zookeeper专题

Java使用Curator进行ZooKeeper操作的详细教程
《Java使用Curator进行ZooKeeper操作的详细教程》ApacheCurator是一个基于ZooKeeper的Java客户端库,它极大地简化了使用ZooKeeper的开发工作,在分布式系统... 目录1、简述2、核心功能2.1 CuratorFramework2.2 Recipes3、示例实践3

Zookeeper安装和配置说明
一、Zookeeper的搭建方式 Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式。 ■ 单机模式:Zookeeper只运行在一台服务器上,适合测试环境; ■ 伪集群模式:就是在一台物理机上运行多个Zookeeper 实例; ■ 集群模式:Zookeeper运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”(ensemble) Zookeeper通过复制来实现
搭建Kafka+zookeeper集群调度
前言 硬件环境 172.18.0.5 kafkazk1 Kafka+zookeeper Kafka Broker集群 172.18.0.6 kafkazk2 Kafka+zookeeper Kafka Broker集群 172.18.0.7 kafkazk3

ZooKeeper 中的 Curator 框架解析
Apache ZooKeeper 是一个为分布式应用提供一致性服务的软件。它提供了诸如配置管理、分布式同步、组服务等功能。在使用 ZooKeeper 时,Curator 是一个非常流行的客户端库,它简化了 ZooKeeper 的使用,提供了高级的抽象和丰富的工具。本文将详细介绍 Curator 框架,包括它的设计哲学、核心组件以及如何使用 Curator 来简化 ZooKeeper 的操作。 1

zookeeper相关面试题
zk的数据同步原理?zk的集群会出现脑裂的问题吗?zk的watch机制实现原理?zk是如何保证一致性的?zk的快速选举leader原理?zk的典型应用场景zk中一个客户端修改了数据之后,其他客户端能够马上获取到最新的数据吗?zk对事物的支持? 1. zk的数据同步原理? zk的数据同步过程中,通过以下三个参数来选择对应的数据同步方式 peerLastZxid:Learner服务器(Follo

设置zookeeper开机自启动/服务化
设置启动zk的用户为zookeeper 设置启动zk的用户为zookeeper用户,而非root用户,这样比较安全。 可以使用root用户进行zookeeper的管理(启动、停止…),但对于追求卓越和安全的的人来说,采用新非root用户管理zookeeper更好。 步骤: 1. 创建用户和用户组 2. 相关目录设置用户和用户组属性 3. 采用zookeeper用户启动进程 设置z
Zookeeper集群是如何升级到新版本的
方案1:复用老数据方案 这是经过实践的升级方案,该方案是复用旧版本的数据,zk集群拓扑,配置文件都不变,只是启动的程序为最新的版本。 参考文章: Zookeeper集群是如何升级到新版本的 方案2:重新建立数据方案 该方案的思路是:先停掉一台follower的机器上的服务,然后加入一个新版本的zk(zk的数据目录是空的),然后启动新zk,之后新zk会把旧集群中的数据同步过来。之后再操作另

Zookeeper基本原理
1.什么是Zookeeper? Zookeeper是一个开源的分布式协调服务器框架,由Apache软件基金会开发,专为分布式系统设计。它主要用于在分布式环境中管理和协调多个节点之间的配置信息、状态数据和元数据。 Zookeeper采用了观察者模式的设计理念,其核心职责是存储和管理集群中共享的数据,并为各个节点提供一致的数据视图。在Zookeeper中,客户端(如
一、什么是Zookeeper
原文: GitHub:https://github.com/wangzhiwubigdata/God-Of-BigData关注公众号,内推,面试,资源下载,关注更多大数据技术~大数据成神之路~预计更新500+篇文章,已经更新50+篇~ 张大胖所在的公司这几年发展得相当不错,业务激增,人员也迅速扩展,转眼之间,张大胖已经成为公司的“资深”员工了,更重要的是,经过这些年的不懈努力,他终于
三、Zookeeper典型应用场景及实践
因编辑原因图片不显示,请戳GitHub原文: https://github.com/wangzhiwubigdata/God-Of-BigData关注公众号,内推,面试,资源下载,关注更多大数据技术~大数据成神之路~预计更新500+篇文章,已经更新50+篇~ Zookeeper 从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受

ZooKeeper在HBase集群中的作用
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! ZooKeeper作为分布式协调组件,在大数据领域的其他分布式组件中往往扮演着重要的辅助角色,因此我们就算不单独去研究ZooKeeper,也短不了要接触它。本文就以最典型的HBase为例,简要介绍ZooKeeper为HBase
linux下安装配置zookeeper
1.下载zookeeper download zookeeper from www 2.安装Jre环境 export ZOOKEEPER_INSTALL=/software/zookeeper/zookeeper-3.4.9export PATH=$PATH:$ZOOKEEPER_INSTALL/binexport JRE_HOME=your java path 3.配置启动 cd
zookeeper/dubbo使用记录
zookeeper版本号:zookeeper-3.4.6 在windows上使用的时候将 1,conf目录下的zoo_sample.cfg名字修改为zoo.cfg,里面内容可以不变 2,执行bin目录下的zkServer.cmd 这样zookeeper服务就启动了。 自己在本地使用zookeeper与dubbo时行接口调用时使用的时需要的部分jar包: dubbo-

面试题:Zookeeper是如何解决脑裂问题
前言 这是分布式系统中一个很实际的问题,书上说的不是很详细,整理总结一下。 1、脑裂和假死 1.1 脑裂 官方定义:当一个集群的不同部分在同一时间都认为自己是活动的时候,我们就可以将这个现象称为脑裂症状。通俗的说,就是比如当你的 cluster 里面有两个结点,它们都知道在这个 cluster 里需要选举出一个 master。那么当它们两之间的通信完全没有问题的时候,就会达成共识,选出其中
从Paxos到Zookeeper(三)
前言 前面已经介绍了Paxos,这章开始学习Paxos在Zookeeper中的应用,主要介绍ZAB协议,Chubby和Hypertable估计也接触不到,这里先简单介绍下Zookeeper。 1、Zookeeper简介 相信大部分从事分布式开发项目的人都有过使用经验,其设计目标是将那些复杂且容易出错的分布式服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用,分布式

从Paxos到Zookeeper(二)
前言 这个月公司风波很多,比较忙,心态也有些变化,一个月没更了,终归还是要沉淀下来工作学习呀,继续学习Paxos。前面已经介绍了2PC和3PC,并了解了它们各自的特点以及解决的分布式问题,接着,我们来介绍Paxos:一种基于消息传递且具有高度容错性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法。 1、背景 在常见的分布式系统中,设计者必须要考虑的一个问题就是节点宕机或网络异常,这
从Paxos到Zookeeper(一)
前言 随着计算器系统规模变得越来越大,计算机系统正在经历一场前所未有的从集中式到分布式架构的变革,相信有过分布式开发经验的都能明白其痛点--分布式一致性。Zookeeper的出现帮助很多系统在一定程度上解决了这个难点,使用也非常简单,作为分布式一致性问题的工业解决方案,paxos是理论算法,其中zab,raft和众多开源算法是对paxos的工业级实现。这本书是本人很早就想看的书了,
docker 启动 wurstmeister/zookeeper出错:be owned by root and not group or world-writable docker zookeep
总有一些意想不到的问题,别的环境都好好的,这个环境就是不行,启动脚本 docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper 发现 zookeeper启动后直接退出。查看日志 >> docker logs zookeeper>> /var/run/sshd must be owned by root and
《Zookeeper 的监听机制及原理解析》
一、引言 在分布式系统中,协调和管理各个节点的状态是一项至关重要的任务。ZooKeeper 作为一个开源的分布式协调服务,被广泛应用于众多分布式系统中,如 Hadoop、HBase、Kafka 等。其中,ZooKeeper 的监听机制是其实现分布式协调的关键特性之一,它允许客户端在特定的节点上设置监听器,当节点的数据发生变化或者子节点发生变化时,客户端能够及时收到通知并做出相应的处理。本文将

Kafka【六】Linux下安装Kafka(Zookeeper)集群
Kafka从早期的消息传输系统转型为开源分布式事件流处理平台系统,所以很多核心组件,核心操作都是基于分布式多节点的。本文这里采用三台虚拟机模拟真实物理主机搭建Zookeeper集群和kafka集群。 VMware可以使用户在一台计算机上同时运行多个操作系统,还可以像Windows应用程序一样来回切换。用户可以如同操作真实安装的系统一样操作虚拟机系统,甚至可以在一台计算机上将几个虚拟机系统连接为一
在 CentOS 上安装 zookeeper-3.4.9 服务
http://www.cnblogs.com/hapday/p/5854907.html 在 CentOS7 上安装 zookeeper-3.4.9 服务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29

zookeeper单机版安装
环境:centos6.4 zookeeper-3.4.6 安装之前需要先安装jdk,请自行百度安装 1、上传 zookeeper-3.4.6.tar.gz 到/local 目录 2、解压文件: # tar zxf zookeeper-3.4.6.tar.gz 查看是否解压成功: 在zookeeper根目录下面新建data目录: cd conf目录: 修改zo
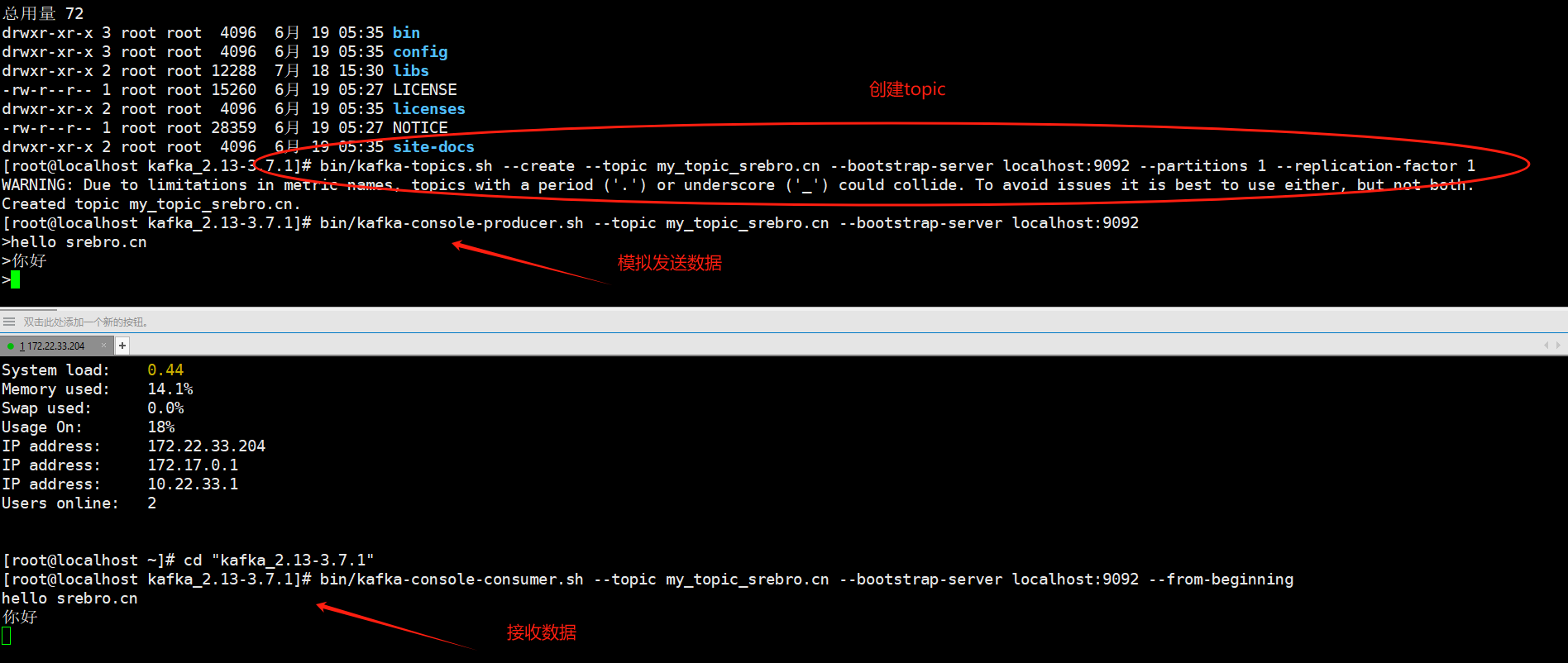
KRaft模式下的Kafka启动指南:摆脱Zookeeper依赖
一、背景介绍 多年来,人们一直在同时使用Apache ZooKeeper和Apache Kafka。但是自Apache Kafka 3.3发布以来,它就可以在没有ZooKeeper的情况下运行。同时它包含了新的命令kafka-metadata-quorum和kafka-metadata-shell?该如何安装新版kafka,以及如何使用新命令,在本文中,我将回答这些和其他相关的问题。 历史背景

大数据修炼之Zookeeper
文章目录 概述原理客户端命令节点集群分布式锁实现 https://zookeeper.apache.org/ 概述 分布式系统资源协调服务中间件。 从设计模式角度看,zk是一个基于观察者设计模式的分布式服务管理框架,接受观察者注册,负责储存管理关心的数据,接受观察者注册。 zk=文件系统+通知机制 特点: 一致性,最终一致性原子性单一视图,无论是连到哪个节点,数据是一致

zookeeper做成windows服务启动
zookeeper下载安装 首先去官网下载zookeeper 注意:zookeeper的安装路径一定不要有空格,作者之前就是因为安装在D:\Program Files\zookeeper-3.4.10路径下,路径中有空格(Program Files中间有空格)解决了很长时间,想尽各种办法,最后发现TMD的是空格原因 配置环境变量 添加ZOOKEEPER_SERVICE, ZOOKE

Spring Boot集成dubbo+zookeeper
版本环境 名称版本号JDK1.8Spring Boot1.5.8dubbo2.5.6zookeeper3.4.9zkclient0.2Nodejs0.2Vue2.0Maven3.0.5IDEA2018.3 Zookeeper ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务。很多中间件,比如Kafka、Hadoop、HBase,都用到了 Zookeeper。可以说在分布式系