本文主要是介绍Hadoop3:MapReduce源码解读之Mapper阶段的FileInputFormat的切片原理(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Job那块的断点代码截图省略,直接进入切片逻辑
参考:Hadoop3:MapReduce源码解读之Mapper阶段的Job任务提交流程(1)
4、FileInputFormat切片源码解析
切片入口
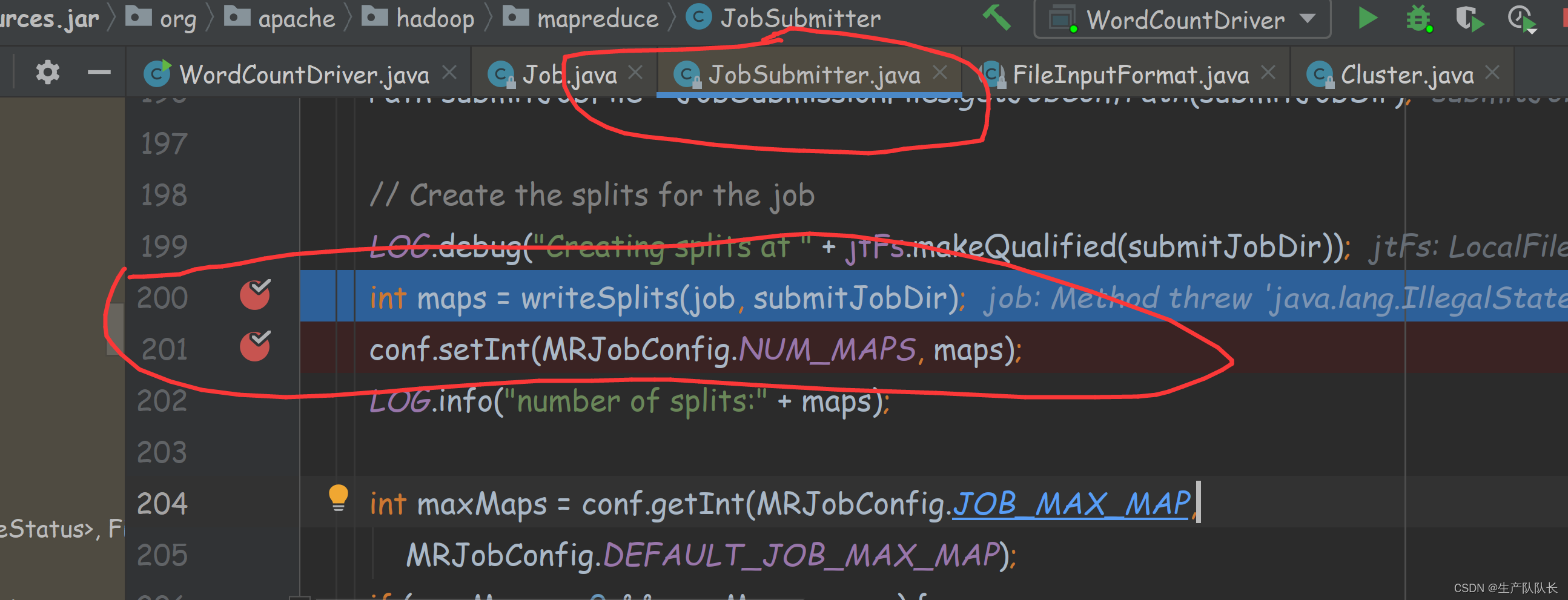
获取切片

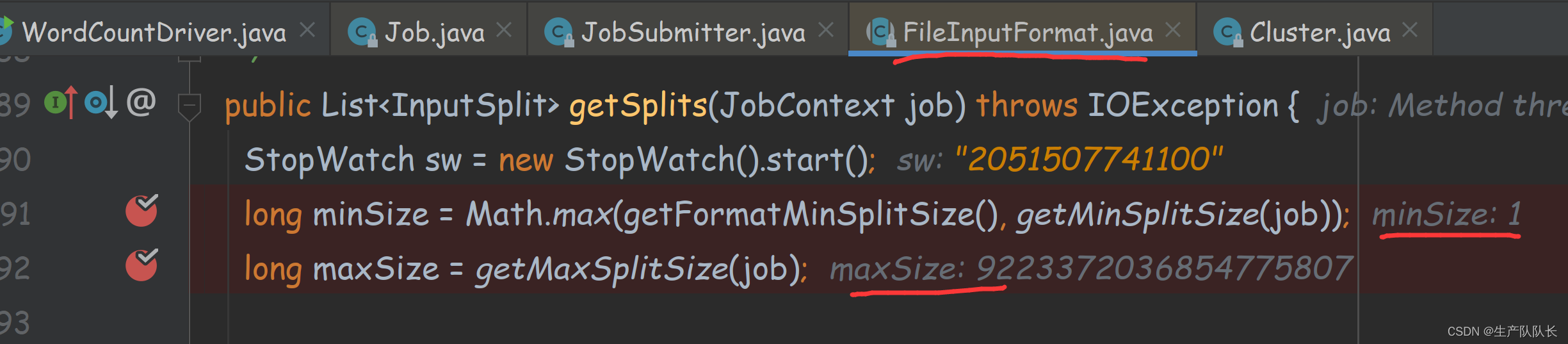
获取切片最大的Size和切片最小的Size
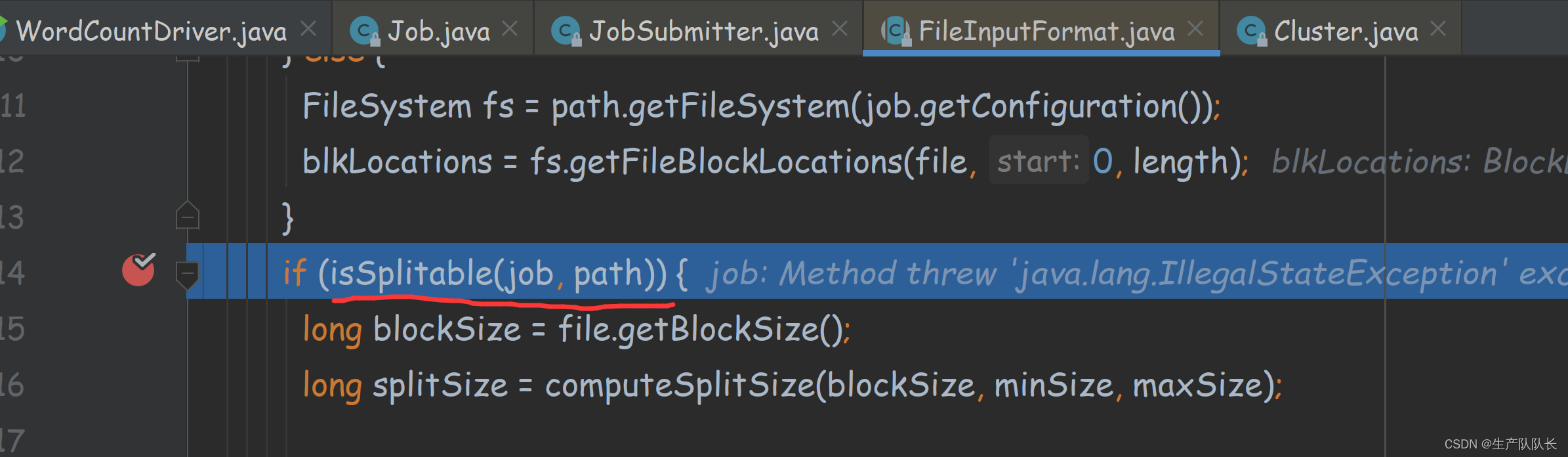
判断文件是否可以切片,如果文件不支持切片,则整体处理
这里只考虑支持切片的代码逻辑
根据切片大小配置,及块大小配置,计算出切片最终取值

此处可以看出,如果块大小配置在切片大小之间的值,则切片大小取块大小。

这里可以看出,切片是对每一个文件单独计算的,不是把所有文件累加到一起的大小进行计算切片数量。
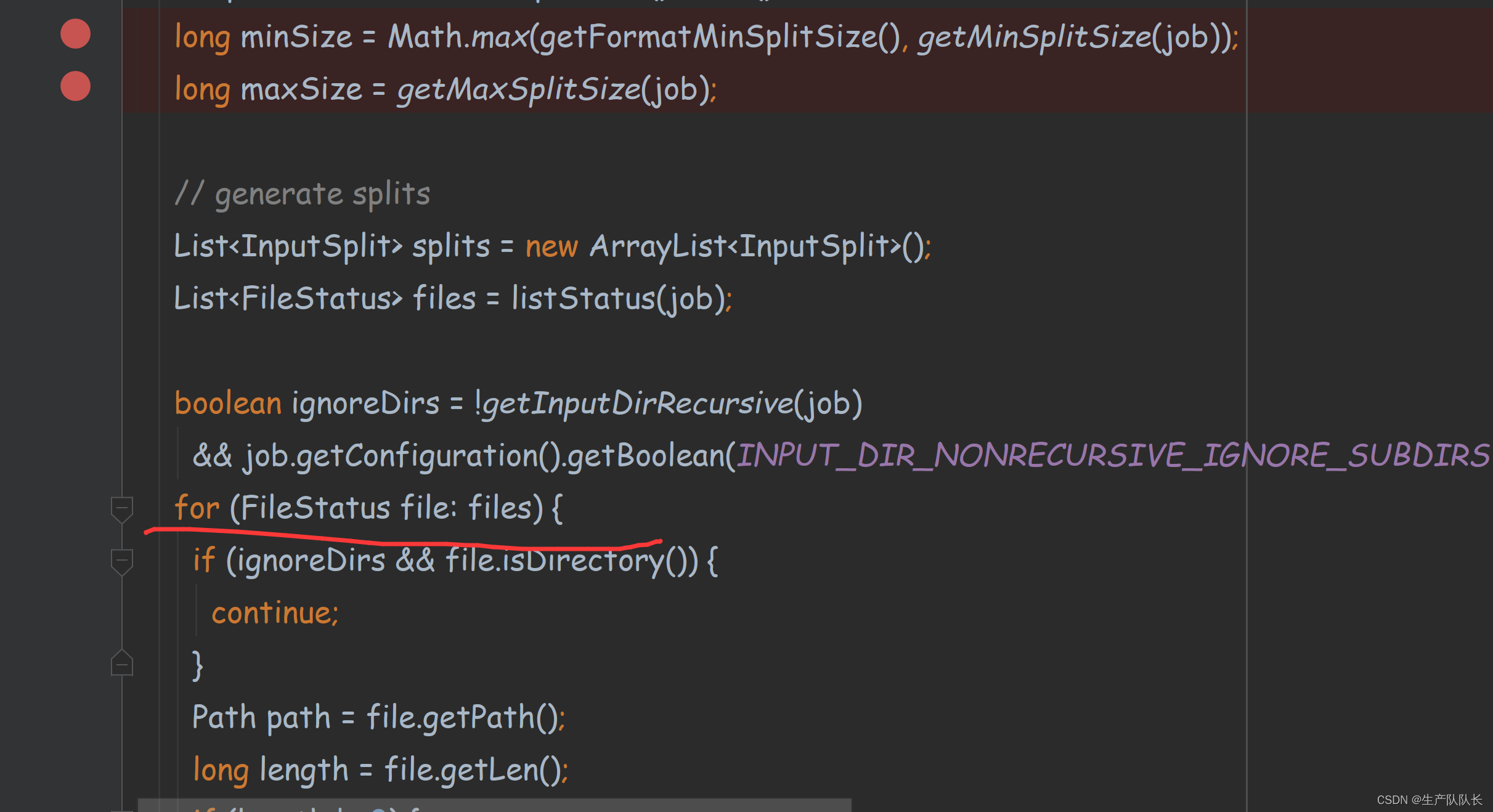
切片的一个代码层面的处理逻辑。
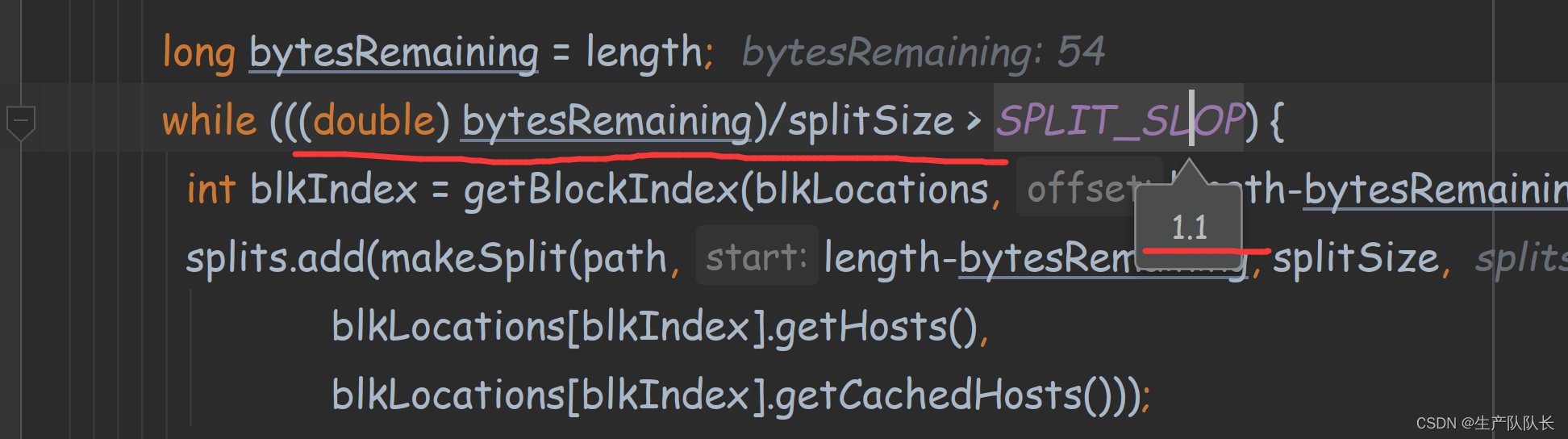
如果,文件大小小于切片大小的1.1倍,则不增加切片。
然后根据splitSize值去划分数据块
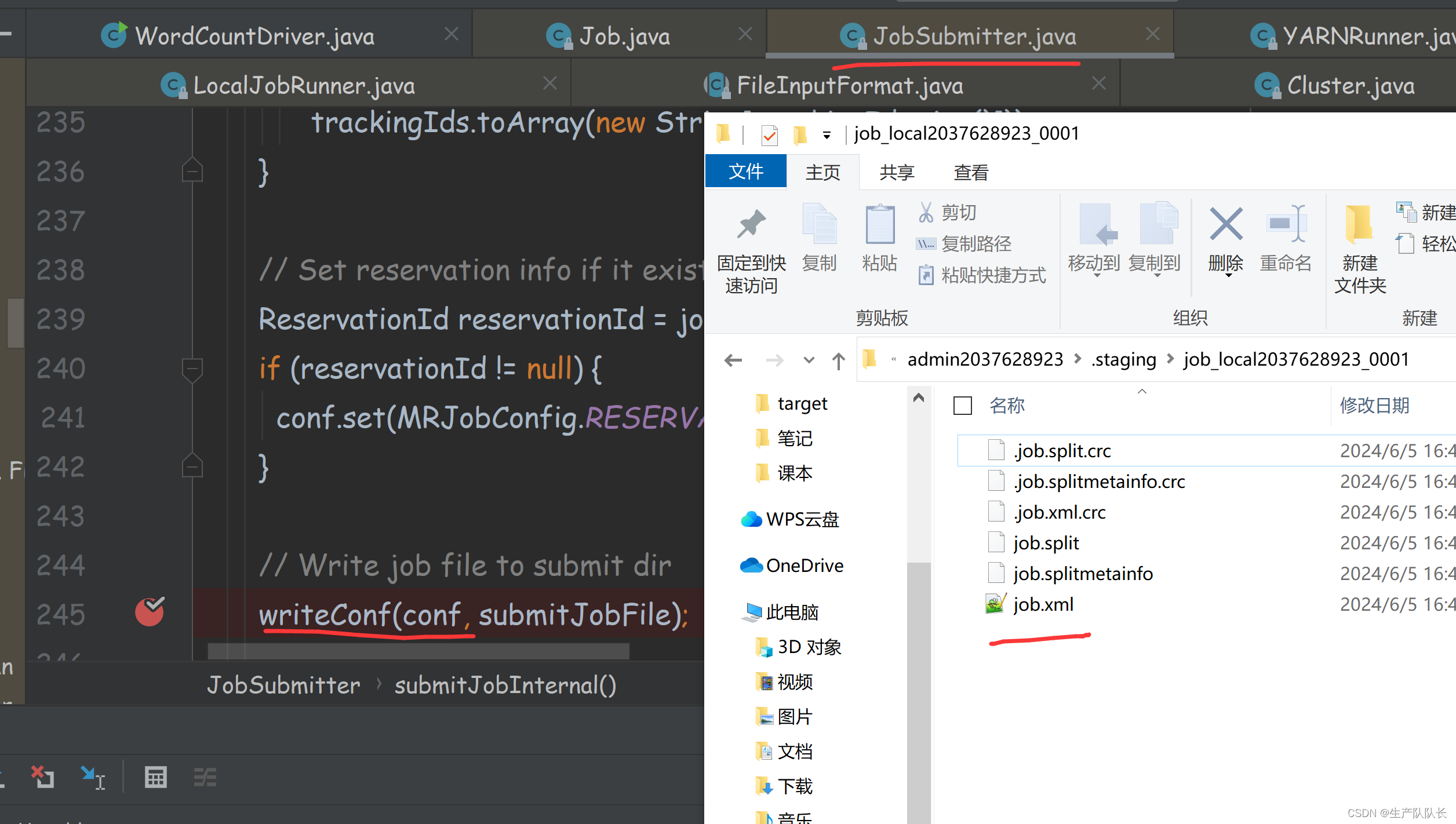
生成临时切片文件

创建配置信息文件到临时文件夹中
总结
FileInputFormat类的继承关系
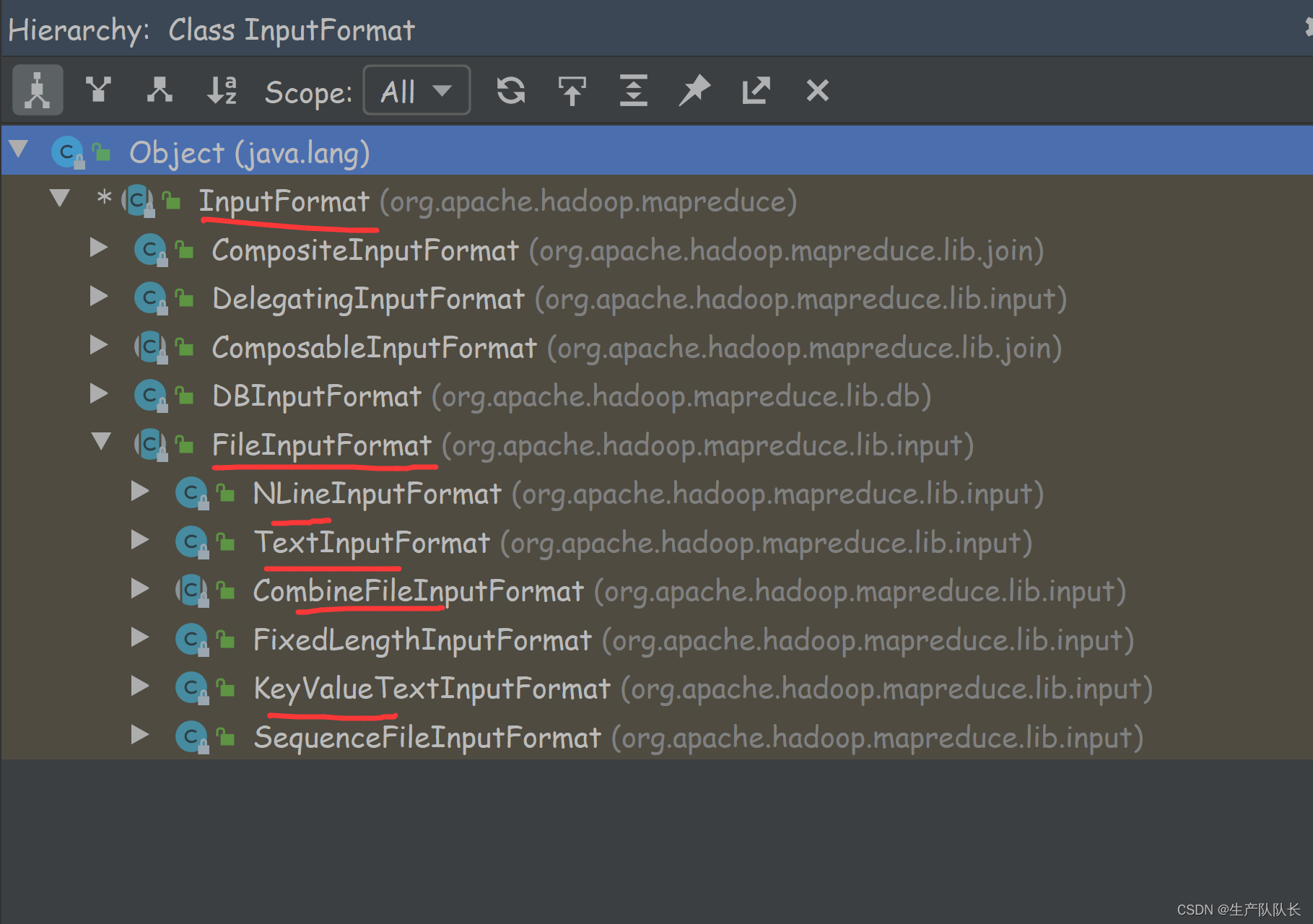
主要关注该类里面的getSplits方法

整体流程梳理


常用API

这篇关于Hadoop3:MapReduce源码解读之Mapper阶段的FileInputFormat的切片原理(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






