本文主要是介绍KRaft模式下的Kafka启动指南:摆脱Zookeeper依赖,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景介绍
多年来,人们一直在同时使用Apache ZooKeeper和Apache Kafka。但是自Apache Kafka 3.3发布以来,它就可以在没有ZooKeeper的情况下运行。同时它包含了新的命令kafka-metadata-quorum和kafka-metadata-shell?该如何安装新版kafka,以及如何使用新命令,在本文中,我将回答这些和其他相关的问题。
历史背景和时间线
很久以前,Apache Kafka 服务器是一项独立的服务:一个简单而实用的应用程序,很快就受到许多人的喜爱。但是,它缺乏高可用性和复原能力。系统管理员解决该问题的标准方法通常是创建多个代理副本以进行复制,并由知名技术 Apache ZooKeeper 协调,该技术很快成为标准 Kafka 部署的一部分,两者共生。标准方法通常是创建多个代理副本用于复制目的,通过Apache ZooKeeper进行协调,该技术很快成为标准Kafka部署的一部分,两者协同工作。
尽管如此,Apache ZooKeeper 并非万无一失的解决方案。随着时间的推移,Apache Kafka 技术的弹性、可扩展性和性能期望发生了变化,导致了更加严格的需求。进行了许多变更,其中最重要的是将消费者偏移量从 ZooKeeper 迁移到 Kafka,逐步在 Kafka 工具中删除 ZooKeeper 连接主机,并实现了著名的 KIP-500(Kafka 改进提案 500)。
KIP-500 从 2.8 版本开始出现,当时 Kafka Raft(KRaft,Apache Kafka 用于管理元数据的共识协议 Raft 实现)作为早期访问功能出现,尽管它在 2022 年 10 月 3 日被标记为生产就绪。从 ZooKeeper 到 KRaft 功能的早期访问迁移计划在 Kafka 3.4 中发布。其生产就绪版本计划在 Kafka 3.5 版本中发布,同时弃用 ZooKeeper 支持。最后,计划是从 Kafka 4.0 开始的所有部署在没有 ZooKeeper 的情况下运行。
| Kafka version | State |
|---|---|
| 2.8 | KRaft early access |
| 3.3 | KRaft production-ready |
| 3.4 | Migration scripts early access |
| 3.5 | Migration scripts production-ready; use of ZooKeeper deprecated |
| 4.0 | ZooKeeper not supported |
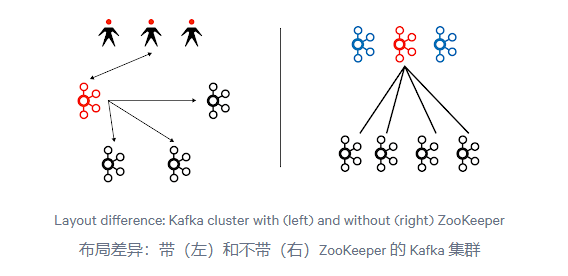
在没有 ZooKeeper 的情况下设置 Kafka 集群,会有一种特殊类型的服务器 - 控制器(controller)。控制器服务器形成一个集群仲裁(quorum)。集群使用 KRaft 算法(我们不在范围内讨论算法的理论描述,更多详情请参考 KRaft 文档或 Raft 文档)选择一个领导者,该领导者开始为连接以拉取集群状态元数据的其他代理(broker)服务的请求提供服务。代理的模型已经发生了变化:以前,活动的控制器将更改推送到代理,而现在代理从领导者控制器中拉取元数据。
Kafka 社区在其最新发布版本中实现了许多内部更改,其中这些是最重要的之一:
- Kafka 集群的扩展限制已得到解决:Kafka 可以处理更多的主题和分区,并且启动和恢复时间得到了显着改善。Kafka 控制器不需要从 ZooKeeper 中读取所有的元数据 — 每个控制器都在本地保存元数据,这节省了将集群恢复运行所需的宝贵时间。
- 使用 Kafka 技术的知识要求和生产设置比同时使用 Kafka 和 ZooKeeper 更简单,因为每种技术都需要设置系统配置、安全性、可观察性、日志记录等。技术越少,依赖关系和相互连接就越少。
二、Kafka 如何下载
官网地址: https://kafka.apache.org/
目前Kafka最新的版本就是3.7.1
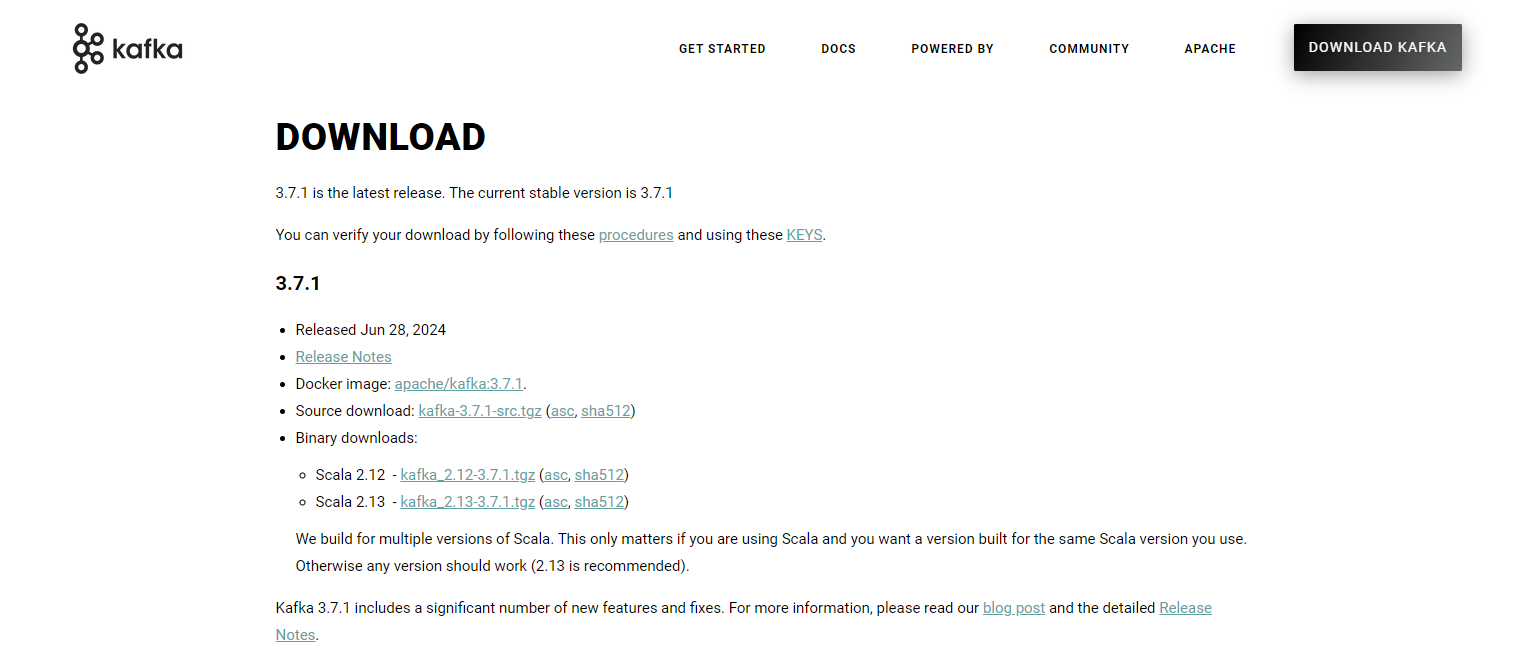
可以看到下面这两个版本信息?
-
Scala 2.12 - kafka_2.12-3.7.1.tgz
-
Scala 2.13 - kafka_2.13-3.7.1.tgz
我们知道,一个完整的Kafka实例,至少包含了3部分:
-
生产者-Producer ,Broker,生产者-Consumer
其中生产者和消费者是使用Java语言,Broker则是使用的Scala语言,这样是不是就明白了。2.12和2.13其实就是说的Scala的版本,3.7.1就是Kafka真正的正式版本号。
国内下载加速地址
- kafka3.7.1 包下载地址: https://mirrors.nju.edu.cn/apache/kafka/3.7.1/kafka_2.13-3.7.1.tgz
- openjdk11.0.2 下载地址: https://mirrors.nju.edu.cn/openjdk/11.0.2/openjdk-11.0.2_linux-x64_bin.tar.gz
三、安装Java环境
#创建openjdk 工作目录
mkdir -p /home/application#下载软件包
wget https://mirrors.nju.edu.cn/openjdk/11.0.2/openjdk-11.0.2_linux-x64_bin.tar.gz#解压至/home/application目录下
tar -xf openjdk-11.0.2_linux-x64_bin.tar.gz -C /home/application#查看jdkls -l /home/application/jdk-11.0.2/
总用量 28
drwxr-xr-x 2 root root 4096 7月 3 2023 bin
drwxr-xr-x 4 root root 4096 7月 3 2023 conf
drwxr-xr-x 3 root root 4096 7月 3 2023 include
drwxr-xr-x 2 root root 4096 7月 3 2023 jmods
drwxr-xr-x 72 root root 4096 7月 3 2023 legal
drwxr-xr-x 6 root root 4096 7月 3 2023 lib
-rw-r--r-- 1 root root 1214 1月 18 2019 release#配置全局的环境变量
【需要注意⚠️从 JDK 9 开始 OpenJDK 和 Oracle JDK 都不再单独提供 JRE(Java 运行时环境),就不需要指定jre的环境变量了】vim /etc/profileexport JAVA_HOME=/home/application/jdk-11.0.2
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH#使环境变量生效
souce /etc/profile##验证java环境
[root@localhost ~]# java -version
openjdk version "11.0.2" 2019-01-15
OpenJDK Runtime Environment 18.9 (build 11.0.2+9)
OpenJDK 64-Bit Server VM 18.9 (build 11.0.2+9, mixed mode)
四、KRaft模式下启动Kafka
#创建kafka工作目录
mkdir -p /home/application#下载软件包
wget https://mirrors.nju.edu.cn/apache/kafka/3.7.1/kafka_2.13-3.7.1.tgz#解压软件包至/home/application
tar -xf kafka_2.13-3.7.1.tgz -C /home/application#查看kafka3.7.1包下内容ls -l /home/application/kafka_2.13-3.7.1
总用量 80
drwxr-xr-x 3 root root 4096 7月 18 15:05 bin
drwxr-xr-x 3 root root 4096 7月 18 14:57 config
drwxr-xr-x 3 root root 4096 7月 18 15:24 kraft-combined-logs
drwxr-xr-x 2 root root 12288 7月 18 14:56 libs
-rw-r--r-- 1 root root 15260 6月 19 05:27 LICENSE
drwxr-xr-x 2 root root 4096 6月 19 05:35 licenses
drwxr-xr-x 2 root root 4096 7月 18 15:06 logs
-rw-r--r-- 1 root root 28359 6月 19 05:27 NOTICE
drwxr-xr-x 2 root root 4096 6月 19 05:35 site-docs#备份并修改config/kraft目录下的server.propertiescd /home/application/kafka_2.13-3.7.1/config/kraftcp server.properties server.properties-bak#修改配置文件,指定log.dirs 位置 和 advertised.listeners 监听地址【内网IP地址】vim server.properties.........log.dirs=/home/application/kafka_2.13-3.7.1/kraft-combined-logsadvertised.listeners=PLAINTEXT://172.22.33.204:9092#生成存储目录唯一ID
[root@localhost bin]# /home/application/kafka_2.13-3.7.1/bin/kafka-storage.sh random-uuid
PgJbkdolTTywNePn8TBr6g#拿着得到的uuid,格式化存储目录
[root@localhost bin]# /home/application/kafka_2.13-3.7.1/bin/kafka-storage.sh format -t PgJbkdolTTywNePn8TBr6g -c /home/application/kafka_2.13-3.7.1/config/kraft/server.properties#使用systemd配置kafka开机自启动
vim /etc/systemd/system/kafka.service
[Unit]
Description=kafka
Requires=network.target
After=network.target[Service]
Environment="JAVA_HOME=/home/application/jdk-11.0.2"
ExecStart=/home/application/kafka_2.13-3.7.1/bin/kafka-server-start.sh /home/application/kafka_2.13-3.7.1/config/kraft/server.properties
ExecStop=/home/application/kafka_2.13-3.7.1/bin/kafka-server-stop.sh[Install]
WantedBy=multi-user.target#systemd-reload,并添加开机自启动
chmod +x /etc/systemd/system/kafka.service
systemctl enable kafka
systemctl start kafka
systemctl status kafka
五、kafka测试发送和接收消息
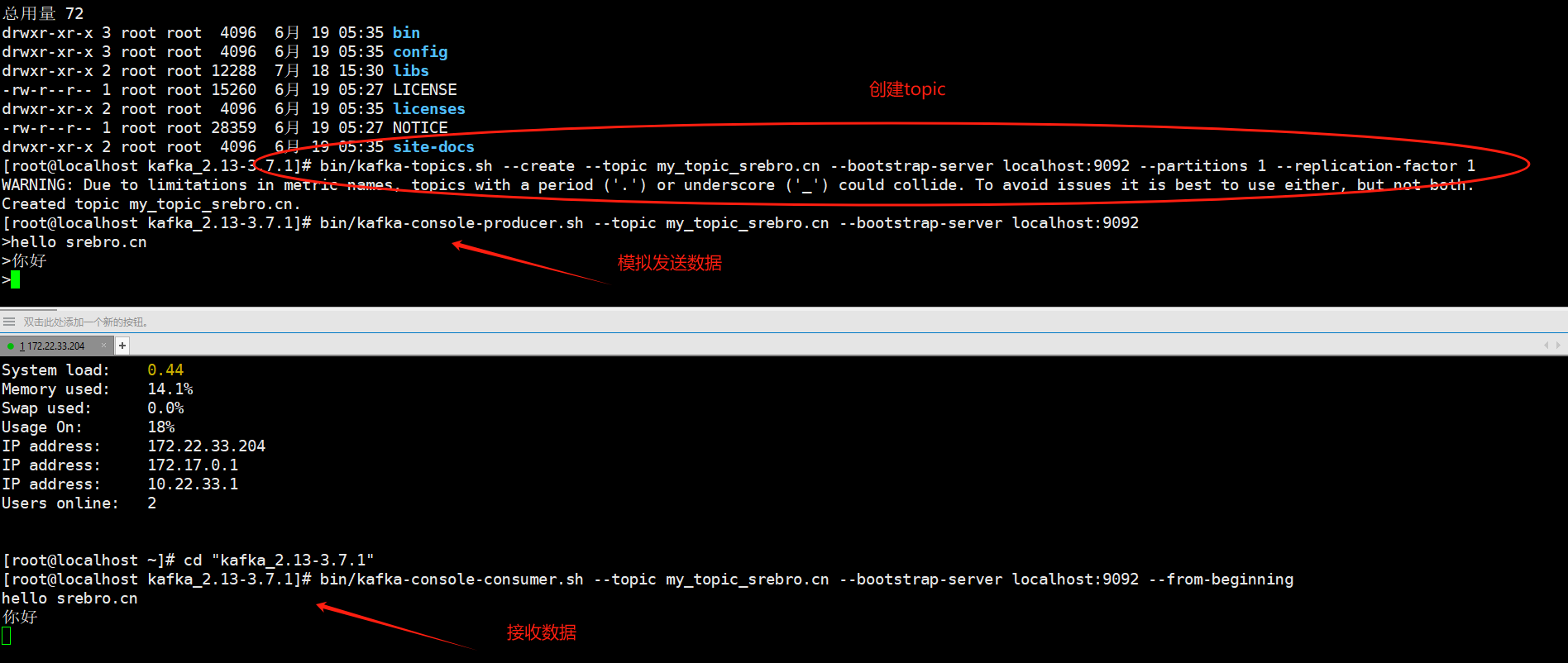
创建一个主题:Kafka使用主题来组织消息。可以使用以下命令创建一个主题:
bin/kafka-topics.sh --create --topic my_topic_srebro.cn --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
发送消息:使用生产者客户端发送消息到Kafka主题。可以使用以下命令发送消息:
bin/kafka-console-producer.sh --topic my_topic_srebro.cn --bootstrap-server localhost:9092
接收消息:使用消费者客户端接收Kafka主题中的消息。可以使用以下命令接收消息:
bin/kafka-console-consumer.sh --topic my_topic_srebro.cn --bootstrap-server localhost:9092 --from-beginning
六、参考
- https://redpanda.com/guides/kafka-tutorial/kafka-without-zookeeper
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 运维小弟
这篇关于KRaft模式下的Kafka启动指南:摆脱Zookeeper依赖的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





