本文主要是介绍测试环境搭建整套大数据系统(三:搭建集群zookeeper,hdfs,mapreduce,yarn,hive),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:搭建zk
https://blog.csdn.net/weixin_43446246/article/details/123327143
二:搭建hadoop,yarn,mapreduce。
1. 安装hadoop。
sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt
2. 修改java配置路径。
cd /opt/hadoop-3.2.4/etc/hadoop
vim hadoop-env.sh
增加以下内容
export JAVA_HOME=/opt/jdk1.8.0_211
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
java_home填写自己安装的路径。
3. 修改配置文件。
- vim core-site.xml
将以下信息填写到configuration中
<property><name>fs.defaultFS</name><value>hdfs://10.15.250.196:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/hadoop-3.2.4/data</value></property><!-- 该参数表示可以通过 httpfs 接口访问 HDFS 的 IP 地址限制 --><!-- 配置 root(超级用户) 允许通过 httpfs 方式访问 HDFS 的主机名、域名 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!-- 通过 httpfs 接口访问的用户获得的群组身份 --><!-- 配置允许通过 httpfs 方式访问的客户端的用户组 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
- vim hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>10.15.250.202:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>10.15.250.202:50091</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
- vim mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定mapreduce jobhistory地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>10.15.250.196:10020</value>
</property>
<!-- 任务历史服务器的web地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>10.15.250.196:19888</value>
</property>
<!-- 配置运行过的日志存放在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<!-- 配置正在运行中的日志在hdfs上的存放路径 -->
<property>
<name>mapreudce.jobhistory.intermediate.done-dir</name>
<value>/history/done/done_intermediate</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/hadoop-3.2.4/etc/hadoop,
/opt/hadoop-3.2.4/share/hadoop/common/*,
/opt/hadoop-3.2.4/share/hadoop/common/lib/*,
/opt/hadoop-3.2.4/share/hadoop/hdfs/*,
/opt/hadoop-3.2.4/share/hadoop/hdfs/lib/*,
/opt/hadoop-3.2.4/share/hadoop/mapreduce/*,
/opt/hadoop-3.2.4/share/hadoop/mapreduce/lib/*,
/opt/hadoop-3.2.4/share/hadoop/yarn/*,
/opt/hadoop-3.2.4/share/hadoop/yarn/lib/*
</value>
</property>
- vim yarn-site.xml
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-xdso</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>10.15.250.196</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>10.15.250.220</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>10.15.250.196:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>10.15.250.220:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>10.15.250.196:2181,10.15.250.202:2181,10.15.250.220:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- Whether virtual memory limits will be enforced for containers. -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://10.15.250.196:19888/jobhistory/logs/</value>
</property>- vim workers
10.15.250.196
10.15.250.202
10.15.250.220
4. copy到其他节点。
cd /opt
scp -r hadoop-3.2.4/ root@hadoop101:`pwd`
scp -r hadoop-3.2.4/ root@hadoop101:`pwd`
5.三台机器全部配置环境变量。
#hadoop
export HADOOP_HOME=/opt/hadoop-3.2.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etcprofile
6. 进行初始化,启动。
- 启动zk
三台机器全部执行
zkServer.sh start
- 在node01执行 格式化NameNode 。
hdfs namenode -format
- 在node01执行 启动hdfs
start-dfs.sh
- 在node01执行 启动yarn
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
7. 检验
jps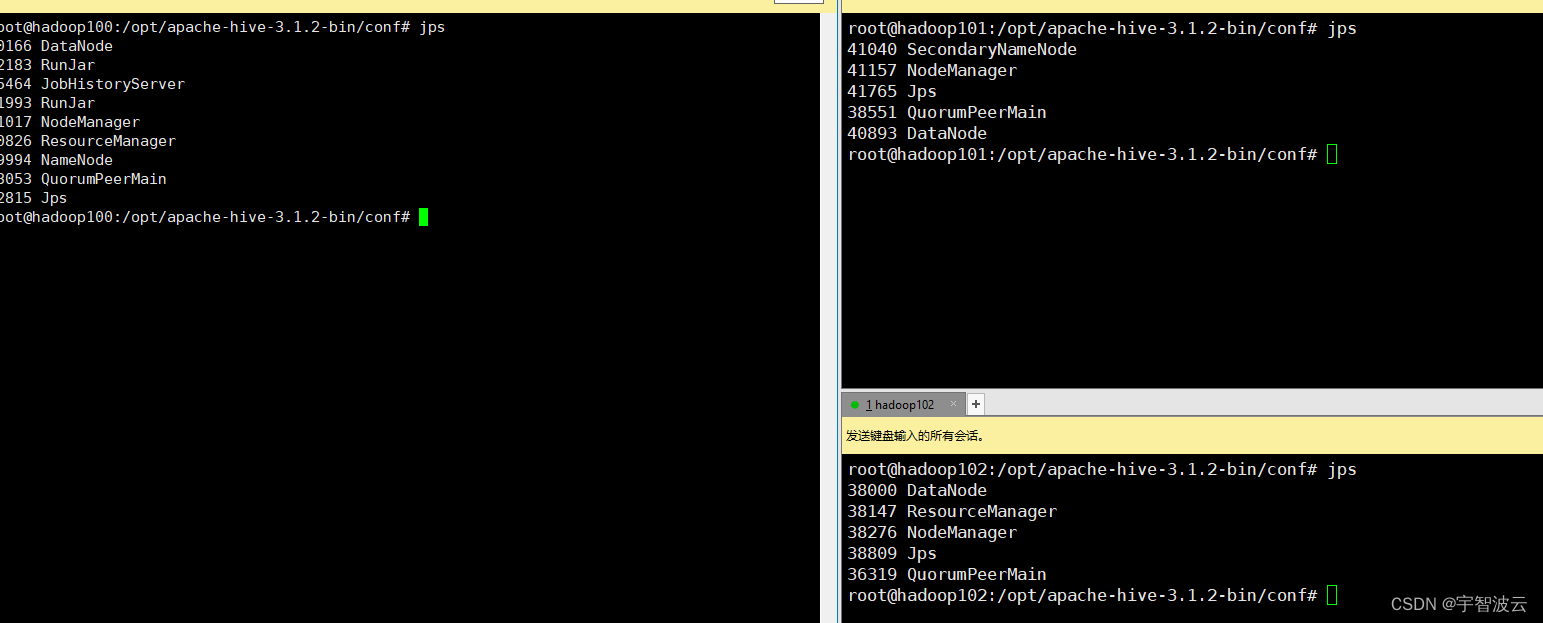
登录页面查看
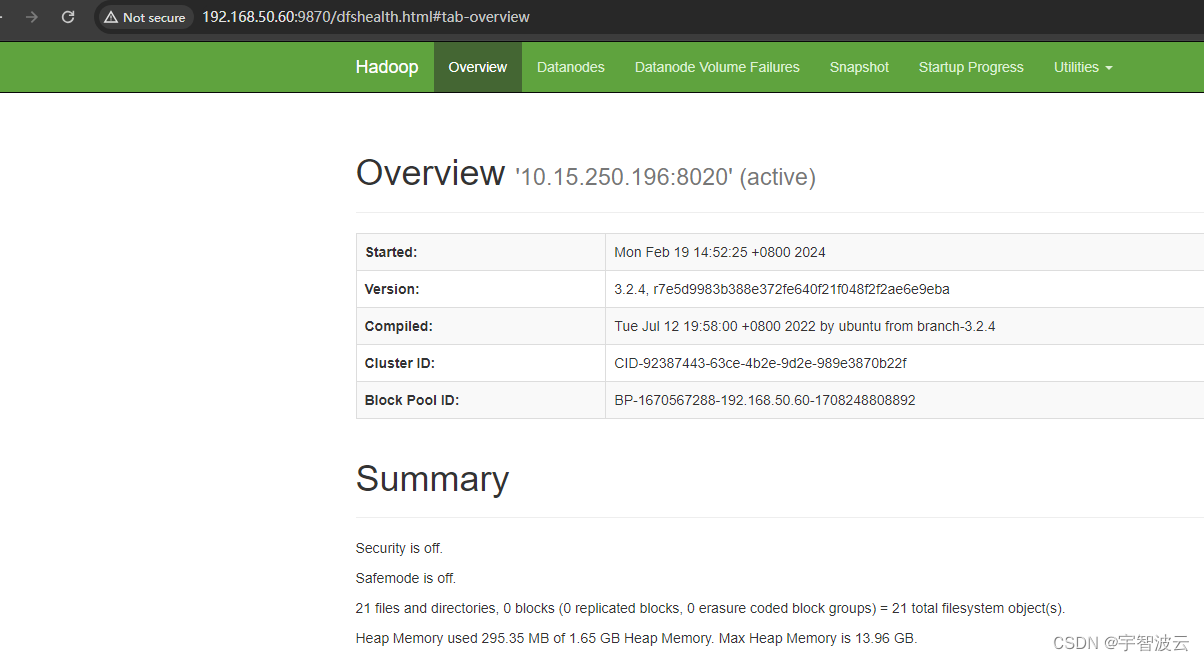
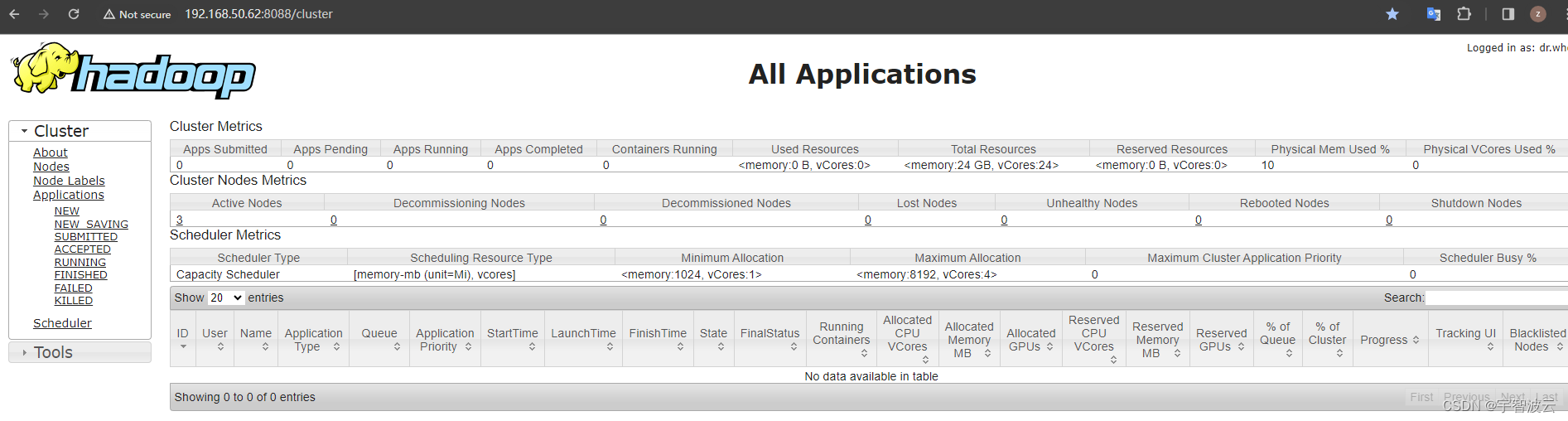
三:搭建hive
1. 提前安装mysql。
https://blog.csdn.net/weixin_43446246/article/details/135953602
2. 下载,解压hive。
wget https://dlcdn.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt
3. 配置文件
- 修改环境配置脚本文件 hive-env.sh
cd /opt/apache-hive-3.1.2-bin/conf/cp hive-env.sh.template hive-env.shvim hive-env.sh
HADOOP_HOME=/opt/hadoop-3.2.4/
export HIVE_CONF_DIR=/opt/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/opt/apache-hive-3.1.2-bin/lib
- 修改配置文件 hive-site.xml
cp hive-default.xml.template hive-site.xmlvim hive-site.xml
<!-- 数据库相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.15.250.196:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- 自动创建表 -->
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<!-- 强制 MetaStore 的 schema 一致性,开启的话会校验在 MetaStore 中存储的信息的版本和 Hive 的 jar 包中的版本一致性,并且关闭自动
schema 迁移,用户必须手动的升级 Hive 并且迁移 schema。关闭的话只会在版本不一致时给出警告,默认是 false 不开启 -->
<!-- 元数据校验 -->
<property>
<name>hive.metastore.schema.verification</name>
<!-- MySQL8 这里一定要设置为 true,不然后面 DROP TABLE 可能会出现卡住的情况 -->
<value>true</value>
</property>
<!-- 美化打印数据 -->
<!-- 是否显示表名与列名,默认值为 false -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 是否显示数据库名,默认值为 false -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- Hive 数据仓库的位置(HDFS 中的位置) -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
<!-- HiveServer2 通过 Thrift 访问 MetaStore -->
<!-- 配置 Thrift 服务绑定的服务器地址,默认为 127.0.0.1 -->
<!--
<property>
<name>hive.server2.thrift.bind.host</name>
<value>127.0.0.1</value>
</property>
-->
<!-- 配置 Thrift 服务监听的端口,默认为 10000 -->
<!--
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
-->
<!-- HiveServer2 的 WEBUI -->
<property>
<name>hive.server2.webui.host</name>
<value>10.15.250.196</value>
</property>
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
</property>
<!-- 指定 hive.metastore.uris 的 port,为了启动 MetaStore 服务的时候不用指定端口 -->
<!-- hive ==service metastore -p 9083 & | hive ==service metastore -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://10.15.250.196:9083</value>
</property>
- 配置日志组件,
mkdir /opt/apache-hive-3.1.2-bin/logs
cp hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.properties将 property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name} 替换为
property.hive.log.dir = /opt/yjx/apache-hive-3.1.2-bin/logs
- 添加驱动包
将mysql驱动包,放到对应的目录下。
mv mysql-connector-java-8.0.18.jar /opt/apache-hive-3.1.2-bin/lib/
jar包冲突
cp /opt/hadoop-3.2.4/share/hadoop/common/lib/guava-27.0-jre.jar /opt/apache-hive-3.1.2-bin/lib/
rm /opt/apache-hive-3.1.2-bin/lib/guava-19.0.jar
5.copy到其他服务器上,三台配置环境变量。
cd /opt/
scp apache-hive-3.1.2-bin/ root@hadoop101:`pwd`
scp apache-hive-3.1.2-bin/ root@hadoop102:`pwd`
三台机器配置环境变量
vim /etc/profile
#hive
export HIVE_HOME=/opt/apache-hive-3.1.2-bin
export HIVE_CONF_DIR=$HIVE_HOME/bin
export PATH=$HIVE_HOME/bin:$PATH
6. 初始化。
- 检查mysql是否启动。
- 启动 ZooKeeper(三台机器都需要执行)。
- 启动 HDFS + YARN。
start-all.sh
- 启动 JobHistory。
mapred --daemon start historyserver
- 初始化 hive 数据库(第一次启动时执行)。
schematool -dbType mysql -initSchema
- 启动hive。
nohup hive --service metastore > /dev/null 2>&1 &
nohup hiveserver2 > /dev/null 2>&1 &
这篇关于测试环境搭建整套大数据系统(三:搭建集群zookeeper,hdfs,mapreduce,yarn,hive)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







