本文主要是介绍【Hudi】Upsert原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
17张图带你彻底理解Hudi Upsert原理
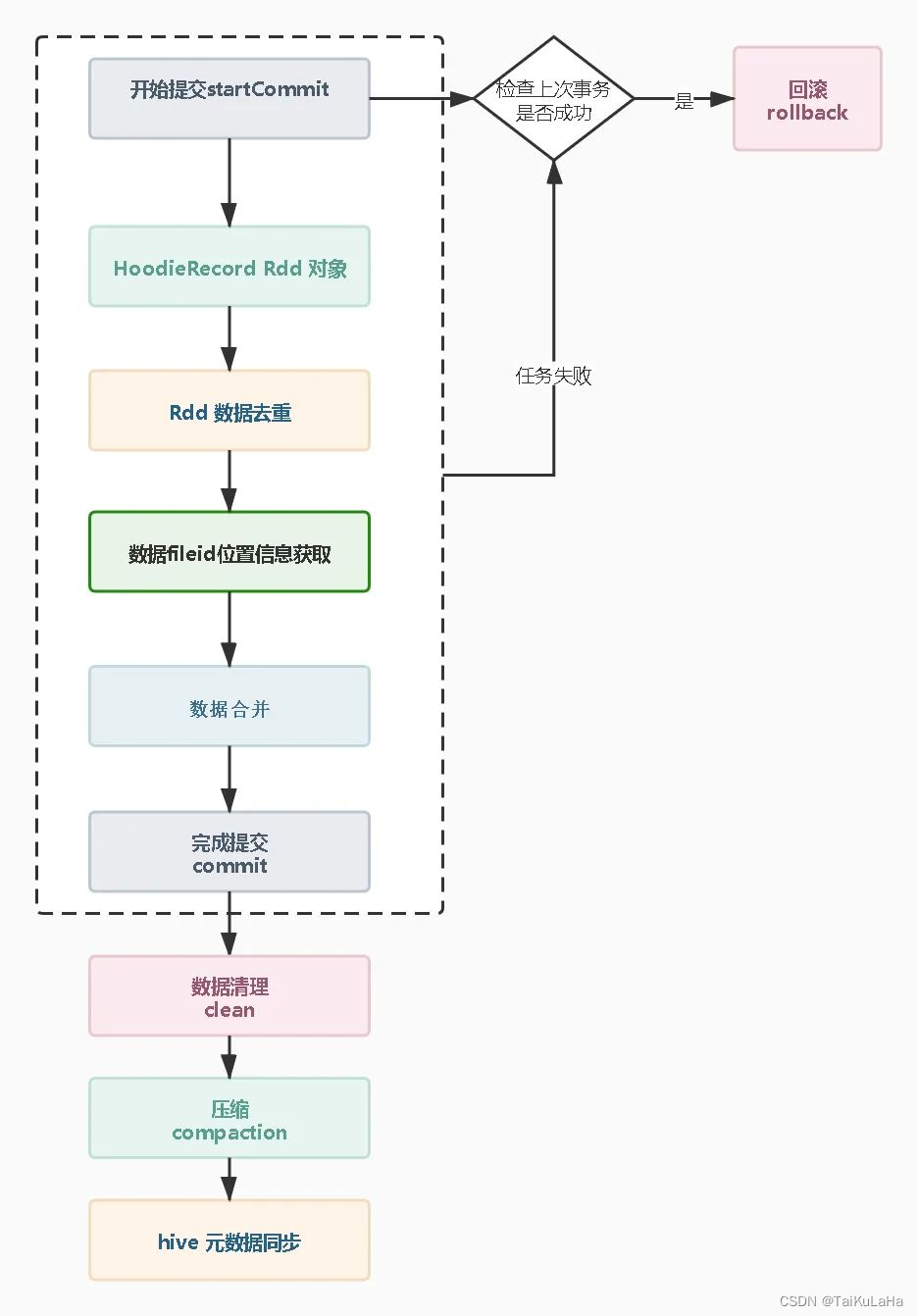
1.开始提交:判断上次任务是否失败,如果失败会触发回滚操作。然后会根据当前时间生成一个事务开始的请求标识元数据。2.构造HoodieRecord Rdd对象:Hudi 会根据元数据信息构造HoodieRecord Rdd 对象,方便后续数据去重和数据合并。3.数据去重:一批增量数据中可能会有重复的数据,Hudi会根据主键对数据进行去重避免重复数据写入Hudi 表。4.数据fileId位置信息获取:在修改记录中可以根据索引获取当前记录所属文件的fileid,在数据合并时需要知道数据update操作向那个fileId文件写入新的快照文件。5.数据合并:Hudi 有两种模式cow和mor。在cow模式中会重写索引命中的fileId快照文件;在mor 模式中根据fileId 追加到分区中的log 文件。6.完成提交:在元数据中生成xxxx.commit文件,只有生成commit 元数据文件,查询引擎才能根据元数据查询到刚刚upsert 后的数据。7.compaction压缩:主要是mor 模式中才会有,他会将mor模式中的xxx.log 数据合并到xxx.parquet 快照文件中去。8.hive元数据同步:hive 的元素数据同步这个步骤需要配置非必需操作,主要是对于hive 和presto 等查询引擎,需要依赖hive 元数据才能进行查询,所以hive元数据同步就是构造外表提供查询。
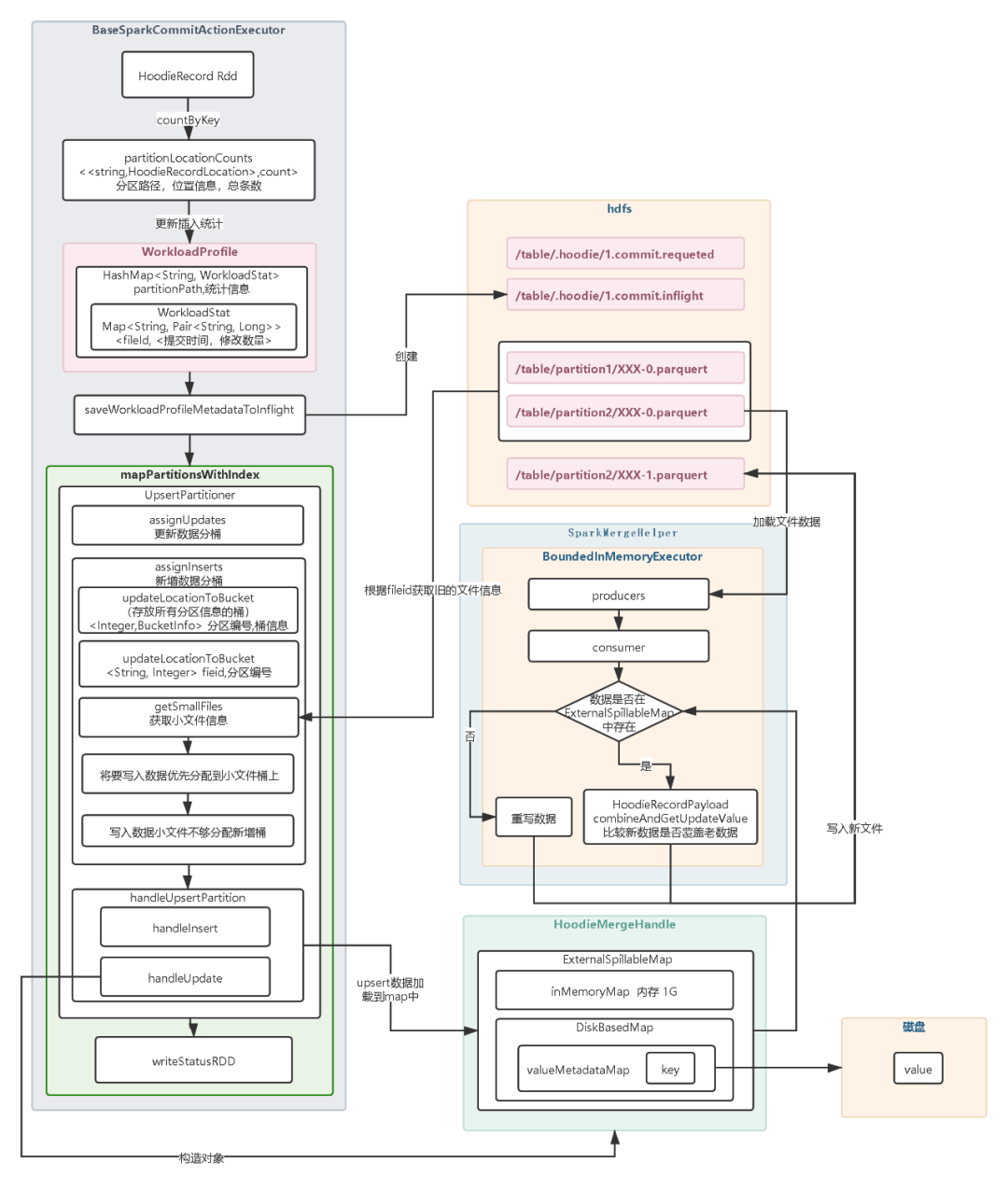
2.5.1 Copy on Write模式
COW模式数据合并实现逻辑调用BaseSparkCommitActionExecutor#excute方法,实现步骤如下:
这篇关于【Hudi】Upsert原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





