glm专题

在高质量视频生成文本、图像生成文本的GLM-4V-Plus技术加持下医疗未来的方向
人工智能的进步为医疗领域带来了巨大的变革,尤其是视频生成文字、图片生成文字和医学统计数据生成文字等技术的应用。这些技术使得我们能够更全面地利用大数据来辅助诊断,为患者提供更加精确和个性化的医疗服务。以下是一些可能的应用场景和优势: 1. 多模态数据整合 这三种方法都利用AI技术为医学领域提供强有力的支持,从而提高医疗质量和效率。下面是这些方法的具体作用和潜在影响: 视频生成文字: 作用:通

<Python><AI>基于智谱AI免费大模型GLM-4-Flash的智能聊天程序
前言 智谱AI开放了一个免费使用的大模型GLM-4-Flash,官方也提供了python的示例程序,我们结合pyqt5来编写一个基于GLM-4的简单的智能聊天工具。 界面大致如下: 环境配置 系统:windows 平台:visual studio code 语言:python 库:pyqt5 大模型:智谱清言 GLM-4-Flash 程序主要分两个方面,一个UI布局,一个是大模型的调用。
【深度学习】LLaMA-Factory 大模型微调工具, 微调GLM-4-9B-Chat-1M ,Docker (4)
文章目录 回顾制作镜像数据准备WebUI训练推理导出模型部署 回顾 之前LLaMA-Factory 还未正式支持GLM-4-9B,做了魔改后进行微调了: https://qq742971636.blog.csdn.net/article/details/140620014 如今LLaMA-Factory 已正式支持GLM-4-9B,本篇文章会以Docker方式进行GLM-4-9
LLM之基于llama-index部署本地embedding与GLM-4模型并初步搭建RAG(其他大模型也可)
前言 日常没空,留着以后写 llama-index简介 官网:https://docs.llamaindex.ai/en/stable/ 简介也没空,以后再写 注:先说明,随着官方的变动,代码也可能变动,大家运行不起来,可以进官网查查资料 加载本地embedding模型 如果没有找到 llama_index.embeddings.huggingface 那么:pip insta

NLP主流大模型如GPT3/chatGPT/T5/PaLM/LLaMA/GLM的原理和差异有哪些-详细解读
自然语言处理(NLP)领域的多个大型语言模型(如GPT-3、ChatGPT、T5、PaLM、LLaMA和GLM)在结构和功能上有显著差异。以下是对这些模型的原理和差异的深入分析: GPT-3 (Generative Pre-trained Transformer 3) 虽然GPT-4O很火,正当其时,GPT-5马上发布,但是其基地是-3,研究-3也是认识大模型的一个基础 原理 架构: 基于
cantos解决C++编译fatal error: glm/glm.hpp: No such file or directory
ubuntu可以直接sudo apt-get install libglm-dev 但是centos直接运行报错,参考官方链接,运行yum install glm-devel
GLM+vLLM 部署调用
GLM+vLLM 部署调用 vLLM 简介 vLLM 框架是一个高效的大型语言模型(LLM)推理和部署服务系统,具备以下特性: 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了内存浪费,优化了模型的运行效率。高吞吐量:vLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。易用性:vLLM 与 H
GLM-4-9B VLLM 推理使用;openai接口调用、requests调用
参考: https://huggingface.co/THUDM/glm-4-9b-chat 直接运行vllm后端服务: from transformers import AutoTokenizerfrom vllm import LLM, SamplingParams# GLM-4-9B-Chat-1M# max_model_len, tp_size

Datawhale出品:《GLM-4 大模型部署微调教程》发布!
前言 就在昨天,智谱 AI 发布了最新开源模型 GLM4,通过 10T 高质量多语言数据与更先进的训练技术,达到了更加出色的生成效果。 在仅有 9B 参数的前提下,在中文能力、长文本能力以及工具调用等任务中达到了更加出色的效果。 😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓 教程介绍 秉承开源贡献的宗旨,Datawhale团队成员在模型发布 12 小时 之内,为 编写了GL

清华大学与智谱AI重磅开源 GLM-4:掀起自然语言处理新革命
在强大的预训练基础上,GLM-4-9B 的中英文综合性能相比 ChatGLM3-6B 提升了 40%。尤其是中文对齐能力 AlignBench、指令遵从能力 IFeval,以及工程代码处理能力 Natural Code Bench 方面都实现了显著提升。 自 2023 年 3 月 14 日开源 ChatGLM-6B 以来,GLM 系列模型受到了广泛的关注和认可。特别是在 ChatGLM3-6B
![[大模型]GLM-4-9b-Chat 接入 LangChain](https://img-blog.csdnimg.cn/direct/973dcde342ac4d39a10abf6eb8f604b5.png#pic_center)
[大模型]GLM-4-9b-Chat 接入 LangChain
环境准备 在 01-ChatGLM4-9B-chat FastApi 部署调用 的 环境准备和模型下载基础上,我们还需要安装 langchain 包。如果不需要使用fastapi相关功能,则可以不安装 fastapi、uvicorn、requests。 pip install langchain==0.2.1 注意langchain这里使用2024年5月新发布的v0.2版本, 但本教程代码

MFC Opengl 使用glm数学库进行空间坐标系矩阵变换
求一个空间坐标系的点在另一个坐标系中的点一直是比较麻烦的一件事情,最近做项目时,恰好需要实现这样一个功能,也是想了挺久,最后实现了点在不同空间坐标系中的转换。功能是通过矩阵进行实现的,数学库用的是glm库。 问题:已知局部坐标系Local中的一个点A的坐标为Pt_local(X,Y,Z),那么,如何才能求得这个点A在世界坐标系World中的坐标表示Pt_world(X
使用智谱 GLM-4-9B 和 SiliconCloud 云服务快速构建一个编码类智能体应用
本篇文章我将介绍使用智谱 AI 最新开源的 GLM-4-9B 模型和 GenAI 云服务 SiliconCloud 快速构建一个 RAG 应用,首先我会详细介绍下 GLM-4-9B 模型的能力情况和开源限制,以及 SiliconCloud 的使用介绍,最后构建一个编码类智能体应用作为测试。 本文首发自博客 使用智谱 GLM-4-9B 和 SiliconCloud 云服务快速构建一个编码类智
基于GLM生成SQL,基于MOSS生成SQL,其中什么是GLM 什么是MOSS
GLM 和 MOSS 是两种不同的模型或系统,通常用在自然语言处理 (NLP) 和生成任务中,如生成 SQL 查询。让我们逐个解释它们的含义和用途: GLM (Generalized Language Model) GLM 是一种通用语言模型,设计用于处理和生成自然语言。以下是一些主要特点: 广泛应用:GLM 通常用于各种 NLP 任务,包括文本生成、翻译、问答系统等。大规模预训练:这些模型

GLM-4开源版本终于发布!!性能超越Llama3,多模态媲美GPT-4V,MaaS平台全面升级
今天上午,在 AI 开放日上,备受关注的大模型公司智谱 AI 公布了一系列行业落地数据: 根据最新统计,智谱 AI 大模型开放平台目前已拥有 30 万注册用户,日均调用量达到 4000 亿 Tokens。GPT-4o深夜发布!Plus免费可用!https://www.zhihu.com/pin/1773645611381747712 没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几
【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
目录 一、引言 二、模型简介 2.1 GLM4-9B 模型概述 2.2 GLM4-9B 模型架构 三、模型推理 3.1 GLM4-9B-Chat 语言模型 3.1.1 model.generate 3.1.2 model.chat 3.2 GLM-4V-9B 多模态模型 3.2.1 多模态模型概述 3.2.2 多模态模型实践 四、总结 一、引

AI大模型日报#0606:智谱AI开源GLM-4-9B、Pika再融5.8亿
导读:AI大模型日报,爬虫+LLM自动生成,一文览尽每日AI大模型要点资讯!目前采用“文心一言”(ERNIE 4.0)、“零一万物”(Yi-Large)生成了今日要点以及每条资讯的摘要。欢迎阅读!《AI大模型日报》今日要点:智谱AI近日发布了新一代开源语言模型GLM-4-9B,以其强大的推理性能、多模态处理能力及对多种语言的支持受到关注。该模型使用FP8技术提升训练效率,并在中文对齐、指令遵从等方
使用Python实现GLM解码器的示例(带有Tensor Shape标注)
下面是一个示例,演示了如何使用Python和PyTorch实现一个基于GLM(Glancing Language Model)原理的解码器,包括对每个Tensor的shape进行标注。 代码示例 import torchimport torch.nn as nnimport torch.nn.functional as Fclass GlancingDecoder(nn.Module):d

别等了!速来体验 GLM-4-9B-Chat
昨日,智谱 AI 发布了基座大模型 GLM-4 的最新开源成果——GLM-4-9B,首次拥有了多模态能力。官方给出的数据显示,对比训练量更多的 Llama-3-8B 模型,GLM-4-9B 在中文学科方面的提升高达 50%,在多模态方面可以比肩 GPT-4V。 在上下文长度上,GLM-4-9B 实现了从 128K 到 1M 的升级跨越,相当于能够一口气消化 125 篇论文!此外,其模型词表从 6
![[AI资讯·0605] GLM-4系列开源模型,OpenAI安全疑云,ARM推出终端计算子系统,猿辅导大模型备案……](https://img-blog.csdnimg.cn/img_convert/2fe12aff0de9446fb9853a33717725eb.png)
[AI资讯·0605] GLM-4系列开源模型,OpenAI安全疑云,ARM推出终端计算子系统,猿辅导大模型备案……
AI资讯 1毛钱1百万token,写2遍红楼梦!国产大模型下一步还想卷什么?AI「末日」突然来临,公司同事集体变蠢!只因四大聊天机器人同时宕机OpenAI员工们开始反抗了!AI手机PC大爆发,Arm从软硬件到生态发力,打造行业AI百宝箱GLM-4开源版本:超越Llama3,多模态比肩GPT4V,MaaS平台也大升级猿辅导竟然是一家AI公司?大模型全家桶曝光|甲子光年FineChatBI,帆软在A

ChatGPT/GLM API使用
模型幻觉问题 在自然语言处理领域,幻觉(Hallucination)被定义为生成的内容与提供的源内容无关或不忠实,具体而言,是一种虚假的感知,但在表面上却似乎是真实的。产生背景 检索增强生成(RAG)技术在弥补大型语言模型(LLM)的局限性方面取得了显著进展,尤其是在解决幻觉问题和提升实效性方面。在之前提到的LLM存在的问题中,特别是幻觉问题和时效性问题,RAG技术通过引入外部知识库的检索机制,
AI大模型探索之路-实战篇3:基于私有模型GLM-企业级知识库开发实战
文章目录 前言概述一、本地知识库核心架构回顾(RAG)1. 知识数据向量化2. 知识数据检索返回 二、大模型选择1. 模型选择标准2. ChatGLM3-6B 三、Embedding模型选择四、改造后的技术选型五、资源准备1. 安装git-lfs2. 下载GLM模型3. 下载Embeding模型 六、代码落地实践1. Embedding代码改造2. LLM代码改造3. 测试运行 总结
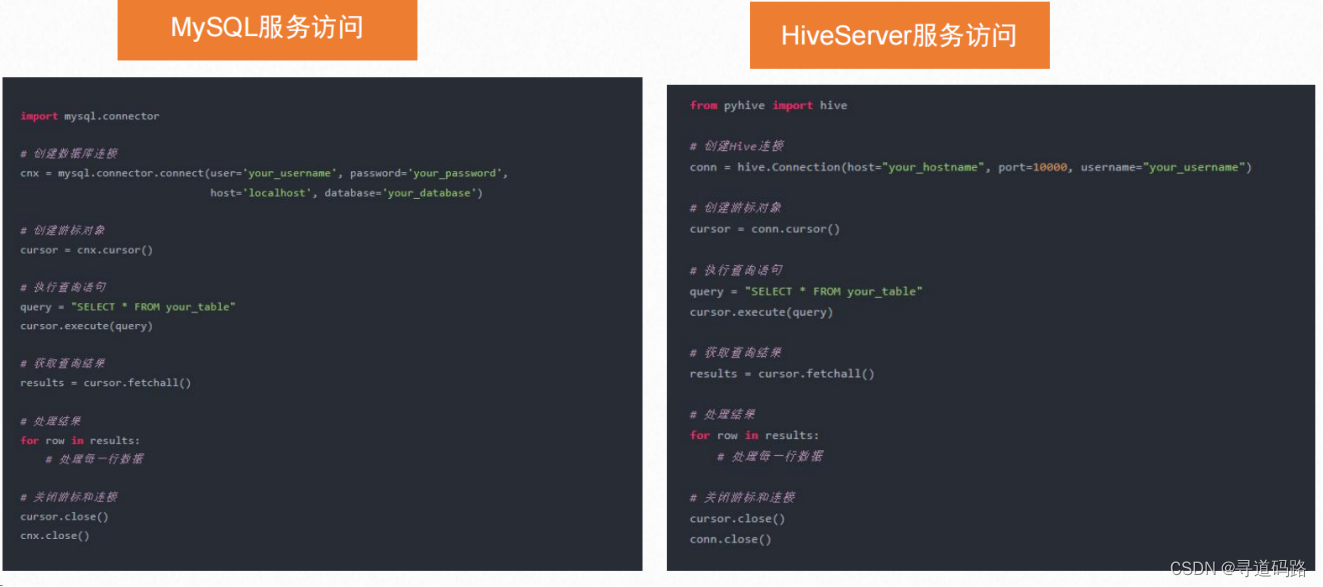
AI大模型探索之路-应用篇17:GLM大模型-大数据自助查询平台架构实践
文章目录 前言一、技术架构设计二、本地知识库准备三、SQLServer服务1. 数据库准备步骤1:安装MySQL数据库步骤2:启动MySQL数据库步骤3:登录MySQL数据库步骤4:创建数据库用户glm步骤5:给数据库用户赋权限步骤6:创建数据库 2. 数据准备3. SQL服务封装 四、核心代码落地1.模型加载2.本地知识库读取3.function call函数封装4.工具函数封装5. 调用

AI大模型探索之路-应用篇16:GLM大模型-ChatGLM3 API开发实践
目录 一、ChatGLM3-6B模型API调用 1. 导入相关的库 2. 加载tokenizer 3. 加载预训练模型 4. 实例化模型 5.调用模型并获取结果 二、OpenAI风格的代码调用 1. Openai api 启动 2. 使用curl命令测试返回 3. 使用Python发送POST请求测试返回 4. 采用GLM提供的chat对话方式 5. Embedding处理

AI大模型探索之路-应用篇15:GLM大模型-ChatGLM3-6B私有化本地部署
目录 前言 一、ChatGLM3-6B 简介说明 二、ChatGLM3-6B 资源评估 三、购买云服务器 四、git拉取GLM 五、pip安装依赖 六、运行测试 七、本地部署安装 总结 前言 ChatGLM3-6B 是 OpenAI 推出的一款强大的自然语言处理模型,它在前两代模型的基础上进行了优化和改进,具有更高的性能和更广泛的应用场景。本文将从技术角度对
glm::vec3 等结构放入结构体中 内存对其问题
介绍 在OpenGL编程中,与顶点数据的交互是非常常见的操作。在C++中,通常会使用GLM库提供的数据结构,如glm::vec3,来表示顶点数据。然而,内存对齐问题可能会影响到这种交互,特别是在涉及到结构体的内存布局时。本教程将探讨在OpenGL中如何处理顶点数据,并对比在加入GLM宏定义和不加入GLM宏定义的情况下的内存大小差异,同时提供相应的Shader代码。 当你在使用GLM库时,可能会