数据系统专题
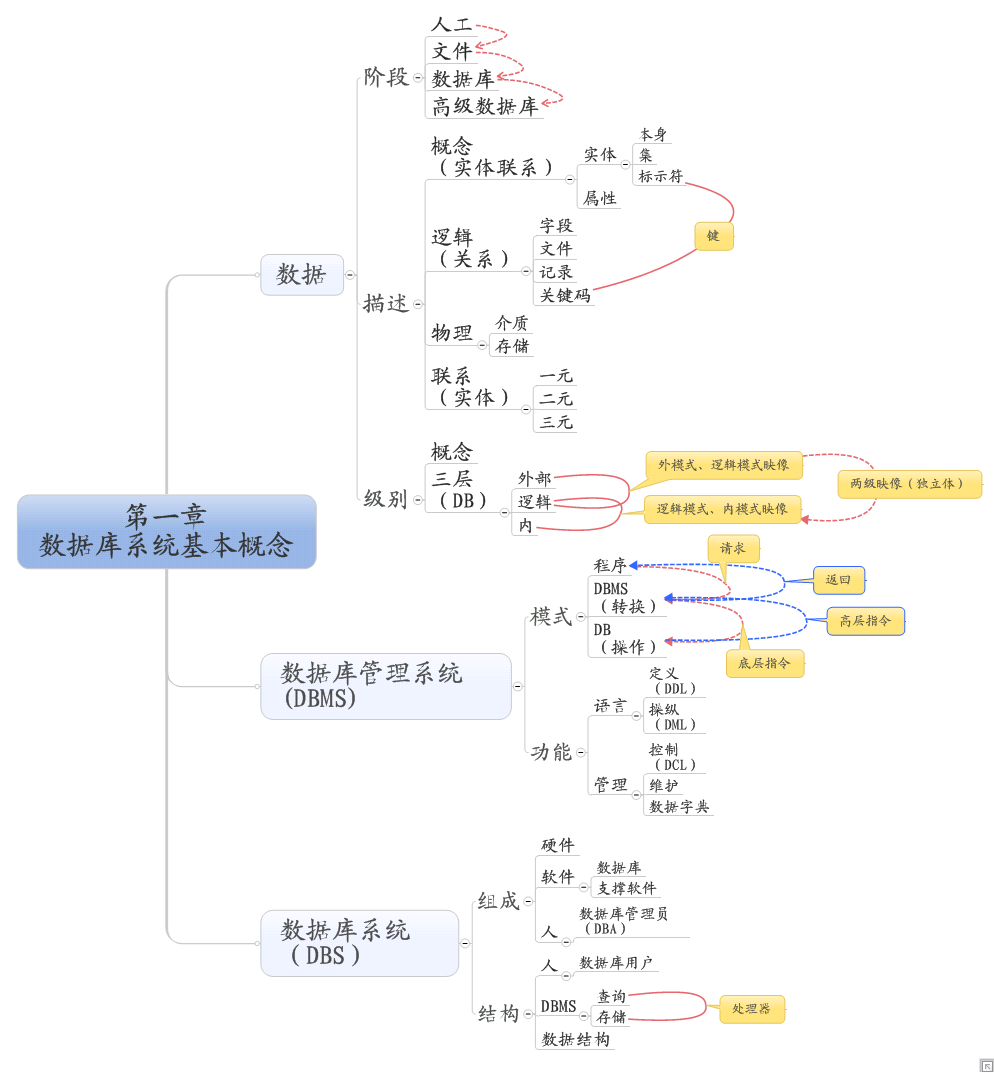
数据库系统原理之第一章数据系统基本概念总结
昨天,听了米老师的讲课之后突然对原本“晕晕乎乎”的数据库有了新的认识,以下便是听了米老师的讲解之后又结合我自己的理解和小童师姐的帮助下对《数据库系统原理》第一章的认识: 首先,将第一章分了三大类:数据、DBMS、DBS; 其次,数据中包括阶段、描述、级别;DBMS大体分为模式和功能两类;DBS又分为组成和结构; 详细请参见导图: (有认识不到位或做的不

大数据系统测试——大数据系统解析(上)
各位好,我是 @道普云 欢迎关注我的主页 希望这篇文章对想提高软件测试水平的你有所帮助。 在本文中我们一起来看一下大数据系统每一个层次需要解决的技术问题和对应的一些技术需求。以此来作为学习大数据系统测试的基础。 数据收集层主要是进行数据源的分布式、异构化、多样化、流水化这样一些场景。我们面向的数据源的类型越来越多,越来越异构化。它整体上对数据收集的扩展性、可靠性、安全性、低延迟这些

测试环境搭建整套大数据系统(十六:超级大文件处理遇到的问题)
一:yarn出现损坏的nodemanger 报错现象 日志:1/1 local-dirs usable space is below configured utilization percentage/no more usable space [ /opt/hadoop-3.2.4/data/nm-local-dir : used space above threshold of 90.0%

测试环境搭建整套大数据系统(十五:搭建mysql8)
一:更新系统 $sudo apt update$sudo apt list --upgradable# get a list of upgrades$sudo apt upgrade 二:下载 sudo apt install mysql-server-8.0sudo mysql 修改密码 ALTER USER 'root'@'localhost' IDENTIFIED WIT

《数据密集型应用系统设计》笔记——第一部分 数据系统基础(ch1-4)
写在前面:对DDIA这本书慕名已久,粗看书里的一些知识都或多或少了解,但仔细阅读下来,还是缺少对细节的认识。目前看了四个章节,这本书一直在围绕两个问题:是什么和为什么,来做阐述,针对工业界已有的技术和存在的问题分析的非常细致,让我时常有种恍然大悟的感觉,对各种知识之间的关联讲述的非常到位。所以写下每章要点的笔记,时常回顾时常新 第1章 可靠、可扩展与可维护的应用系统 Redis既可以用于数据存
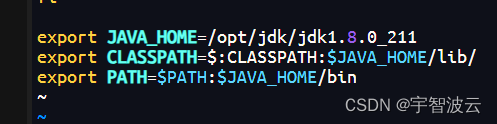
低代码信创开发核心技术(四)动态元数据系统设计
一、概述 在当今快速发展的信息技术领域,动态元数据系统扮演着至关重要的角色。它不仅能够提供数据的描述信息,还能动态地适应业务需求的变化,从而提高系统的灵活性和可扩展性。构建一个动态元数据系统意味着我们可以在不重启系统的情况下,对数据模型进行实时更新和维护,而且通过与前端同步传递元数据,可以在不动用开发资源的情况下建立新的界面。 意义 动态元数据系统的核心意义在于其能够提供一种机制,允许系统在

《大数据系统基础》课程实践项目中期答辩顺利举行,清华持续探索大数据人才教育创新之路
2017年11月15日,清华大学大数据能力提升项目之《大数据系统基础》课程实践项目中期答辩在清华大学六号教学楼顺利举行。160余名同学分为21组,向任课老师和企业导师汇报了各组实践项目的进展情况,任课老师和企业导师根据同学们的汇报表现逐一进行了点评和指导。据悉,本次答辩项目来自于国家发改委、百度、国美等政府机构和知名大数据企业等。项目需求和数据涉及多个行业领域,如“建设工程造价指数”、“餐
工业大数据系统与应用北京市重点实验室给大家拜年啦!
关于我们 工业大数据是新一轮工业革命的核心要素。未来,工业企业将通过数据的全面深入分析进一步提升企业竞争力和实现业务升级转型。主要体现在两方面:一方面,通过大数据驱动的创新产品设计、智能制造、智能服务,实现提升产品质量、生产效率、节省成本,提升企业竞争力;另一方面,以智能联网的工业产品为载体,以联网产品数据支撑服务产品周边用户生态系统的产业互联网业务,开创新兴市场和业务模式。清华大学软件学院、

测试环境搭建整套大数据系统(十二:挂载磁盘到hadoop环境)
一:链接硬盘 将硬盘连接到计算机的 SATA 接口或 USB 接口,并确保硬盘通电并处于可用状态。 二:查看硬盘信息 sudo fdisk -l 三:创建分区 gdisk /dev/vbd 重新扫描磁盘 partprobe /dev/vdb 格式化磁盘 mkfs.ext4 /dev/vdb2 查看磁盘情况 lsblk /dev/vdb 四:挂载磁盘
测试环境搭建整套大数据系统(十一:docker部署superset,无密码登录嵌入html)
一:安装docker 参考文档 https://blog.csdn.net/weixin_43446246/article/details/136554243 二:安装superset 下载镜像。 拉取镜像(docker pull amancevice/superset)查看镜像是否下载完成(docker images) 2. 安装容器。 mkdir /opt/docke
测试环境搭建整套大数据系统-问题篇(一:实时遇到的问题)
1. java.io.IOException: Failed to deserialize JSON ‘{“age”:867,“sex”:“fba8c074f9”,“t_insert_time”:“2024-03-04 14:12:24.821”}’ 解决方式 修改数据类型。将TIMESTAMP_LTZ改为TIMESTAMP。 2. java. lang,classNotFoundExcept
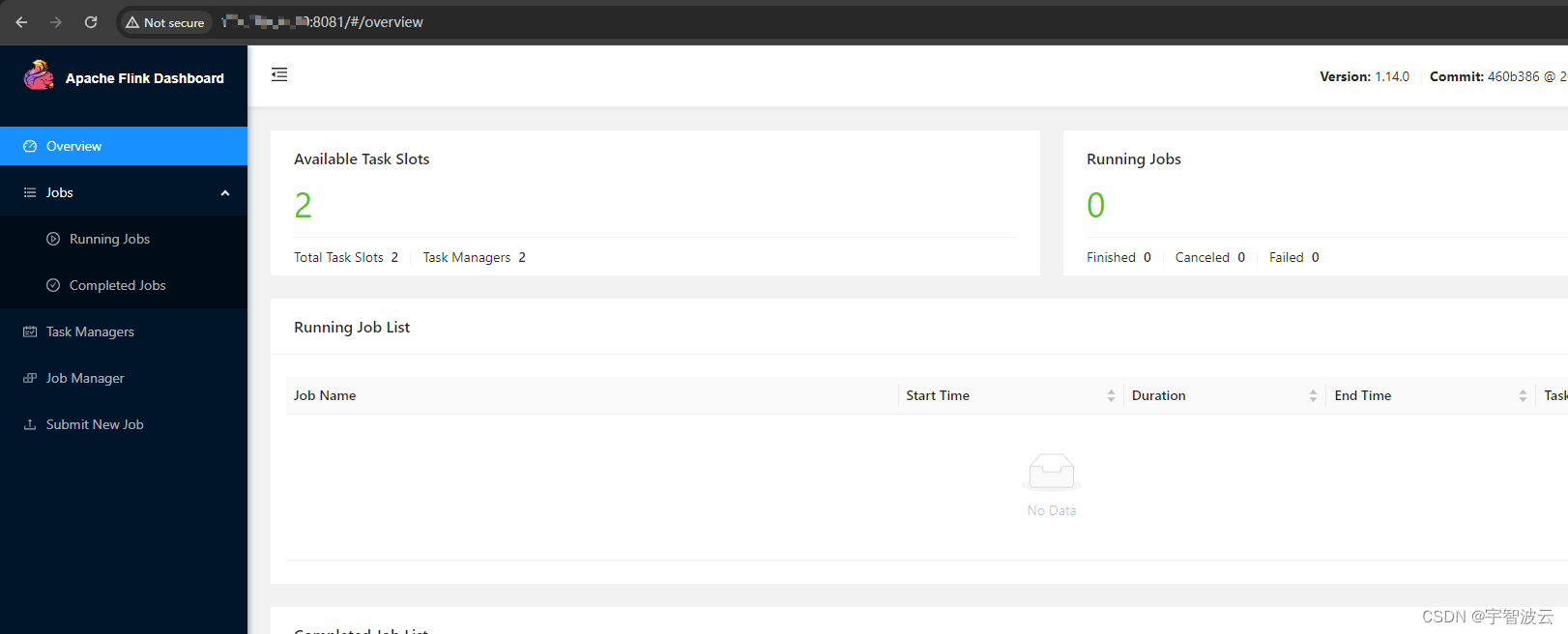
测试环境搭建整套大数据系统(七:集群搭建kafka(2.13)+flink(1.14)+dinky+hudi)
一:搭建kafka。 1. 三台机器执行以下命令。 cd /optwget wget https://dlcdn.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgztar zxvf kafka_2.13-3.6.1.tgzcd kafka_2.13-3.6.1/configvim server.properties 修改以下俩内容 1.三台机器分
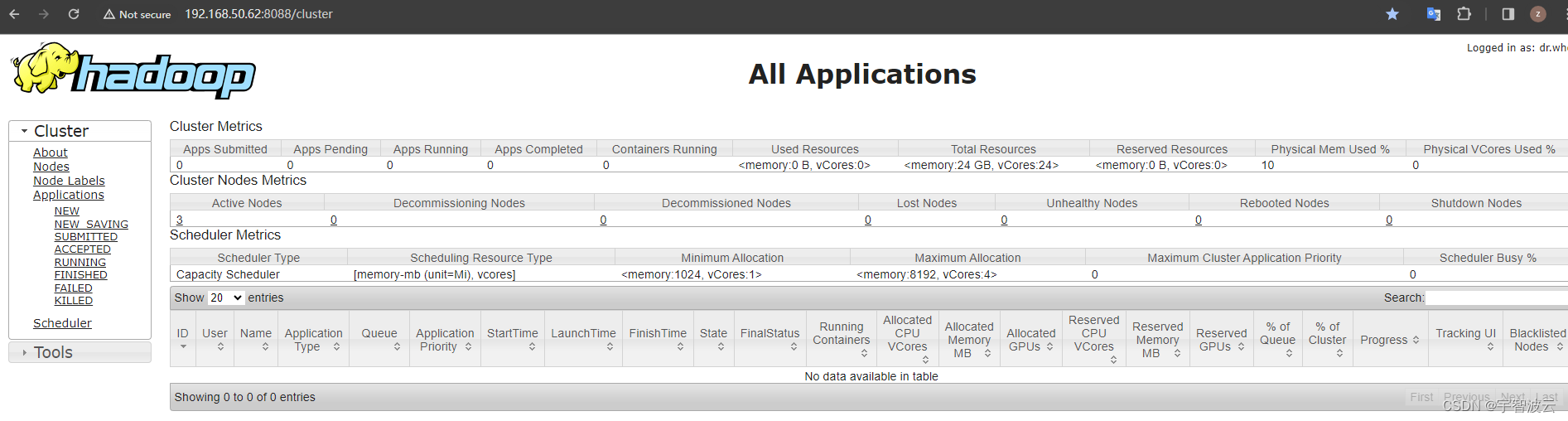
测试环境搭建整套大数据系统(三:搭建集群zookeeper,hdfs,mapreduce,yarn,hive)
一:搭建zk https://blog.csdn.net/weixin_43446246/article/details/123327143 二:搭建hadoop,yarn,mapreduce。 1. 安装hadoop。 sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt 2. 修改java配置路径。 cd /opt/hadoop-3.2.4/
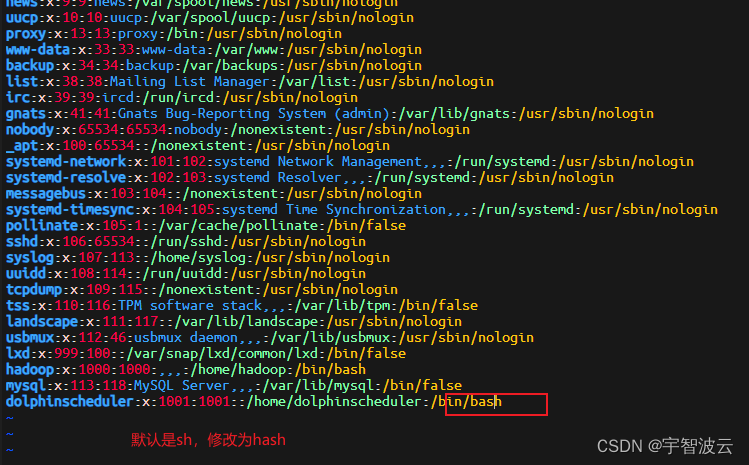
测试环境搭建整套大数据系统(四:ubuntu22.4创建普通用户)
一:创建用户,修改密码,增加sudo权限。 useradd dolphinscheduler#输入密码passwd dolphinscheduler# 配置 sudo 免密sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoerssed -i 's/Defaults requirett/
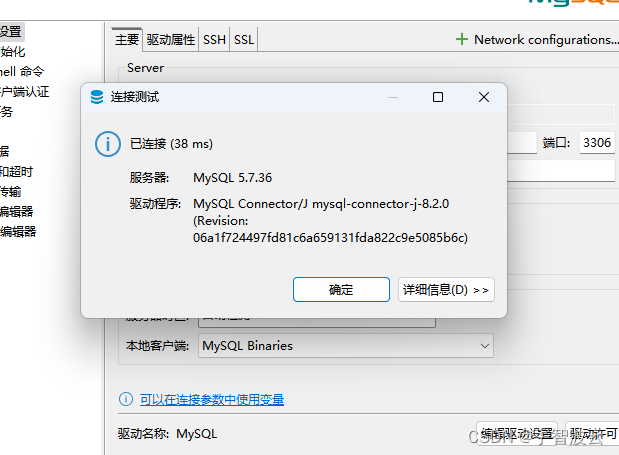
测试环境搭建整套大数据系统(二:安装jdk,mysql)
一:安装JDK 参考 https://blog.csdn.net/weixin_43446246/article/details/123328558 二:安装mysql 1.因为我们安装cdh6.3.2。cdh支持的是5.6和5.7版本的mysql。 2. 步骤 wget https://downloads.mysql.com/archives/get/p/23/file/mysq
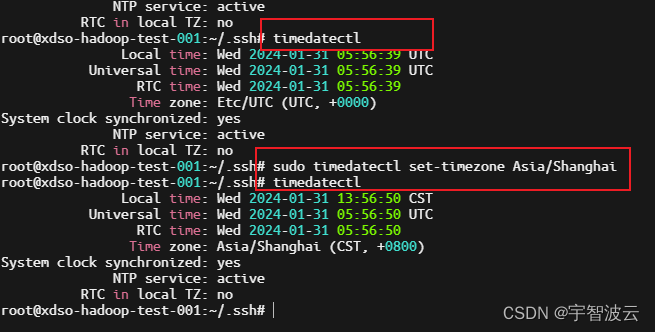
测试环境搭建整套大数据系统(一:基础配置,修改hostname,hosts,免密,时间同步)
一:使用服务器配置。 二:修改服务器名称hostname,hosts。 在 Linux 系统中,hostname 和 /etc/hosts 文件分别用于管理主机名和主机名解析。 在三台服务器上,分别执行以下命令。 vim /etc/hostname xdso-hadoop-test-001 vim /etc/hosts 192.168.50.60 xdso-hadoop-

真果科技贾求真:“双链数据系统确权”引领供应链金融新模式
4月18日,“2019中国产业互联网峰会暨第十一届中国产业链与供应链金融峰会”在上海召开。本次峰会以“产业互联网引领时代发展,金融科技赋能供应链金融,产业链融合提升价值供应链”为主题,聚集行业精英展开深入讨论。 真果科技(原医链科技)创始人兼CEO贾求真受邀出席此次峰会,发表题为《“双链数据系统确权”引领供应链金融新模式》的精彩分享。 贾求真在峰会上分享了真果科技的最佳实践成果,真果科技(原医

如何进行大数据系统测试
大数据系统常见的架构形式有如下几种: Hadoop架构: Hadoop Distributed File System (HDFS):这是一种分布式文件系统,设计用于存储海量数据并允许跨多台机器进行高效访问。 MapReduce:作为Hadoop的核心计算框架,它通过将复杂的计算任务分解为“映射”(map)和“归约”(reduce)阶段,在集群节点上并行执行。 Apache Spark架

数据库原理与统计笔记-1.1数据系统概述
文章目录 前言一、数据库的4个基本概念[1]. 数据(data)[2]. 数据库(DataBase ,DB)[3]. 数据库管理系统(DataBase Management System,DBMS)[4]. 数据库系统(DataBase System,DBS) 二、数据管理技术的产生和发展[1]. 人工管理阶段[2]. 文件系统阶段[3]. 数据库系统阶段 三、数据库系统的特点[1]. 数据
通过聚道云软件连接器实现钉钉与自研主数据系统的完美融合
客户介绍 某知名高校,拥有数千名教职工,日常管理涉及大量的人员异动信息。该高校设有多个学院和研究所,涵盖了工、理、管、文等多个学科领域。该高校是一所充满活力和潜力的学府,致力于为学生提供优质的教育资源和多元化的学习环境。学校将继续努力,为培养更多优秀人才做出贡献。 添加图片注释,不超过 140 字(可选) 客户痛点 该高校人事部门存在以下痛点: ·手工录入繁琐:人事部门需要手动将

区块链+体育发展提速 区块链球员数据系统预计上半年投入使用
2月9日,支付宝公布“支持中国女足发展工作小结”。据披露,支付宝一方面从资金层面支持女足发展,一方面依托技术助力女足数字化管理升级,其正全方位体系化地支持中国女足发展。值得关注的是,支付宝宣布将协助足协开发区块链球员数据系统。 《证券日报》记者注意到,目前数字化技术也正在体育领域“生根发芽”。业内普遍认为,目前区块链技术在我国体育产业尚无广泛落地的应用,不过随着区块链技术的发展,在体育产业的

低代码信创开发核心技术(三):MDA模型驱动架构及元数据系统设计
前言 写最后一篇文章的时候,我本人其实犹豫了半年,在想是否发布出这篇文章,因为可能会动了很多人的利益。所以这篇文章既是整个低代码信创开发的高度总结,也是最为精华的一部分,它点明了低代码中最为核心的技术。虽然你在读这篇文章的时候会有犹抱琵琶半遮面的感觉,但当你领悟之后,会发现原来低代码开发平台的建设是如此的简单。低代码前端设计模型,而设计出来的模型以元数据的方式又能驱动整个系统运行,读完你会发现实

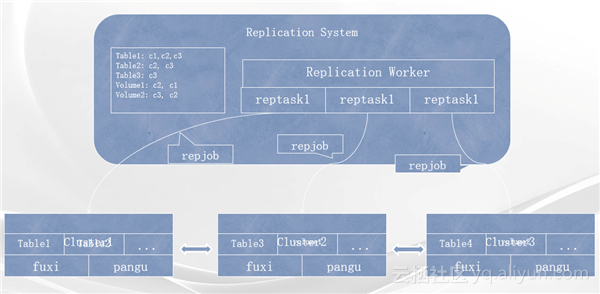
分布式大数据系统巧实现,全局数据调度管理不再难 大数据史记 2017-05-18 13:04:22 浏览63 评论0...
背景 看到这个题目,我们会有很多疑问:什么是分布式大数据系统中的全局数据管理?为什么要从全局对数据进行管理?这种对数据从全局进行分布和调度的策略是在什么样的背景下产生的?如果我们不解决全局数据管理的问题,分布式大数据系统中将会面临一些什么样的风险? 总的来说:基于大数据,云计算的需求,加快了分布式系统的发展;开源分布式系统的发展,让海量数据存储和处理变的简单;产生了很多为了解决特定问题,服务特

数据系统架构-1.基础数据篇
1.基础数据篇 序 (图-本篇文章涉及红框内容,整体架构详见第一篇数据之旅-开篇) 本篇文章主要介绍一下基础数据部分,数据来源主要分成2方面,第一部分介绍一下日志相关内容,第二部分介绍一下业务源表相关,以及在此基础上构建的采集系统与抽象系统,之后再介绍一些常见的问题与对应的解决方案。 总则:基础数据是大数据的基础,规范化、合理、准确的基础数据可以使后续的各类数据应用开发事半功倍。(基础