本文主要是介绍针对 AI 优化数据湖仓一体:使用 MinIO 仔细了解 RisingWave,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

RisingWave 是现代数据湖仓一体处理层中的开源流数据库,专为性能和可扩展性而构建。RisingWave 旨在允许开发人员在流数据上运行 SQL。鉴于 SQL 是数据工程的通用语言,此功能非常重要。它具有强大的架构,包括计算节点、元节点和压缩器节点,所有这些都针对 AI 基础的高吞吐量和低延迟操作进行了优化:例如数据质量、数据探索和预处理。请记住,您的 AI 计划仅与您的数据一样好。
RisingWave 将自己定位为 Apache Flink 和 ksqlDB 的替代品,并能很好地与该领域的其他 Kubernetes 原生技术配合使用;特别是那些也是为速度和规模而构建的。这篇博客展示了使用 Docker Compose 的 RisingWave 和 MinIO 之间的实现。
先决条件
您需要在系统上安装 Docker Desktop。下载并安装适合您的操作系统的版本,然后通过打开终端并运行以下命令来检查是否正确安装了它:
docker-compose --version您还需要一个 PostgreSQL 客户端。 psql 根据您的操作系统按照这些说明进行操作。
接下来,在终端窗口中克隆 RisingWave 存储库并导航到包含 docker-compose 文件的文件夹:
git clone https://github.com/risingwavelabs/risingwave.git
cd risingwave/docker启动服务
使用以下命令启动 RisingWave 和 MinIO 服务:
docker-compose up -d使用此 Docker Compose 文件执行 docker-compose up 时,Docker Compose 会协调多个互连服务的部署,包括 risingwave-standalone 、 etcd-0 、 、 minio-0 prometheus-0 和 grafana-0 message_queue 。它根据指定的设置(如图像源、环境变量、卷映射和端口绑定)配置每个服务。管理服务之间的依赖关系,以确保正确的启动顺序。网络设置允许内部通信,而运行状况检查则监视服务稳定性。应用资源限制和重启策略来保持性能和可靠性。从本质上讲,此命令设置了一个复杂的多服务应用程序环境,该环境针对定义的配置进行了定制。
访问 RisingWave、Grafana 和 MinIO
成功启动服务后,您可以在 http://127.0.0.1:5691 访问 RisingWave 仪表板,查看集群的状态并管理流源、接收器和查询。

访问 MinIO Web 界面,网址为 http://127.0.0.1:9400。使用默认凭据 ( username: hummockadmin , password: hummockadmin ) 登录。您将看到已创建一个名为 hummock001 的存储桶。
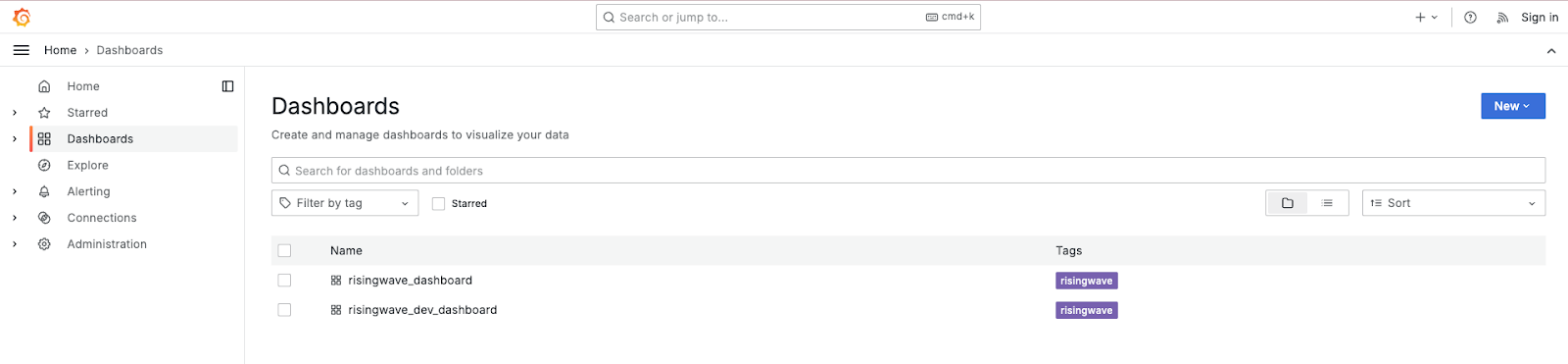
访问 Grafana http://127.0.0.1:3001/ 导航到左侧的“仪表板”菜单。找到 risingwave_dashboard .在此仪表板中,您可以访问多个内部指标,包括节点计数、内存使用情况、吞吐量和延迟。这些指标对于诊断和增强集群的性能很有价值。
执行 SQL
通过在终端窗口中运行以下命令连接到 psql RisingWave:
psql -h localhost -p 4566 -d dev -U root您现在已准备好使用此集成。下面的示例查询将帮助你开始在 Rising Wave 上执行 SQL。运行以下命令以创建名为 purchase records :
CREATE TABLE purchase_records (purchase_id int,product_id int,customer_id int,amount_spent real,purchase_date date
);运行以下命令,将数据插入到刚刚创建的表中:
INSERT INTO purchase_records (purchase_id, product_id, customer_id, amount_spent, purchase_date)
VALUES(1, 301, 3001, 120.5, '2023-05-10'),(2, 301, 3002, 150.0, '2023-05-10'),(3, 301, 3003, 80.0, '2023-05-10'),(4, 302, 3001, 220.2, '2023-06-15'),(5, 302, 3003, 110.0, '2023-06-15');从该表创建具有一些聚合的实例化视图,以进一步浏览数据:
CREATE MATERIALIZED VIEW product_spending_summary AS
SELECTproduct_id,AVG(amount_spent) AS average_spent,COUNT(amount_spent) AS total_purchases
FROMpurchase_records
GROUP BYproduct_id;通过运行以下 SQL 查询从具体化视图中选择所有内容,请查看编译的数据:
SELECT * FROM product_spending_summary;您可以在 http://127.0.0.1:9400 时再次使用 MinIO 进行检查,以查看您创建的 Materialized 视图和表中的对象是否已填充您的对象存储。
扩展本教程
将 RisingWave 与 MinIO 集成,为寻求构建和扩展实时分析应用程序的开发人员提供了强大的解决方案。这种组合提供了高效处理大量数据流所需的可靠性和可伸缩性。按照上述步骤,您可以设置一个利用 RisingWave 和 MinIO 优势的环境。与所有 Kubernetes 原生软件一样,如果您愿意,可以部署这种与 Kubernetes 的集成。无论您是运行复杂的查询还是管理庞大的数据集,这种服务组合都能确保您有能力应对现代数据处理的挑战,并确保您的组织为 AI 计划做好准备。
这篇关于针对 AI 优化数据湖仓一体:使用 MinIO 仔细了解 RisingWave的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








