grad专题

【PyTorch】深入解析 `with torch.no_grad():` 的高效用法
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C++干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 文章目录 引言一、`with torch.no_grad():` 的作用二、`with torch.no_grad():` 的原理三、`with torch.no_grad():` 的高效用法3.1 模型评估3.2 模型推理3.3

深度学习01:pytorch中model eval和torch no_grad()的区别
公众号:数据挖掘与机器学习笔记 主要区别如下: model.eval()会通知所有的网络层目前处于评估模式(eval mode),因此,batchnorm或者dropout会以评估模式工作而不是训练模式。 在train模式下,dropout网络层会按照设定的参数p设置保留激活单元的概率(保留概率=p); batchnorm层会继续计算数据的mean和var等参数并更新。 在val模式下,dro
【PyTorch常用库函数】一文向您详解 with torch.no_grad(): 的高效用法
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C++干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 引言 在训练神经网络时,我们通常需要计算损失函数关于模型参数的梯度,以便通过梯度下降等优化算法更新参数。然而,在评估阶段,我们只关心模型的输出,而不需要更新参数。在这种情况下,使用 with torch.no_grad(): 上下文管

【Pytorch】一文向您详尽解析 with torch.no_grad(): 的高效用法
【Pytorch】一文向您详尽解析 with torch.no_grad(): 的高效用法 下滑即可查看博客内容 🌈 欢迎莅临我的个人主页 👈这里是我静心耕耘深度学习领域、真诚分享知识与智慧的小天地!🎇 🎓 博主简介:985高校的普通本硕,曾有幸发表过人工智能领域的 中科院顶刊一作论文,熟练掌握PyTorch框架。 🔧 技术专长: 在CV、NLP及多模态等领域有丰富的项目

【Grad-Cam】pycaffe实现
python获取梯度脚本 # -*- coding: UTF-8 -*-import sysimport shutilimport ossys.path.insert(0, "caffe/python")import caffeimport numpy as npimport dicomimport cv2from scipy.misc import bytescalefr
optimizer.zero_grad()
optimizer.zero_grad()意思是把梯度置零,也就是把loss关于weight的导数变成0. 在学习pytorch的时候注意到,对于每个batch大都执行了这样的操作: # zero the parameter gradientsoptimizer.zero_grad()# forward + backward + optimizeoutputs = net(in

model.eval()和torch.no_grad()的区别
model.eval() model.eval()是PyTorch中模型的一个方法,用于设置模型为评估模式。在评估模式下,模型的所有层都将正常运行,但不会进行反向传播(backpropagation)和参数更新。此外,某些层的行为也会发生改变,如Dropout层将停止dropout,BatchNorm层将使用训练时得到的全局统计数据而不是评估数据集中的批统计数据。 torch.no_grad()
pytorch中的zero_grad()函数的含义和使用
optimizer.zero_grad() ,用于将模型的参数梯度初始化为0。 #反向计算loss.backward()#反向传播计算梯度optimizer.step()#更新参数,梯度被反向计算之后,调用函数进行所有参数更新#在反向传播计算时,梯度的计算是累加,但是每个batch处理时不需要和其它batch混合起来累加计算,所以对每个batch调用zero_grad将参数梯度置0#如

clip_grad_norm_ 梯度裁剪
torch.nn.utils.clip_grad_norm_ 函数是用来对模型的梯度进行裁剪的。在深度学习中,经常会使用梯度下降算法来更新模型的参数,以最小化损失函数。然而,在训练过程中,梯度可能会变得非常大,这可能导致训练不稳定甚至梯度爆炸的情况。 裁剪梯度的作用是限制梯度的大小,防止它们变得过大。裁剪梯度的常见方式是通过计算梯度的范数(即梯度向量的长度),如果梯度的范数超过了设定的阈值,则对
Grad-CAM(梯度加权类激活图)
Grad-CAM(Gradient-weighted Class Activation Mapping)是一种可视化技术,用于解释卷积神经网络(CNN)的决策过程。它通过生成类激活图(Class Activation Map,CAM)来突出显示对网络预测贡献最大的图像区域。以下是Grad-CAM的基本原理和流程: 原理: 梯度计算:Grad-CAM利用了神经网络在输出层对特定类别的梯度。这些梯
Training - PyTorch Lightning 分布式训练的 global_step 参数 (accumulate_grad_batches)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137640653 在 PyTorch Lightning 中,pl.Trainer 的 accumulate_grad_batches 参数允许在执行反向传播和优化器步骤之前,累积多个批次的
args.grad_accum_steps = max(1, args.grad_accum_steps)
# 将args.grad_accum_steps的值与1比较取较大值,确保args.grad_accum_steps至少为1。这个设置通常用于控制梯度累积的步数。 args.grad_accum_steps = max(1, args.grad_accum_steps) 梯度累积 why? 模型太大,不能一次性装入显存 What? 将多个小批次的的梯度累积起来,一次性参数更新 how
pytorch | with torch.no_grad()
1.关于with with 是python中上下文管理器,简单理解,当要进行固定的进入,返回操作时,可以将对应需要的操作,放在with所需要的语句中。比如文件的写入(需要打开关闭文件)等。 以下为一个文件写入使用with的例子。 with open (filename,'w') as sh: sh.write("#!/bin/bash\n")sh.write("#$ -N "+'IC'
理论学习:optimizer.zero_grad() loss.backward() optimizer.step()
optimizer.zero_grad(): 在开始一个新的迭代之前,需要清零累积的梯度。这是因为默认情况下,PyTorch在调用.backward()进行梯度计算时会累积梯度,而不是替换掉旧的梯度。如果不手动清零,那么梯度会从多个迭代中累积起来,导致错误的参数更新。optimizer.zero_grad()正是用来清除过往的梯度信息,确保每次迭代的梯度计算都是基于当前迭代的数据。 loss.b
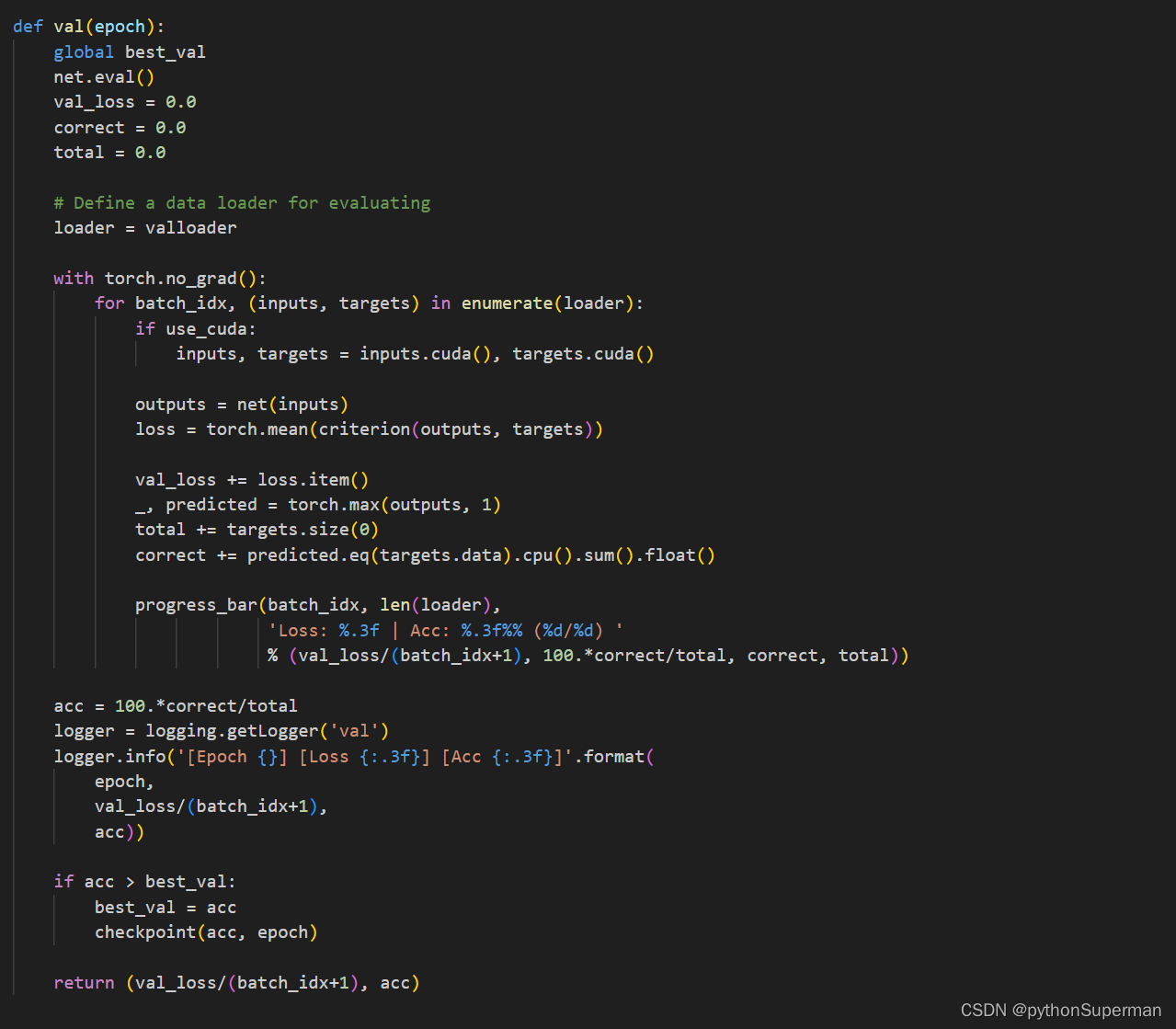
理论学习:with torch.no_grad()
如果不加上“with torch.no_grad():”,模型参数会发生改变吗? 如果不使用with torch.no_grad():,在进行模型推理(即计算outputs_cls = net(inputs[batch_size//2:])这一步)时,模型参数不会发生改变,原因如下: 参数更新机制:在PyTorch中,模型参数的更新发生在执行optimizer.step()时,这一步
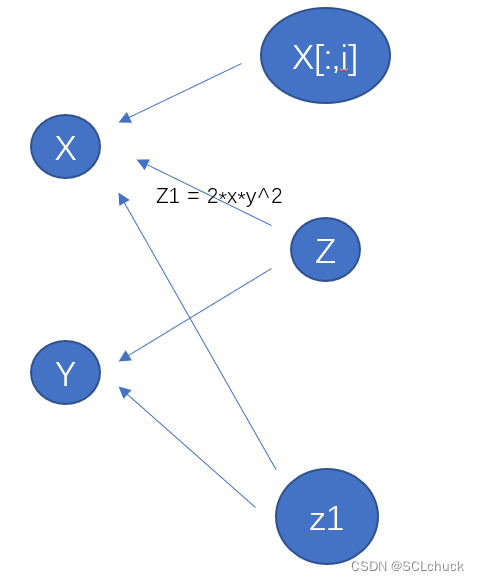
pytorch的梯度图与autograd.grad和二阶求导
前向与反向 这里我们从 一次计算 开始比如 z=f(x,y) 讨论若我们把任意对于tensor的计算都看为函数(如将 a*b(数值) 看为 mul(a,b)),那么都可以将其看为2个过程:forward-前向,backward-反向在pytorch中我们通过继承torch.autograd.Function来实现这2个过程,详细的用法和扩展参考:https://pytorch.org/doc
model.eval()与with torch.no_grad()
requires_grad、volatile与no_grad requires_gradvolatileno_gradmodel.eval()与with torch.no_grad() 总结: requires_grad=True 要求计算梯度; requires_grad=False 不要求计算梯度; model.eval()中的数据不会进行反向传播,但是仍然需要计算梯度; wi
特殊的bug:element 0 of tensors does not require grad and does not have a grad_fn
很多帖子都说了,设置requires_grad_()就行。 但是我这次遇到的不一样,设置了都不行。 我是这种情况,在前面设置了torch.no_grad():,又在这个的作用域下进行了requires_grad_(),这是不起作用的。 简单版: with torch.no_grad():model.eval()pos_embed = model(homo_data.x, homo_data.

反卷积,CAM,Grad-CAM
反卷积,导向反向传播,反向传播 区别在于反向传播过程中经过ReLU层时对梯度的不同处理策略 CAM Class Activation Mapping 借鉴GAP 对于其中一个类别: 这样,CAM以热力图的形式告诉了我们,模型是重点通过哪些像素确定这个图片是羊驼了。 Grad-CAM CAM缺点是要求修改修改原模型的结构,提出Grad-CAM 第k个特征图对类别c的
Pytorch:torch.nn.utils.clip_grad_norm_梯度截断_解读
torch.nn.utils.clip_grad_norm_函数主要作用: 神经网络深度逐渐增加,网络参数量增多的时候,容易引起梯度消失和梯度爆炸。对于梯度爆炸问题,解决方法之一便是进行梯度剪裁torch.nn.utils.clip_grad_norm_(),即设置一个梯度大小的上限。 注:旧版为torch.nn.utils.clip_grad_norm() 函数参数: 官网链接:ht
关于with torch.no_grad:的一些小问题
with torch.no_grad:是截断梯度记录的,新生成的数据的都不记录梯度,但是今天产生了一点小疑惑,如果存在多层函数嵌入,是不是函数内所有的数据都不记录梯度,验证了一下,确实是的。 import torchx = torch.randn(10, 5, requires_grad = True)y = torch.randn(10, 5, requires_grad = True)
pytorch 中detach() 和 with torch.no_grad()和eval()
detach() 和 torch.no_grad() 都可以实现相同的效果,只是前者会麻烦一点,对每一个变量都要加上,而后者就不用管了: - detach() 会返回一个新的Tensor对象,不会在反向传播中出现,是相当于复制了一个变量,将它原本requires_grad=True变为了requires_grad=False - torch.no_grad() 通常是在推断(inference

Grad-CAM简介-网络 热力图分析
论文名称:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization 论文下载地址:https://arxiv.org/abs/1610.02391 推荐代码(Pytorch):https://github.com/jacobgil/pytorch-grad-cam bilibili视频讲解:ht

【阅读笔记】《Grad-CAM: Why did you say that? ...》
本文记录了博主阅读论文《Grad-CAM: Why did you say that? Visudal Explanations from Deep Networks via Gradient-based Localization》的笔记,代码,demo。更新于2019.05.31。 文章目录 AbstractIntroductionRelated WorkApproachWeakly-s
使用Pytorch实现Grad-CAM并绘制热力图
这篇是我对哔哩哔哩up主 @霹雳吧啦Wz 的视频的文字版学习笔记 感谢他对知识的分享 看一下这个main cnn.py的文件 那这里我为了方便 就直接从官方的torch vision这个库当中导入一些我们常用的model 比如说我这里的例子是采用的mobile net v3 large这个模型 然后这里我将pretrain设置成true之后呢 它就会自动的去下载torch官方在image
为什么每次optimizer.zero_grad()
当你训练一个神经网络时,每一次的传播和参数更新过程可以被分解为以下步骤: 1前向传播:网络对输入数据进行操作,最终生成输出。这个过程会基于当前的参数(权重和偏差)计算出一个或多个损失函数的值。 2计算梯度(反向传播):损失函数对网络参数的梯度(即导数)是通过一个称为反向传播的过程计算出来的。这个过程从损失函数开始,向后通过网络传播,直到达到输入层,计算每个参数对损失的贡献。 3 更新参数:一