本文主要是介绍测试环境搭建整套大数据系统(七:集群搭建kafka(2.13)+flink(1.14)+dinky+hudi),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:搭建kafka。
1. 三台机器执行以下命令。
cd /opt
wget wget https://dlcdn.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz
tar zxvf kafka_2.13-3.6.1.tgz
cd kafka_2.13-3.6.1/config
vim server.properties
修改以下俩内容
1.三台机器分别给予各自的broker_id。
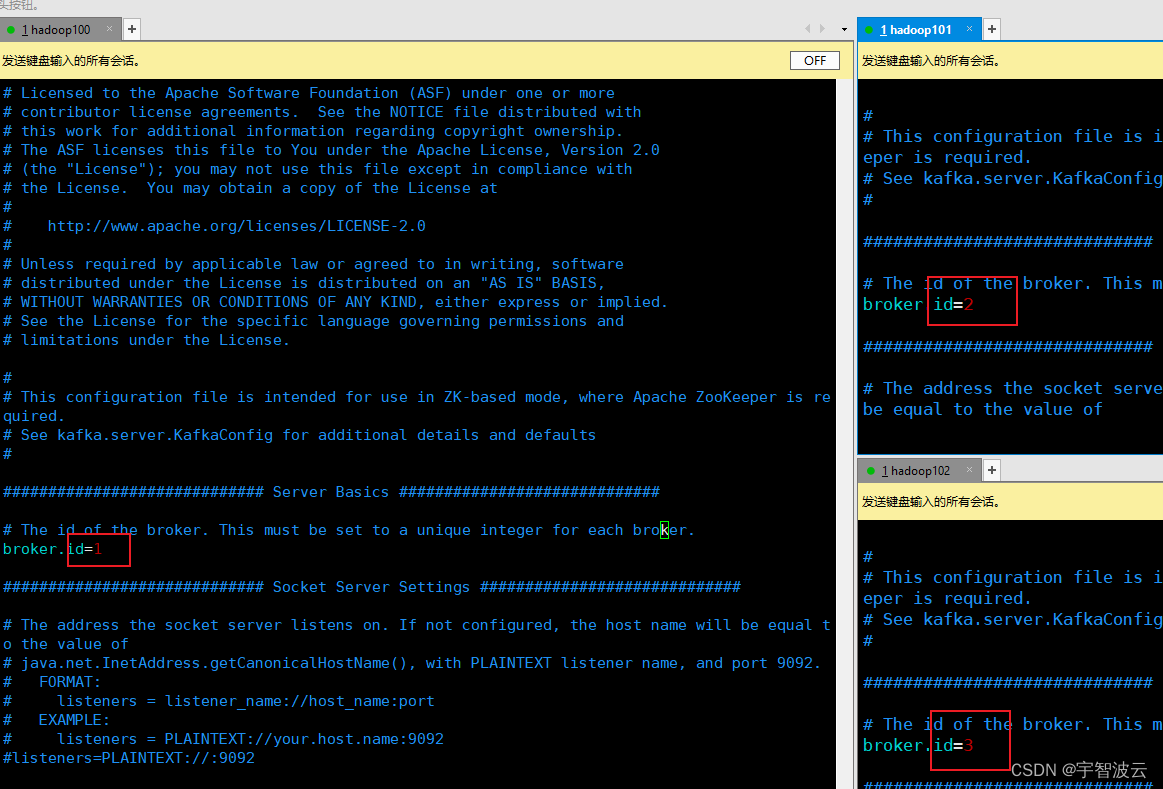
2. 配置zk。
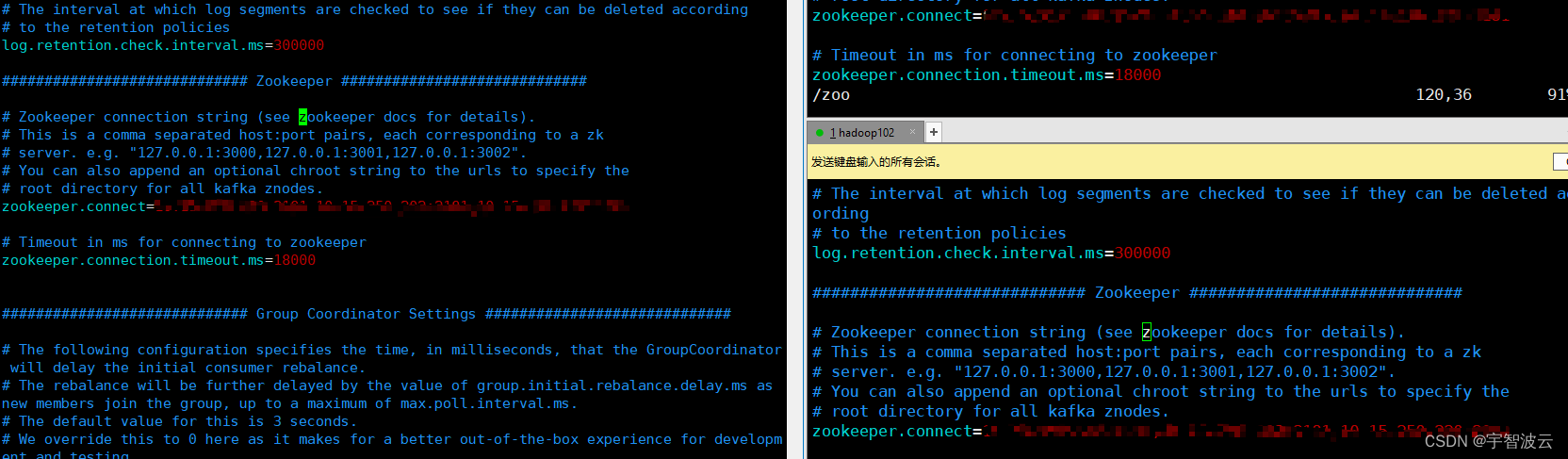
3. 启动测试。
3.1 后台启动。
第一步:启动zk。
第二步:执行启动命令
nohup /opt/kafka_2.13-3.6.1/bin/kafka-server-start.sh /opt/kafka_2.13-3.6.1/config/server.properties > /dev/null 2>&1 &
3.2 测试。
在一台机器上执行创建topic命令。
/opt/kafka_2.13-3.6.1/bin/kafka-topics.sh --create --topic my-topic-kraft --bootstrap-server localhost:9092
在另外一台机器上执行查看topic命令。
/opt/kafka_2.13-3.6.1/bin/kafka-topics.sh --list --bootstrap-server localhost:9092

二:搭建flink。
1. 三台机器下载flink。
cd /opt
https://www.apache.org/dyn/closer.lua/flink/flink-1.14.0/flink-1.14.0-bin-scala_2.12.tgz
2.修改配置参数。
- 三台机器都修改 flink-conf.yaml
cd /opt/flink-1.14.0/conf
vim flink-conf.yaml
填写主节点地址

zk地址修改

2. 修改 masters
vim masters

3. 修改works
vim works
其他俩台机器地址填写到此处。
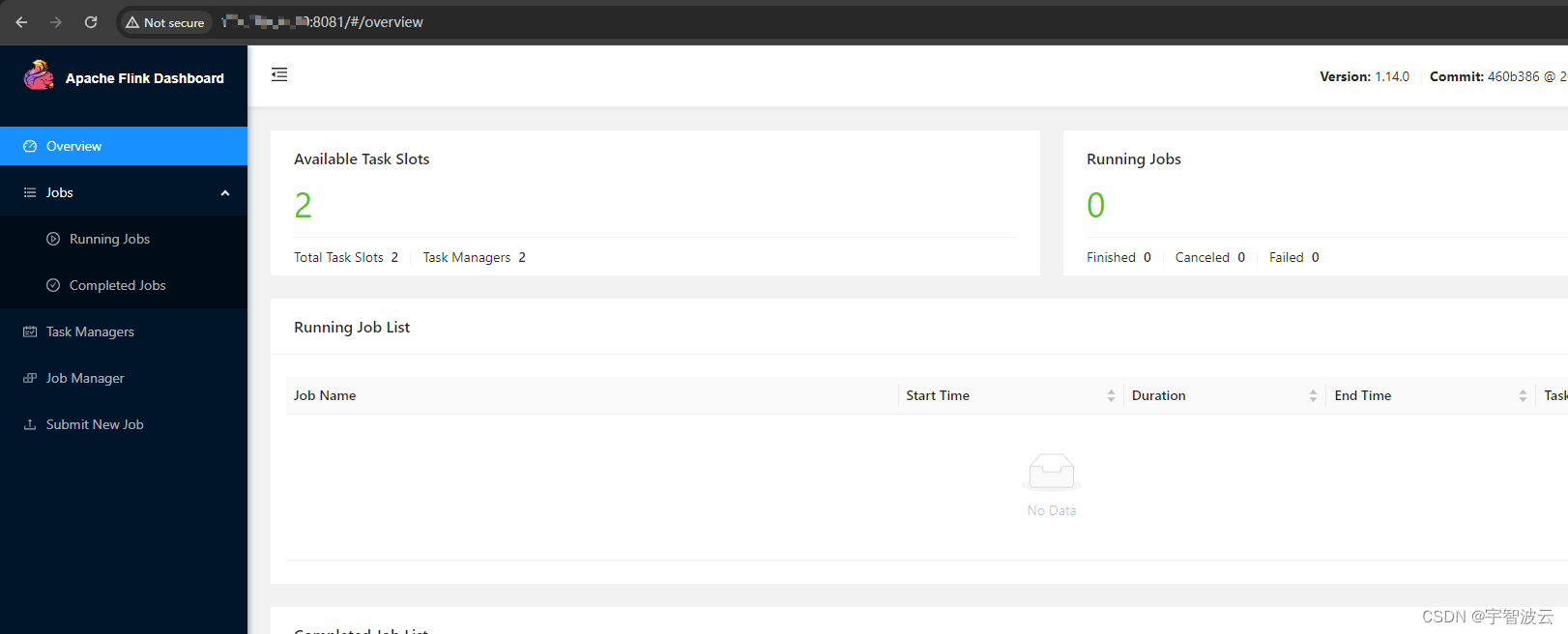
3.启动flink。
cd /opt/flink-1.14.0/bin
./start-cluster.sh
查看页面,ip位主节点,端口8081
这篇关于测试环境搭建整套大数据系统(七:集群搭建kafka(2.13)+flink(1.14)+dinky+hudi)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








