hudi专题

Apache Hudi 架构设计和基本概念
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! Apache Hudi是一个Data Lakes的开源方案,Hudi是Hadoop Updates and Incrementals的简写,它是由Uber开发并开源的Data Lakes解决方案。Hudi具有如下基本特性/能力

「Apache Hudi系列」核心概念与架构设计总结
点击上方蓝色字体,选择“设为星标” 回复”面试“获取更多惊喜 简介 Apache Hudi依赖 HDFS 做底层的存储,所以可以支撑非常大规模的数据存储。同时基于下面两个原语,Hudi可以解决流批一体的存储问题。 提供了在hadoop兼容的存储之上存储大量数据,同时它还提供两种原语: Update/Delete 记录:Hudi 支持更新/删除记录,使用文件/记录级别索引,同时对写操作提供事务保

大数据之数据湖Apache Hudi
一、Hudi框架概述 Apahe Hudi (Hadoop Upserts delete and Incrementals) 是Uber主导开发的开源数据湖框架,为了解决大数据生态系统中需要插入更新及增量消费原语的摄取管道和ETL管道的低效问题,该项目在2016年开始开发,并于2017年开源,2019年1月进入 Apache 孵化器,且2020年6月称为Apache 顶级项目 官网:A
Apache Hudi在医疗大数据中的应用
本篇文章主要介绍Apache Hudi在医疗大数据中的应用,主要分为5个部分进行介绍:1. 建设背景,2. 为什么选择Hudi,3. Hudi数据同步,4. 存储类型选择及查询优化,5. 未来发展与思考。 1. 建设背景 我们公司主要为医院建立大数据应用平台,需要从各个医院系统中抽取数据建立大数据平台。如医院信息系统,实验室(检验科)信息系统,体检信息系统,临床信息系统,放射科信息管理系统,电子
Hudi原理 | Apache Hudi 典型应用场景介绍
1.近实时摄取 将数据从外部源如事件日志、数据库提取到Hadoop数据湖中是一个很常见的问题。在大多数Hadoop部署中,一般使用混合提取工具并以零散的方式解决该问题,尽管这些数据对组织是非常有价值的。 对于RDBMS摄取,Hudi通过Upserts提供了更快的负载,而非昂贵且低效的批量负载。例如你可以读取MySQL binlog日志或Sqoop增量导入,并将它们应用在DFS上的Hudi表,这比

Hudi 实践 | 3天撸了一套数据湖架构,我飘了~
数仓技术应对关系型结构化数据游刃有余,但对于多元异构数据,却爱莫能助。最近行业大佬都在聊怎么部署数据湖,这波操作未来走向如何? 数据湖技术能够实现全量数据的单一存储,通常存储原始格式的对象块或者文件。 不管是传统数仓承载的结构化数据还是半结构化数据、非结构化数据、二进制数据等任意类型的数据,数据湖都可以轻松实现采集、存储和分析。 更为人性化的是,数据湖可根据企业的业务需求提供可大可小

hudi开启了流读,read.streaming.enabled为true,还需要设置查询类型吗 如snapshot
在使用 Apache Hudi 时,尤其是开启了流式读取(read.streaming.enabled 为 true),配置查询类型非常重要。查询类型决定了如何读取数据,尤其是在处理更新和删除操作时。 查询类型选项 在 Hudi 中,常见的查询类型包括: Snapshot 查询Incremental 查询Read Optimized 查询 Snapshot 查询 Snapshot 查询类

Hudi Spark Sql Procedures 回滚 Hudi 表数据
前言 因为有 Hudi Rollback 的需求,所以单独总结 Hudi Spark Sql Procedures Rollback。 版本 Hudi 0.13.0(发现有bug)、(然后升级)0.14.1Spark 3.2.3 Procedures 官方文档:https://hudi.apache.org/docs/procedures 相关阅读:Hudi Spark SQL Cal
Hudi之数据读写探究
Hudi之数据读写深入探究 1. Hudi数据写入 1-1. 写操作 Hudi数据湖中的数据更新、插入和删除操作,是一个基于Apache Hadoop的库,为数据湖提供了一种有效的方法来处理更新和增量数据,并支持基于时间的快照和增量数据处理。Hudi支持三种主要的数据操作模式:UPSERT(更新或插入)、INSERT(插入)、BULK_INSERT(批量插入)。 1-1-1. UPSERT

Hudi Flink MOR 学习总结
前言 之前很少用MOR表,现在来学习总结一下。首先总结一下 compaction 遇到的问题。 版本 Flink 1.15.4Hudi 0.13.0 表类型 COW 和 MOR COW:COW COPY_ON_WRITE 写时复制,写性能相比于MOR表差一点,因为每次写数据都会合并文件,但是能及时读取到最新的表数据。数据文件只有 parquetMOR:MERGE_ON_READ 读时

探索在Apache SeaTunnel上使用Hudi连接器,高效管理大数据的技术
Apache Hudi是一个数据湖处理框架,通过提供简单的方式来进行数据的插入、更新和删除操作,Hudi能够帮助数据工程师和科学家更高效地处理大数据,并支持实时查询。 支持的处理引擎 Spark Flink SeaTunnel Zeta 主要特性 批处理 流处理 精确一次性 列投影 并行处理 支持用户自定义切分 描述 Hudi Source 连接器专为从Apache Hud


Debezium-Flink-Hudi:实时流式CDC
目录 1. 什么是Debezium 2. Debezium常规使用架构 3. 部署Debezium 3.1. AWS EKS部署Kafka Connector 4. Flink 消费Debezium 类型消息 5. 写入Hudi表 5.1. 依赖包问题 5.2. Flink 版本问题 6. Flink消费Debezium与写入Hudi测试 7. 验证hudi表 8. 总结
Hudi 表支持多种查询引擎对比
Hudi 表支持多种查询引擎对比 Apache Hudi有两种主要的表类型,分别是Copy on Write(COW)表和Merge on Read(MOR)表。 Copy on Write(COW)表: 特点:COW表在写入新数据时会创建一个全新的数据文件,保留历史版本的数据文件不变。每次写入都会生成新的数据文件,因此数据不会被覆盖,保证了数据的完整性和可追溯性。使用场景:适用于需要
Hudi面试题及参考答案:全面解析与实战应用
在大数据领域,Apache Hudi(Hadoop Upserts and Incrementals)作为一个高性能的数据存储框架,越来越受到企业的青睐。本文将为您提供一系列Hudi面试题及其参考答案,帮助您深入了解Hudi的核心概念、架构设计以及实战应用。 目录 1. Hudi的核心优势是什么? 2. Hudi如何处理数据的变更? 3. Hudi支持哪些数据存储格式? 4. 如何在Hu
Flink实时写Hudi报NumberFormatException异常
Flink实时写Hudi报NumberFormatException异常 问题描述 在Flink项目中,针对Hudi表 xxxx_table 的 bucket_write 操作由于 java.lang.NumberFormatException 异常而从运行状态切换到失败状态。异常信息显示在解析字符串"ddd7a1ec"为整数时出现了问题。报错如下: bucket_write: xxxx_t

HashData的湖仓一体思考:Iceberg、Hudi特性讲解与支持方案
湖仓一体作为一种新兴的开放式数据管理架构,能够充分发挥数据湖的灵活性、生态丰富以及数据仓库的企业级数据分析能力,已经成为企业建设现代数据平台的热门选择。 在此前的直播中,我们分享了HashData湖仓一体方案架构设计与Hive数据同步。本次直播,我们介绍了Iceberg、Hudi的特性与支持方案,并对HashData连接组件的原理和实现流程进行了详细的讲解和演示。以下内容根据直播文字整理。 H
【大数据】-- dataworks 创建odps 的 hudi 外表
文档:创建OSS外部表_云原生大数据计算服务 MaxCompute(MaxCompute)-阿里云帮助中心 举例:创建 odps 的 hudi 外表 CREATE EXTERNAL TABLE IF NOT EXISTS my_project.ods_hudi_mysql_words_h_all(id BIGINT COMMENT '主键id',`words`

【Hudi】核心概念
https://www.bilibili.com/video/BV1ue4y1i7na?p=17&vd_source=fa36a95b3c3fa4f32dd400f8cabddeaf 大数据新风口:Hudi数据湖(尚硅谷&Apache Hudi联合出品) 1 基础概念 1.1 时间轴(TimeLine) 1.2 文件布局(File Layout) 1.3 索引(Index) 1
测试环境搭建整套大数据系统(七:集群搭建kafka(2.13)+flink(1.14)+dinky+hudi)
一:搭建kafka。 1. 三台机器执行以下命令。 cd /optwget wget https://dlcdn.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgztar zxvf kafka_2.13-3.6.1.tgzcd kafka_2.13-3.6.1/configvim server.properties 修改以下俩内容 1.三台机器分
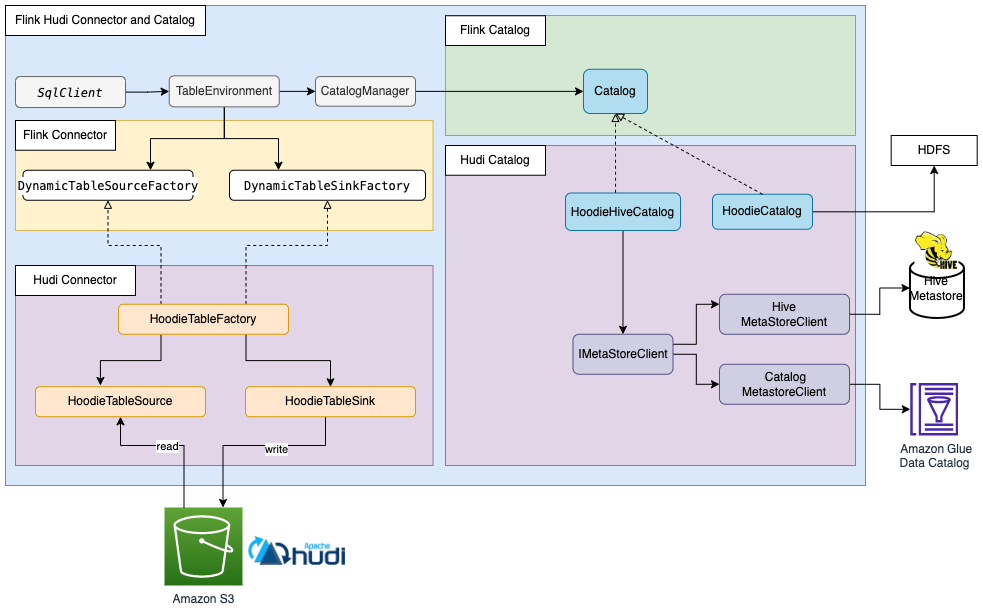
Flink Catalog 解读与同步 Hudi 表元数据的最佳实践
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维码进入京东手机购书页面。 文章目录 1. Flink Catalog 的整体设计和各类具体实现2.
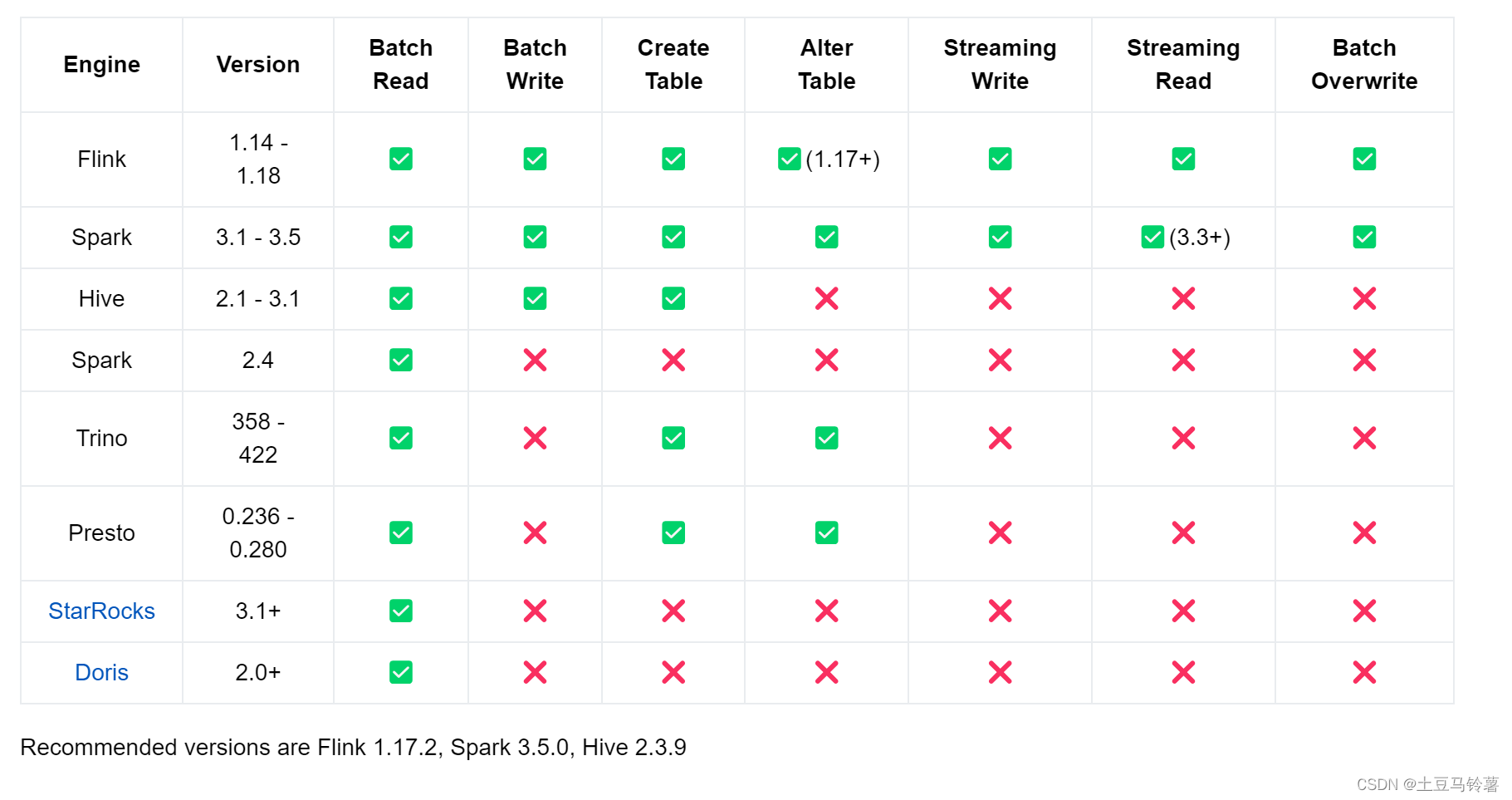
数据湖Iceberg、Hudi和Paimon比较
1.社区发展现状 项目Apache IcebergApache HudiApache Paimon开源时间2018/11/62019/1/172023/3/12LicenseApache-2.0Apache-2.0Apache-2.0Github Watch1481.2k70Github Star5.3k4.9k 1.7k Github Fork1.9k2.3k702Github issue(O
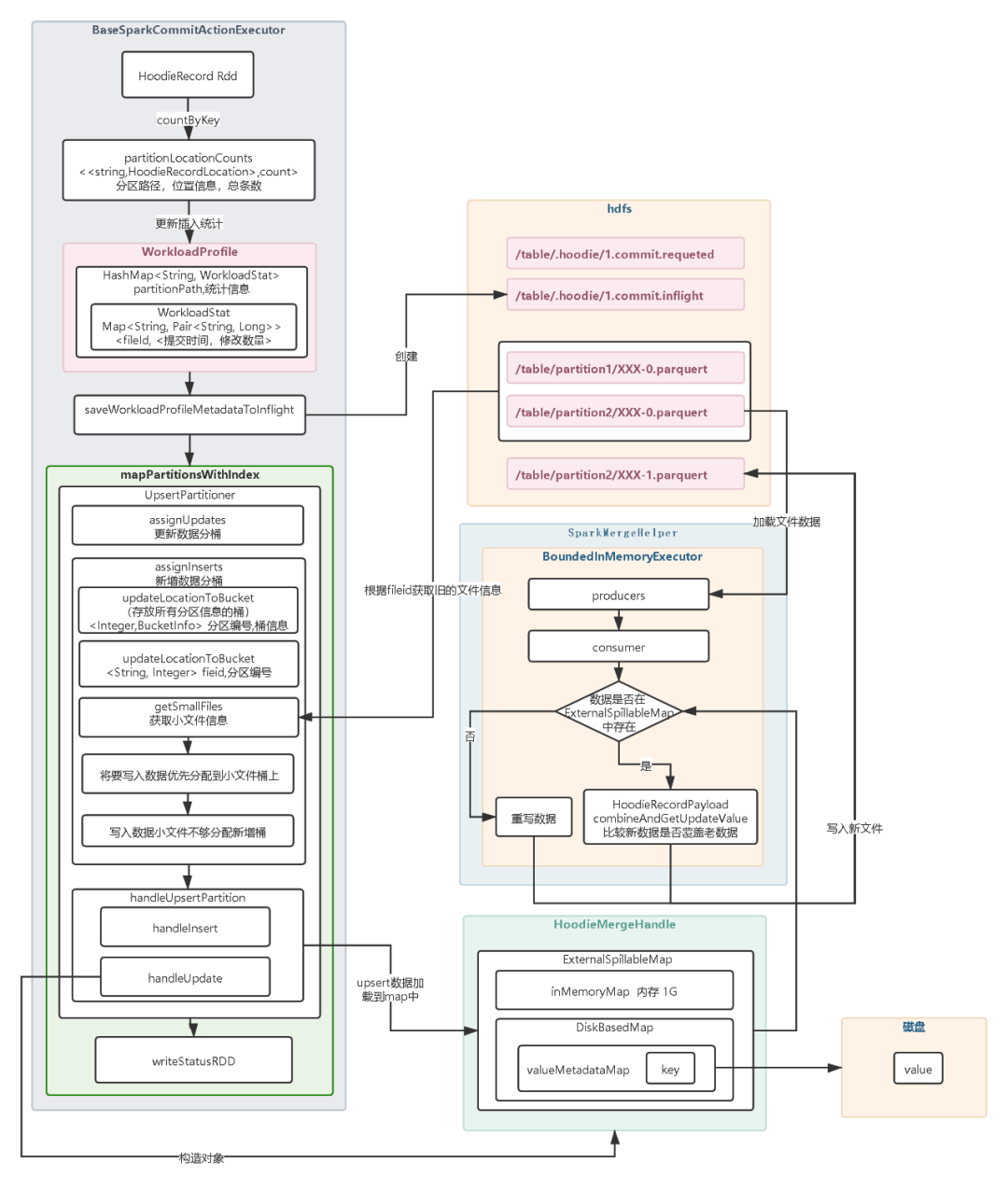
【Hudi】Upsert原理
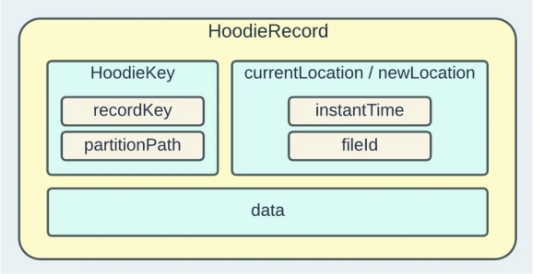
17张图带你彻底理解Hudi Upsert原理 1.开始提交:判断上次任务是否失败,如果失败会触发回滚操作。然后会根据当前时间生成一个事务开始的请求标识元数据。2.构造HoodieRecord Rdd对象:Hudi 会根据元数据信息构造HoodieRecord Rdd 对象,方便后续数据去重和数据合并。3.数据去重:一批增量数据中可能会有重复的数据,Hudi会根据主键对数据进行去重避免重复数据