本文主要是介绍联邦学习论文阅读:2018 Federated learning with non-IID data,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
这是一篇2018年挂在arXiv上的文章,是一篇针对FL中数据Non-IID的工作。
作者发现,对于高度Non-IID的数据集,FedAvg的准确性下降了55%。
作者提出了可以用权重散度(weight divergence)来解释这种性能下降,这个权重散度用各client上的数据类别分布与总体分布之间的EMD(earth mover’s distance)来量化。
关于什么是EMD,gpt这样说:
EMD(Earth Mover’s Distance,即地球搬运距离)是一种度量两个分布之间差异的方法。其基本思想来源于土方工程,即计算将一个堆土变成另一个堆土所需的最小工作量。
具体来说,EMD用于度量两个概率分布之间的差异,特别是在多维空间中。假设有两个概率分布P和Q,它们分别由一组加权点组成,EMD计算的是将分布P转换为分布Q所需的最小代价。
计算EMD的一般步骤如下:
- 定义分布:两个分布P和Q分别由若干个点和其对应的权重(或质量)组成。
- 构建流量矩阵:确定从分布P的每个点到分布Q的每个点的流量(即将多少质量从一个点移动到另一个点)。
- 计算流动成本:每个点的流动成本通常是两个点之间的距离乘以流量。
- 优化流动方案:通过优化算法(如线性规划),找到总流动成本最小的方案,即EMD。
数学上,EMD可以被表述为一个线性规划问题。其目标函数是:
EMD ( P , Q ) = min ∑ i = 1 m ∑ j = 1 n f i j d i j \text{EMD}(P, Q) = \min \sum_{i=1}^m \sum_{j=1}^n f_{ij} d_{ij} EMD(P,Q)=min∑i=1m∑j=1nfijdij
其中,f_{ij}表示从分布P的第i个点到分布Q的第j个点的流量,d_{ij}表示这两个点之间的距离。约束条件包括:
- 从P的每个点流出的总流量不能超过该点的权重。
- 到达Q的每个点的总流量不能超过该点的权重。
- 所有流量的总和应等于两个分布总权重的较小值。
EMD在计算机视觉、图像处理和模式识别等领域中有广泛应用,特别是在图像检索中,用于比较不同图像的特征分布。
作者提出了一个策略用于解决Non-IID,那就是server来创建一小部分共享数据集来提升模型acc。这显然是一种centralization-accuracy的trade-off。
实验
作者用了三个数据集:MNIST、Cifar-10、Speech Commands dataset(一个语音数据集)划分出的KWS数据集。这三个数据集的output classes都是10。
数据集划分方面,做了三种划分:
- iid:均匀分配给10个client;
- non-iid(1):每个client只有一类的数据,总共10个client;
- non-iid(2):每个client有两类的数据,总共10个client;
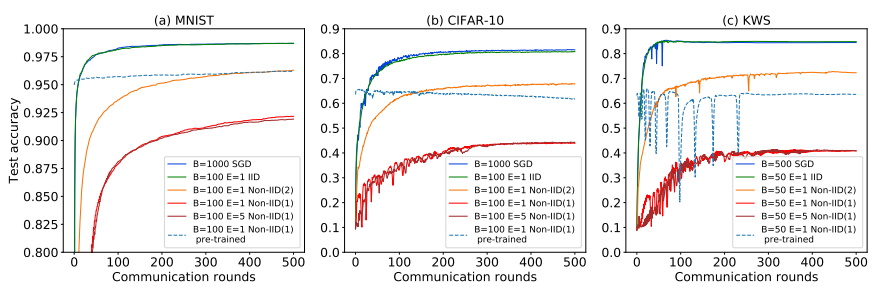
根据上图可知以下实验结论:
1、 IID数据下联邦学习和正常中心式的SGD训练结果基本一致;
2、 non-IID 会导致准确度下降,而且Non-IID(1)相对Non-IID(2)下降的更多,减少本地训练epoch增加通信频率可以一定程度降低损失,但是作用不大;
3、一个有意思的点是,用SGD预训练的模型刚刚开始结果就不错,但在CIFAR-10上在 non-IID 数据上训练还会降低精度;
分析
作者给出了权重散度weight divergence的定义公式:
weight divergence = ∣ ∣ w FedAvg − w SGD ∣ ∣ ∣ ∣ w SGD ∣ ∣ \text{weight divergence}=\frac{||w^{\text{FedAvg}}-w^{\text{SGD}}||}{||w^{\text{SGD}}||} weight divergence=∣∣wSGD∣∣∣∣wFedAvg−wSGD∣∣
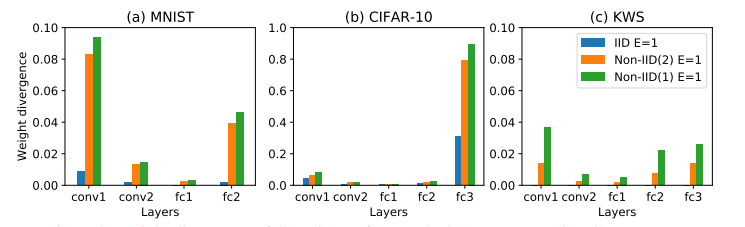
接下来,作者分析weight divergence分歧的根本原因是client的数据分布与总体数据分布之间的距离,这个距离可以用EMD来评估。
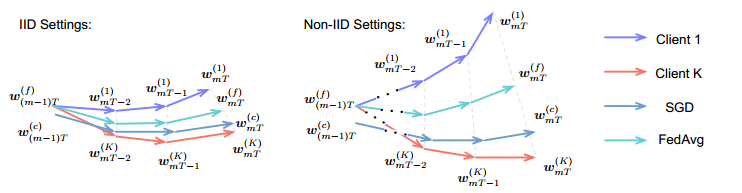
然后就是一顿数学推导,得到这样一个公式:
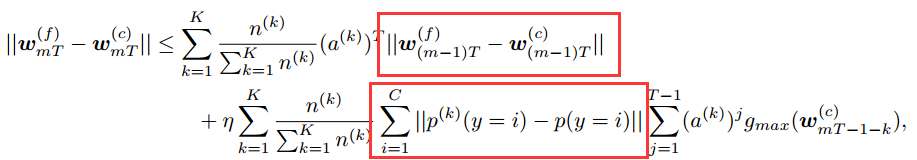
上图中圈出的两部分就是误差的两个来源,分别是:
- 之前累计的梯度误差;
- 本次迭代产生的分布误差;
此外,作者根据公式得出两个结论:
- 开始训练时,各client的初始化权重最好一样;
- EMD被定义为
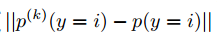 。
。
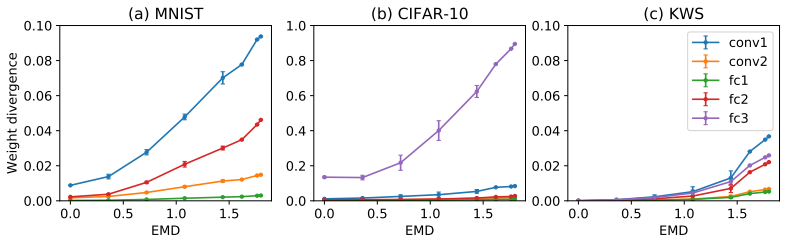
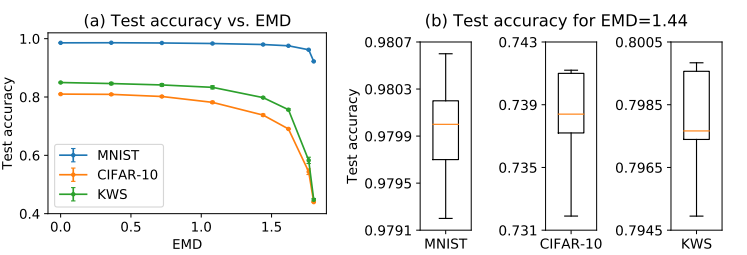
接下来,作者探究了EMD与weight divergence和test acc的关系:
改进方法
作者提出让server创建一个全局可共享的小部分数据集给各client。实验表明,仅用5%的全局数据,可以提高test acc约30%。
此外,server首次分发给client的模型可以是在这小部分数据集上预训练过的。
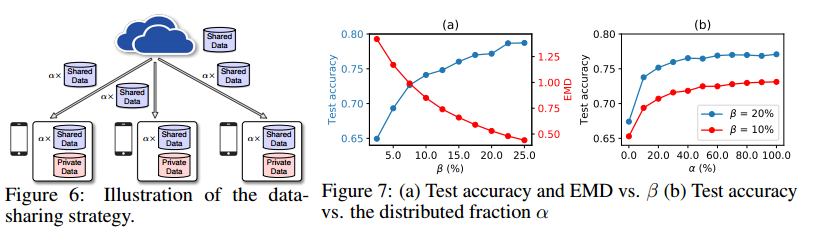
如上图所示,整个过程涉及到两个trade-off:
- test acc和 β = ∣ ∣ G ∣ ∣ ∣ ∣ D ∣ ∣ × 100 % \beta=\frac{||G||}{||D||}\times 100\% β=∣∣D∣∣∣∣G∣∣×100%的trade-off,其中G为全局可共享数据集的样本量,D为所有client的样本量和。
- test acc和 α \alpha α的tarde-off,其中 α \alpha α为server分给client的样本量与server全局可共享数据集的比值。
作者表示,这个策略只用于整个训练过程初始化的时候,所以通信成本不是主要问题,此外,全局可共享的数据集和client数据集是分开了,不会有隐私威胁。
这篇关于联邦学习论文阅读:2018 Federated learning with non-IID data的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







