本文主要是介绍【Iceberg学习四】Evolution和Maintenance在Iceberg的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Evolution
Iceberg 支持就底表演化。您可以像 SQL 一样演化表结构——即使是嵌套结构——或者当数据量变化时改变分区布局。Iceberg 不需要像重写表数据或迁移到新表这样耗费资源的操作。
例如,Hive 表的分区布局无法更改,因此从每日分区布局变更到每小时分区布局需要新建一个表。而且因为查询依赖于分区,所以必须为新表重写查询。在某些情况下,即使是像重命名一个列这样简单的变化要么不被支持,要么可能导致数据正确性问题。
Schema evolution(Schema演变)
Iceberg 支持以下模式演变更改:
- 添加 – 在表中或嵌套结构中添加一个新列
- 删除 – 从表中或嵌套结构中移除一个已有的列
- 重命名 – 重命名一个已有的列或嵌套结构中的字段
- 更新 – 扩展列、结构字段、映射键、映射值或列表元素的类型
- 重新排序 – 改变列或嵌套结构中字段的顺序
Iceberg 的架构更新是元数据更改,因此不需要重写任何数据文件来执行更新。
请注意,映射键不支持添加或删除会改变等值性的结构字段。
Correctness(正确性)
Iceberg 保证模式演化更改是独立的,没有副作用,且无需重写文件:
- 添加的列从不从另一个列读取现有值。
- 删除列或字段不会改变任何其他列中的值。
- 更新列或字段不会改变任何其他列中的值。
- 改变结构中列或字段的顺序不会改变与列或字段名相关联的值。
Iceberg 使用唯一的 ID 来跟踪表中的每一列。当您添加列时,它会被分配一个新的 ID,所以现有数据绝不会被错误使用。
- 按名称跟踪列的格式可能会在重用名称时无意中“取消删除”一个列,这违反了规则 #1。
- 按位置跟踪列的格式不能删除列而不改变用于每列的名称,这违反了规则 #2。
Iceberg 表的分区可以在现有表中更新,因为查询不会直接引用分区值。
当您演化一个分区规范时,使用早期规范编写的旧数据保持不变。新数据使用新的规范在新的布局中编写。每个分区版本的元数据分别保留。因此,当您开始编写查询时,您会得到分割规划。这是每个分区布局使用它为特定分区布局派生的过滤器分别计划文件的地方。这里有一个人为示例的视觉表示:
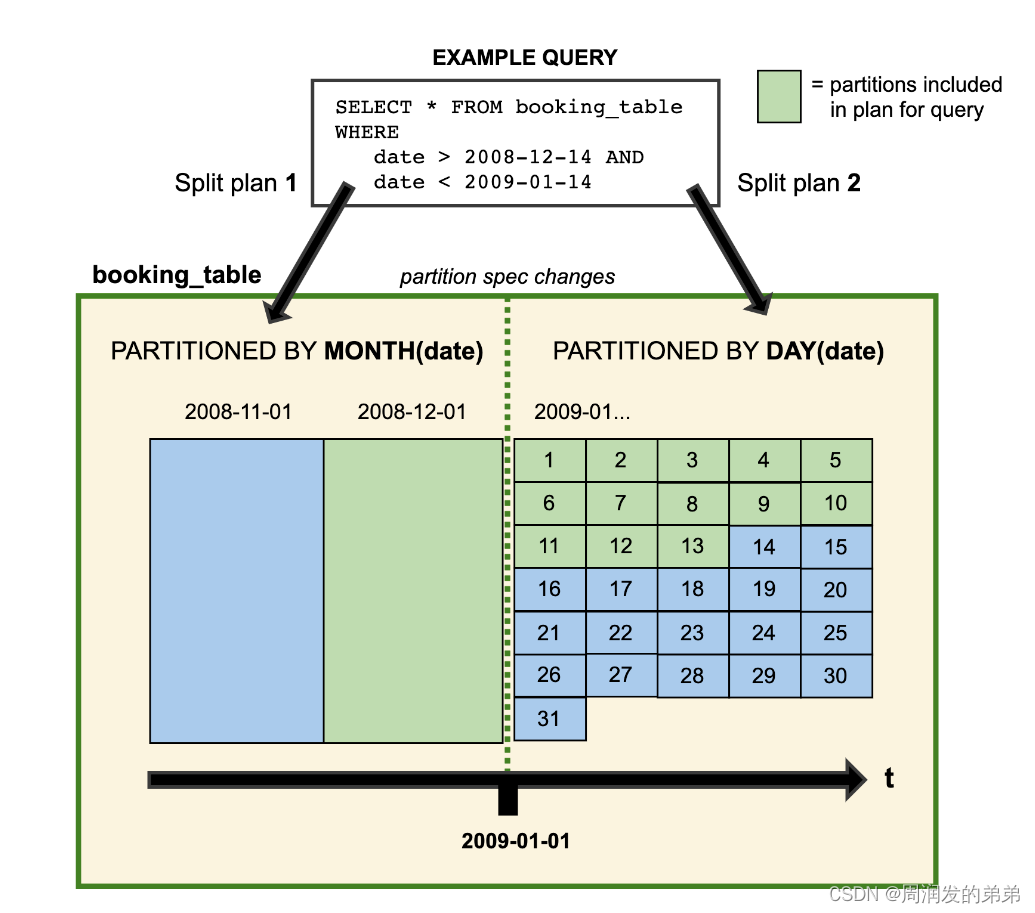
2008年的数据按月分区。从2009年开始,表更新,数据改为按天分区。两种分区布局能够在同一张表中共存。
Iceberg 使用隐藏分区,所以您不需要为了快速查询而编写特定分区布局的查询。相反,您可以编写选择您需要的数据的查询,Iceberg 会自动剪除不包含匹配数据的文件。
分区演化是一个元数据操作,并不会急切地重写文件。
Iceberg 的 Java 表 API 提供了 updateSpec API 来更新分区规范。例如,以下代码可以用来更新分区规范,添加一个新的分区字段,该字段将 id 列的值分成 8 个桶,并移除现有的分区字段 category:
Table sampleTable = ...;
sampleTable.updateSpec().addField(bucket("id", 8)).removeField("category").commit();
Spark 通过其 ALTER TABLE SQL 语句支持更新分区规范,更多细节请参见 Spark SQL。
Sort order evolution
与分区规范类似,Iceberg 的排序顺序也可以在现有表中更新。当您更改排序顺序时,用早期排序顺序写入的旧数据保持不变。当排序成本过高时,引擎总是可以选择以最新的排序顺序或未排序的方式写入数据。
Iceberg 的 Java 表 API 提供了 replaceSortOrder API 来更新排序顺序。例如,以下代码可用于创建一个新的排序顺序,其中 id 列按升序排列,null 值排在最后,而 category 列按降序排列,null 值排在最前:
Table sampleTable = ...;
sampleTable.replaceSortOrder().asc("id", NullOrder.NULLS_LAST).dec("category", NullOrder.NULL_FIRST).commit();
Spark 支持通过其 ALTER TABLE SQL 语句更新排序顺序,更多细节请参见 Spark SQL 文档。
Maintenance(维护)
Expire Snapshots(过期快照)
对 Iceberg 表的每次写入都会创建一个新的快照,或者说是表的一个新版本。快照可以用于时光旅行查询,或者可以将表回滚到任何有效的快照。
快照会累积,直到通过 expireSnapshots 操作将其过期。建议定期过期快照,以删除不再需要的数据文件,并保持表元数据的大小较小。
这个例子将过期所有超过1天的快照:
Table table = ...
long tsToExpire = System.currentTimeMillis() - (1000 * 60 * 60 * 24); // 1 day
table.expireSnapshots().expireOlderThan(tsToExpire).commit();
还有一个 Spark 操作,可以并行运行大型表的过期处理:
Table table = ...
SparkActions.get().expireSnapshots(table).expireOlderThan(tsToExpire).execute();
过期旧快照会将它们从元数据中移除,因此它们将不再可用于时光旅行查询。
备注:数据文件直到不再被可能用于时光旅行或回滚的快照引用时才会被删除。定期过期快照会删除不再使用的数据文件。
Remove old metadata files
Iceberg 使用 JSON 文件来跟踪表的元数据。每一次对表的更改都会生成一个新的元数据文件,以提供原子性。
默认情况下,旧的元数据文件会被保留以供历史记录。那些被流作业频繁提交的表可能需要定期清理元数据文件。
要自动清理元数据文件,请在表属性中设置 write.metadata.delete-after-commit.enabled=true。这将保留一些元数据文件(最多到 write.metadata.previous-versions-max),并且在每次创建新文件后删除最旧的元数据文件。
属性 描述
write.metadata.delete-after-commit.enabled 是否在每次表提交后删除旧的跟踪元数据文件
write.metadata.previous-versions-max 保留的旧元数据文件的数量
请注意,这只会删除在元数据日志中跟踪的元数据文件,不会删除孤立的元数据文件。例如:当 write.metadata.delete-after-commit.enabled=false 且 write.metadata.previous-versions-max=10 时,在100次提交后,将会有10个跟踪的元数据文件和90个孤立的元数据文件。配置 write.metadata.delete-after-commit.enabled=true 和 write.metadata.previous-versions-max=20 不会自动删除元数据文件。当达到 write.metadata.previous-versions-max=20 时,跟踪的元数据文件将再次被删除。
有关更多详细信息,请参阅表写入属性。
备注
-
在任何写入操作完成之前,使用比预期完成时间短的保留间隔来删除孤立文件是危险的,因为如果正在进行的文件被认为是孤立的并被删除,可能会破坏表。默认的间隔是3天。
-
Iceberg 在确定哪些文件需要被移除时,使用路径的字符串表示形式。在一些文件系统上,路径随时间改变可能会变化,但它仍然代表同一个文件。例如,如果你更改了 HDFS 集群的权限,那么在创建期间使用的旧路径 URL 将不会与当前列表中出现的那些匹配。当运行 RemoveOrphanFiles 时,这将导致数据丢失。请确保你的 MetadataTables 中的条目与 Hadoop FileSystem API 列出的那些相匹配,以避免意外删除。
Optional Maintenance
一些表需要额外的维护。例如,流查询可能会产生小的数据文件,这些文件应该被整合到更大的文件中。同时,有些表可以通过重写清单文件来受益,以便更快地定位查询所需的数据。
Compact data files
Iceberg 跟踪表中的每个数据文件。更多的数据文件意味着在清单文件中存储了更多的元数据,而小数据文件则导致了不必要的元数据量和由于打开文件的成本而降低了查询效率。
Iceberg 可以使用 Spark 并行地通过 rewriteDataFiles 操作来压缩数据文件。这将把小文件合并成大文件,以减少元数据开销和运行时打开文件的成本。
Table table = ...
SparkActions.get().rewriteDataFiles(table).filter(Expressions.equal("date", "2020-08-18")).option("target-file-size-bytes", Long.toString(500 * 1024 * 1024)) // 500 MB.execute();
文件元数据表对于检查数据文件的大小以及确定何时压缩分区非常有用。
Rewrite manifests(重写分区)
Iceberg 利用其清单列表和清单文件中的元数据来加速查询计划并剪除不必要的数据文件。元数据树功能类似于对表数据的索引。
元数据树中的清单会按照它们被添加的顺序自动压缩,当写入模式与读取过滤器对齐时,这使得查询更快。例如,按小时分区写入数据,随着数据到来即时写入,这与时间范围查询过滤器是对齐的。
当表的写入模式与查询模式不对齐时,可以通过 rewriteManifests 或使用 Spark 进行并行重写的 rewriteManifests 操作,重写元数据以将数据文件重新分组到清单中。
此示例重写小的清单,并按照第一个分区字段对数据文件进行分组。
Table table = ...
SparkActions.get().rewriteManifests(table).rewriteIf(file -> file.length() < 10 * 1024 * 1024) // 10 MB.execute();
这篇关于【Iceberg学习四】Evolution和Maintenance在Iceberg的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



