本文主要是介绍详解FedAvg:联邦学习的开山之作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FedAvg:2017年 开山之作
论文地址:https://proceedings.mlr.press/v54/mcmahan17a/mcmahan17a.pdf
源码地址:https://github.com/shaoxiongji/federated-learning
针对的问题:移动设备中有大量的数据,但显然我们不能收集这些数据到云端以进行集中训练,所以引入了一种分布式的机器学习方法,即联邦学习Federal Learning。在FL中,server将全局模型下放给各client,client利用本地的数据去训练模型,并将训练后的权重上传到server,从而实现全局模型的更新。
论文贡献:
- 提出了联邦学习这个研究方向,简单来说就是从分散的存储于各设备的数据中训练模型;
- 提出了FedAvg算法;
- 通过实验验证了FedAvg的可靠性;
总结一下就是,本文提出了FedAvg算法,这种算法融合了client上的局部随机梯度下降和server上的模型平均。作者用该算法做了不少实验,结果表明FedAvg对于unbalanced且non-iid的数据有很好的鲁棒性,并且使得在非数据中心存储的数据上进行深度网络训练所需的通信轮次减少了好几个数量级。
算法介绍:
- 联邦随机梯度下降算法FedSGD:
设定固定的学习率η,对K个client的数据计算损失梯度:
g k = ▽ F k ( w t ) g_k=\bigtriangledown F_k(w_t) gk=▽Fk(wt)
server将聚合每个服务器计算的梯度,以此来更新模型参数:
w t + 1 ← w t − η ∑ k = 1 K n k n g k = w t − η ▽ f ( w t ) w_{t+1}\leftarrow w_t-\eta\sum\limits_{k=1}^K\frac{n_k}{n}g_k=w_t-\eta\bigtriangledown f(w_t) wt+1←wt−ηk=1∑Knnkgk=wt−η▽f(wt)
- 联邦平均算法FedAvg:
在client进行局部模型的更新:
w t + 1 k ← w t − η g k w_{t+1}^k\leftarrow w_t-\eta g_k wt+1k←wt−ηgk
server对每个client更新后的权重进行加权平均:
w t + 1 ← ∑ k = 1 K n k n w t + 1 k w_{t+1}\leftarrow \sum_{k=1}^K \frac{n_k}{n}w_{t+1}^k wt+1←∑k=1Knnkwt+1k
注意,在这里每个client可以在本地独立地多次更新本地权重,然后将更好的权重参数发给server进行加权平均。这样做的好处是不用每更新一次就去聚合,这大大减少了通信量。
FedAvg的计算量与3个参数有关:
- C:每轮训练选择client的比例,每一轮通信时只选择C*K个client;(K为client总数)
- E:每个client更新本地权重时,在本地数据集上训练E轮;
- B:client更新权重时,每次梯度下降所使用的数据量,即本地数据集的batch size;
对于一个拥有 n k n_k nk个数据样本的client,每轮通信本地参数的更新次数为:
u k = E × n k B u_k=E\times\frac{n_k}{B} uk=E×Bnk
所以我们可知,FedSGD只是FedAvg的一个特例,即当参数 E = 1 , B = ∞ E=1,B=\infty E=1,B=∞时,FedAvg等价于FedSGD。注: B = ∞ B=\infty B=∞意味着batch size大小就是本地数据集大小。
下面为FedAvg的算法流程图:

实验设计与实现:
Q1:在训练伊始,需不需要对模型进行统一初始化?
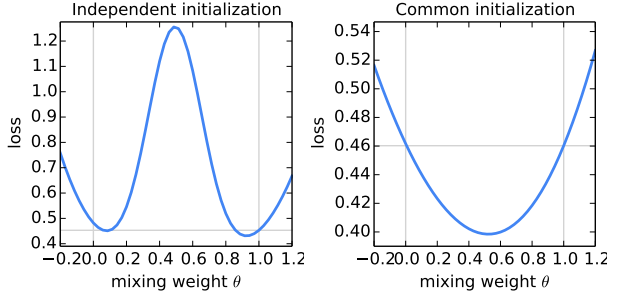
可见,采用不同的初始化参数进行模型平均,模型性能比两个父模型都差(左图);而统一初始化后,对模型的平均可以显著减少整个训练集的loss,模型性能优于两个父模型(右图)。
该结论是实现FL的重要支持,在每一轮通信时,server有必要发布全局模型,使各client采用相同的参数在本地数据集上进行训练,可以有效减少loss。
Q2:数据集怎么设置?
原文中主要研究了MNIST数据集和一个莎士比亚作品集构建的数据集,但我们在这里主要关注MNIST数据集和Cifar-10数据集,这两个数据集也是以后FL领域工作最常用的。
在模型选择方面,作者选择了多层感知机MLP和卷积神经网络CNN。
在数据集划分方面,作者假设有100个client,对于MNIST数据集,进行了iid和non-iid两种划分:
- MNIST-iid:数据随机打乱分给100个client,每个client得到600个样例;
- MNIST-non-iid:按数字label将数据集划分为200个大小为300的碎片,每个client两个碎片,意味着每个client至多只能获得两种label的样例;
对于Cifar-10数据集,做了iid划分。
Q3:实验咋做的?
作者指出,相比于传统模式下训练模型时计算开销为主通信开销较小的情况,在FL中,通信开销才是大头,因此减少通信开销才是我们需要关注的,作者提出可以通过加大计算以减少训练模型所需的通信轮数。作者提出主要有两种方法:提高并行度、增加每个client的计算量。
而FedAvg的计算量在前面我们也给出过,再来看一下:
u k = E × n k B u_k=E\times\frac{n_k}{B} uk=E×Bnk
提高并行度:固定参数E,对C和B进行讨论。注:此处C=0时,算法也会选择一个client参与,详见上面的算法流程图。
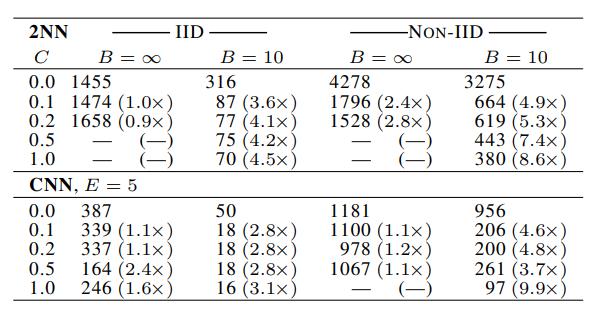
- 当 B = ∞ B=\infty B=∞时,增加client的比例C,效果提升的优势较小;
- 当 B = 10 B=10 B=10时,效果显著改善了,特别是在non-iid情况下;
- 当 B = 10 , C ≥ 10 B=10,C\geq10 B=10,C≥10时,收敛速度明显改进,当client到一定数量后,收敛速度增加也不明显了;
增加每个client的计算量:根据公式,可以通过增加E或者减小B实现。

- 每个通信轮次内增加更多的本地SGD可以显著降低通信成本;
- 对于unbalanced-non-iid的莎士比亚数据集减少的通信轮数更多,推测可能某些client有相对较大的本地数据集,这种情况下增加了本地训练的价值;
Q4:FedAvg VS FedSGD?
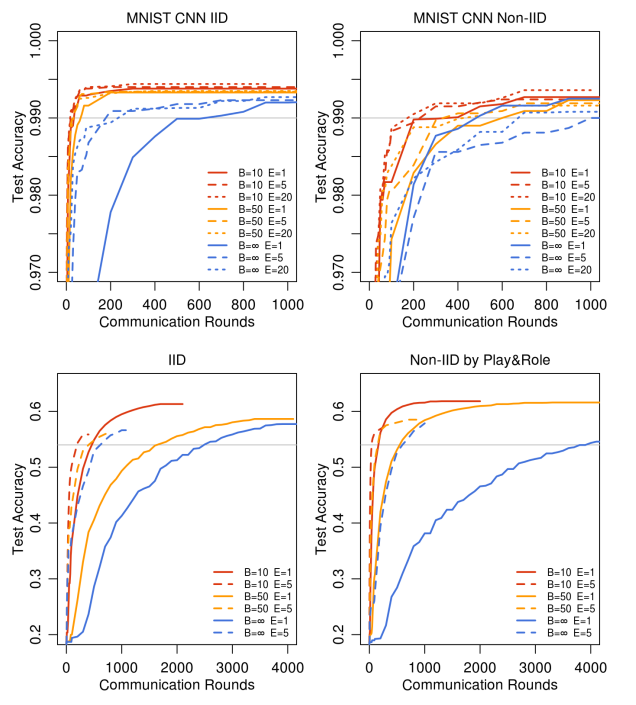
蓝色实现即为FedSGD。由图可知,FedAvg相比FedSGD不仅降低通信轮数,还具有更高的测试精度。推测是平均模型产生了类似Dropout的正则化效益。
Q5:加大每个client的计算量会不会导致过拟合?

加大每个client的计算量(主要体现在加大E),确实可能导致训练损失停滞或发散。所以在实际应用时,在训练后期减少各client的E,或者在loss有震荡的苗头时即刻停止,这样做有助于收敛。
Q6:在Cifar-10数据集上的表现如何?
如下图所示:

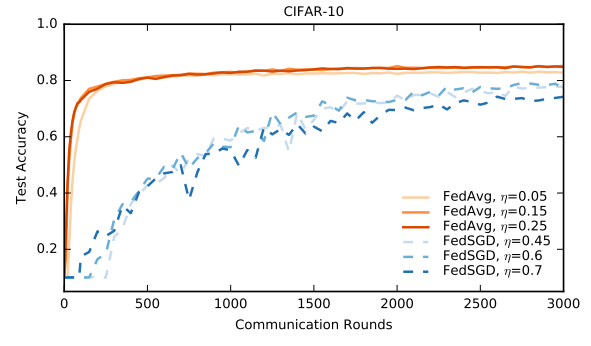
针对第一张图的一点吐槽,你去拿分布式深度学习去pk单机上的深度学习,去比通信轮数,这不是太不公平了。。。
总结展望:
作者证明了FL在实践中是可行的,能够用相对较少的通信轮数训练出高质量的模型。并且提出未来的一个方向就是通过差分隐私、安全多方技术等隐私保护技术去组合FL以提供隐私保护。
这篇关于详解FedAvg:联邦学习的开山之作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





