paimon专题

Apache Paimon V0.9最新进展
摘要:本文整理自 Paimon PMC Chair 李劲松老师在 8 月 3 日 Streaming Lakehouse Meetup Online(Paimon x StarRocks,共话实时湖仓架构)上的分享。主要分享 Apache Paimon V0.9 的最新进展以及遇到的一些挑战。 一、Paimon:飞速发展的 2024 Paimon 诞生于 2022 年的 Flink
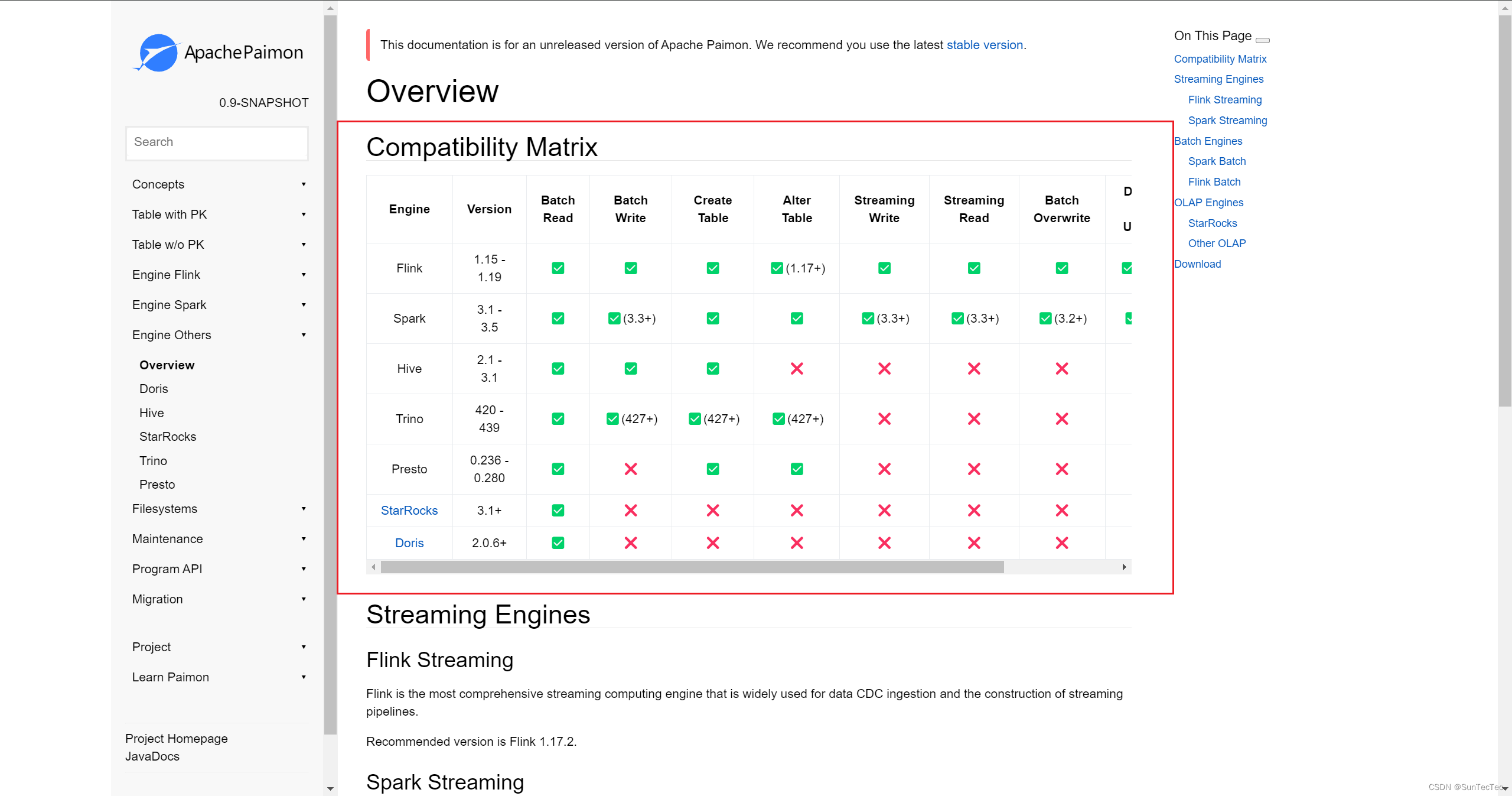
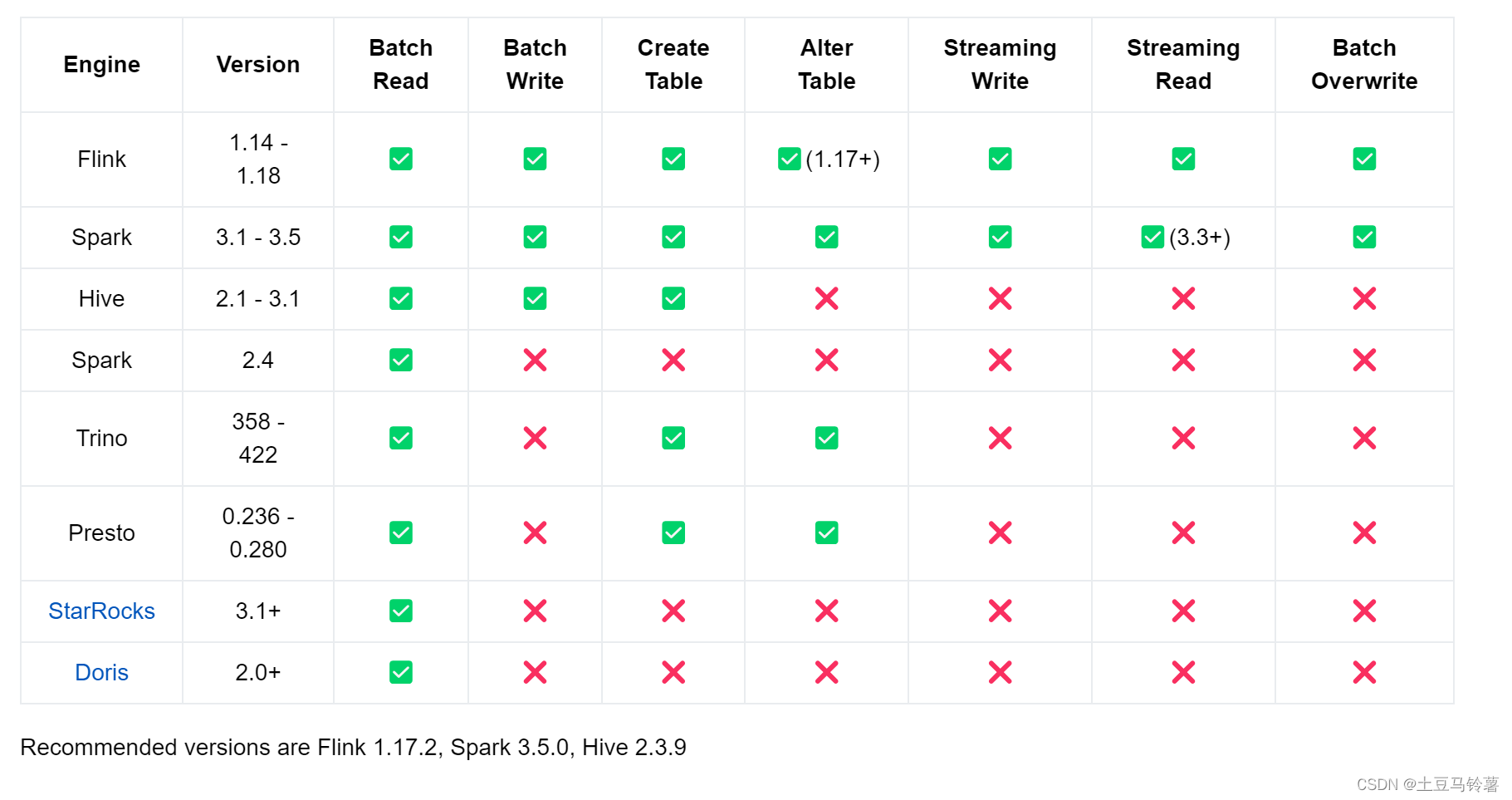
Paimon Trino Presto的关系 分布式查询引擎
Paimon支持的引擎兼容性矩阵: Trino 是 Presto 同项目的不同版本,是原Faceboo Presto创始人团队核心开发和维护人员分离出来后开发和维护的分支,Trino基于Presto,目前 Trino 和 Presto 都仍在继续开发和维护。 参考:

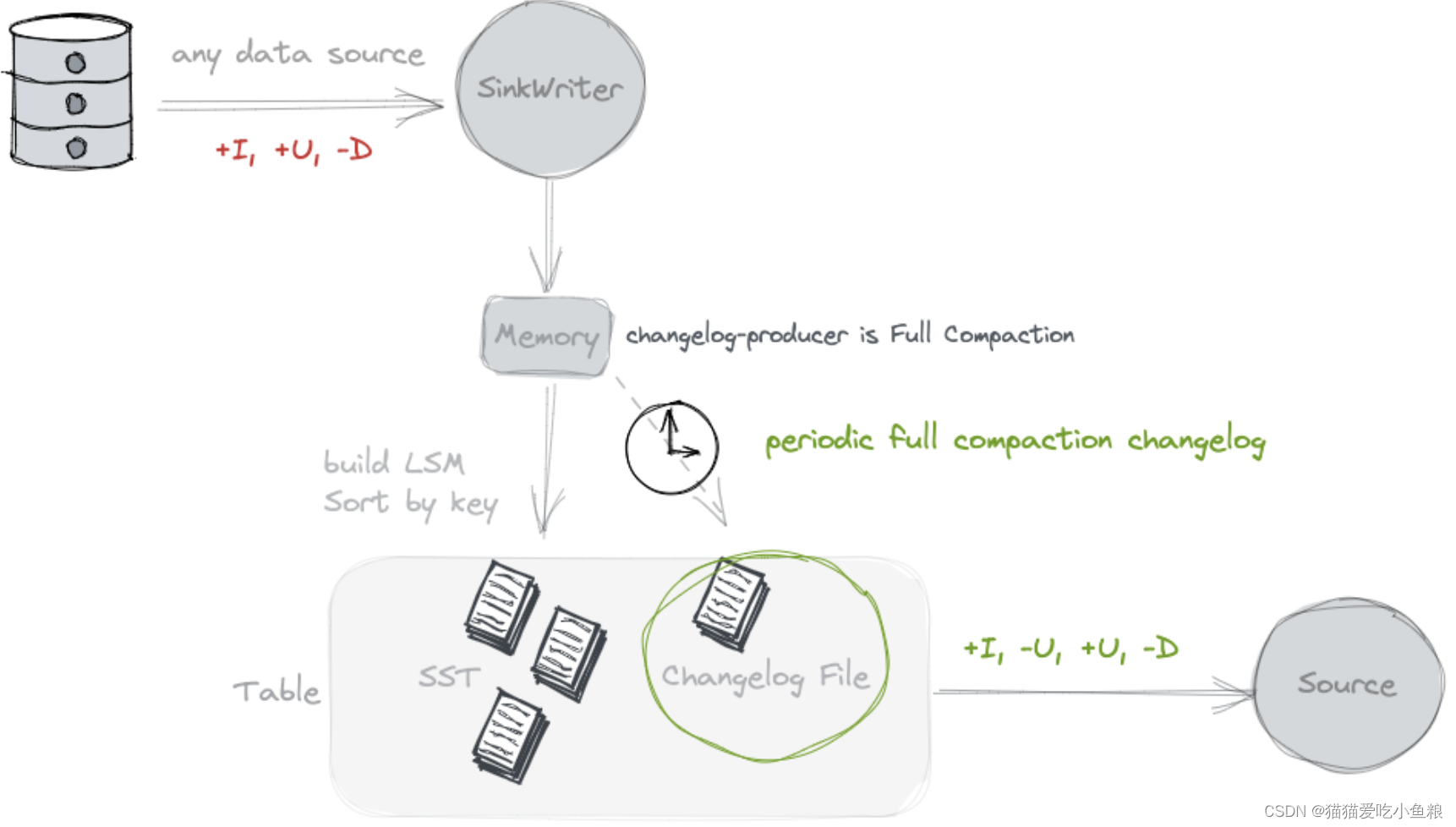
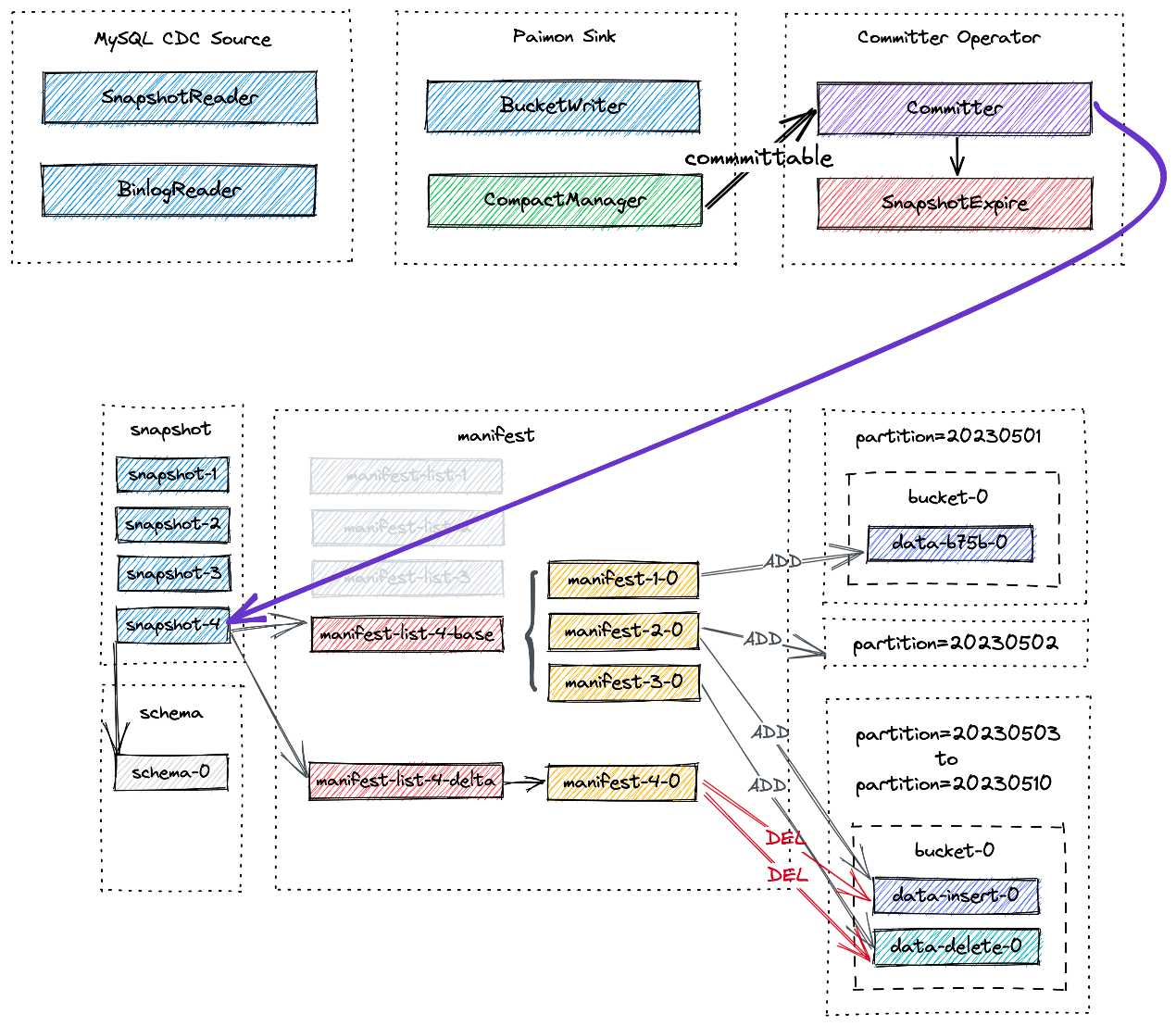
一图读懂:Flink CDC如何流式写入Paimon?
一图读懂:Flink CDC如何流式写入Paimon? 以Mysql CDC至Paimon为例 整体架构 MySQL CDC SourceSnapshotReader读取快照全量数据,BinlogReader读取增量数据。 paimon sink 实现桶级别的写入,compactManager实现异步compaction comitter 单例模式负责提交和过期快照 流程
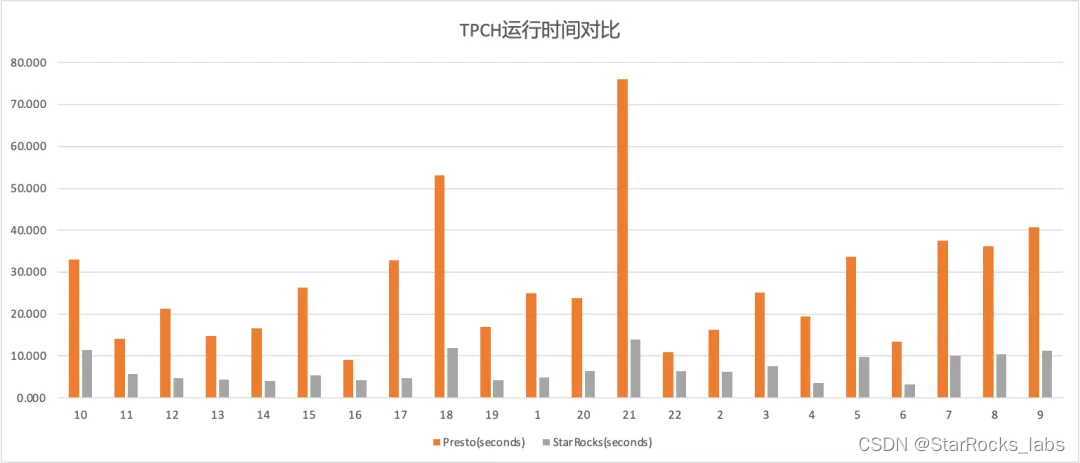
StarRocks x Paimon 构建极速实时湖仓分析架构实践
Paimon 介绍 Apache Paimon 是新一代的湖格式,可以使用 Flink 和 Spark 构建实时 Lakehouse 架构,以进行流式处理和批处理操作。Paimon 创新性地使用 LSM(日志结构合并树)结构,将实时流式更新引入 Lakehouse 架构中。 Paimon 提供以下核心功能: 高效实时更新:高吞吐和低延迟的数据摄入和更新 统一的批处理和流处理:同时支持批量读写

Apache Paimon 使用之 Writing Tables
Writing Tables 1.插入语法 INSERT { INTO | OVERWRITE } table_identifier [ part_spec ] [ column_list ] { value_expr | query }; part_spec:PARTITION ( partition_col_name = partition_col_val [ , … ] ) col

Apache Paimon 使用之Creating Catalogs
Paimon Catalog 目前支持两种类型的metastores: filesystem metastore (default),在文件系统中存储元数据和表文件。 hive metastore,将metadata存储在Hive metastore中。用户可以直接从Hive访问表。 1.使用 Filesystem Metastore 创建 Catalog Flink引擎 Flink SQ
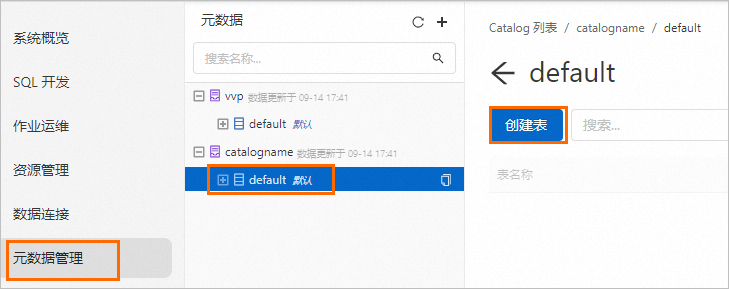
【大数据】-- 创建 Paimon 外部表
如今,在数据湖三剑客(delta lake、hudi、iceberg)之上,又新出一派: apache paimon。我们恰好在工作中遇到,以下介绍在 dataworks 上,使用 maxcompute odps sql 创建 apache paimon 外部表的一些操作和注意事项。参考:创建MaxCompute Paimon外部表_云原生大数据计算服务 MaxCompute(M

flink on yarn paimon
目录 概述实践paimon 结束 概述 ogg kafka paimon 实践 前置准备请看如下文章 文章链接hadoop一主三从安装链接spark on yarn链接flink的yarn-session环境链接 paimon 目标: 1.同步表2.能过 kafka 向 paimon写入 SET parallelism.default =2;set table.e
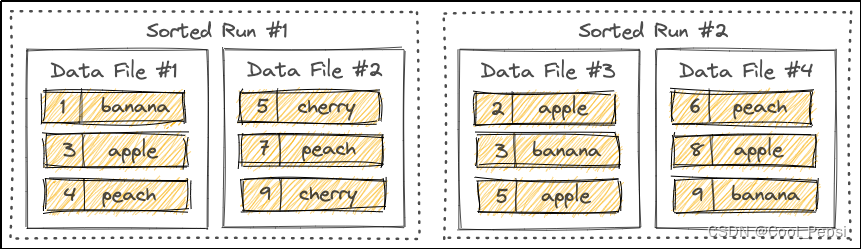
Apache Paimon 主键表解析
Primary Key Table-主键表 1.概述 主键表是创建表时的默认表类型,用户可以插入、更新或删除表中的记录; 主键由一组列组成,这些列包含每条记录的唯一值; Paimon通过对每个桶中的主键排序来强制数据有序,允许用户在主键上应用过滤条件来实现高性能。 2.Data Distribution 桶是用于读取和写入的最小存储单元,每个桶目录都包含一个LSM树; 默认,Paim
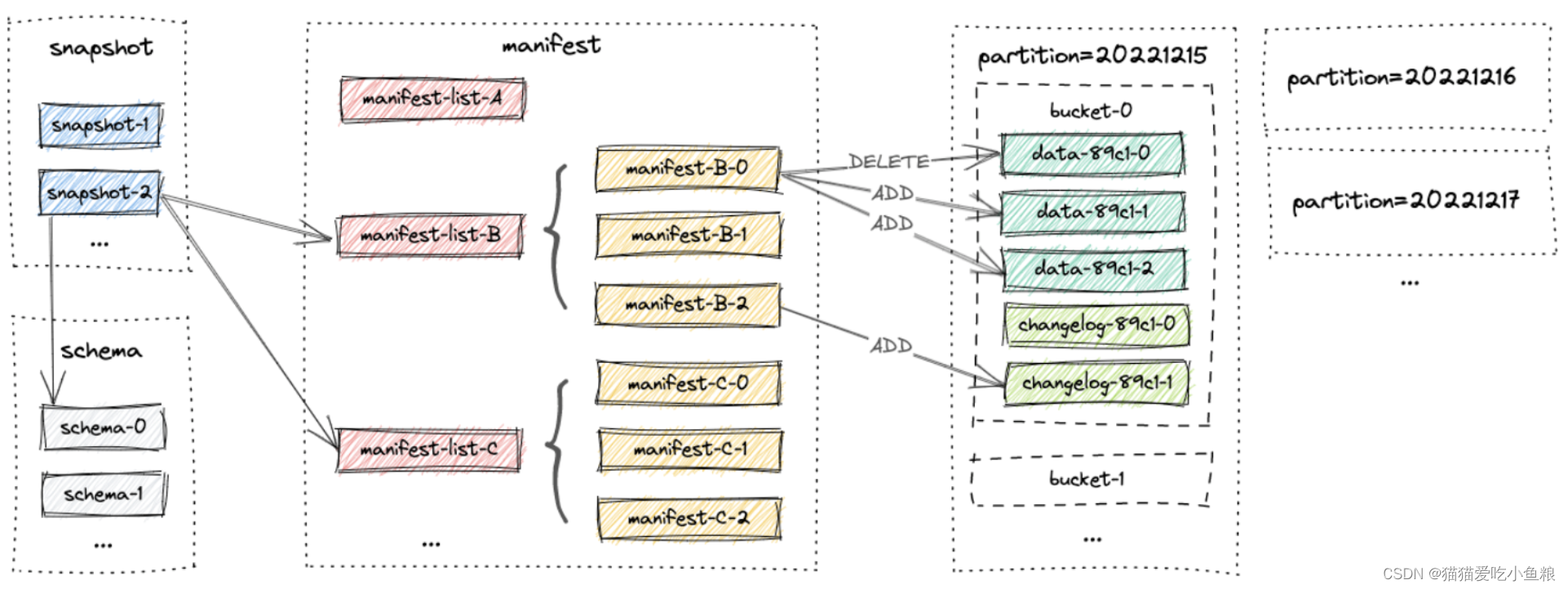
Apache Paimon 基本概念解析
1、概述 1)架构图 2)基本概念 1.Snapshot latest snapshot:访问最新快照数据; time traveling-earlier snapshot:访问历史快照数据。 2.Partition 根据日期、城市等特定列的值将表进行切分,每个表可以有一个或多个分区键来识别特定的分区,通过分区,用户可以有效地对表中的一段记录进行操作。 3.Bucket 用户
数据湖Iceberg、Hudi和Paimon比较
1.社区发展现状 项目Apache IcebergApache HudiApache Paimon开源时间2018/11/62019/1/172023/3/12LicenseApache-2.0Apache-2.0Apache-2.0Github Watch1481.2k70Github Star5.3k4.9k 1.7k Github Fork1.9k2.3k702Github issue(O

使用 Paimon + StarRocks 极速批流一体湖仓分析
摘要:本文整理自阿里云智能高级开发工程师王日宇,在 Flink Forward Asia 2023 流式湖仓(二)专场的分享。本篇内容主要分为以下四部分: StarRocks+Paimon 湖仓分析的发展历程使用 StarRocks+Paimon 进行湖仓分析主要场景和技术原理StarRocks+Paimon 湖仓分析能力的性能测试StarRocks+Paimon 湖仓分析能力的未来规划
P9843 [ICPC2021 Nanjing R] Paimon Sorting 题解 (SPJ)
[ICPC2021 Nanjing R] Paimon Sorting 传送门 题面翻译 给出一个排序算法(用伪代码表示): // 排序算法SORT(A)for i from 1 to n // n 是序列 A 的元素个数for j from 1 to nif a[i] < a[j] // a[i] 是序列 A 的第 i 个元素Swap a[i] and a[j] 请你算出对于一个序列
【Flink SQL API体验数据湖格式之paimon】
前言 随着大数据技术的普及,数据仓库的部署方式也在发生着改变,之前在部署数据仓库项目时,首先想到的是选择国外哪家公司的产品,比如:数据存储会从Oracle、SqlServer中或者Mysql中选择,ETL工具会从Informatica、DataStage或者Kettle中选择,BI报表工具会从IBM cognos、Sap Bo或者帆软中选择,基本上使用的产品组合都类似,但随着数据量的激增,之前的

flink 读取 apache paimon表,查看source的延迟时间 消费堆积情况
paimon source查看消费的数据延迟了多久 如果没有延迟 则显示0 官方文档 Metrics | Apache Paimon
flink 读取 apache paimon表,查看source的延迟时间 消费堆积情况
paimon source查看消费的数据延迟了多久 如果没有延迟 则显示0 官方文档 Metrics | Apache Paimon
Spark Paimon 中为什么我指定的分区没有下推
背景 最近在使用 Paimon 的时候遇到了一件很有意思的事情,写的 SQL 居然读取的数据不下推,明明是分区表,但是却全量扫描了。 目前使用的版本信息如下: Spark 3.5.0 Paimon 0.6.0 paimon的建表语句如下: CREATE TABLE `table_demo`(`user_id` string COMMENT 'from deserializer' )PARTI

以csv为源 flink 创建paimon 临时表相关 join 操作
目录 概述配置关键配置测试启动 kyuubi执行配置中的命令 bug解决bug01bug02 结束 概述 目标:生产中有需要外部源数据做paimon的数据源,生成临时表,以使用与现有正式表做相关统计及 join 操作。 环境:各组件版本如下 kyuubi 1.8.0flink 1.17.1paimon 0.5 正式版本hive 3.1.3 阅读此文前,需涉及前置的知识点如
Spark Paimon 中为什么我指定的分区没有下推
背景 最近在使用 Paimon 的时候遇到了一件很有意思的事情,写的 SQL 居然读取的数据不下推,明明是分区表,但是却全量扫描了。 目前使用的版本信息如下: Spark 3.5.0 Paimon 0.6.0 paimon的建表语句如下: CREATE TABLE `table_demo`(`user_id` string COMMENT 'from deserializer' )PARTI
6 Hive引擎集成Apache Paimon
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html 在实际工作中,我们通查会使用Flink计算引擎去读写Paimon,但是在批处理场景中,更多的是使用Hive去读写Paimon,这样操作起来更加方便。 前面我们在Flink代码里面,借助于Hive Catalog,实现了在Flink中创建Paimon表,写入数据,并且把paimon的

4 Paimon数据湖之Hive Catalog的使用
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html Paimon提供了两种类型的Catalog:Filesystem Catalog和Hive Catalog。 Filesystem Catalog:会把元数据信息存储到文件系统里面。Hive Catalog:则会把元数据信息存储到Hive的Metastore里面,这样就可以直接在H

5 Paimon数据湖之表数据查询详解
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html 虽然前面我们已经讲过如何查询Paimon表中的数据了,但是有一些细节的东西还需要详细分析一下。 首先是针对Paimon中系统表的查询,例如snapshots\schemas\options等等这些系统表。 其实简单理解就是我们可以通过sql的形式查询系统表来查看实体表的快照、sc

2 快速上手使用Paimon数据湖
2.1 基于Flink SQL操作Paimon 在这里我们基于Flink 1.15(ON YARN)、Paimon 0.5版本开发一个案例。 注意:想要使用Paimon是非常简单的,不需要复杂的安装部署,只需要使用一个jar包即可对它进行操作。 我们在使用Paimon的时候其实也可以把它简单理解为Hive,这样便于理解。但是我们要知道,他们两个底层其实是不一样的,一个是数据仓库,一个是
Paimon 学习笔记
本博客对应于 B 站尚硅谷教学视频 尚硅谷大数据Apache Paimon教程(流式数据湖平台),为视频对应笔记的相关整理。 1 概述 1.1 简介 Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化