本文主要是介绍【论文笔记 | 异步联邦】Asynchronous Federated Optimization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文信息
Asynchronous Federated Optimization,OPT2020: 12th Annual Workshop on Optimization for Machine Learning,不属于ccfa
introduction
背景:联邦学习有三个关键性质
- 任务激活不频繁(比较难以达成条件):对于弱边缘设备,学习任务只在设备空闲、充电、连接非计量网络时执行
- 通信不频繁:边缘设备和远程服务器之间的连接可能经常不可用、缓慢或昂贵(就通信成本或电池电量使用而言)
- 非iid训练数据: 联邦学习不同设备上的数据不相交,因此可能代表来自总体的非相同分布的样本
挑战:系统异构导致的“掉队者”问题
不同设备的计算和通信能力不同,可能会有很多弱设备无法按时完成本地更新任务
解决的问题:
- 解决正则化的局部问题保证收敛性
- 使用加权平均更新全局模型,其中混合权值作为过时性的函数自适应设置 α
贡献点:
- 提出了新的异步联邦优化算法,给出了原型系统设计
- 证明了该方法对于一类受限的非凸问题的收敛性
- 提出了控制由异步引起的错误的策略。引入一个混合超参数 α,可以自适应地控制收敛速度和方差减少之间的权衡
- 实验表明提出的算法收敛速度快,并且在实际设置中通常优于同步联邦优化。
问题描述:System model/架构/对问题的形式化描述
对问题的形式化描述
符号定义

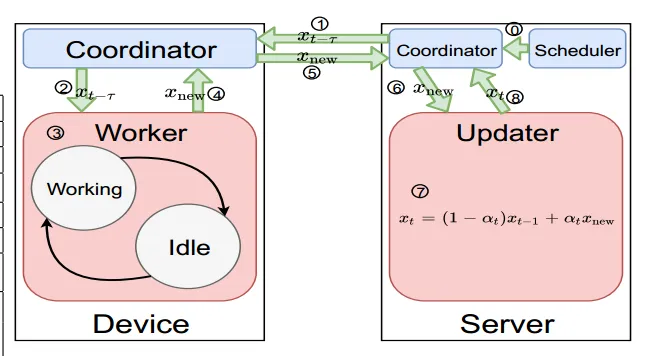
0:调度程序通过协调程序触发训练
1,2: worker通过coordinator从server接收模型xt−τ
3 :worker按照算法1计算本地更新。Worker可以在工作和空闲两种状态之间切换
4,5,6:worker通过协调器将本地更新的模型推送到服务器。协调器将5中接收到的模型排成队列,并将它们依次提供给6中的更新程序。
7、8:服务器更新全局模型,并使其准备好在协调器中读取。在系统中,1和5是异步并行运行的
t:当前的全局模型版本
t - τ:设备接收到的全局模型版本
τ:过时度
解决方法
执行流程:

t:当前的全局模型版本
τ:设备接收到的全局模型版本
t - τ:过时度
挑战问题怎么解决:
- 解决掉队者问题:允许异步聚合
- 利用
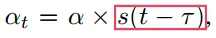
,调整 当前全局模型 与 从设备端接收到的模型 的 权重,完成对全局模型的更新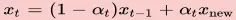
,目的是降低陈旧模型的权重,减少陈旧模型对全局模型的负面影响
s( )需要满足两个条件
- t = τ 时,模型是最新的,即 s(t-τ)=1
- 随着 t-τ 的增加, s(t-τ)减少 s( ) 可以设置成以下三种形式

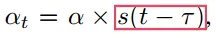
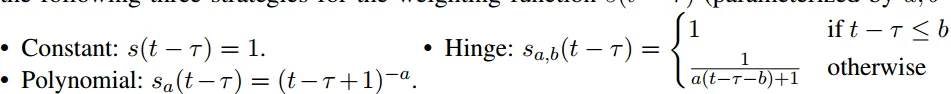
性能保证:
收敛性分析(略)
效果:重点是实验设计,每一部分实验在验证论文中的什么结论
实验设置
数据集:CIFAR-10 和 WikiText-2。训练集被划分为n = 100个设备。小批量分别为50个和20个。
Baseline:
- FedAvg:在每个epoch中,随机选择k = 10个设备启动本地更新
- 单线程SGD
- FedAsync,通过从均匀分布中随机采样陈旧度(t−τ)来模拟异步
每个实验重复10次,取平均值。
对比实验
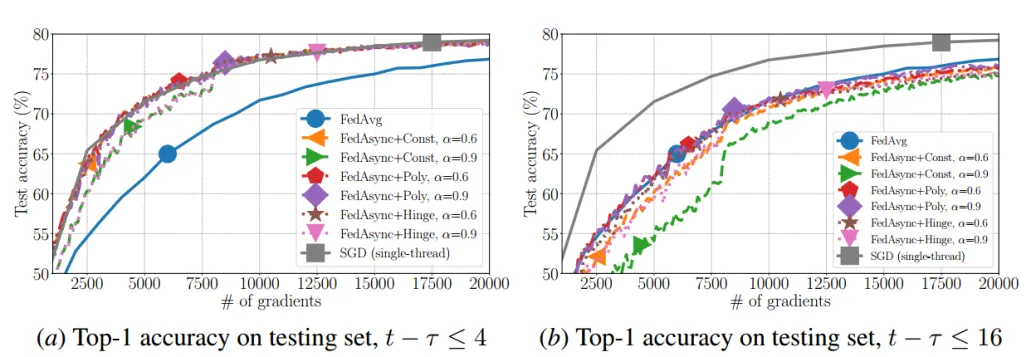
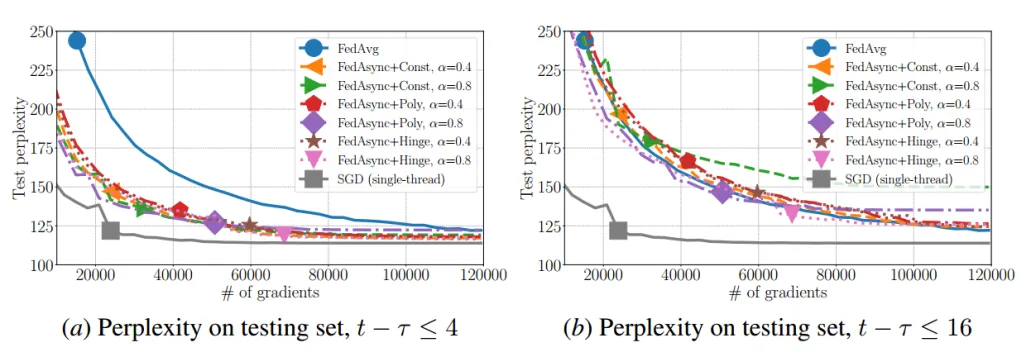
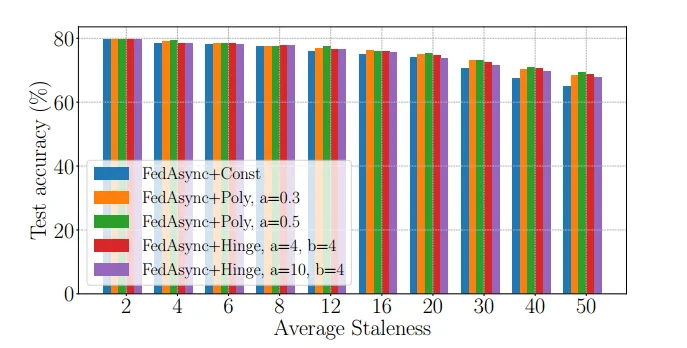
实验效果:
- FedAsync的收敛速度一般介于单线程SGD和fedavg之间。较大的α值和较小的陈旧度 使FedAsync更接近单线程SGD。较小的α和较大的陈旧度 使得FedAsync更接近fedavg。
- 根据经验,FedAsync通常对超参数不敏感。当偏差较大时,可以通过调整α来提高收敛性。如果没有自适应α,则α越小越好。对于自适应α,经验上的最佳选择是 FedAsync+Hinge。FedAsync+Poly和FedAsync+Hinge具有类似的性能。
- 与fedavg相比,FedAsync的性能与fedavg一样好,在大多数情况下甚至更好。当陈旧度较小时,FedAsync的收敛速度比fedag快得多。当陈旧度较大时,FedAsync仍然可以达到与fedag相似的性能。
(备选)自己的思考
异步 FL :一个FL生态中有一个Server,多个Device,其中不同device 的计算能力、通信资源以及本地数据集不同,导致device 进行本地模型训练所需的时间不同,有快有慢。传统FL 需要等待所有的device 完成本地模型训练后,server 端才会按照选定的策略(eg:加权平均)进行聚合。但是异步FL 不需要等待,只要涉及训练的device 中有一个完成训练,就可以上传到Server 端完成聚合。
问题: server 端 updater 顺次从 coordinater上获取 Xnew 进行模型更新,假设当最新的模型为 X3
,但其他模型都没训练完成时,全局模型再次更新为 X4,X3是会轮空还是? 思考:目前的论文大部分其实是半异步,就是 Server
端会等待一个固定时间 T 之后进行全局模型聚合,或者等待固定个数 n 个模型后进行聚合。而且一般情况下为了获得较好的模型,实验设定的
device 数都不会很少,基本不需要考虑这样的情况,也就是问题不存在 通过允许 Plato 代码得出, client 端和 fedavg
流程一致,只对算法进行修改 主要的修改在server
动机,通过什么方法解决,达到了什么效果,有什么可以改进的地方
论文对你的启发,包括但不限于解决某个问题的技术、该论文方法的优缺点、实验设计、源码积累等。
备注:
- 不是每一篇论文都有以上内容,但是尽可能按照以上思路读论文、总结论文。
- 注意用自己的话总结以上内容,不要整篇翻译论文,而且不推荐使用类似知云翻译这种软件读论文。建议直接读英文原文,有不理解或者不知道的词可以翻译记录。
- 读论文的过程中,一定要多问为什么,多考虑这个问题存不存在、这个方法能不能解决,不要盲目迷信论文作者。
- 读论文的目的在于调研本领域的研究内容,发现问题,提出自己的想法,刷论文数量没有意义,需要发现读过论文对自己研究的价值。
- 当发现论文中存在自己不了解的技术或者方法,首先进行调研,不要有畏难的心理,多掌握一门工具能帮助你解决自己的研究问题。
这篇关于【论文笔记 | 异步联邦】Asynchronous Federated Optimization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



