本文主要是介绍Hadoop3:集群搭建及常用命令与shell脚本整理(入门篇,从零开始搭建),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、集群环境说明
1、用VMware安装3台Centos7.9虚拟机
2、虚拟机配置:2C,2G内存,50G存储
3、集群架构
从表格中,可以看出,Hadoop集群,主要有2部分,一个是HDFS服务,一个是YARN服务

二、搭建集群
1、安装3台Centos7.9虚拟机
安装教程:VMware安装Centos7详细教程及初始化配置
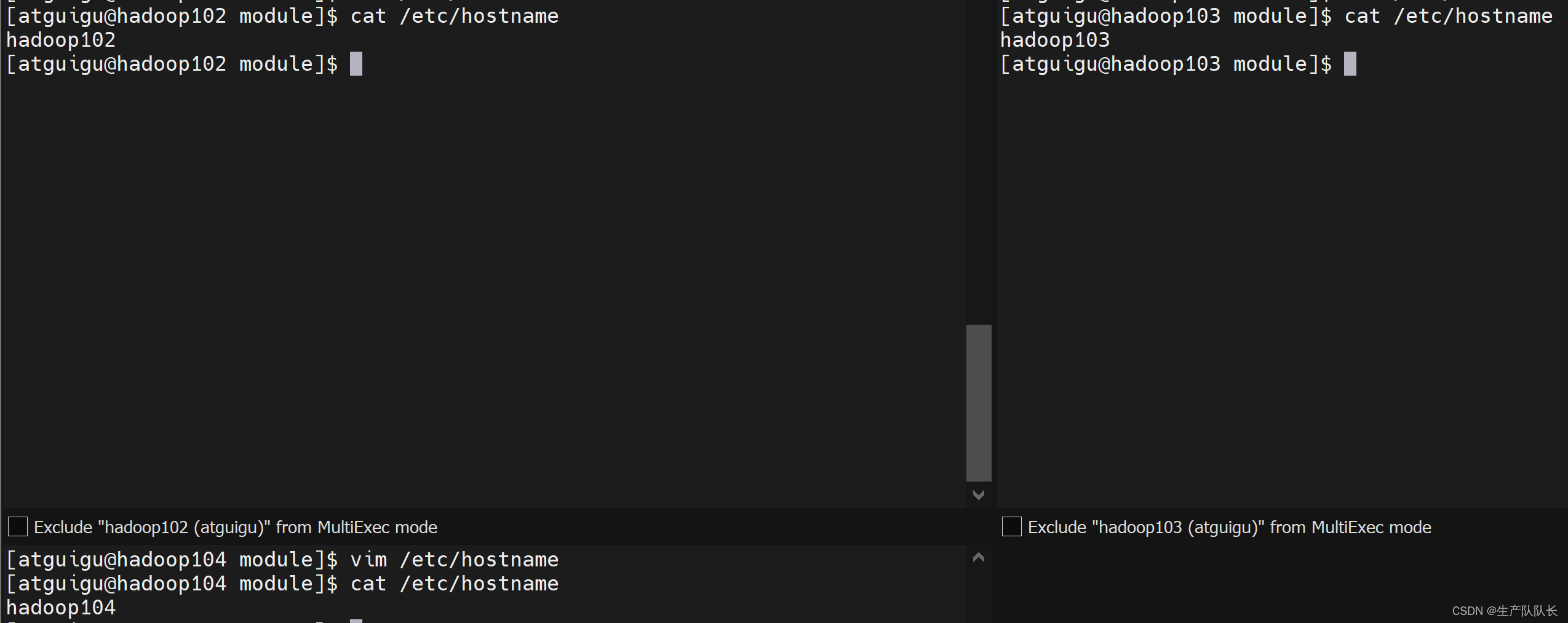
1.1、修改主机名
三台虚拟机固定IP:192.168.31.102、192.168.31.103、192.168.31.104
三台主机的hostname分别修改为,hadoop102,hadoop103,hadoop104
vim /etc/hostname
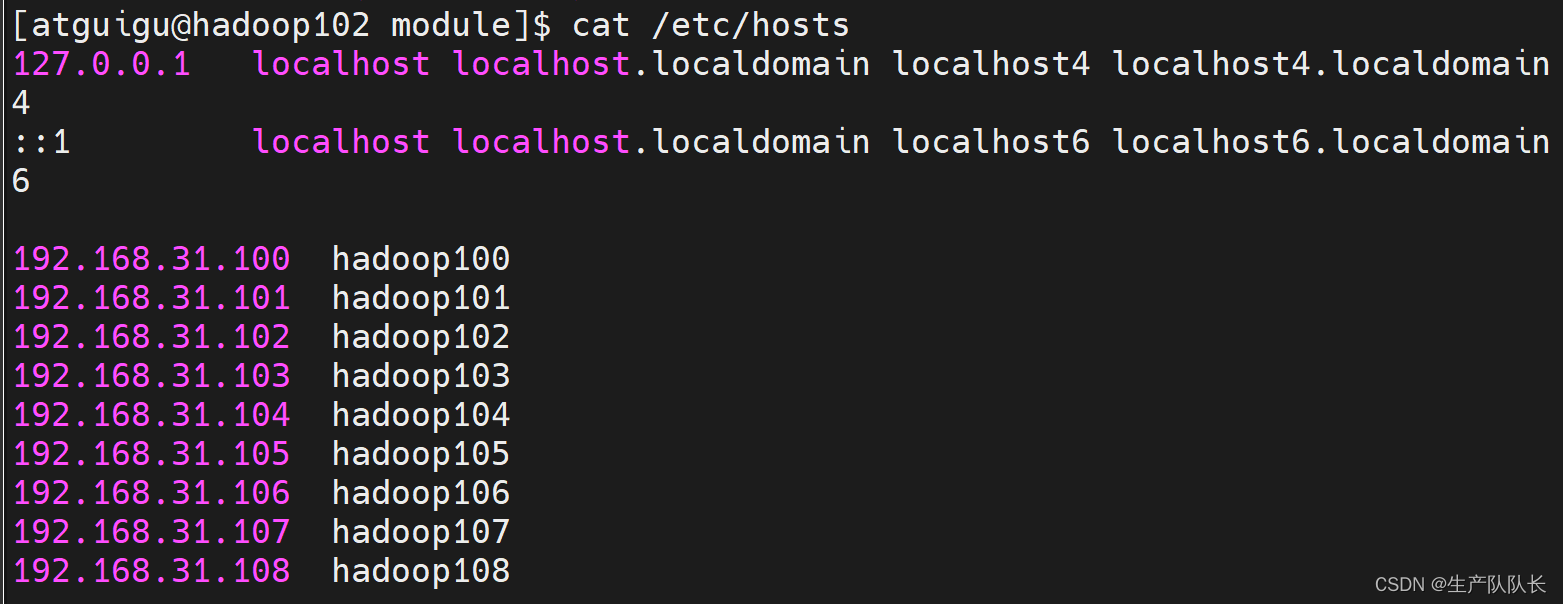
1.2、配置主机hosts文件
vim /etc/hosts192.168.31.100 hadoop100
192.168.31.101 hadoop101
192.168.31.102 hadoop102
192.168.31.103 hadoop103
192.168.31.104 hadoop104
192.168.31.105 hadoop105
192.168.31.106 hadoop106
192.168.31.107 hadoop107
192.168.31.108 hadoop108
1.3、创建账号
创建atguigu账号,并设置密码为123456
useradd atguigu
echo 123456|passwd --stdin atguigu;
配置atguigu账号root权限
visudo末尾添加
atguigu ALL=(ALL) NOPASSWD:ALL
1.4、三台机器间配置atguigu账号免密登陆
用102配置到103免密登陆为例
cd 进入当前账号家目录
ssh-keygen 连续三次回车
ssh-copy-id 192.168.31.103 复制公钥到hadoop103服务器,这样,102的atguigu就可以免密登陆hadoop103服务器
参考:服务器间配置免密登陆
2、3台虚拟机都安装JDK,并配置环境变量
2.1、卸载自带的OpenJDK
2.1.1、查看openJDK
[root@CFDB2 ~]$ rpm -qa|grep java
tzdata-java-2018e-3.el7.noarch
java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64
java-1.7.0-openjdk-headless-1.7.0.181-2.6.14.8.el7_5.x86_64
java-1.7.0-openjdk-1.7.0.181-2.6.14.8.el7_5.x86_64
javapackages-tools-3.4.1-11.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.171-8.b10.el7_5.x86_64
2.1.2、卸载openJDK
rpm -qa | grep -i java | xargs n1 rpm -e --nodeps
2.1.3、安装JDK8
tar -zxvf jdk-7u79-linux-x64.tar.gz -C /usr/local/jdks/
cd /usr/local/jdks/vim /etc/profile.d/java.sh#!/bin/bash
#
export JAVA_HOME=/usr/local/jdks/jdk1.8.0_211
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
--------------------------
source /etc/profile #执行该命令
java -version #查看java是否安装成功
3、3台虚拟机都安装Hadoop3,并配置环境变量
1、准备Hadoop3安装包
 2、三台机器上准备两个目录
2、三台机器上准备两个目录

3、将hadoop3安装包上传到software目录下

4、解压并配置环境变量
解压安装
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
配置环境变量
进入目录cd /etc/profile.d/创建文件,并添加如下内容
vim hadoop.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin重新加载环境变量,这样新配置的hadoop环境变量才会生效
source /etc/profile
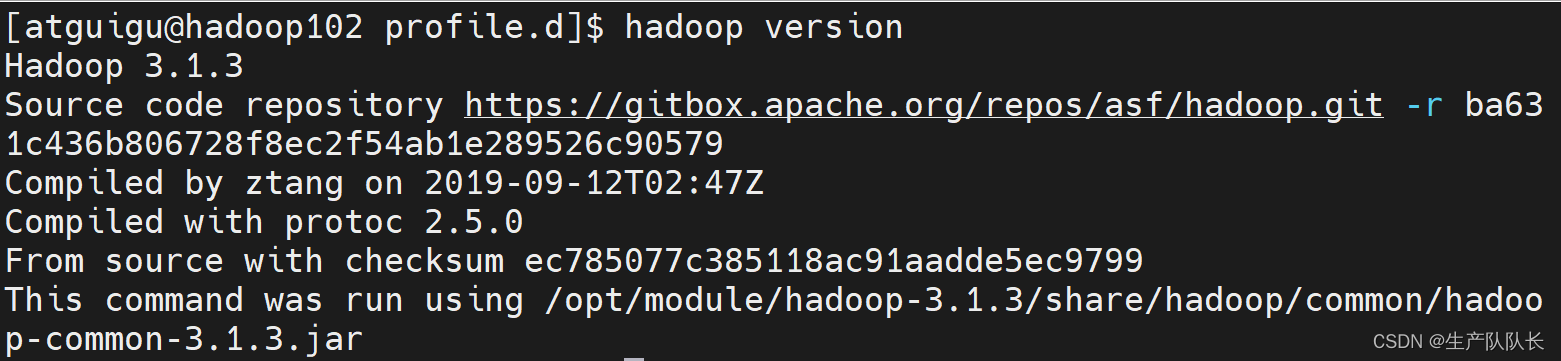
检查hadoop安装是否成
hadoop version
4、hadoop的4个自定义配置文件及workers配置
1、准备一个同步文件的脚本
参考:服务器同步文件脚本
这样,在102上配置好后,用该脚本同步到另外两台机器上即可。
2、core-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
完整配置内容如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration>
<property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value><description>指定 NameNode 的地址</description>
</property><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value><description>指定 Hadoop 数据的存储目录</description>
</property>
</configuration>
3、hdfs-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
完整配置内容如下
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value><description>nn web 端访问地址</description>
</property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value><description>2 nn web 端访问地址</description>
</property>
</configuration>
4、mapred-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
完整配置内容如下
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description></description></property><property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value><description>历史服务器端地址</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value><description>历史服务器 web 端地址</description></property>
</configuration>5、yarn-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
完整配置内容如下
<?xml version="1.0"?>
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>指定 MR 走 shuffle</description></property><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value><description>指定 ResourceManager 的地址</description></property> <property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value><description>系统环境变量的继承</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>开启日志聚集功能</description></property><property><description>设置日志聚集服务器地址</description><name>yarn.log.server.url</name><value>http://hadoop102:19888/jobhistory/logs</value></property><property><description>设置日志保留时间为 7 天, -1 表示不保存日志</description><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>
6、配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
完整配置内容如下
hadoop102
hadoop103
hadoop104
7、使用xsync同步脚本,将配置文件同步到103、104
xsync core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers
5、启动HDFS服务
1、第一次启动的准备工作
需要在hadoop102上格式化 NameNode(后面重启hadoop集群,无需这一步操作)
cd /opt/module/hadoop-3.1.3
hdfs namenode -format

2、启动HDFS服务
cd /opt/module/hadoop-3.1.3
sbin/start-dfs.sh

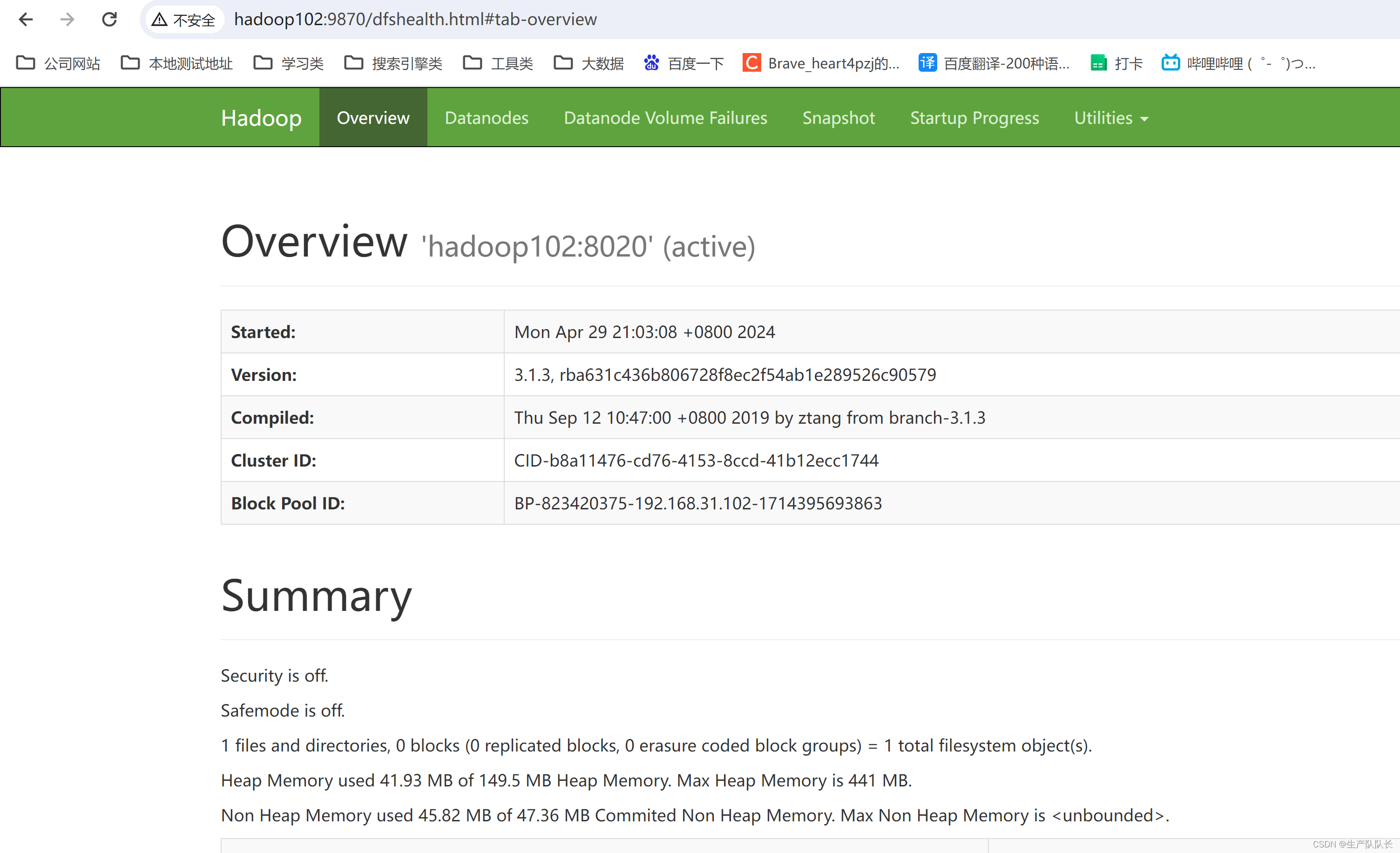
3、访问web页
http://hadoop102:9870
6、103上启动YARN
1、启动YARN服务
cd /opt/module/hadoop-3.1.3
sbin/start-yarn.sh

2、访问web页
http://hadoop103:8088

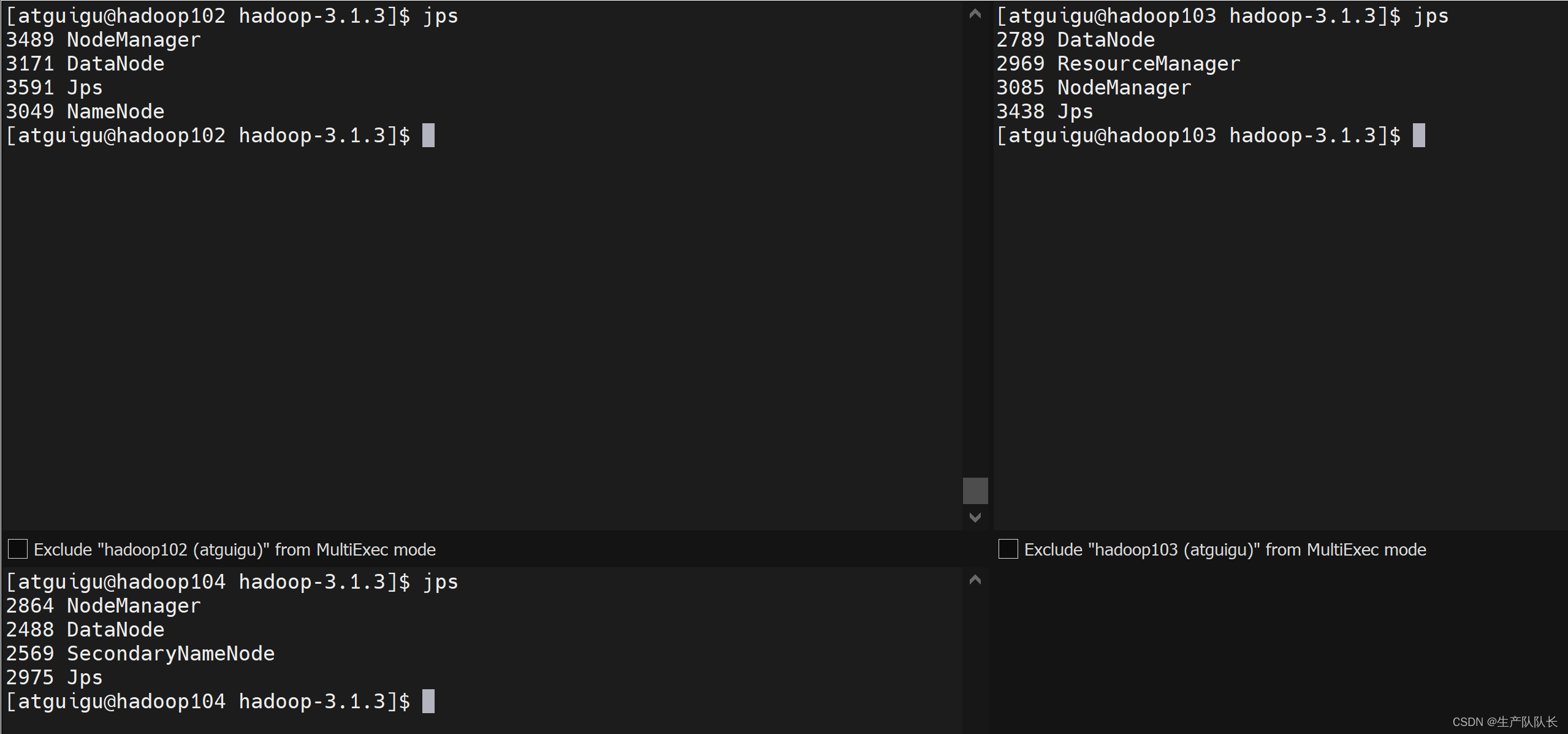
7、检查各个集群节点服务
从图中可以看出,和我们设计的集群架构完全匹配
8、在102上开启YARN的历史任务查询服务
cd /opt/module/hadoop-3.1.3
bin/mapred --daemon start historyserver

9、同步集群时间
10、测试集群相关功能
明天继续。。。
这篇关于Hadoop3:集群搭建及常用命令与shell脚本整理(入门篇,从零开始搭建)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







