直接在源数据上使用
BI工具,加快分析效率,降低数据延时。另外相比于在数据湖和数据仓库中分别操作两个副本的方式,更具成本优势。 -
批流一体:支持批处理和实时计算;可以使用批处理分析数据流;可提供批处理、流处理的联动和转换。实时报表已经成为企业中的常态化需求,实现了对流的支持后,为实时数据服务构建专用的系统。
-
多种高性能计算引擎支撑:提供高性能的数据计算引擎;,提供Flink、Spark、Hive、MR等多种计算引擎,满足不同业务场景数据处理需求。
价值与意义
-
弥补原架构的不足。相比数据湖来说,湖仓一体架构能够支撑实时查询和实时分析场景,弥补了Hadoop技术对于数据实时处理能力的不足。湖仓一体技术能够从基础架构上打通数据湖与数据仓库,提供实时查询以及实时分析能力
-
而相比数据仓库来说,湖仓一体架构作为支持实时处理的统一数据底座,具备多引擎实时处理多类型数据的能力,避免了数据仓库无法分析非结构化数据的问题,
-
以及不同平台间数据移动所带来的成本。能够降低企业成本,提高效率。湖仓一体架构能够降低数据流动带来的开发成本及计算存储开销,提升企业效率。
-
助力企业数字化转型。在企业数字化转型的过程中,企业需要根据自身业务场景及发展诉求来设计系统架构,单一模式已然无法满足。而湖仓一体架构能够帮助企业构建起全新的数据融合平台,打破了数据湖与数据仓库割裂的体系,将数据湖的灵活性、数据多样性以及丰富的生态与数据仓库的企业级数据分析能力进行了融合。
湖仓一体主要应用在什么场景,它能够给我们带来什么收益?我们的理解是它查询性能和使用场景处在离线数据分析和分布式OLAP引擎的中间位置。相比于离线数据分析,它能够提供更好的查询性能,同时Iceberg表能够提供较粗力度的ACID事务能力,保证数据查询的正确性,还有它能提供实时的数据可见性,将原来离线表、天表、小时表的可见性提升到分钟级,对于离线数据分析能够支持更丰富的场景,同时在报表、数仓分析层建模等场景可以提供更好的查询体验和计算效率。
另外一方面,相比于ClickHouse这样的OLAP引擎,湖仓一体的好处是它可以自然作为离线数仓Hive表分层的一部分,无需数据在HDFS和ClickHouse冗余存储和数据同步,它的计算和存储是分离架构,能够有更好的弹性,一般的公司大数据平台的工具链都比较完备,Iceberg表可以非常小成本接入,因为它本来就可以认为是一个特殊存储类型的Hive表,所以在历史数据上只会很低频的访问,放在Iceberg中会比ClickHouse成本更低,它也可以作为ClickHouse中数据的一个低成本副本存储方案,或者直接支持一些性能要求没有那么高的数据服务。简单总结来说,湖仓一体相比于离线分析可以提供更好的查询体验和更高的查询效率,相比于ClickHouse,查询效率比不上,但是资源和用户使用成本则更低。
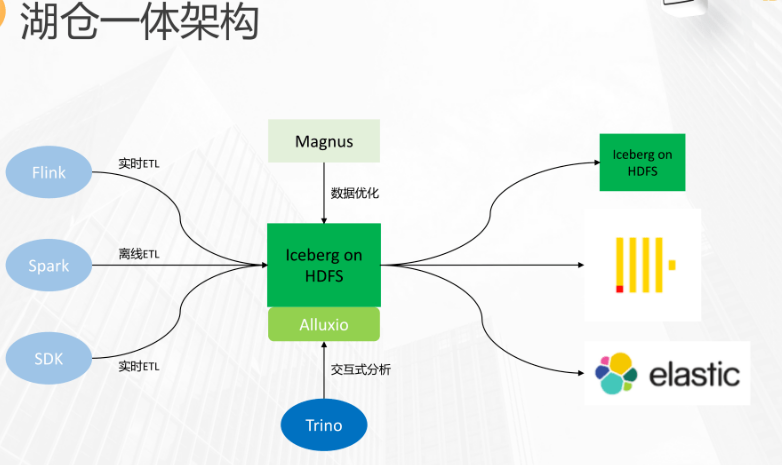
湖仓一体架构如上图所示,采用 Iceberg 来存储数据,数据是在 HDFS 上。入湖的几条链路包括 FIink、Spark 引擎来写入,Spark和Flink可以接入流或者批的数据写入Iceberg,也提供 java 的 API,业务方可以直接通过 API 来写入数据,后台有一个叫做 Magnus 的服务对 Iceberg 的数据进行不断的优化。另外我们也用 Alluxio 来对数据进行缓存加速。我们使用 Trino 来进行交互式分析,对外提供查询接口。写入 Iceberg 的数据有一部分是要继续写入下游的 Iceberg 表。一般是数仓的分层建模的场景。虽然我们减少了 Hive 出仓的链路,但是有一些场景可能 Trino 的查询还是达不到响应时间的要求。比如毫秒级的响应,可能还是会出仓到 ClickHouse、ES 等其它存储中。
湖仓一体架构

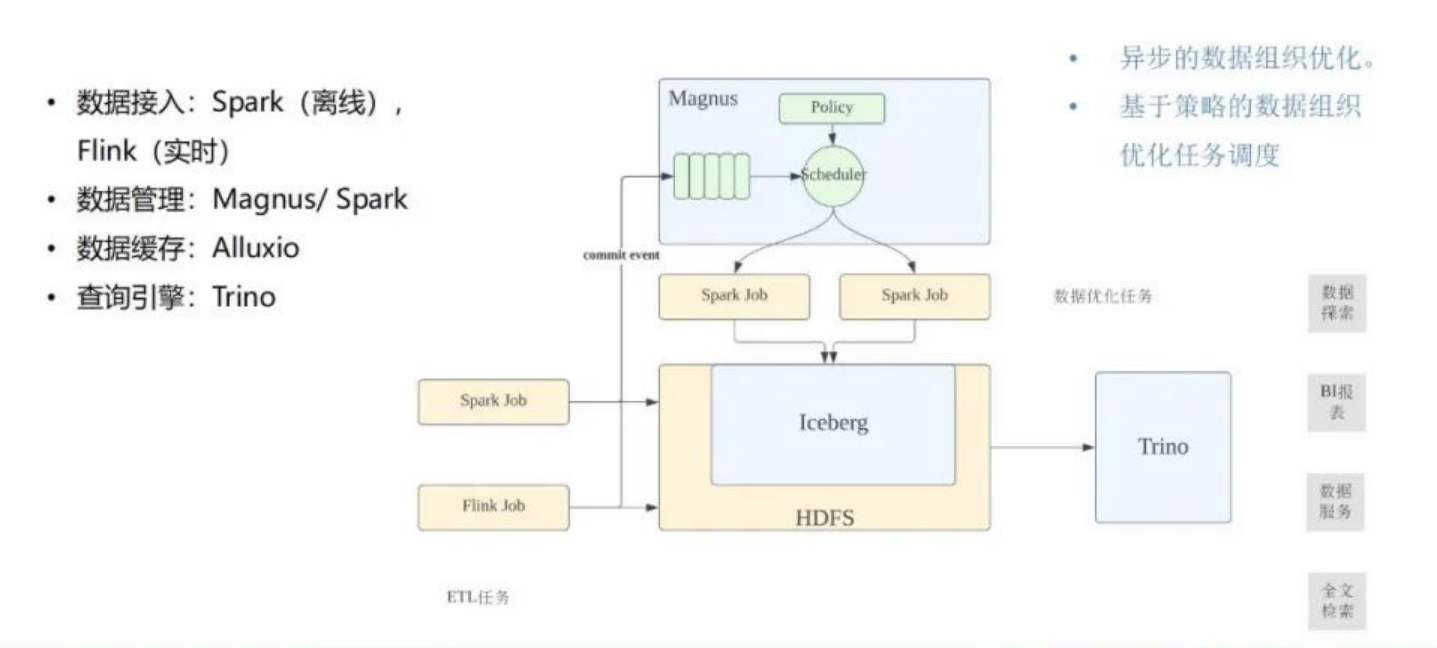 所以我们引入了基于Trino+Iceberg的湖仓一体架构,希望能够简化当前的数据处理流程,核心的目标有两个:
所以我们引入了基于Trino+Iceberg的湖仓一体架构,希望能够简化当前的数据处理流程,核心的目标有两个:
一是之前存在大量的通过Trino/Spark访问Hive的情况,我们希望通过湖仓一体加速这部分的查询效率,在提升用户体验的同时,降低查询的机器资源成本。
第二是对于之前很多需要同步到外部存储的场景,在对性能要求没有特别高的情况下,可以不用同步到外部存储,直接使用Iceberg表响应,简化业务的数据开发流程,提升开发效率。
支持了Iceberg CDC流读的能力。用户可以构建PB甚至EB级别的数据分析平台,构建出一个分钟级别实时的入湖项目,但在数据分析上,可以达到秒级。从传统的T+1变成小时、分钟甚至是秒级的业务响应能力
Iceberg 有文件级别的元数据管理。它基于 snapshot 来做多版本的控制。每一个 snapshot 对应一组 manifest,每一个 manifest 再对应具体的数据文件。我们选 Iceberg 的一个比较重要的原因是其开放的存储格式。它有着比较好的 API 和存储规范的定义,方便我们在后续对它做一些功能上的扩展。
Trino(即原PrestoSQL)是一个开源的分布式SQL查询引擎,适用于交互式分析查询。之前各版本控制台显示为Presto,内核其实是Trino,使用时请注意区分。
3 查询加速
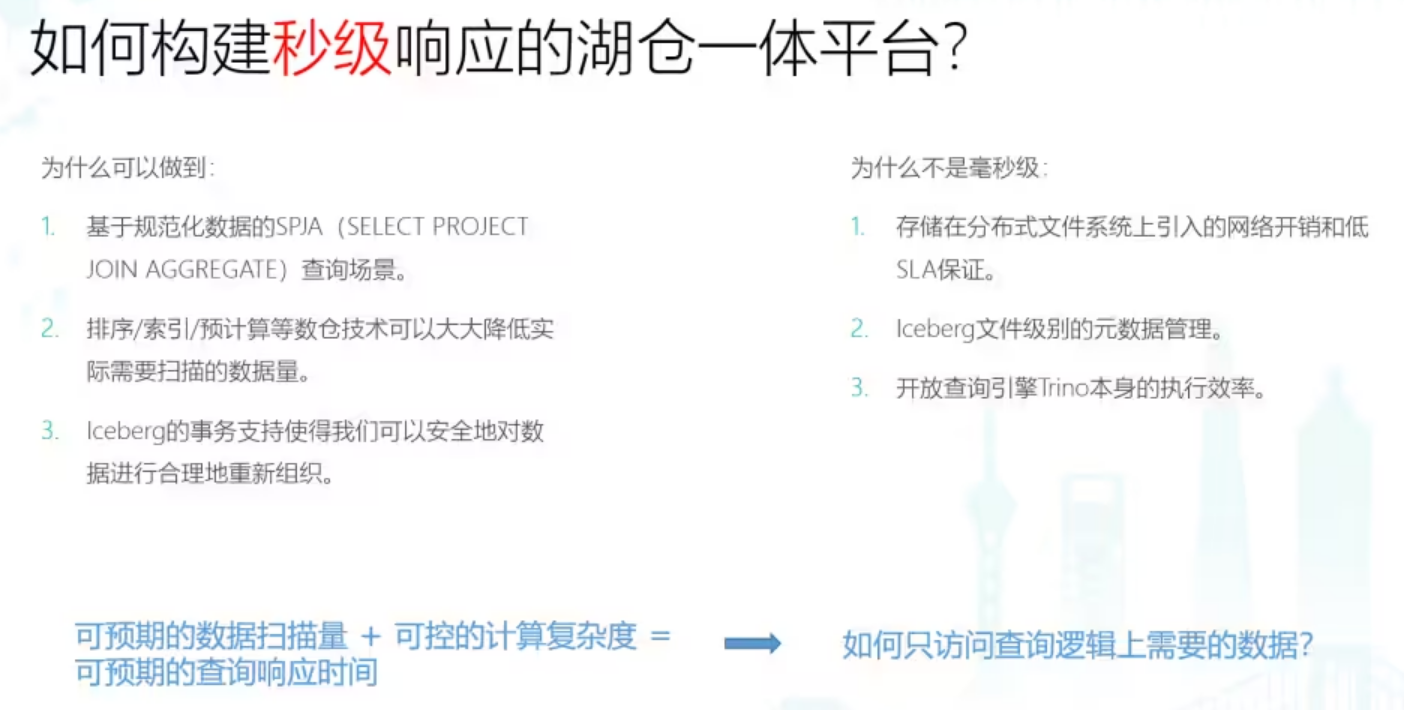
我们的目标是基于Trino和Iceberg构建秒级响应的湖仓一体平台,这个目标的设定主要基于以下的几个我们观察到的事实:
一是我们主要目标业务场景,比如报表/数据产品,他们的表都是经过我们数据开发同学ETL后的强Schema规范化数据,查询的场景也主要是投影/过滤/关联/聚合这几种基本算子的组合,像是两个大表关联,或者复杂嵌套子查询,当然可以执行,但不是我们主要的目标场景。对于这种SPJA查询,一般来说结果集都是非常小的。
二是我们可以通过对Iceberg和Trino进行增强,支持排序/索引/预计算等OLAP高级特性,使得查询时只扫描SQL逻辑上需要的数据,不需要的数据都Skip掉,同时控制需要扫描的数据量在一定的范围内。
第三,Iceberg的事务支持是的我们可以安全地对数据进行合理的重新组织,这个基础是我们能够通过Magnus服务异步进行数据排序/索引/预计算的基础。
同时我们也并不追求向ClickHouse那样的毫秒级响应的能力,主要是不同于ClickHouse的存算一体架构,Iceberg数据存储在HDFS分布式文件系统上,引入了额外网络和文件系统开销,Iceberg主要是在文件级别进行元数据管理,文件一般在256M左右大小级别,粒度相比ClickHouse更粗。
此外,开放的查询引擎在计算侧相比于其他基于native语言开发的,充分利用向量化能力的OLAP引擎也是有不少差距的。基于可预期的数据扫描量和可控的SPJA计算复杂度,我们可以有一个可预期的查询响应时间,那问题就在于:我们如何基于Trino和Iceberg做到在执行查询时,尽量只访问查询逻辑上需要的数据?
多维分析场景
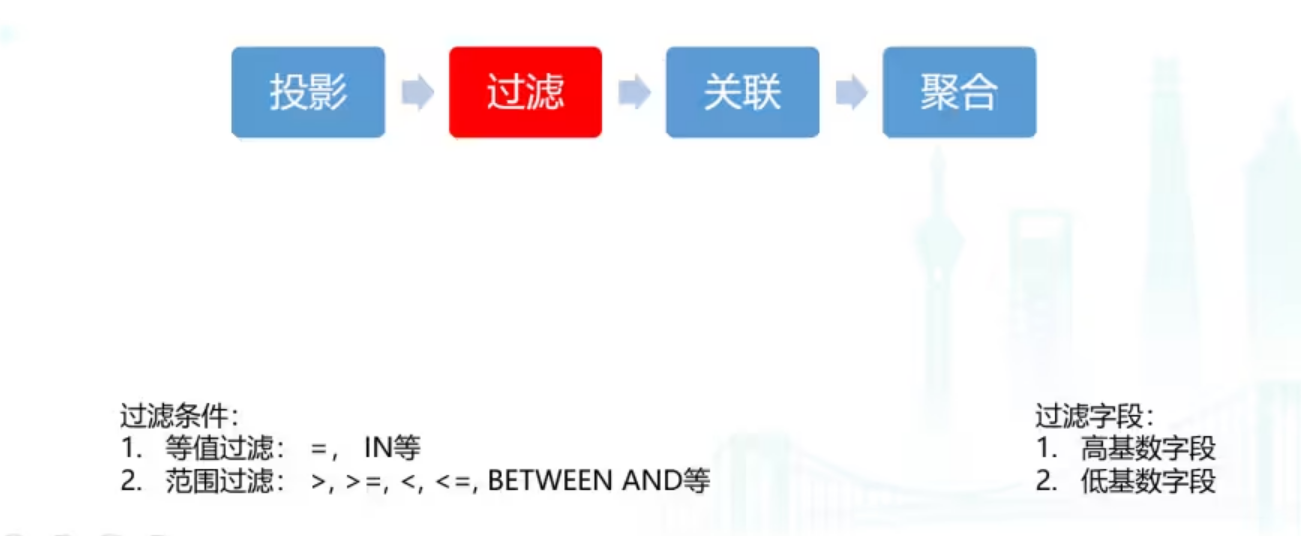
对于典型的多位分析场景SPJA算子,我们针对每个算子类型进行分析。首先是投影,Iceberg表实际的数据存储类型是ORC列存格式,所以查询中投影的字段下推到TableScan层,ORC Reader只会读取需要的字段而不是所有字段,这是一个已经解决的问题。
对于过滤,我们需要考虑不同的过滤类型,找到合适的解决方案。过滤一般可以分为两种过滤条件,等值和范围过滤,过滤字段本身也可以根据字段基数的不同分为高基数字段和低基数字段。
过滤条件 Data Skipping相关技术
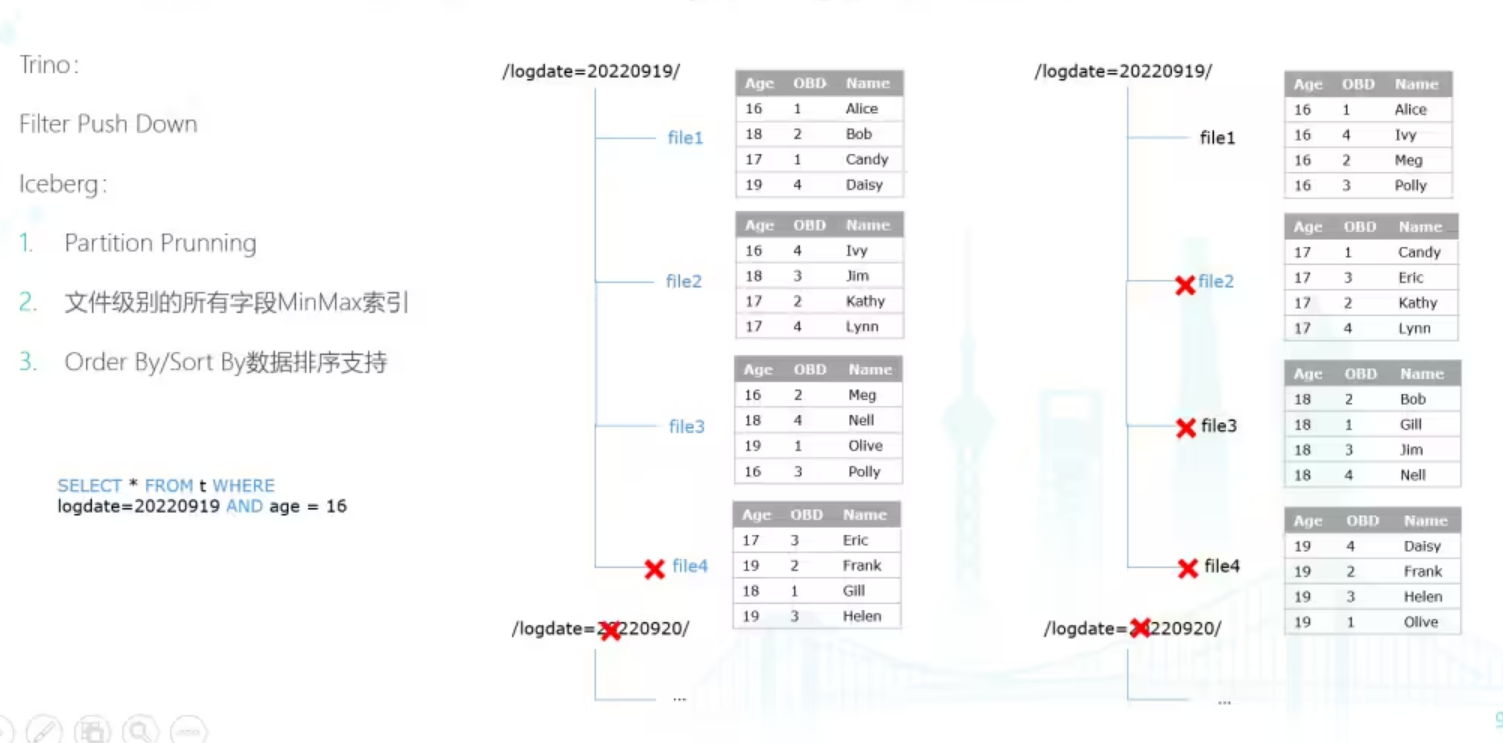
在当前Trino和Iceberg的社区版本中,已经有实现了一些针对过滤条件的Data Skipping相关技术。在引擎侧,Trino通过FiterPushDown相关优化器规则会尽可能把过滤条件下推到最底下的TableScan层。
Iceberg首先支持Partition Prunning,分区的文件存储在分区目录中,过滤条件中包含分区时可以skip不相干的分区目录,同时会在表的metadata中记录每个文件所有字段的minmax值信息,在生成InputSplit时,如果某个字段的过滤条件和该字段的minmax值匹配判断是否需要扫描这个文件。
此外,Iceberg还支持用户定义排序字段,比如示例中,age是常用的过滤字段,用户可以定义age为排序字段,Magnus会拉起异步的Spark任务,将该Iceberg表的数据按照用户的定义将数据按照age字段排序。数据排序的好处是重新调整数据的聚集性,让他们按照age字段聚集,比如对于age=16的查询,排序前需要扫描3个文件,排序后只需要扫描1个文件就行了。
Iceberg对于数据排序分布的能力 Zorder
我们首先将Iceberg表数据的排序分布分为两类:文件间的数据组织和文件内的数据组织,两者相互独立,可以分别单独配置。我们主要扩展的是文件间的数据组织,总共支持了Hash/Range/Zorder和HibertCurve四种数据组织方式。Hash和Range大家都比较熟悉,这里主要简单介绍下Zorder和HibertCurve两种Distribution。

如果对于某个Iceberg表,有多个常用的过滤字段,我们使用Order By a,b,c对多个字段进行排序后,数据的聚集性对于a,b,c依次降低,data skipping效果也会依次下降,尤其是a的基数比较高的时候,很可能对只有b或c过滤条件的查询无法skip任何一个文件。
Zorder的做法就是将多个字段值的多维数据依照规则映射成一维数据,我们按照映射成的一维数据排序组织,这个一维数据按照大小顺序连接起来是一个嵌套的Z字型,所以被成为Zorder排序。
Zorder可以保证映射后的一维数据的顺序可以同时保证原始各个维度的聚集性,从而保证对于各个参与Zorder排序的过滤字段,都有比较好的Data Skipping效果。
针对不同数据类型和数据分布,Zorder的实现也是一个比较有挑战的事情,有兴趣的同学可以参考我们之前的一篇文章:https://zhuanlan.zhihu.com/p/354334895。
这是我们一个具体的测试场景,用了star schema 1TB的数据集,总共1000个文件,可以看到,按照Zorder排序后,针对三个参与Zorder排序字段的等值过滤,都只需要扫描一百多个文件,可以skip掉80%以上的文件,而希伯特曲线排序后,需要扫描的文件数量有进一步的降低。
索引
除了数据排序分布,我们也在Iceberg支持的索引方面进行了增强,支持了多种索引,以应对不同的过滤条件和字段类型。


BitMap索引可以支持范围过滤,并且多个过滤条件的bitmap可以求并,增加skip概率。但是bitmap的主要问题有两个,一个是对于每个基数值都存储一个bitmap代价太大了,二是范围查询时需要读取大量bitmap计算交并差,这大大限制了bitmap索引的应用场景,使用索引可能导致性能的逆优化。我们在这块也有一些探索,感兴趣的话可以参考:https://zhuanlan.zhihu.com/p/433622640。
基于Iceberg支持了丰富的索引类型 ,以及通过数据排序分布提升数据聚集性,保证索引的效果,那么Trino是怎么使用Iceberg的索引的呢?

可以分成两个阶段,第一个阶段是Coordinator在获取InputSplit时,这个阶段使用存储在Iceberg表metadata文件中的相关索引信息,比如每个文件各字段的minmax值,skip掉的文件不会生成InputSplit。
第二个阶段是在Trino Worker接收到分配的task,处理Input Split中的数据时,首先根据文件读取文件对应的索引文件数据,判读是否可以skip当前文件。
我们生成的索引文件和数据文件是一一对应的,当索引大小 小于某个阈值时保存在表的metadata中,在阶段一时使用,当大于阈值时,保存在独立文件中,阶段二使用。
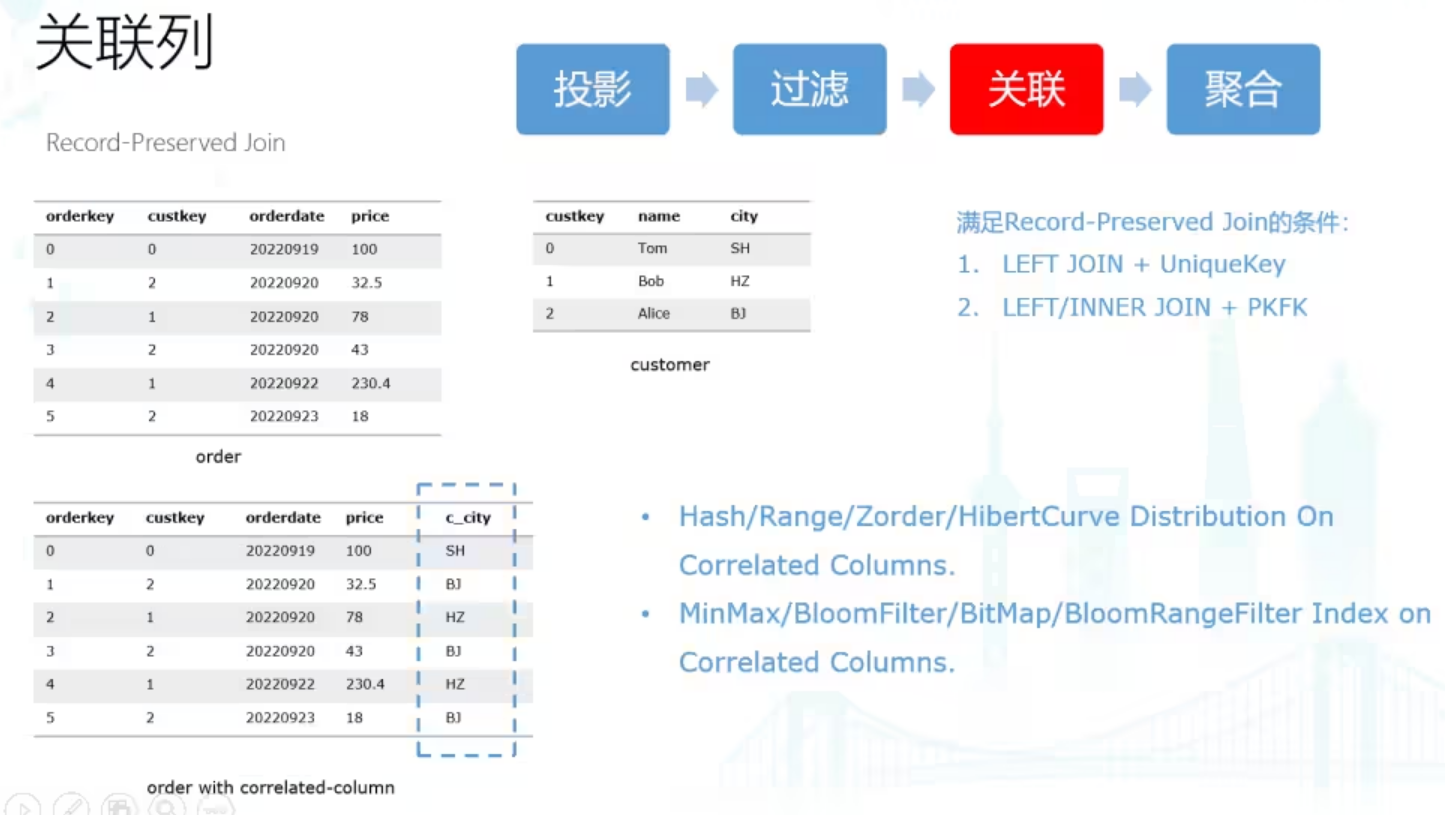
在有Join的查询中,如何有效地Skip不需要访问的数据是一个很难解决的问题。对于典型的星型模型场景,影响性能的关键是扫描事实表的数据量,但是过滤条件一般是根据维度表中的维度字段过滤,Trino是没办法使用维度字段的过滤条件去skip事实表的文件的。
我们支持了在Iceberg表上定义虚拟的关联列,关联列相当于把维度表的维度字段打宽到事实表上,当然实际上不会真的存储,只是一个逻辑上的定义,然后用户就可以像对待原始的列一样对待关联列,可以基于关联列定义数据排序组织,可以基于关联列定义索引。关联列要求事实表和维度表满足一定的约束关系,也就是事实表和维度表Join后的结果相当于对事实表的打宽,事实表的行数没有增加也没有减少,称为Record-Preserved Join。
一般满足这种条件的是:事实表Left Join维度表,且维度表的Join key满足Unique Key的约束,或者,两表的join key满足PKFK的约束,那么事实表和维度表LEFT JOIN或者Inner Join都可以保证Record-Preserved Join。
 我们能够根据关联列定义数据排序组织和索引后,针对维度字段的过滤条件,通过添加一个Trino的优化器Rule,把符合条件的过滤条件就可以从维度表的TableScan中抽取下推到事实表的TableScan中,利用定义在事实表上该字段的索引数据判断是否可以Skip当前的事实表数据文件,从而使得星型模型的Data Skipping效果可以达到和大款表类似的效果,对于我们支持星型模型的业务场景,是一个非常大的提升。
我们能够根据关联列定义数据排序组织和索引后,针对维度字段的过滤条件,通过添加一个Trino的优化器Rule,把符合条件的过滤条件就可以从维度表的TableScan中抽取下推到事实表的TableScan中,利用定义在事实表上该字段的索引数据判断是否可以Skip当前的事实表数据文件,从而使得星型模型的Data Skipping效果可以达到和大款表类似的效果,对于我们支持星型模型的业务场景,是一个非常大的提升。
预计算
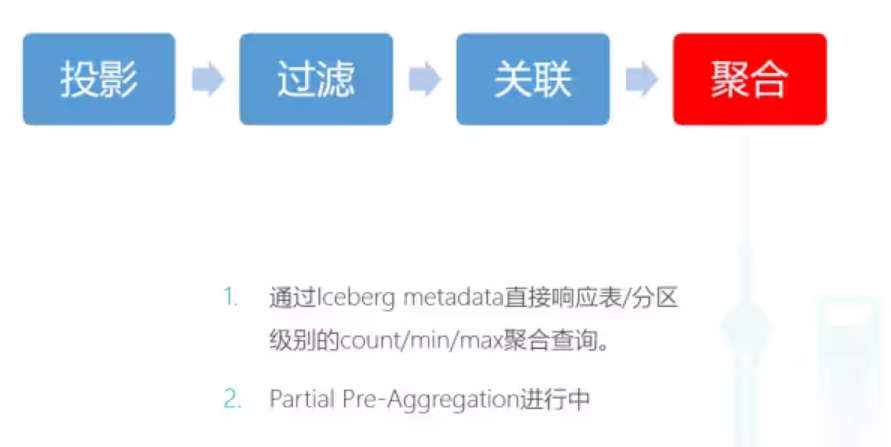
通过对于数据排序组织,索引和关联列的支持,Trino + Iceberg可以基本上做到文件级的只实际扫描SQL逻辑上需要的数据到引擎中参与计算,但是对于部分包含聚合算子的查询场景,可以SQL逻辑上就需要计算大量的数据,聚合成少量结果集返回给用户,这样的场景主要是需要通过预计算解决性能上的问题,通过预计算的结果直接响应查询,从而避免实际扫描计算大量的数据。
我们当前支持了直接通过Iceberg metadata中的数据直接响应用户表/分区级别的count/min/max聚合查询。对于更通用的预计算方案,还在开发过程中,如何实现高效的文件级别预计算存储和查询,如何利用部分文件预计算结果加速查询,如何解决预计算cube维度爆炸问题等,这是一个非常有意思而且有挑战的方向,我们后面有实际成果的时候到时会和大家在分享在这个方面的工作。
湖仓一体现状

目前主要场景包括 BI 报表、指标服务、A/B Test、人群圈选和日志等。
湖仓一体平台目前处在快速发展的阶段,这里和大家分享下当前的一些关键指标,我们的Trino集群大概是5376个core,每天有7万的查询量,总接入的数据量目前是2PB,通过数据排序/索引等广泛的应用,平均查询只需要扫描2GB的数据,总体P90的响应时间在2s以内,基本上达到了我们建设秒级响应的湖仓一体平台的目标。
Iceberg 表总量大约为 5PB,日增 75TB。Trino 查询每天在 20 万左右,P95 的响应时间是 5 秒。我们给自己的定位为秒级到 10 秒级。过滤的数据量(估算)为 500TB/ 天,占比约 100%~200%。
这篇关于湖仓一体平台构建实践 (基于 Iceberg )的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



