联邦专题

【Python深度学习】联邦学习概述、实现技术和主流联邦学习方法
文章目录 联邦学习联邦学习的基本流程:联邦学习的优点:联邦学习的挑战:联邦学习的应用场景: 联邦学习是一种思想,而不是一个具体的技术联邦学习的思想包括:但要实现这一思想,通常需要借助多种**具体的技术**,包括但不限于: 主流的联邦学习方法1. **联邦平均算法(Federated Averaging,FedAvg)**2. **联邦优化算法(Federated Optimization,

联邦学习【分布式机器学习技术】【①各客户端从服务器下载全局模型;②各客户端训练本地数据得到本地模型;③各客户端上传本地模型到中心服务器;④中心服务器接收各方数据后进行加权聚合操作,得全局模型】
随着计算机算力的提升,机器学习作为海量数据的分析处理技术,已经广泛服务于人类社会。 然而,机器学习技术的发展过程中面临两大挑战: 一是数据安全难以得到保障,隐私数据泄露问题亟待解决;二是网络安全隔离和行业隐私,不同行业、部门之间存在数据壁垒,导致数据形成“孤岛”无法安全共享 ,而仅凭各部门独立数据训练的机器学习模型性能无法达到全局最优化。 为了解决以上问题,谷歌提出联邦学习(FL,feder

探索联邦学习:保护隐私的机器学习新范式
探索联邦学习:保护隐私的机器学习新范式 前言联邦学习简介联邦学习的原理联邦学习的应用场景联邦学习示例代码结语 前言 在数字化浪潮的推动下,我们步入了一个前所未有的数据驱动时代。海量的数据不仅为科学研究、商业决策和日常生活带来了革命性的变化,同时也带来了前所未有的挑战。尤其是数据隐私和安全问题,已经成为全球关注的焦点。 随着对个人隐私保护意识的增强,传统的集中式数据处理方

Hadoop联邦模式搭建
在Hadoop架构中提供了三类搭建方式,第一类是给测试或开发人员使用的伪分布式或单NN节点搭建方式,第二类是用来商用化并解决NN单点故障的HA搭建方式,第三类就是这里要说的联邦模式,它本身也是一种供给商用的模式,但是它的应用在国内不多,它是用来解决HA单ActionNN压力问题的,在技术顶设上,一个Hadoop集群内部同一时间只允许存在一个生效的NN,但是当你的数据量非常庞大,庞大到你的DataN

大数据技术之_07_Hadoop学习_HDFS_HA(高可用)_HA概述+HDFS-HA工作机制+HDFS-HA集群配置+YARN-HA配置+HDFS Federation(联邦) 架构设计
大数据技术之_07_Hadoop学习_HDFS_HA(高可用) 第8章 HDFS HA 高可用8.1 HA概述8.2 HDFS-HA工作机制8.2.1 HDFS-HA工作要点8.2.2 HDFS-HA手动故障转移工作机制8.2.3 HDFS-HA自动故障转移工作机制 8.3 HDFS-HA集群配置8.3.1 环境准备8.3.2 规划集群8.3.3 配置Zookeeper集群8.3.4 配置H

FL论文专栏|设备异构、异步联邦
论文:Asynchronous Federated Optimization(12th Annual Workshop on Optimization for Machine Learning) 链接 实现Server的异步更新。每次Server广播全局Model的时候附带一个时间戳,Client跑完之后上传将时间戳和Model同时带回来,Server收到某个Client的上传数据后马上更新,更

重磅资源!PyTorch的福音,用PyTorch 1.0进行教学的免费深度学习课程,来自idiap和瑞士洛桑联邦理工学院...
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 编译:ronghuaiyang 前戏 好东西就是要拿来分享的,今天给大家介绍一个非常好的免费深度学习的课程,该课程是由idiap研究所和瑞士洛桑联邦理工学院联合推出的,该课程的最大特点是使用PyTorch 1.0进行教学,也是目前为止我所看到的唯一使用PyTorch 1.0进行教学的,刚刚出炉还热乎的哦!该课程还提供了全套的PPT和课

如何配置Hadoop2.0HDFS的HA以及联邦使用QJM
配置过程详述 大家从官网下载的apache hadoop2.2.0的代码是32位操作系统下编译的,不能使用64位的jdk。我下面部署的hadoop代码是自己的64位机器上重新编译过的。服务器都是64位的,本配置尽量模拟真实环境。大家可以以32位的操作系统做练习,这是没关系的。关于基本环境的详细配置,大家可以观看我的视频,或者浏览吴超沉思录的相关文章。 在这里我们选
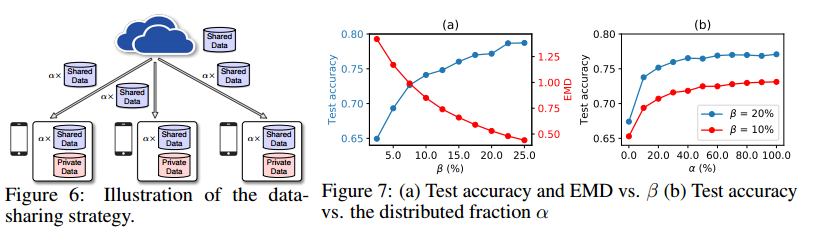
联邦学习论文阅读:2018 Federated learning with non-IID data
介绍 这是一篇2018年挂在arXiv上的文章,是一篇针对FL中数据Non-IID的工作。 作者发现,对于高度Non-IID的数据集,FedAvg的准确性下降了55%。 作者提出了可以用权重散度(weight divergence)来解释这种性能下降,这个权重散度用各client上的数据类别分布与总体分布之间的EMD(earth mover’s distance)来量化。 关于什么是EMD,

联邦学习的基本流程,联邦学习权重聚合,联邦学习权重更新
目录 联邦学习的基本流程是 S_t = np.random.choice(range(K), m, replace=False) 联邦学习权重聚合 model.state_dict() 联邦学习权重更新 下载数据集 https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz 联邦学
联邦学习中的非独立同分布Non-IID
在联邦学习Federated Learning中,出现的很高频的一个词就是Non-IID,翻译过来就是非独立同分布,这是一个来自于概率论与数理统计中的概念,下面我来简单介绍一下在Federated Learning中IID和Non-IID的概念。 何为IID(独立同分布) IID是数据独立同分布(Independent Identically Distribution,IID),它是指一组随机
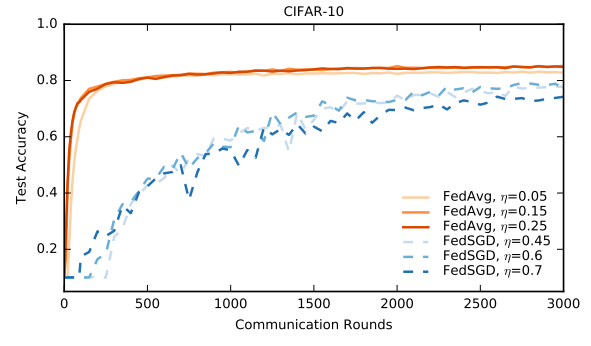
详解FedAvg:联邦学习的开山之作
FedAvg:2017年 开山之作 论文地址:https://proceedings.mlr.press/v54/mcmahan17a/mcmahan17a.pdf 源码地址:https://github.com/shaoxiongji/federated-learning 针对的问题:移动设备中有大量的数据,但显然我们不能收集这些数据到云端以进行集中训练,所以引入了一种分布式的机器学习方法,即
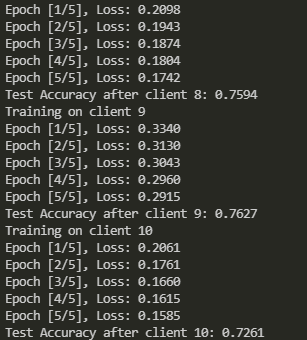
联邦学习在non-iid数据集上的划分和训练——从零开始实现
虽然网上已经有了很多关于Dirichlet分布进行数据划分的原理和方法介绍,但是整个完整的联邦学习过程还是少有人分享。今天就从零开始实现 加载FashionMNIST数据集 import torchfrom torchvision import datasets, transforms# 定义数据转换transform = transforms.Compose([transforms.To

联邦学习实现FedAVg算法
目录 PaddleFL PaddleFL概述 横向联邦学习(Horizontal Federated Learning, HFL) 纵向联邦学习(Vertical Federated Learning, VFL)
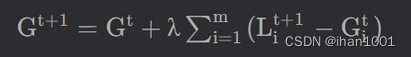
联邦学习【01】杨强第三章横向联邦学习复现
环境:有无gpu均可 anaconda环境:conda install pytorch1.13.1 torchvision0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia 具体安装命令结合自己的gpu的cuda版本 项目代码放在 https://gitee.com/ihan1001gitee https://gith

【差分隐私联邦学习从入门到发文】
差分隐私联邦学习从入门到发文 差分隐私联邦学习从入门到发文一、学习相关理论1. 差分隐私理论解读2. 联邦学习相关收敛性分析3. 差分隐私经典论文解读4. 联邦学习代码解读5. 深度学习相关代码网站 二、必读论文三、最新进展2023 差分隐私联邦学习从入门到发文 这是关于差分隐私联邦学习一份学习资料:有关理论知识、收敛性分析、代码、进展 一、学习相关理论 1. 差分隐私理论
HDFS Federation 联邦hdfs的实践与改进
HDFS Federation 为 HDFS 系统提供了 NameNode 横向扩容能力。然而作为一个已实现多年的解决方案,真正应用到已运行多年的大规模集群时依然存在不少的限制和问题。本文以实际应用场景出发,介绍了 HDFS Federation 在美团点评的实际应用经验。 一 背景 2015 年 10 月,经过一段时间的优化与改进,美团点评 HDFS 集群稳定性和性能有显著提升,保证了业务数

【科研基础】联邦学习
[1]. Kairouz, Peter, et al. “Advances and open problems in federated learning.” Foundations and trends® in machine learning 14.1–2 (2021): 1-210. [2]. Wang, Hui-Po, et al. “ProgFed: effective, communi
Webpack模块联邦:微前端架构的新选择
Webpack模块联邦(Module Federation)是Webpack 5引入的一项革命性特性,它彻底改变了微前端架构的实现方式。模块联邦允许不同的Web应用程序(或微前端应用)在运行时动态共享代码,无需传统的打包或发布过程中的物理共享。这意味着每个微应用可以独立开发、构建和部署,同时还能轻松地共享组件、库甚至是业务逻辑。 基础概念 容器应用(Container):作为微前端架构的宿主,
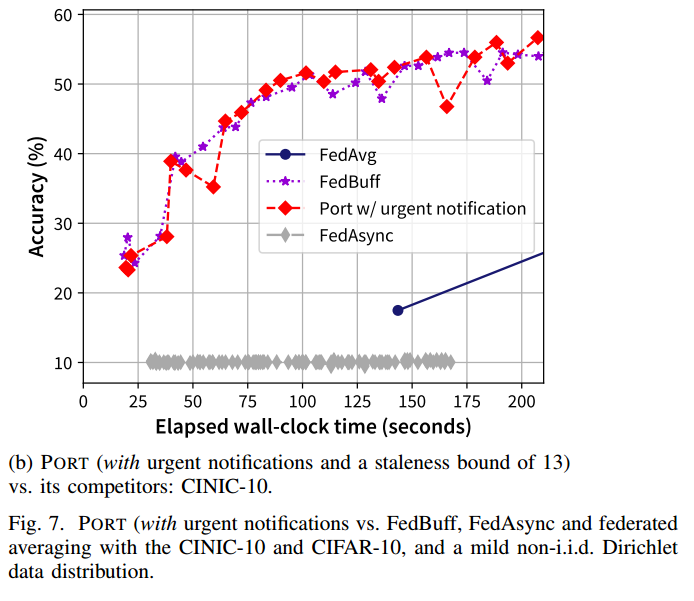
【论文笔记 | 异步联邦】PORT:How Asynchronous can Federated Learning Be?
1. 论文信息 How Asynchronous can Federated Learning Be?2022 IEEE/ACM 30th International Symposium on Quality of Service (IWQoS). IEEE, 2022,不属于ccf认定 2. introduction 2.1. 背景: 现有的异步FL文献中设计的启发式方法都只反映设计空间
陀螺产业区块链第六季 | 基于蒙正链-联邦学习数据协同平台
2020年4月,国家发改委在例行新闻发布会上宣布区块链被正式列为新型基础设施中的信息基础设施,自此区块链正式搭上新基建的“风口”。 与传统基础设施建设相比,新型基础设施建设更加侧重于突出产业转型升级的新方向,无论是5G还是区块链,都体现出加快推进产业高端化发展的大趋势。 但相较于新基建中的其他产业,区块链发展还稍显稚嫩。由于目前产业区块链的发展面临传统企业和区块链技术提供方信息不对称情形,拥有技

毕设学习:联邦学习梯度聚合加密算法
原本的加密算法大致思路:各个客户端上传梯度时进行加密,服务端直接用有扰乱的梯度当成真梯度来计算,这样一来谁也不知道谁是真梯度 为了避免原本的算法的一些问题,本文提出了加密-解密结构,并证明了这种结构带来的误差是可量化的,且en-decoder可以线下训练出来 首先要对输入的梯度做如下处理: 这样可以保证梯度被转化到一个固定的范围内,方便后面的encoder,decoder操作 这个
GPFL个性化联邦学习:同时学习全局和个性化特征信息
Global category embedding指的是将全局类别信息嵌入到模型中的过程。在机器学习和深度学习中,当处理具有多个类别的数据集时,可以使用全局类别嵌入来将类别信息编码到模型中,以帮助模型更好地理解和利用类别之间的关系。这可以帮助提高模型在分类、推荐和其他任务中的性能。通过将全局类别信息嵌入到模型中,可以使模型更好地理解和利用类别之间的相似性和差异性,从而提高模型的泛化能力和性能。
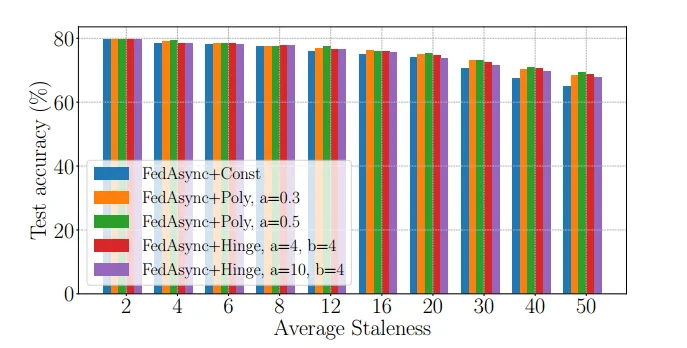
【论文笔记 | 异步联邦】Asynchronous Federated Optimization
论文信息 Asynchronous Federated Optimization,OPT2020: 12th Annual Workshop on Optimization for Machine Learning,不属于ccfa introduction 背景:联邦学习有三个关键性质 任务激活不频繁(比较难以达成条件):对于弱边缘设备,学习任务只在设备空闲、充电、连接非计量网络时执行通信