本文主要是介绍Hadoop3:HDFS的架构组成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、官方文档
我这里学习的是Hadoop3.1.3版本,所以,查看的也是3.1.3版本的文档
Architecture模块最下面
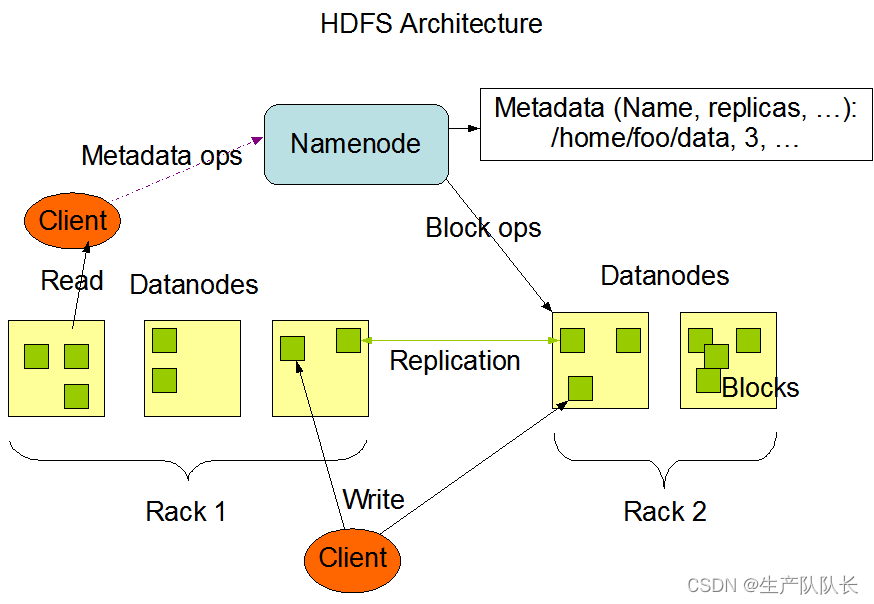
二、HDFS架构介绍
HDFS架构的主要组成部分,是一下四个部分
1、NameNode(NN)
就是Master节点,它是集群管理者。
1、管理HDFS的名称空间
2、配置副本策略
3、管理数据块(Block)映射信息
4、处理客户端读写请求
2、DataNode
就是Slave节点,干活的。NameNode下达程序命令,DataNode执行具体命令。
1、存储实际的数据块
2、执行数据块的读写操作
3、Client
客户端,web页面也算是客户端,终端命令也是客户端来执行的。
1、切分文件,文件上传到HDFS集群的时候,Client将文件切分成一个个的Block,然后,进行上传
2、与NameNode交互,获取文件的位置信息
3、与DataNode交互,读写数据
4、Client提供一些命令来管理HDFS,比如NameNode的格式化命令
5、Client可以通过一些命令来访问HDFS,比如对HDFS的增删改查操作
4、Secondary NameNode(2NN)
它不是NameNode的热备,当NameNode节点挂掉的时候,它并不能马上替换NameNode并提供服务
实际场景中,一般用两个NameNode来实现高可用,2NN一般不用
1、辅助NameNode,分担工作量
2、在紧急情况下,可辅助恢复NameNode
三、思考题
1、NameNode中的Block大小如何设置?设置多大合适?怎么计算?
1、配置参数dfs.blocksize
在Hadoop2.x/3.x版本中默认大小是128M,1.x版本中是64M。
默认配置在hdfs-default.xml中,我们可以在hdfs-site.xml中自定义配置
<property><name>dfs.blocksize</name><value>134217728</value><description>The default block size for new files, in bytes.You can use the following suffix (case insensitive):k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.),Or provide complete size in bytes (such as 134217728 for 128 MB).</description>
</property>
2、Block大小计算逻辑
这个Block大小的确定,主要受寻址时间、传输时间、磁盘性能3个因素影响。
一般地
寻址时间为传输时间的1%时,则为最佳状态。
假设,寻址时间是10ms,则最佳传输时间是10ms/0.01=1000ms=1s
于是,根据这个传输时间及磁盘的读写速率,计算出Block的大小设置
一般性配置
机械硬盘,我们就设置为128MB
固态硬盘,我们就设置为256MB
3、设置太小或太大会有什么弊端?
设置太小
那么,HDFS里面会有很多的小文件,这样,会增加寻址时间,影响性能。
设置太大
会降低HDFS的并发能力,影响性能。
这篇关于Hadoop3:HDFS的架构组成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









