hadoop3专题

Hadoop3.x中一把锁毁灭的大数据集群
集群版本:HDP3.1.5 Hadoop版本:Hadoop3.1.1 源码地址:https://github.com/hortonworks/hadoop-release/tree/HDP-3.1.5.152-1-tag 一、前置知识 大家都知道hadoop的核心组件是HDFS和YARN,HDFS负责存储,YARN负责计算资源管理,今天要重点扯一扯YARN。YARN的架构跟众多分布式架

分布式系统框架hadoop3入门
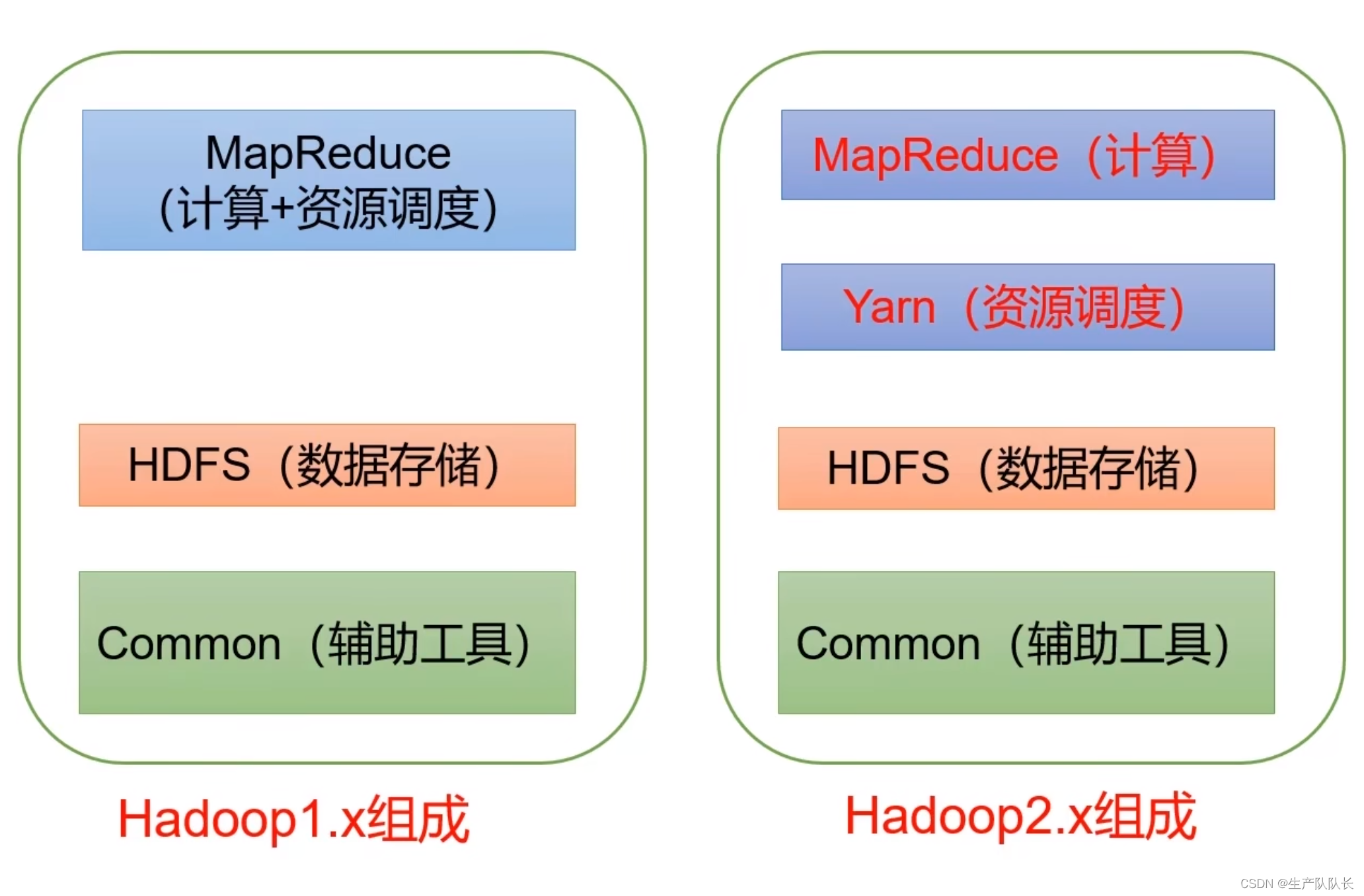
分布式系统框架hadoop3入门 (qq.com) Hadoop3作为分布式系统架构的重要基石,为大规模数据存储与处理提供了强大支持 基本信息 hadoop:一个存储和处理大数据的分布式系统框架 组成: HDFS(数据存储)、MapReduce(计算)、Yarn(资源调度)、Common(辅助工具) HDFS:Hadoop Distributed File System,一个分布式文

Hadoop3:MapReduce中Reduce阶段自定义OutputFormat逻辑
一、情景描述 我们知道,在MapTask阶段开始时,需要InputFormat来读取数据 而在ReduceTask阶段结束时,将处理完成的数据,输出到磁盘,此时就要用到OutputFormat 在之前的程序中,我们都没有设置过这部分配置 所以,采用的是默认输出格式:TextOutputFormat 在实际工作中,我们的输出不一定是到磁盘,可能是输出到MySQL、HBase等 那么,如何实现

Hadoop3:MapReduce中实现自定义排序
一、场景描述 以统计号码的流量案例为基础,进行开发。 流量统计结果 我们现在要对这个数据的总流量进行自定义排序。 二、代码实现 我们要对总流量进行排序,就是对FlowBean中的sumFlow字段进行排序。 所以,我们需要让FlowBean实现WritableComparable接口,并重写compareTo方法。 另外,我们知道,排序是在Shuffle过程进行的,且是在环形缓冲区进行
Hadoop3:MapReduce工作流程图解
一、流程图 二、流程说明 上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下: (1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中 (2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件 (3)多个溢出文件会被合并成大的溢出文件 (4)在溢出过程及合并的过程中,都要调用Parti
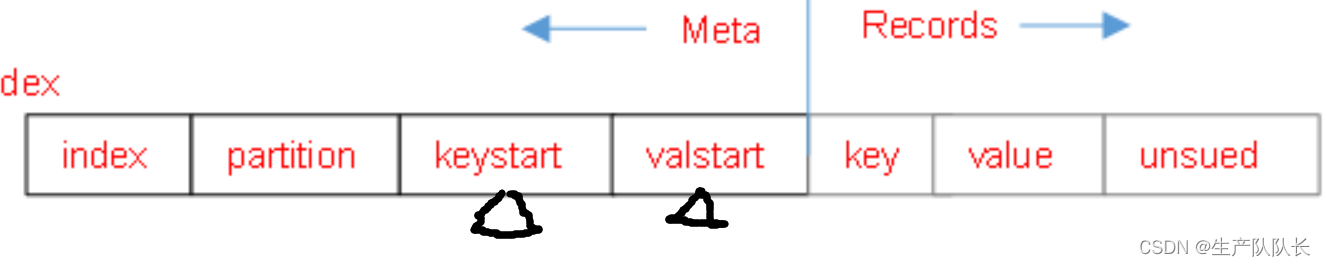
Hadoop3:MapReduce源码解读之Map阶段的CombineFileInputFormat切片机制(4)
Job那块的断点代码截图省略,直接进入切片逻辑 参考:Hadoop3:MapReduce源码解读之Map阶段的Job任务提交流程(1) 6、CombineFileInputFormat原理解析 类的继承关系 与TextInputFormat切片机制的区别 框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,

Hadoop3:MapReduce源码解读之Mapper阶段的FileInputFormat的切片原理(2)
Job那块的断点代码截图省略,直接进入切片逻辑 参考:Hadoop3:MapReduce源码解读之Mapper阶段的Job任务提交流程(1) 4、FileInputFormat切片源码解析 切片入口 获取切片 获取切片最大的Size和切片最小的Size 判断文件是否可以切片,如果文件不支持切片,则整体处理 这里只考虑支持切片的代码逻辑 根据切片大小配置,及块大小配置,计算出切片最终取值
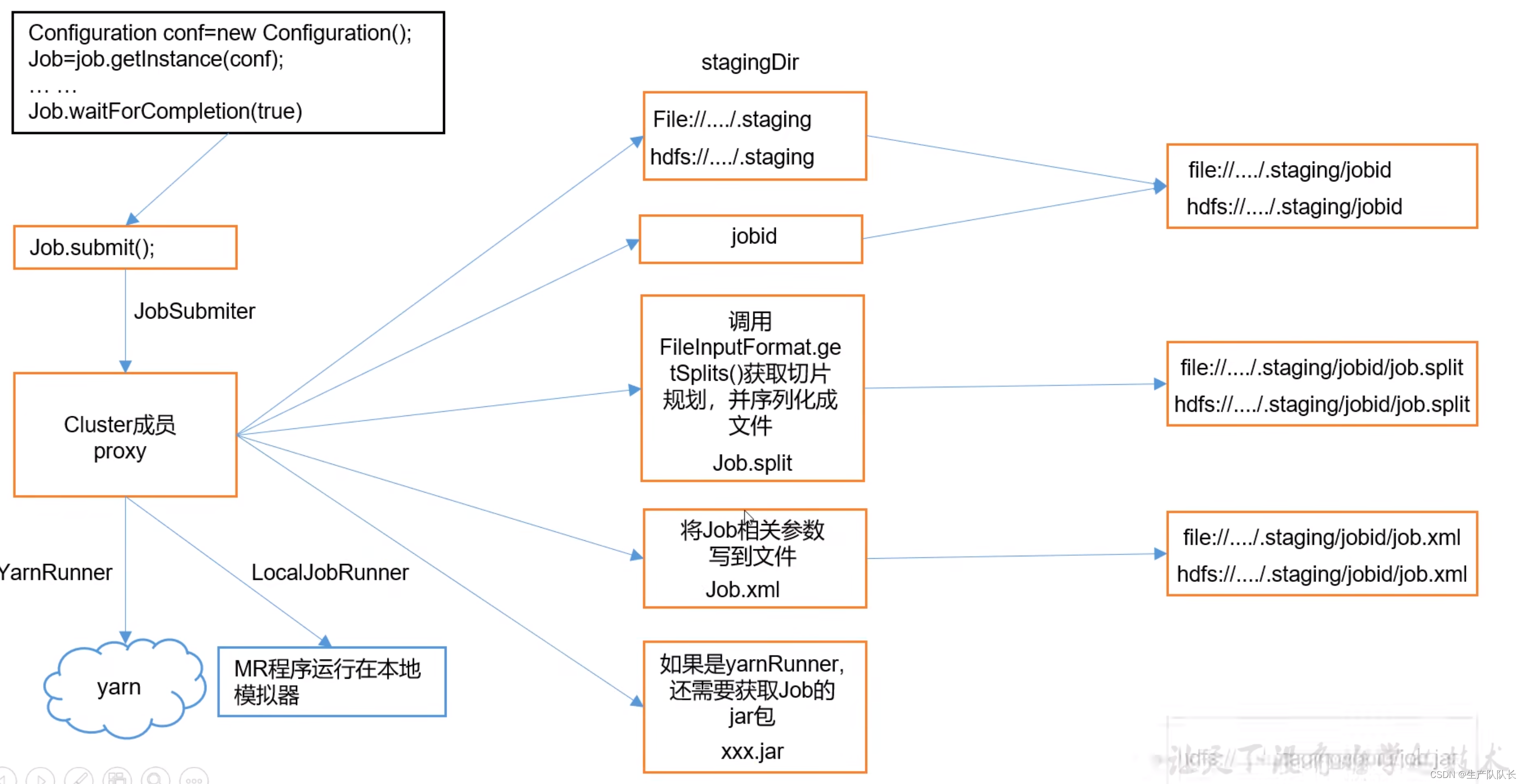
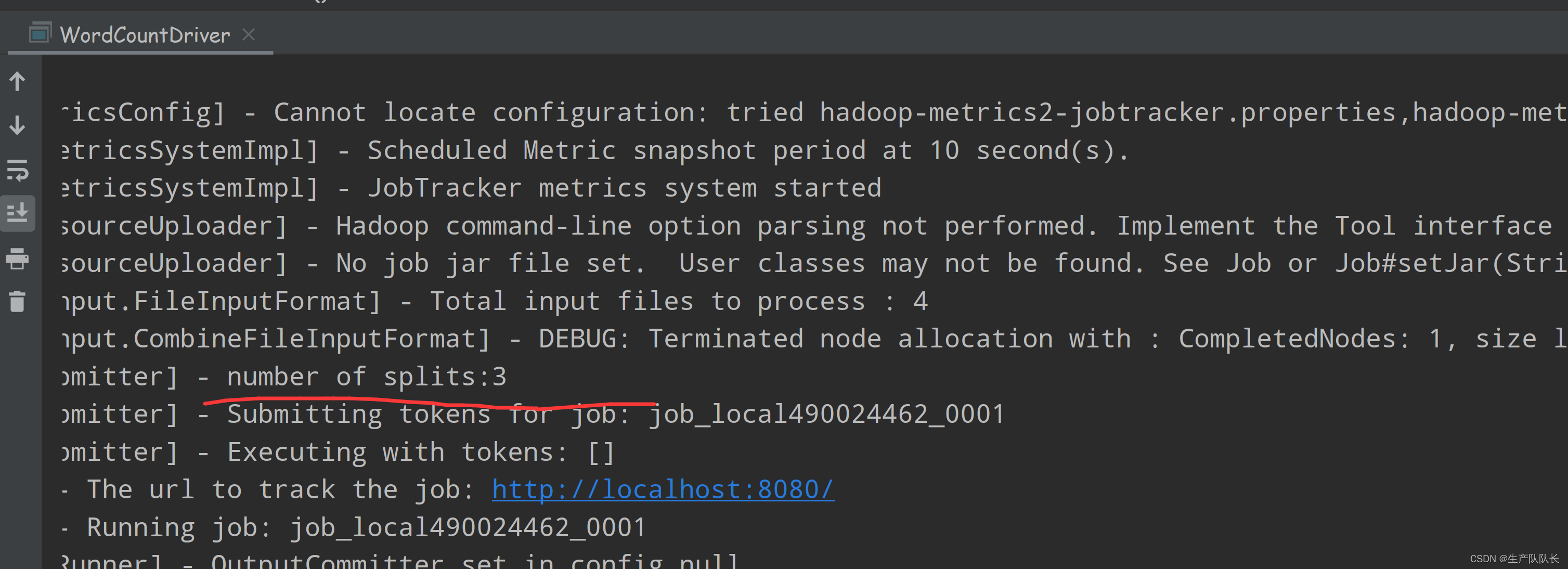
Hadoop3:MapReduce之MapTask的Job任务提交流程原理解读(1)
3、Job工作机制源码解读 用之前wordcount案例进行源码阅读,debug断点打在Job任务提交时 提交任务前,建立客户单连接 如下图,可以看出,只有两个客户端提供者,一个是YarnClient,一个是LocalClient。 显然,我这里是LocalClient模式 检查输出路径是否存在,存在则报错 这里的两串提示就很熟悉了,如果输出路径存在,则报错。 提交任务前会创建一个j
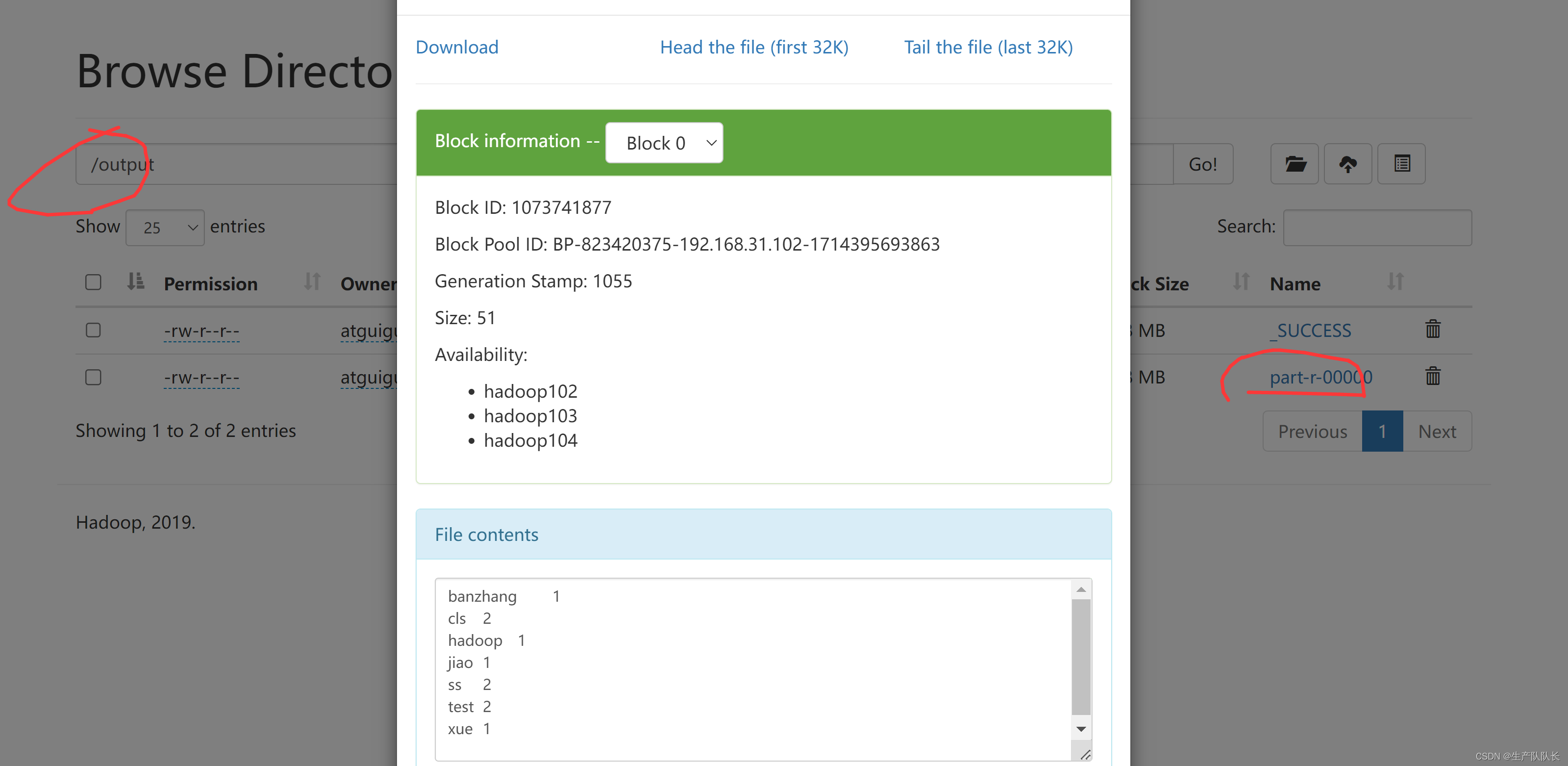
Hadoop3:MapReduce之简介、WordCount案例源码阅读、简单功能开发
一、概念 MapReduce是一个 分布式运算程序 的编程框架,是用户开发“基于 Hadoop的数据分析 应用”的核心框架。 MapReduce核心功能是将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的 分布式运算程序 ,并发运行在一个 Hadoop集群上。 1、MapReduce是集群上的并行计算框架 2、平时开发中只需要基于MapReduce接口,编写业务逻辑代码即可。 二
Hadoop3:HDFS副本节点选择逻辑讲解
一、副本节点选择(机架感知) 说明 第一个副本,因为我们的client可能是web页,也可能是shell终端。 如果是web页,则随机选取一个节点,如果是shell终端,则选择当前shell终端所在的节点。 节点距离最近,保证了性能。 第二个副本,选择机架2的n0节点,为了保证数据的可靠性。 第三个副本,为什么不选择机架3上的节点呢? 因为,第二个副本已经保证了可靠性,所以,第三副本,更注
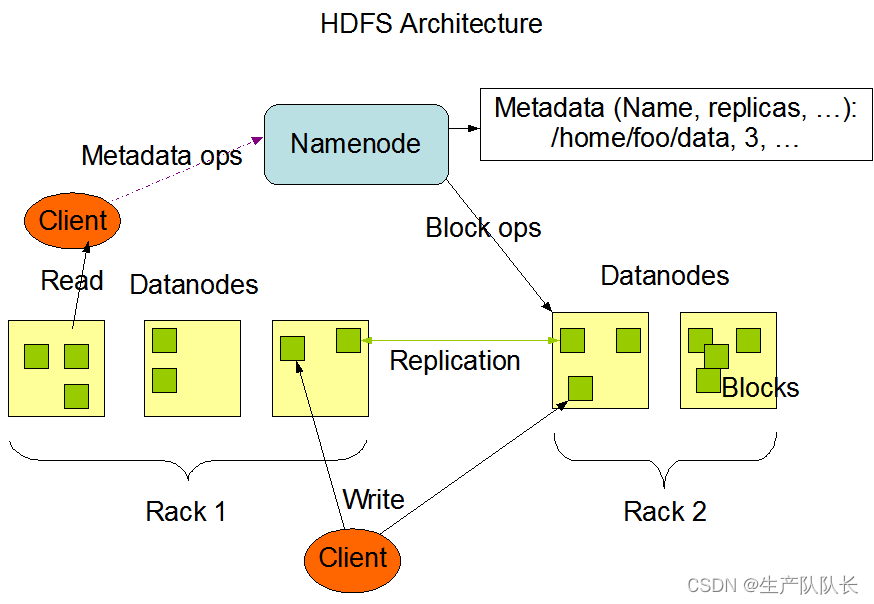
Hadoop3:HDFS的架构组成
一、官方文档 我这里学习的是Hadoop3.1.3版本,所以,查看的也是3.1.3版本的文档 Architecture模块最下面 二、HDFS架构介绍 HDFS架构的主要组成部分,是一下四个部分 1、NameNode(NN) 就是Master节点,它是集群管理者。 1、管理HDFS的名称空间 2、配置副本策略 3、管理数据块(Block)映射信息 4、处理客户端读写请求 2、D

Hadoop3:集群搭建及常用命令与shell脚本整理(入门篇,从零开始搭建)
一、集群环境说明 1、用VMware安装3台Centos7.9虚拟机 2、虚拟机配置:2C,2G内存,50G存储 3、集群架构 从表格中,可以看出,Hadoop集群,主要有2部分,一个是HDFS服务,一个是YARN服务 二、搭建集群 1、安装3台Centos7.9虚拟机 安装教程:VMware安装Centos7详细教程及初始化配置 1.1、修改主机名 三台虚拟机固定IP:192.16
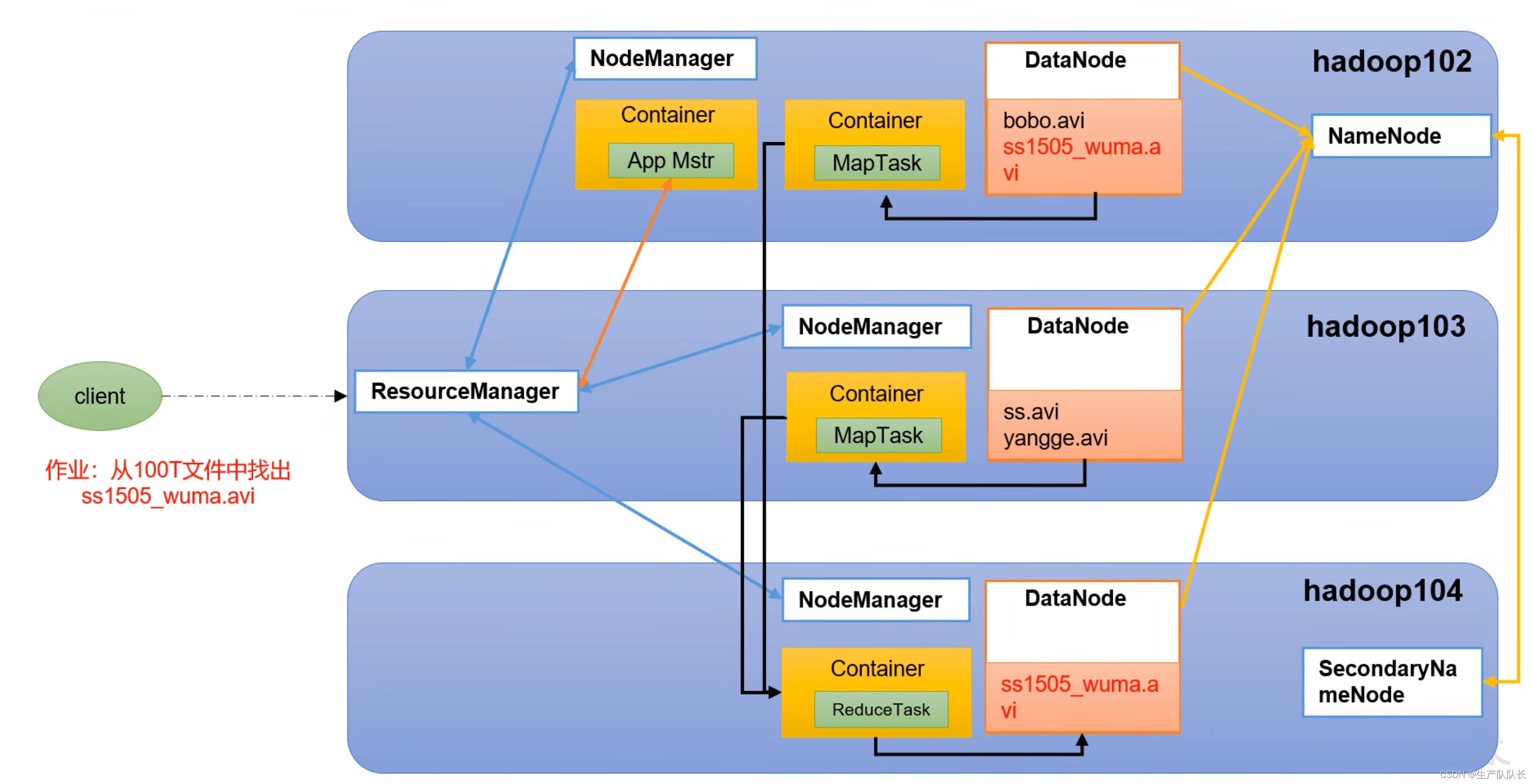
Hadoop3:HDFS、YARN、MapReduce三部分的架构概述及三者间关系(Hadoop入门必须记住的内容)
一、HDFS架构概述 Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。 1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。理解为集群数据索引 2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。 3)Se
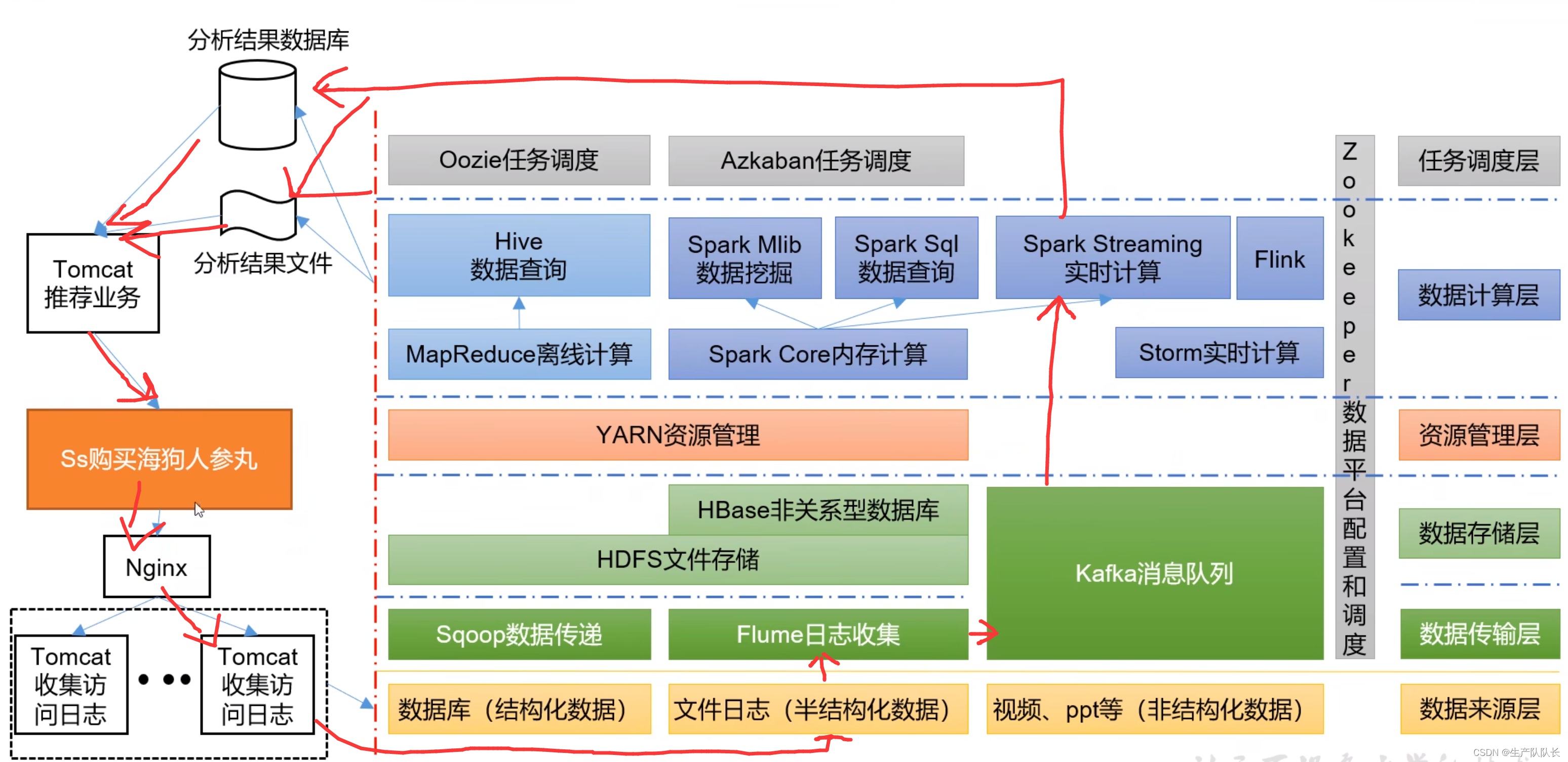
Hadoop3:大数据生态体系
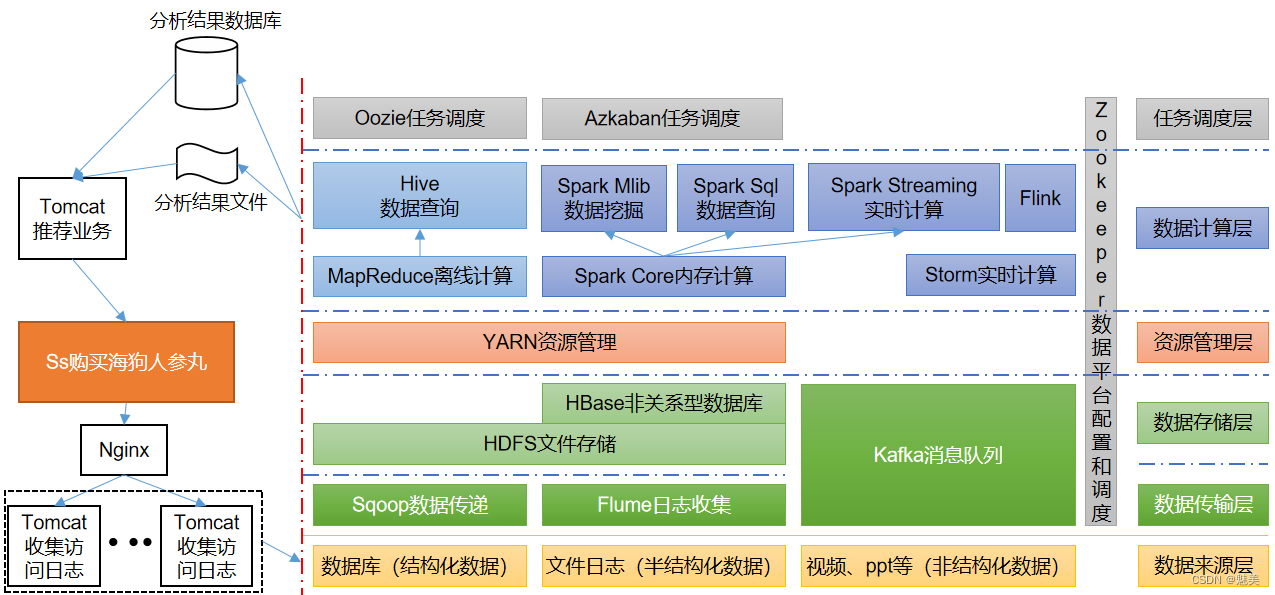
一、技术层面 通过下面这张图,我们可以大概确定,在大数据行业里,自己的学习路线。 个人认为,Hadoop集群一旦搭建完工,基本就是个把人运维的事情 主要岗位应该是集中在数据计算层,尤其是实时计算! 实时计算框架比较实用的是Spark Streaming 和 Flink 数据传输层,又叫数据采集层,将不同的数据源中的各种类型数据,采集到Hadoop中进行存储 Flume组件,个人觉得与Log
Hadoop3:大数据的基本介绍
一、什么是大数据 1、大数据的4v特点 Volume(大量) Velocity(高速) Variety(多样) Value(低价值密度) 2、大数据部门间的工作岗位 第三部分,其实就是JavaWeb 二、什么是Hadoop 三、Hadoop的4大优势 1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元 素或存储出现故障,也不会导致数据的丢失。 2
MapReduce工作流程(Hadoop3.x)
MapReduce 是一种用于并行处理大规模数据集的——编程模型和处理框架。它通常用于分布式计算环境中,如Apache Hadoop。 工作流程 1. 切分阶段(Splitting): 数据集被分成多个数据块,每个数据块的大小通常在64MB到128MB之间。切分可以按照数据的行数、字节数或其他标准进行。数据块的切分通常在输入阶段完成,然后将切分后的数据块分配到集群中的不同节点上进行处理。

搭建Hadoop3.x完全分布式集群
零、资源准备 虚拟机相关: VMware workstation 16:虚拟机 > vmware_177981.zipCentOS Stream 9:虚拟机 > CentOS-Stream-9-latest-x86_64-dvd1.iso Hadoop相关 jdk1.8:JDK > jdk-8u261-linux-x64.tar.gzHadoop 3.3.6:Hadoop > Hadoop 3.
Hadoop3.x完全分布式模式下slaveDataNode节点未启动调整
目录 前言 一、问题重现 1、查询Hadoop版本 2、集群启动Hadoop 二、问题分析 三、Hadoop3.x的集群配置 1、停止Hadoop服务 2、配置workers 3、从节点检测 4、WebUI监控 总结 前言 在大数据的世界里,Hadoop绝对是一个值得学习的框架。关于Hadoop的知识,有很多博主和视频博主都做了很详细的教

Hadoop3.x基础(3)- MapReduce
来源: B站尚硅谷 目录 MapReduce概述MapReduce定义MapReduce优缺点优点缺点 MapReduce核心思想MapReduce进程常用数据序列化类型MapReduce编程规范WordCount案例实操本地测试提交到集群测试 Hadoop序列化序列化概述自定义bean对象实现序列化接口(Writable)序列化案例实操 MapReduce框架原理InputFormat数
Hadoop3.x基础(2)- HDFS
来源:B站尚硅谷 目录 HDFS概述HDFS产出背景及定义HDFS优缺点HDFS组成架构HDFS文件块大小(面试重点) HDFS的Shell操作(开发重点)基本语法命令大全常用命令实操准备工作上传下载HDFS直接操作 HDFS的API操作HDFS的API案例实操HDFS文件上传(测试参数优先级)HDFS文件下载HDFS文件更名和移动HDFS删除文件和目录HDFS文件详情查看HDFS文件和
Hadoop3.x基础(1)
来源:B站尚硅谷 这里写目录标题 大数据概论大数据概念大数据特点(4V)大数据应用场景 Hadoop概述Hadoop是什么Hadoop发展历史(了解)Hadoop三大发行版本(了解)Hadoop优势(4高)Hadoop组成(面试重点)HDFS架构概述YARN架构概述MapReduce架构概述HDFS、YARN、MapReduce三者关系 大数据技术生态体系推荐系统框架图常用端口号说明
Hadoop3.x源码解析
文章目录 一、RPC通信原理解析1、概要2、代码demo 二、NameNode启动源码解析1、概述2、启动9870端口服务3、加载镜像文件和编辑日志4、初始化NN的RPC服务端5、NN启动资源检查6、NN对心跳超时判断7、安全模式 三、DataNode启动源码解析1、概述2、初始化DataXceiverServer3、初始化HTTP服务4、初始化DN的RPC服务端5、DN向NN注册6、向NN

Hudi Hadoop3 环境运行报错, 关于 HftpFileSystem问题
问题 Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop

【生产级实践】Docker部署配置Hadoop3.x + HBase2.x实现真正分布式集群环境
网上找了很多资料,但能够实现Docker安装Hadoop3.X和Hbase2.X真正分布式集群的教程很零散,坑很多, 把经验做了整理, 避免趟坑。 一、安装Docker Hadoop3.X分布式集群 1、机器环境 这里采用三台机器来部署分布式集群环境: 192.168.1.101 hadoop1 (docker管理节点) 192.168.1.102 hadoop2 192.168

尚硅谷hadoop3.x课程部分资料文件下载,jdk,hadoopjar包
jdk文件百度云下载: 链接:https://pan.baidu.com/s/1MCiGRzOZY8rAFpRJwA3tdw 提取码:kphl hadoop的jar包: 最新版官网链接: Index of /dist/hadoop/core/stable (apache.org) 百度云下载,3.3.3版: 链接:https://pan.baidu.com/s/

CentOS 搭建 Hadoop3 高可用集群
Hadoop FullyDistributed Mode 完全分布式 spark101spark102spark103192.168.171.101192.168.171.102192.168.171.103namenodenamenodejournalnodejournalnodejournalnodedatanodedatanodedatanodenodemanagernodemanager