本文主要是介绍Hadoop3:大数据生态体系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
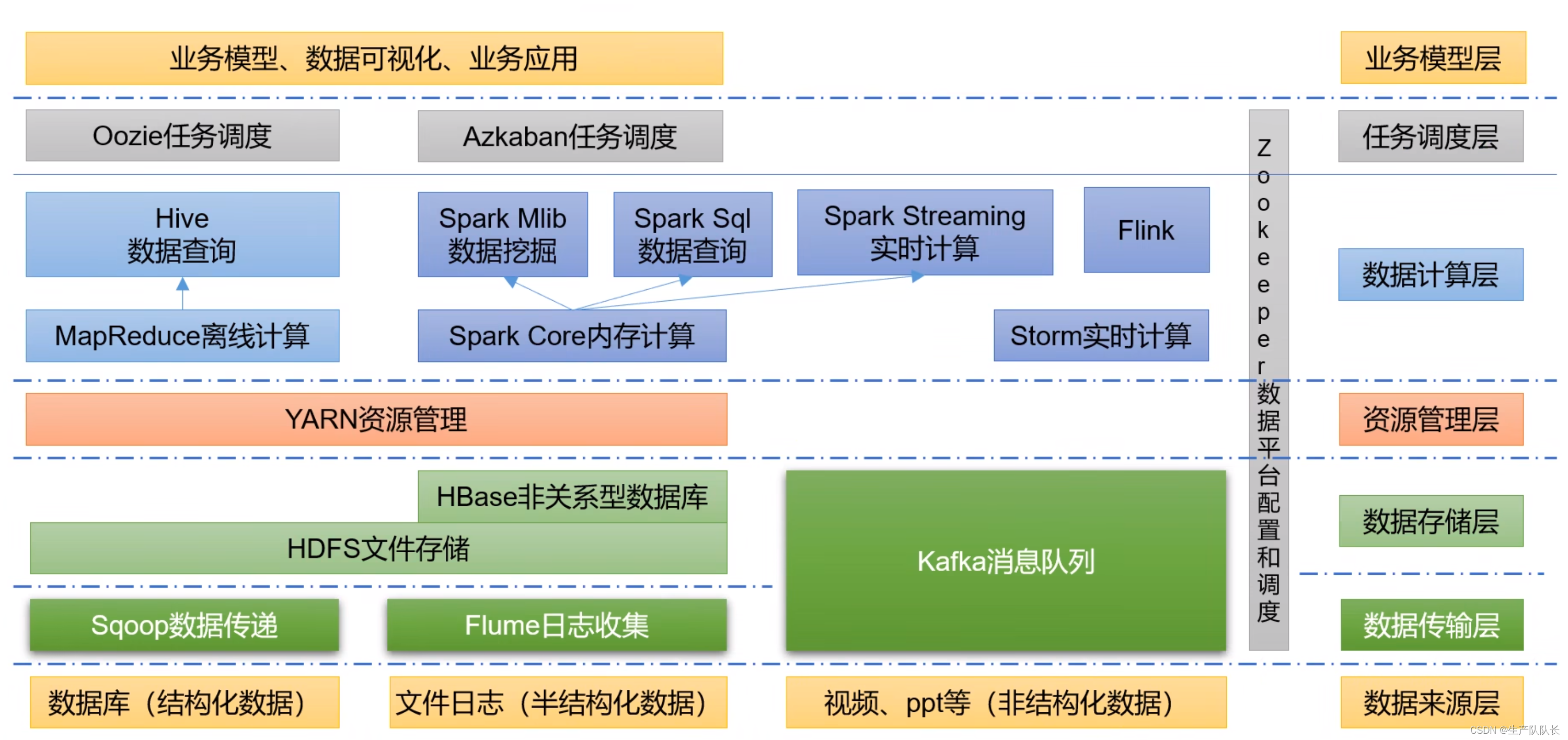
一、技术层面
通过下面这张图,我们可以大概确定,在大数据行业里,自己的学习路线。
个人认为,Hadoop集群一旦搭建完工,基本就是个把人运维的事情
主要岗位应该是集中在数据计算层,尤其是实时计算!
实时计算框架比较实用的是Spark Streaming 和 Flink
数据传输层,又叫数据采集层,将不同的数据源中的各种类型数据,采集到Hadoop中进行存储
Flume组件,个人觉得与Logstash组件等效。
这里的定时任务,任务之间是可以相互依赖的
二、业务层面
个人偏好推荐功能
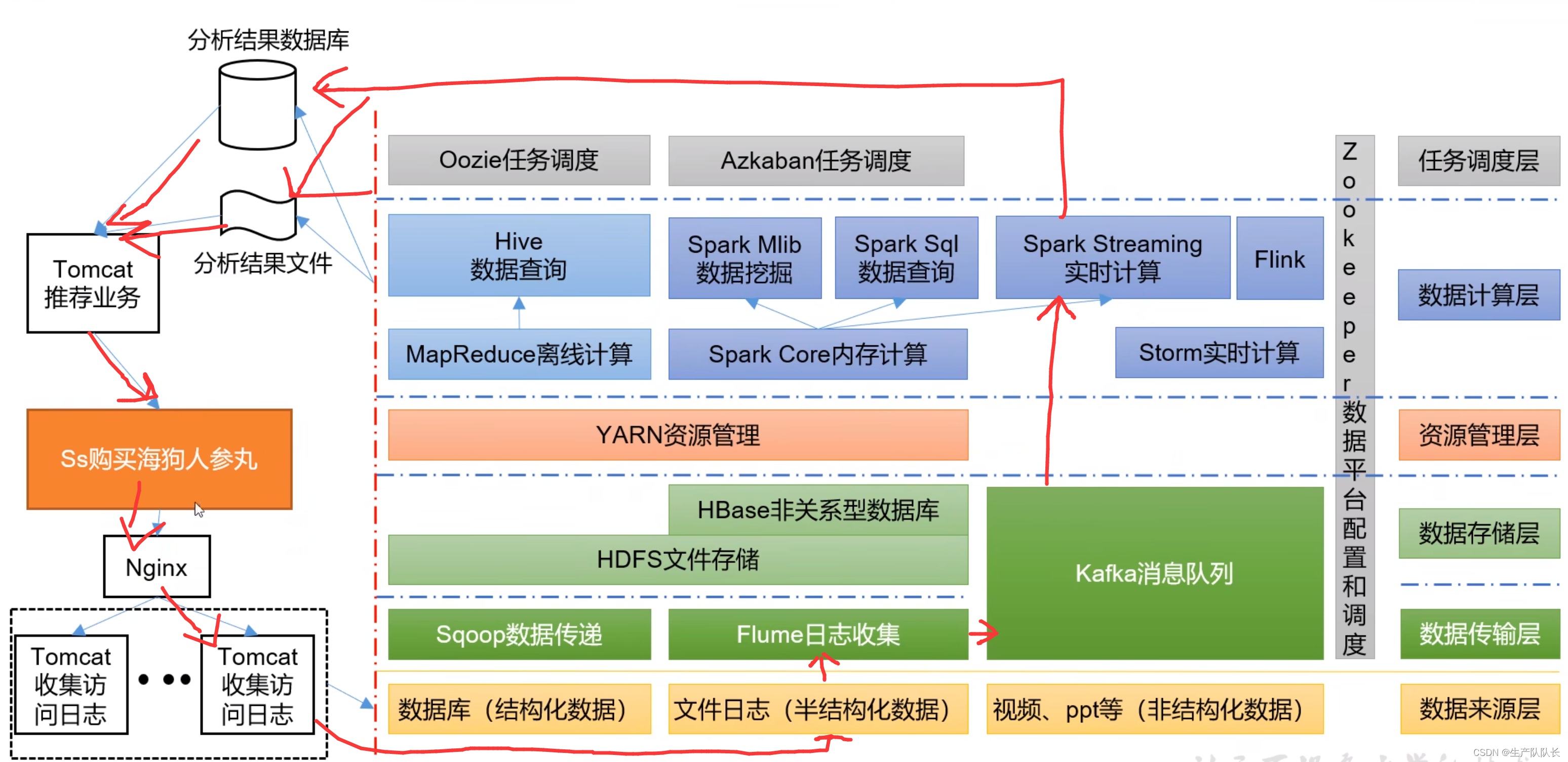
这篇关于Hadoop3:大数据生态体系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








