本文主要是介绍数据湖Iceberg、Hudi和Paimon比较,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.社区发展现状
| 项目 | Apache Iceberg | Apache Hudi | Apache Paimon |
|---|---|---|---|
| 开源时间 | 2018/11/6 | 2019/1/17 | 2023/3/12 |
| License | Apache-2.0 | Apache-2.0 | Apache-2.0 |
| Github Watch | 148 | 1.2k | 70 |
| Github Star | 5.3k | 4.9k | 1.7k |
| Github Fork | 1.9k | 2.3k | 702 |
| Github issue(Open) | 898 | 481 | 263 |
| Github issue(closed) | 2054 | 2410 | 488 |
| Github Open PR(Open) | 565 | 449 | 82 |
| Github Open PR(Closed) | 6240 | 7378 | 2049 |
| Committers | 454 | 436 | 131 |
| Releases | 17 | 16 | 3 |
| Release Latest | Apache Iceberg 1.4.3 | 0.14.1 Release | Release 0.6 |
(以上数据为2024年2月21日)
可见Apache iceberg和Apache hudi不相伯仲,Apache Paimon成立时间较晚。
Uber的工程师分享了大量Hudi的技术细节和内部方案落地,研究官网的近10个PPT已经能较为轻松理解内部细节,此外国内的小伙伴们也在积极地推进社区建设,提供了官方的技术公众号和邮件列表周报。
Iceberg 相对会平静一些,社区的大部分讨论都在 Github 的 issues 和 pull request 上,邮件列表的讨论会少一点,不少有价值的技术文档要仔细跟踪 issues 和 PR 才能看到,这也许跟社区核心开发者的风格有关。
Paimon 项目的committers可以看出主要由国人发起和主导,具备更好的本地化支持。
2.功能比较
| 对比项 | Apache Iceberg | Apache Hudi | Apache Paimon |
|---|---|---|---|
| update/delete | YES | YES | YES |
| 文件合并 | Manually | Automatic | Automatic |
| 历史数据清理 | Manually | Automatic | Automatic |
| 文件格式 | parquet,avro,orc | parquet,avro | parquet,avro,orc |
| 计算引擎 | Hive/Spark/Presto/Flink/Impala /Trino等 | Hive/Spark/Presto/Flink/Impala /Trino等 | Hive/Spark/Presto/Flink /Trino |
| 存储引擎 | HDFS/S3 | HDFS/S3/OBS/ALLUXIO/Azure | HDFS/S3/OSS |
| SQL DML | YES | YES | YES |
| ACID transaction | YES | YES | YES |
| 索引 | NO | YES | YES |
| 可扩展的元数据存储 | YES | YES | YES |
3.ACID和隔离级别支持
| 对比项 | Apache Iceberg | Apache Hudi | Apache Paimon |
|---|---|---|---|
| ACID Support | YES | YES | YES |
| Isolation Level | Write Serialization | Snapshot Isolation | Snapshot Isolation |
| Concurrent Multi-Writers | YES | YES | YES |
| Time travel | YES | YES | YES |
对于数据湖来说,三种隔离分别代表。
Serialization:所有的 reader 和 writer 都必须串行执行;
Write Serialization: 多个 writer 必须严格串行,reader 和 writer 之间则可以同时跑;
Snapshot Isolation: 如果多个 writer 写的数据无交集,则可以并发执行;否则只能串行。Reader 和 writer 可以同时跑。
综合起来看,Snapshot Isolation 隔离级别的并发性是相对比较好的。
4.Schema变更支持
| 对比项 | Apache Iceberg | Apache Hudi | Apache Paimon |
|---|---|---|---|
| Schema Evolution | ALL | back-compatible | back-compatible |
| Self-defined schema object | YES | NO(spark-schema) | NO(我理解,不准确) |
Schema Evolution:指schema变更的支持情况,我的理解是hudi仅支持添加可选列和删除列这种向后兼容的DDL操作,而其他方案则没有这个限制。
Paimon支持有限的schema变更。目前,框架无法删除列,因此 DROP 的行为将被忽略,RENAME 将添加新列,列类型只支持从短到长或范围更广的类型。
Self-defined schema objec:指数据湖是否自定义schema接口,以期跟计算引擎的schema解耦。这里iceberg是做的比较好的,抽象了自己的schema,不绑定任何计算引擎层面的schema。
在Hudi 0.11.0版本中,针对Spark 3.1、Spark 3.2版本增加了schema功能的演进。如果启用 set hoodie.schema.on.read.enable=true以后,我们可以对表列和对表进行一系列的操作。列的变更(增加、删除、重命名、修改位置、修改属性),表的变更(重命名、修改属性) 等。
5.其它功能
| 对比项 | Apache Iceberg | Apache Hudi | Apache Paimon |
|---|---|---|---|
| One line demo | Not Good | Medium | Good |
| Python Support | YES | NO | NO(不确定) |
| File Encryption | YES | NO | NO |
| Cli Command | NO | YES | YES |
One line demo:指的是,示例demo是否足够简单,体现了方案的易用性,Iceberg稍微复杂一点(我认为主要是Iceberg自己抽象出了schema,所以操作前需要定义好表的schema)。做得最好的其实是delta,因为它深度跟随spark易用性的脚步。
Python Support:Python支持,很多基于数据湖之上做机器学习的开发者会考虑的问题,Iceberg比较做的好。
File Encryption:出于数据安全的考虑,Iceberg还提供了文件级别的加密解密功能,这是其他方案未曾考虑到的一个比较重要的点。
Cli Command:命令行
6.商业公司支持
Apache Iceberg
Iceberg 在国内的厂商非常多,腾讯一马当先,是贡献者数量最多的团队,国内的字节 、网易也紧随其后,相比腾讯 Iceberg 和 Hudi 通吃的战略,阿里在 Iceberg 的投入就少了非常多,国外的贡献者也非常多,包括 Netflix、Apple 等等
Apache Hudi
Hudi 在国内的应用很广,包括国内的大厂阿里巴巴、腾讯、字节跳动和华为,国外的话主要是 Uber 和 Amazon。
Apache Paimon
2023 年 3 月 12 日,Flink Table Store 项目顺利通过投票,正式进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。进入孵化器后,Paimon 得到了众多的关注,包括 阿里云、字节跳动、Bilibili、汽车之家、蚂蚁 等多家公司参与到 Apache Paimon 的贡献,也得到了广大用户的使用。
7.性能比较
7.1 Iceberg和Hudi比较
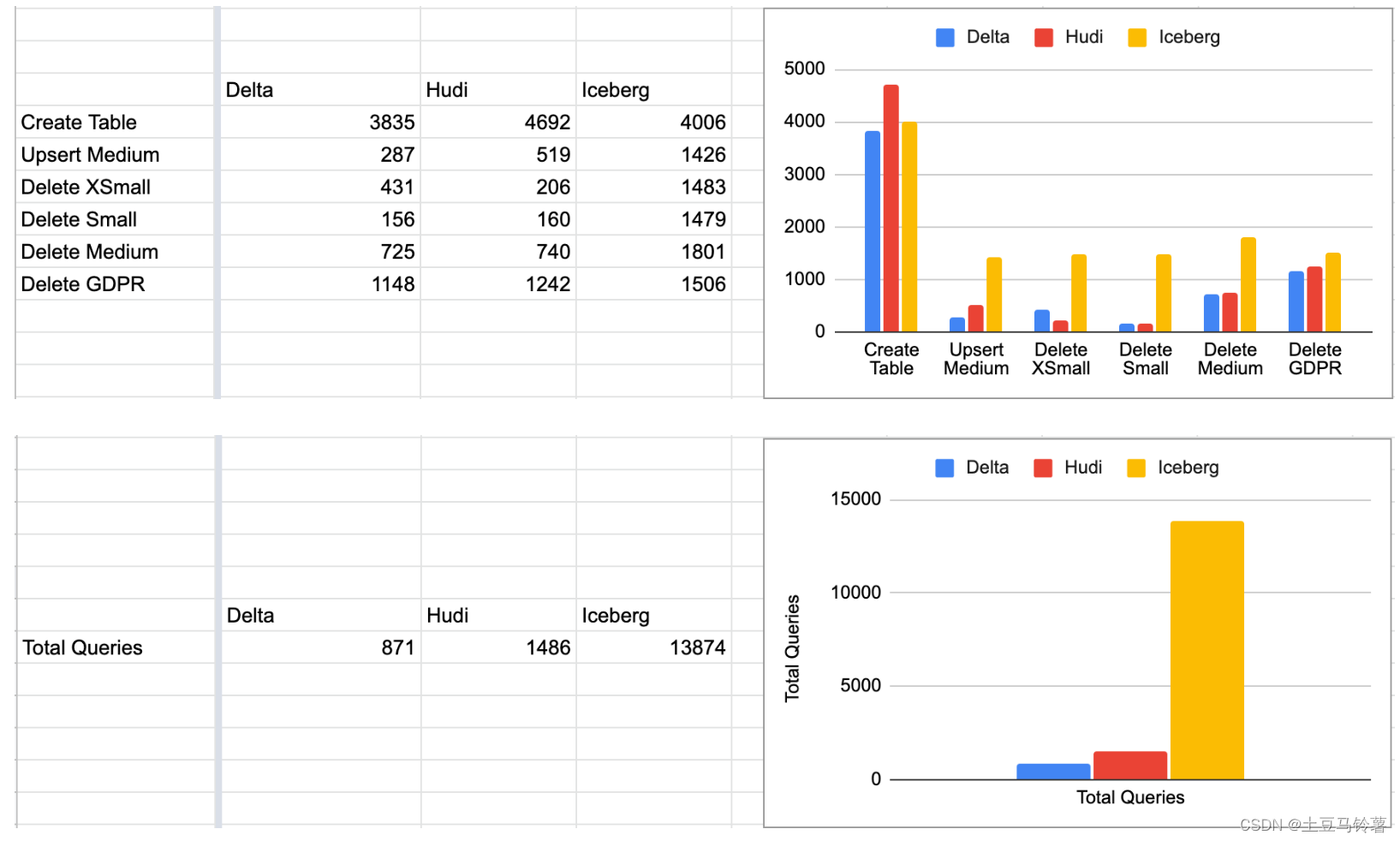
Brooklyn Data在 2022 年 11 月发布 Delta 与 Iceberg 的基准测试结果:Setting the Table: Benchmarking Open Table Formats
Onehouse 添加了 Apache Hudi,并在Brooklyn Github 代码库中发布了代码:https://github.com/brooklyn-data/delta/pull/2
测试结果见上图所示,Delta 和 Hudi 不相上下,Iceberg 落后并且还有一定的差距。
注意:在运行 TPC-DS 基准比较 Hudi、Delta 和 Iceberg 时,需要记住的一个关键点是,默认情况下 Delta + Iceberg 是针对仅追加的工作负载进行优化的,而 Hudi 默认情况下是针对可变工作负载进行优化的。默认情况下,Hudi 使用 "upsert "写模式,与插入相比,这种写模式自然会产生写开销。benchmarks 这个东西还是要以实际的业务场景测试为好,benchmarks 只能作为参考。
7.2 Hudi和Paimin比较
(1) Flink中文社区对Hudi和Paimon进行了性能比较,详细过程见:构建 Streaming Lakehouse:使用 Paimon 和 Hudi 的性能对比
直接说结论:
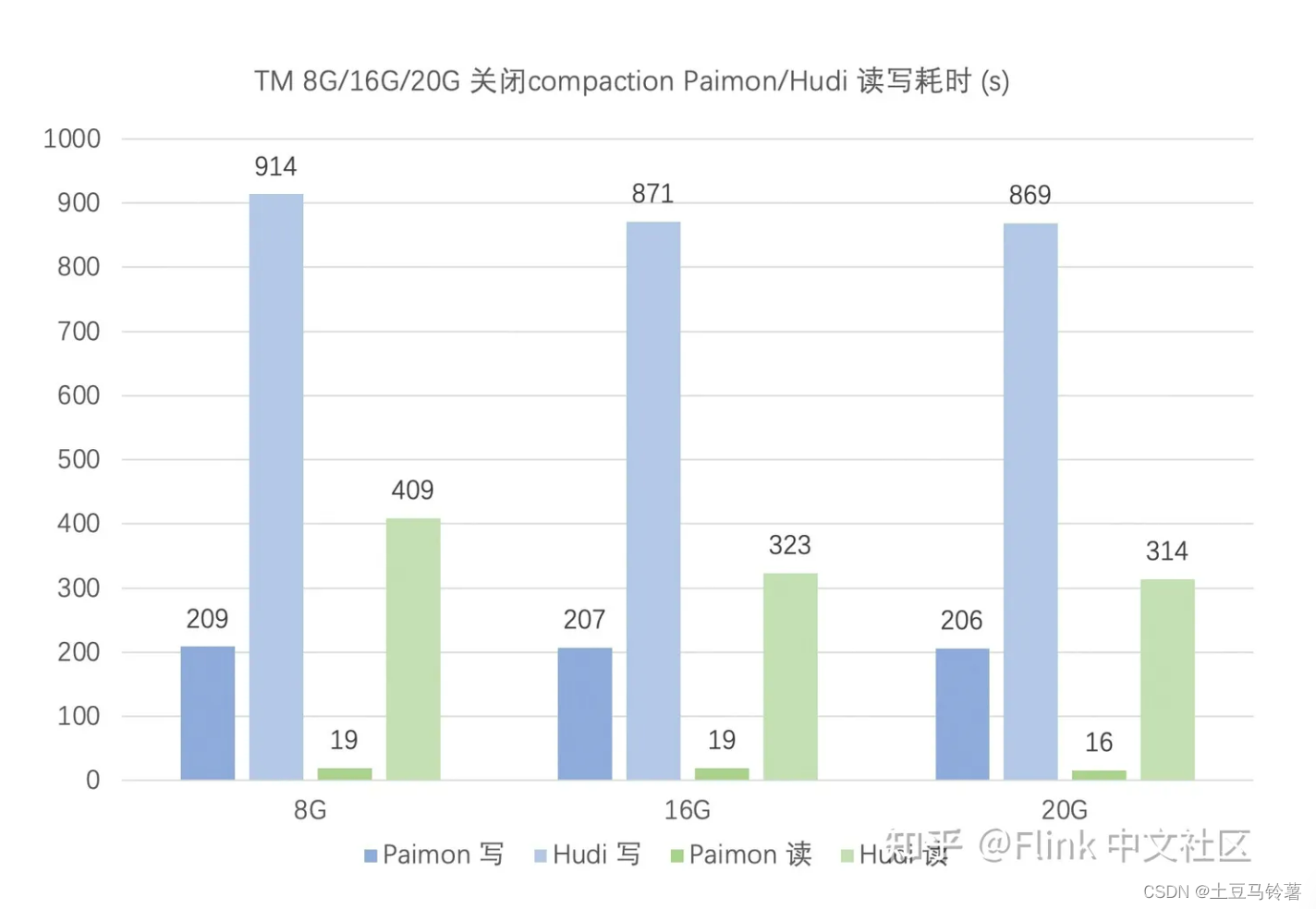
在 upsert 场景,关闭 compaction 时,Paimon 读写性能均优于 Hudi,且 Hudi 对 TM 的内存要求更高。
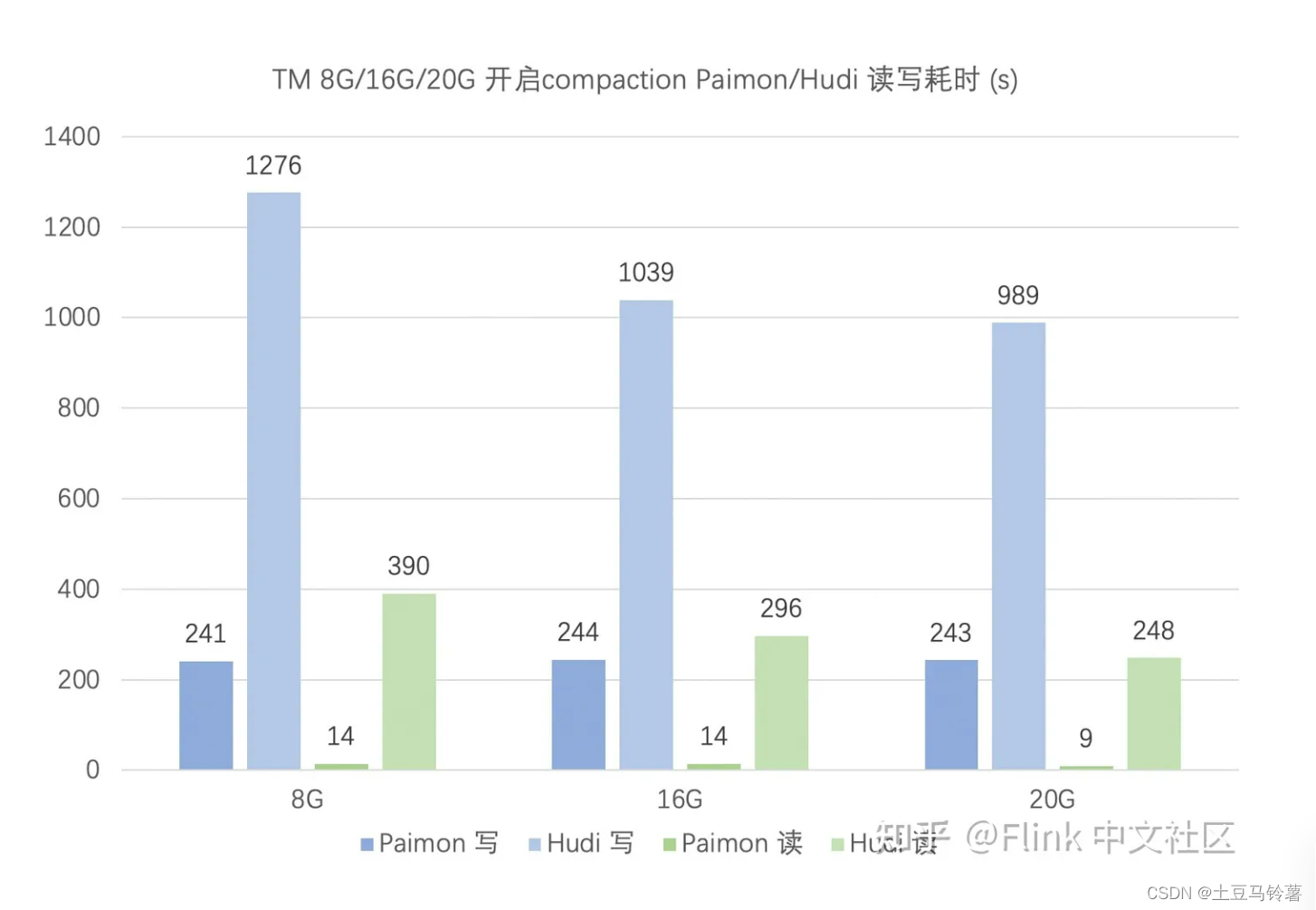
在 upsert 场景,开启 compaction 时,Paimon 读写性能均优于 Hudi。对比前面的关闭 compaction 测试,Paimon 和 Hudi 的写性能均有所下降,但读性能得到提升。
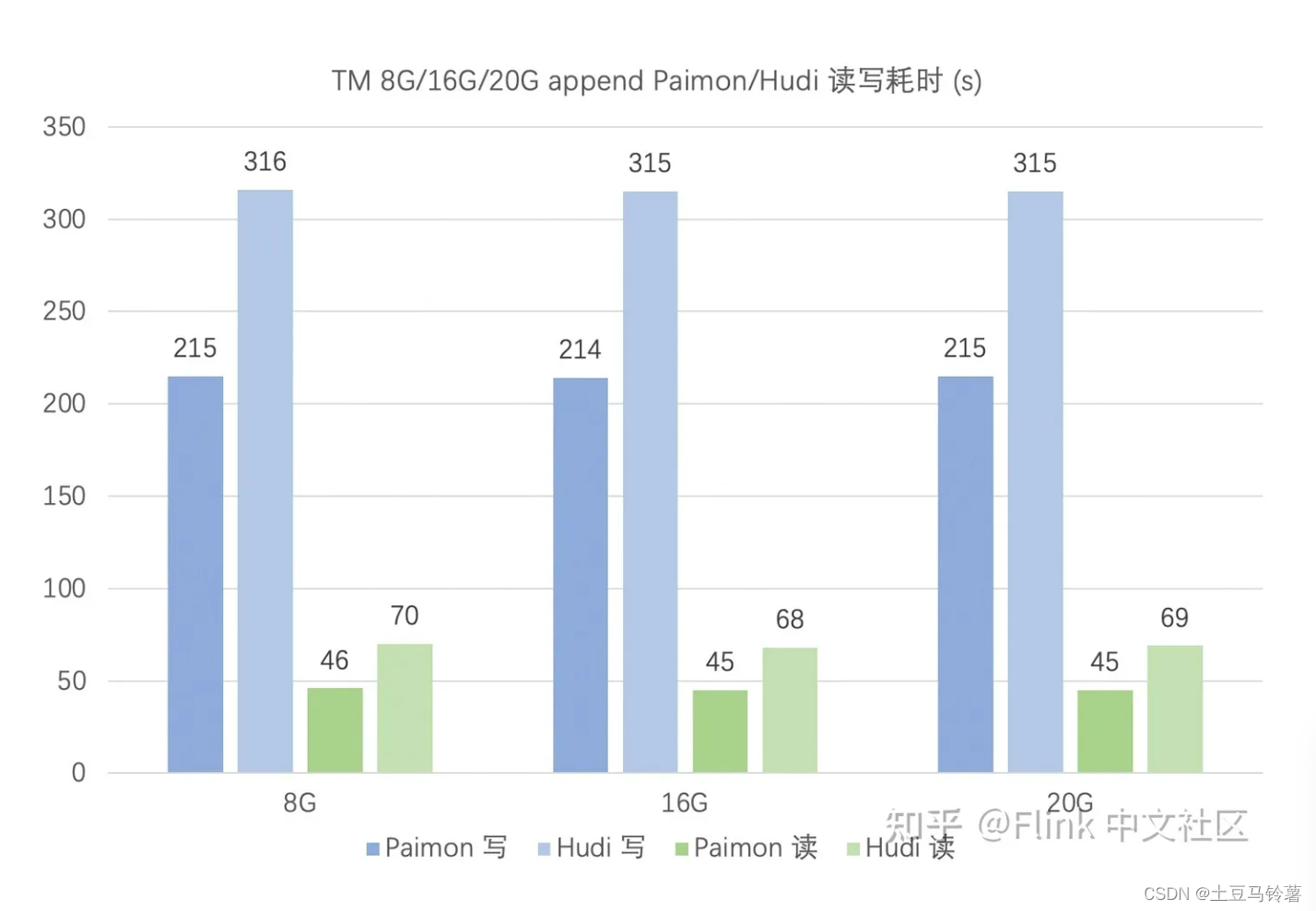
在 append 场景,Paimon 读写性能优于 Hudi,且二者都对 TM 内存要求均不高。
(2) 同程也对Hudi和Paimon进行了性能测试,详细内容见:Apache Paimon 在同程旅行的实践进展
同程在实践过程中,发现在全量+增量写入的场景中,相对 Hudi,Paimon 在相同计算资源的情况下,摄入的速度要优于 Hudi MOR 的摄入,大概有 3 倍左右的差距。查询场景下会更明显,在同样数据量的情况下,Paimon 的查询速度要优于 Hudi,大概有 7 倍左右的差距。
(3) 同时,一些开发人员对Flink 官方测试结果产生疑问,自己对也Hudi和Paimon进行了性能测试,具体过程见:Paimon VS Hudi 写入效率大PK
发现Paimon 的写入效率跟写入效果(文件数量),写入速度是 Hudi 的2倍多,而文件数量只有 Hudi数量的一半不到。对比Flink官方测试出来的,比 Hudi COW 表写入效率快12倍的结论,没有完全没有体现出来(测试的数据量不同)
实验测试结论为:Hudi 的MOR 表无论是写入速度,还是生成的文件数量,都要比 Paimon 优秀。而Hudi 的 COW 表,则正好相反,其无论写入速度,还是文件生成数量,则要比 Paimon 差,但这个差距,貌似在随着 checkpoint 时间的增大,逐渐在缩小。
8.总结
Apache Iceberg
Iceberg 社区基本盘还是在离线处理,它在国外的应用场景主要是离线取代 Hive,它也有强力的竞争对手 Delta,很难调整架构去适配 CDC 流更新。同时,Iceberg 扩展性强,对其它计算引擎也暴露的比较多的优化空间,但是这也导致后续的发展难以迅速,涉及到众多已经对接好的引擎。这并没有什么错,后面也证明了 Iceberg 主打离线数据湖和扩展性是有很大的优势,得到了众多国外厂商的支持。
Apache Hudi
Hudi 默认使用 Flink State 来保存 Key 到 FileGroup 的 Index,好处是全自动,想 Scale Up 只用调整并发就行了,坏处是性能差,直接让湖存储变成了实时点查,超过5亿条数据性能更是急剧下降。同时,存储成本也高,RocksDB State 保存所有索引。数据非常容易不一致,甚至再也不能有别的引擎来读写,因为一旦读写就破坏了 State 里面的 Index。
针对 Flink State Index 诸多问题,字节跳动的工程师们在 Hudi 社区提出了 Bucket Index 的方案,该解决方案好处是去除了 Index 带来了诸多性能问题。坏处是需要手动选取非常合适的 Bucket Number,多了小文件操作很多,少了性能不行。这套方案也是目前 Hudi 体量较大的用户的主流方案。
Hudi 当前存在的问题:
- Hudi 众多的模式让用户难以选择。
- 使用 Flink State 还是 Bucket Index?一个易用性好但是性能不行,一个难以使用。
- 使用 CopyOnWrite 还是 Merge On Read?一个写入吞吐很差,一个查询性能很差。
- 更新效率低,1-3 分钟 Checkpoint 容易反压,默认 5 次 Checkpoint 合并,一般业务可接受的查询是查询合并后的数据;全增量一体割裂,难以统一。
- 系统设计复杂,Bugs 难以收敛,工单层出不穷;各引擎之间的兼容性也非常差;参数众多。
Hudi 天然面向 Spark 批处理模式设计而诞生,不断在面向批处理的架构上进行细节改造,无法彻底适配流处理更新场景,在批处理架构上不断强行完善流处理更新能力,导致架构越来越复杂,可维护性越来越差。
Apache Paimon
Apache Paimon 最典型的场景是解决了 CDC (Change Data Capture) 数据的入湖。但是因为发展较晚,当前国内并没有主流的商业平台落地,对于批处理的性能也有待考量,仍需要一定的时间去完善和发展。以下为当前各版本支持情况:
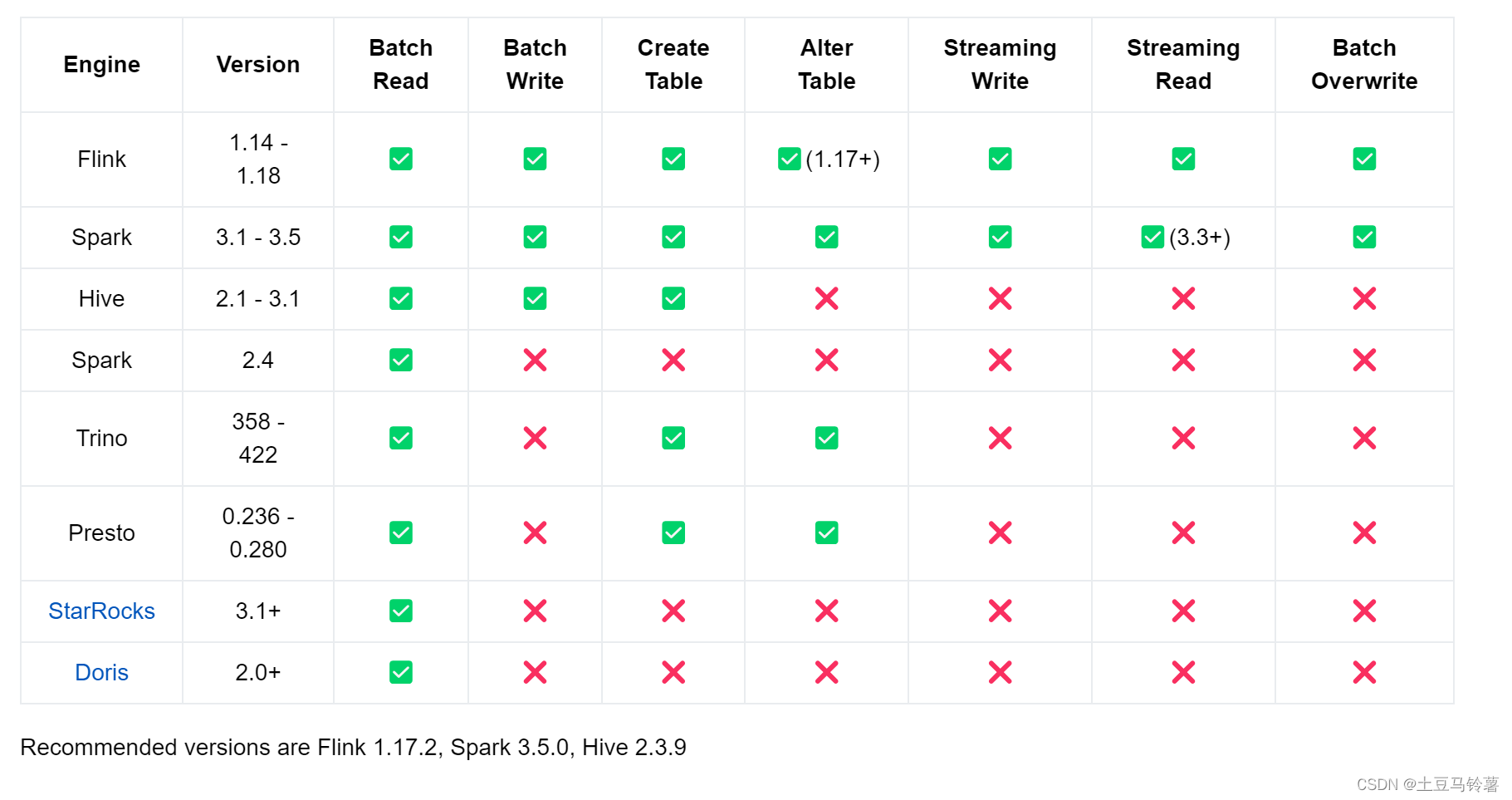
最后,对于官方的性能测试结果,仅参考即可。实际业务场景中需要结果自身业务去测试验证,综合考虑场景、数据量、各组件版本等多个因素,根据业务需求选择适合自己的解决方案。
任何关于性能测试的结论,都必须建立在具体的场景之下才有意义!
这篇关于数据湖Iceberg、Hudi和Paimon比较的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








