本文主要是介绍Hadoop3:大数据的基本介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、什么是大数据
1、大数据的4v特点
Volume(大量)
Velocity(高速)
Variety(多样)
Value(低价值密度)
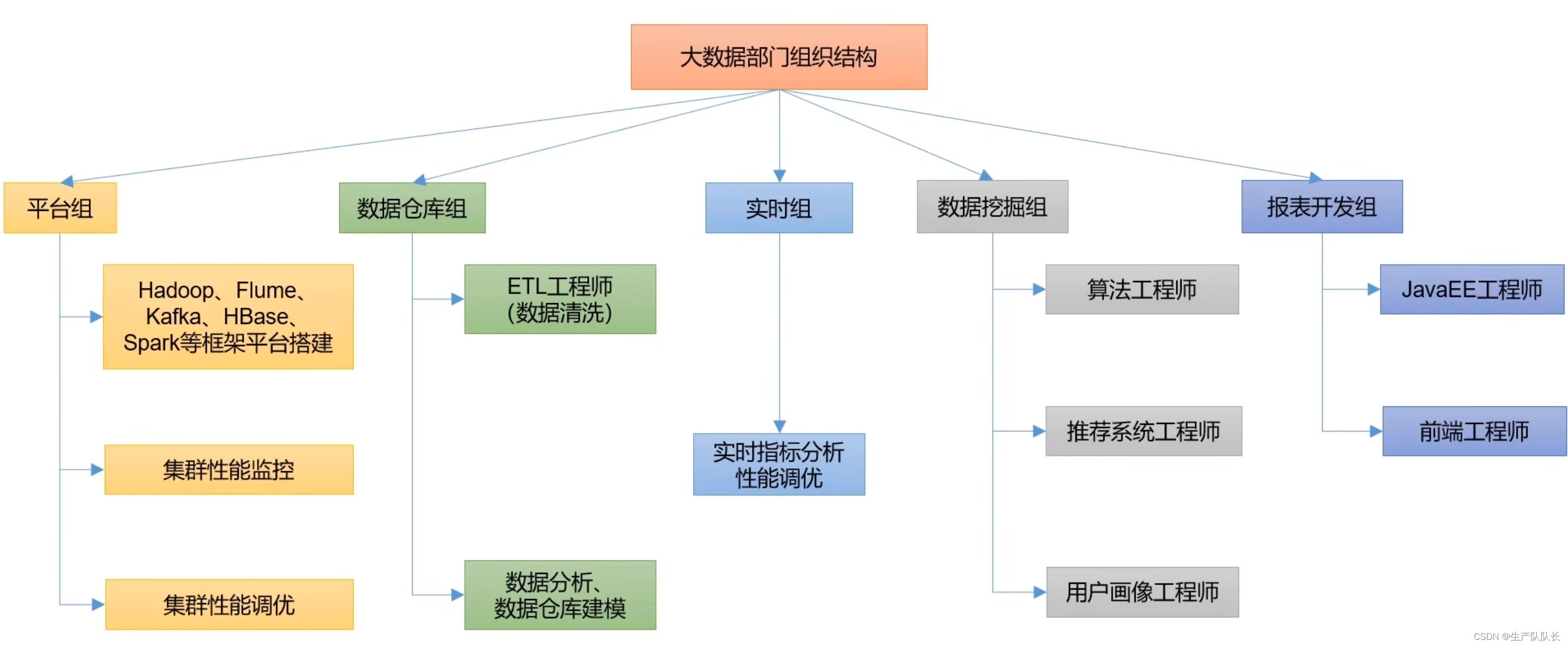
2、大数据部门间的工作岗位
第三部分,其实就是JavaWeb

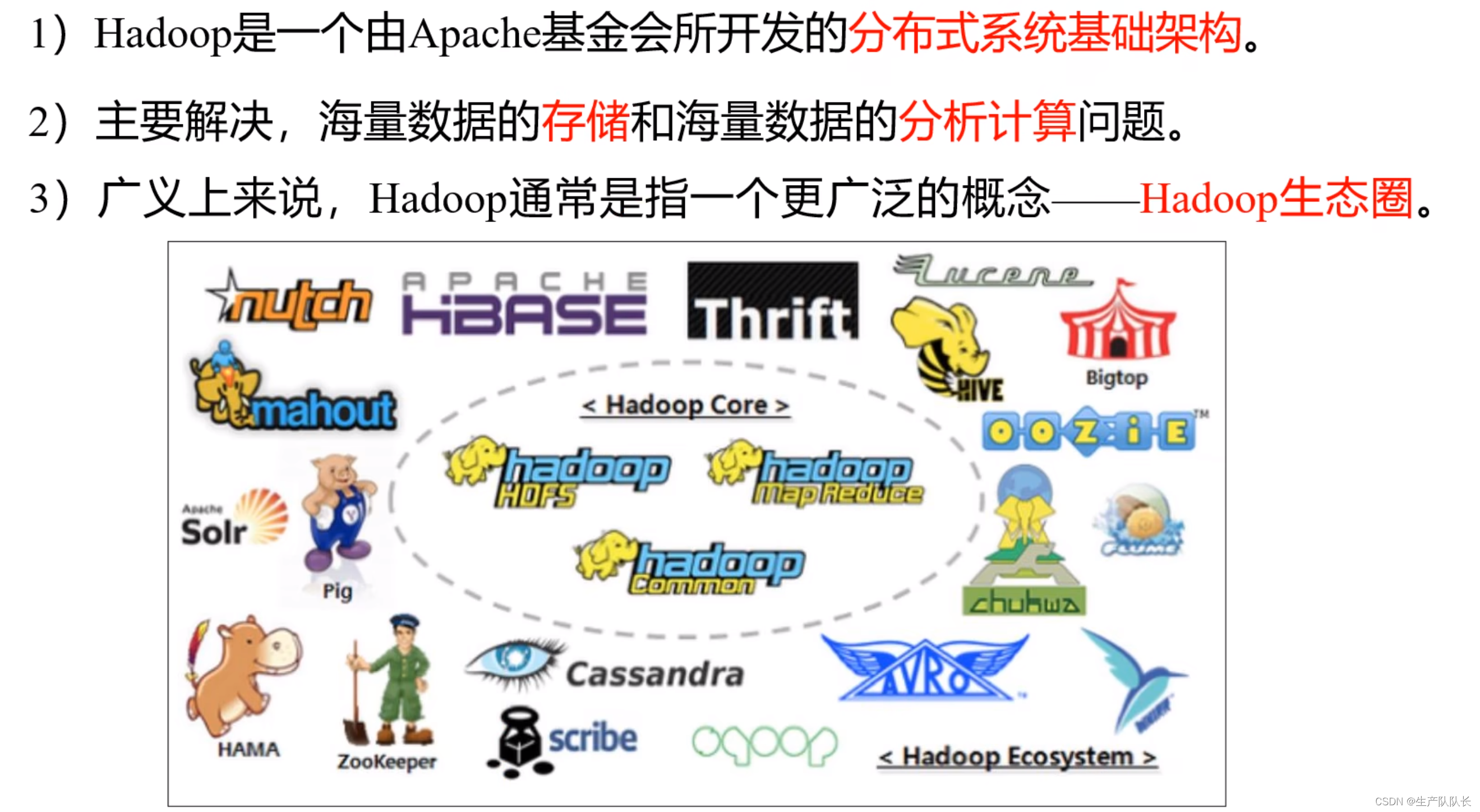
二、什么是Hadoop
三、Hadoop的4大优势
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元
素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:能够自动将失败的任务重新分配。
四、Hadoop架构简介
Hadoop3在架构组成上,和Hadoop2相同
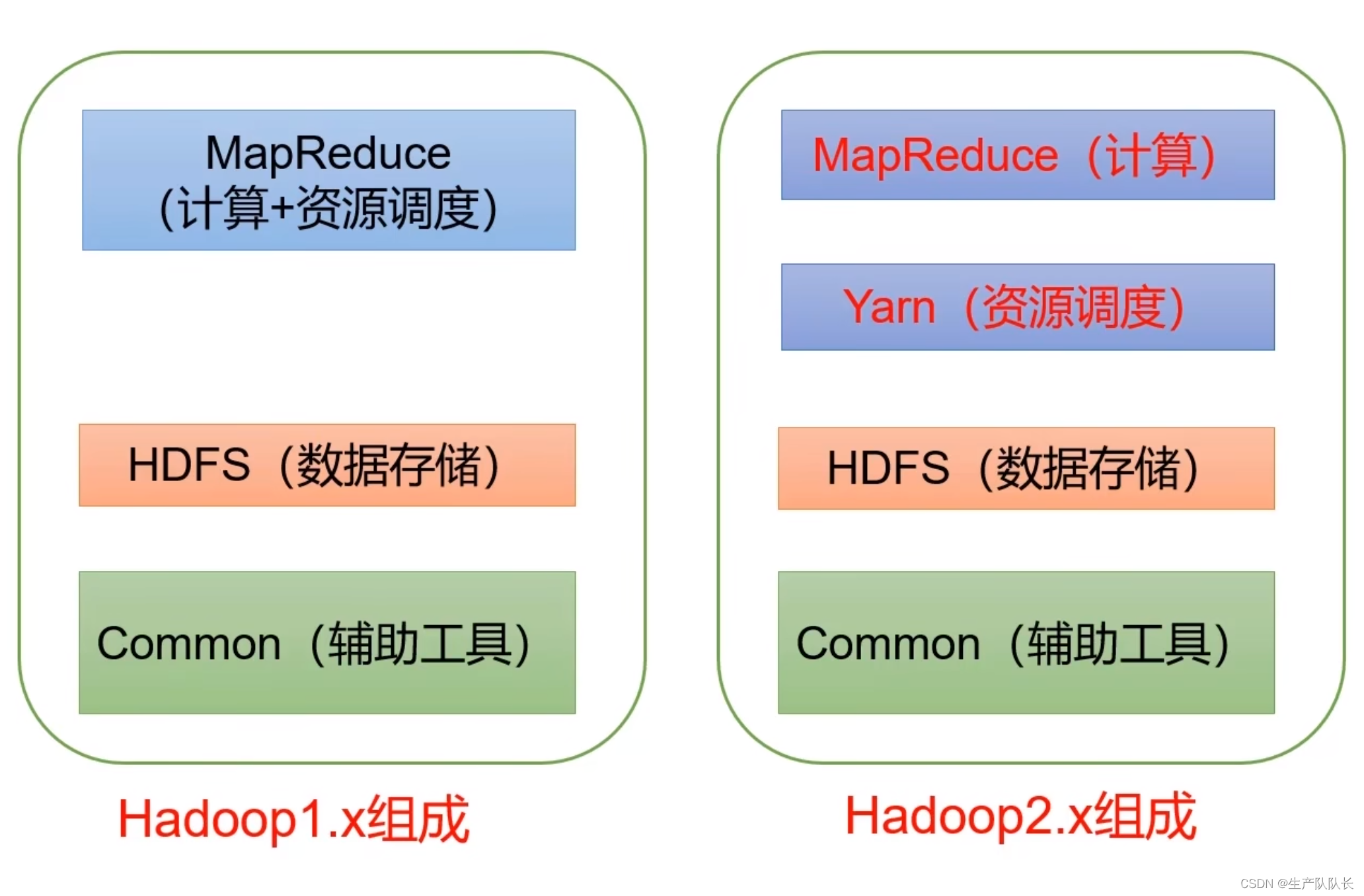
1、Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。简单理解,就是用来存储文件的。
2、Yet Another Resource Negotiator 简称YARN(读作:雅恩) ,另一种资源协调者,是Hadoop的资源管理器。类似SpringBoot里面任务调度框架Quartz
3、MapReduce 将计算过程分为两个阶段:Map和Reduce
1)Map 阶段并行分发任务,进行数据处理
2)Reduce 阶段对Map结果进行汇总
这篇关于Hadoop3:大数据的基本介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





