本文主要是介绍【Hudi】核心概念,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://www.bilibili.com/video/BV1ue4y1i7na?p=17&vd_source=fa36a95b3c3fa4f32dd400f8cabddeaf
大数据新风口:Hudi数据湖(尚硅谷&Apache Hudi联合出品)
1 基础概念
1.1 时间轴(TimeLine)
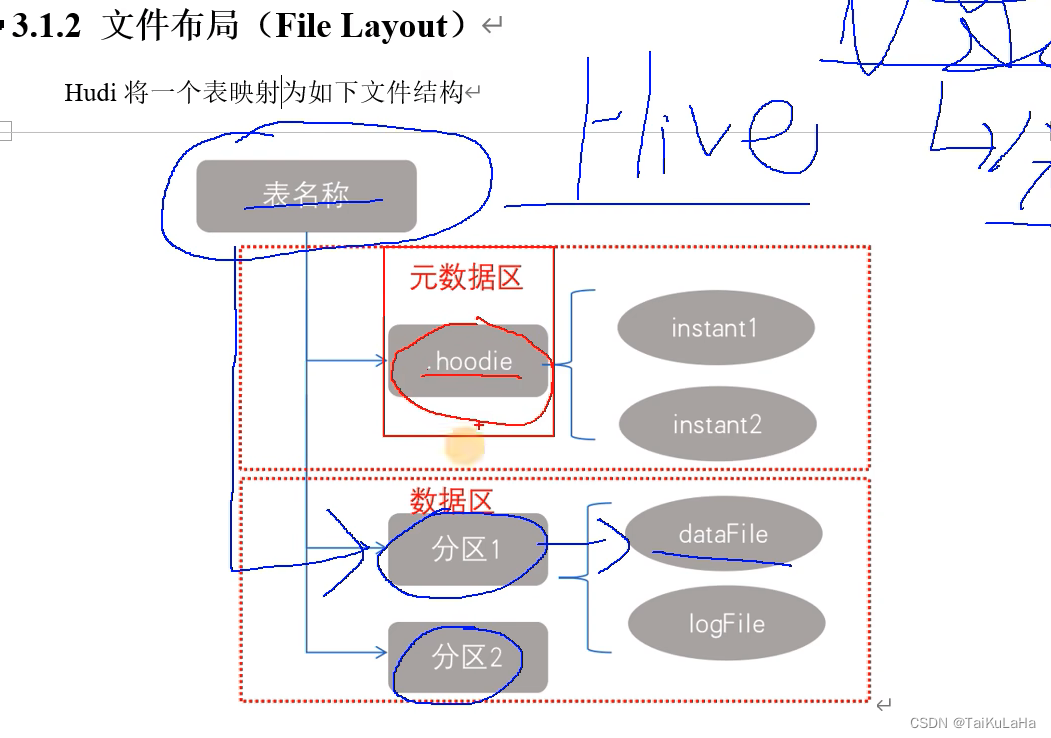
1.2 文件布局(File Layout)
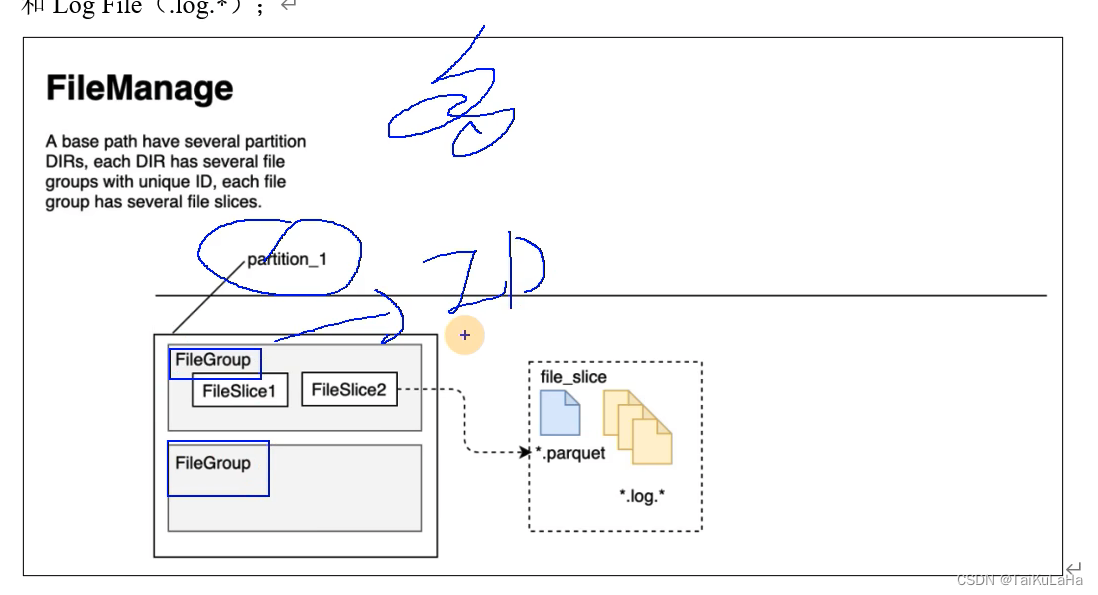
1.3 索引(Index)

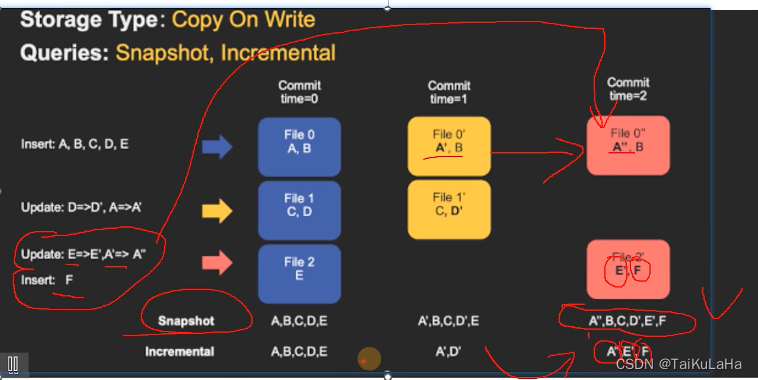
1.4 表类型(Table Types)
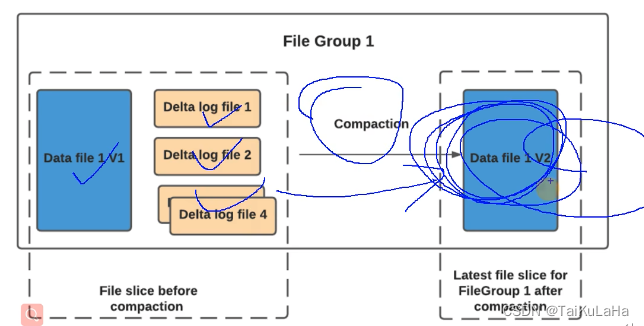
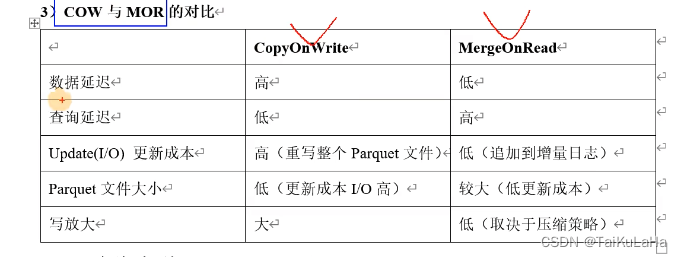
COW (Copy on write) 只有列存基础数据文件*.parquet,没有行级的增量日志*.log文件, 每一个批次写完都会生成新的FileSlice。不需要其他tableservice(比如compact)
MOR(Merge on read) 有列存基础数据文件*.parquet 和行级的增量日志*.log文件
1.5 查询类型 (Query Types)
-
Snapshot query 最新快照数据
-
Increment query
-
Read Optimized query 对MOR只读到最新parquet 为合并的log读不到



这篇关于【Hudi】核心概念的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







