本文主要是介绍AI大模型探索之路-应用篇17:GLM大模型-大数据自助查询平台架构实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、技术架构设计
- 二、本地知识库准备
- 三、SQLServer服务
- 1. 数据库准备
- 步骤1:安装MySQL数据库
- 步骤2:启动MySQL数据库
- 步骤3:登录MySQL数据库
- 步骤4:创建数据库用户glm
- 步骤5:给数据库用户赋权限
- 步骤6:创建数据库
- 2. 数据准备
- 3. SQL服务封装
- 四、核心代码落地
- 1.模型加载
- 2.本地知识库读取
- 3.function call函数封装
- 4.工具函数封装
- 5. 调用查询测试
- 五、结束思考
前言
在众多大型企业中,数据资产庞大无比,因此它们纷纷构建了多种大数据平台。然而,关键在于如何高效地利用这些数据,例如,将数据有效地提供给产品经理或数据分析师以供他们进行设计和分析。在传统工作流程中,由于这些角色通常不是技术专家,他们往往无法直接使用和操控SQL,导致必须依赖技术人员来编写SQL查询并返回结果,然后才能由产品经理、数据分析师或其他相关人员进一步处理。
然而,随着强大的大模型]的出现,我们对自然语言的理解能力得到了极大的提升,同时通过支持的插件式扩展(允许自主调用相关外部方法或API),为我们解决这一难题提供了全新的思路。这些大模型不仅能够理解复杂的自然语言查询,还能够与现有的数据处理工具无缝集成,从而使得非技术用户也能够直接参与到数据分析的过程中,无需通过技术人员作为中介,极大地提高了工作效率和决策的速度。
一、技术架构设计
用户输入说明要查询的信息,LLM基于本地知识库生成SQL,调用不同的Funcation Call,每个一个Funcation call中都封装一个不同的数据服务的调用;比如Mysql、Hive、Spark、Flink。
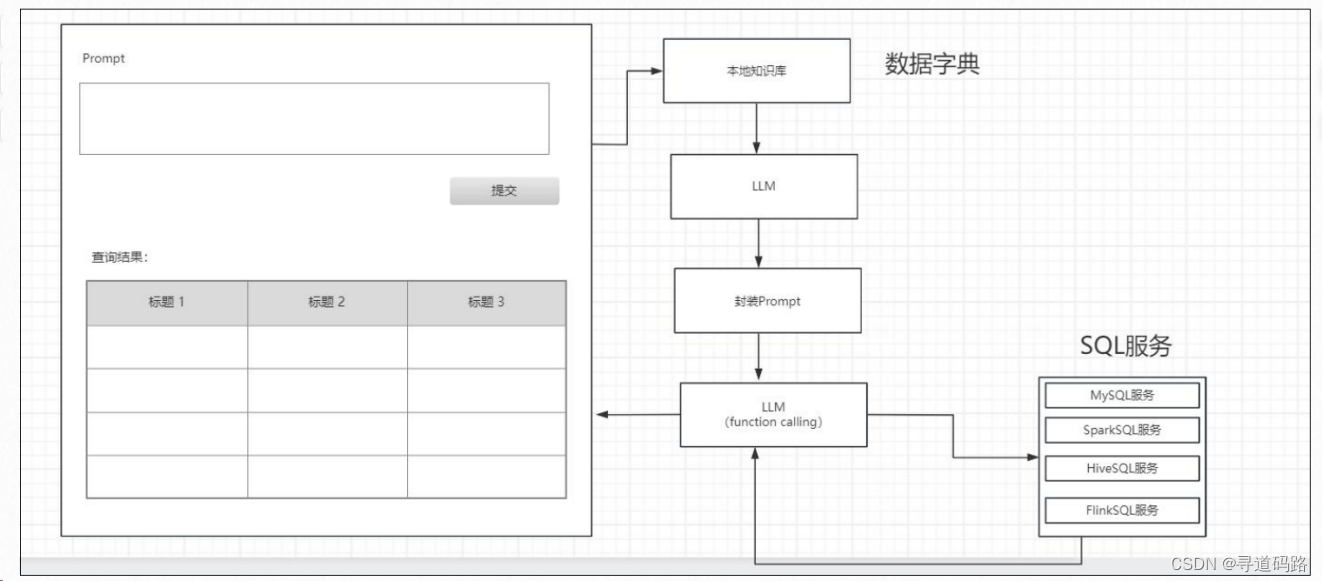
二、本地知识库准备
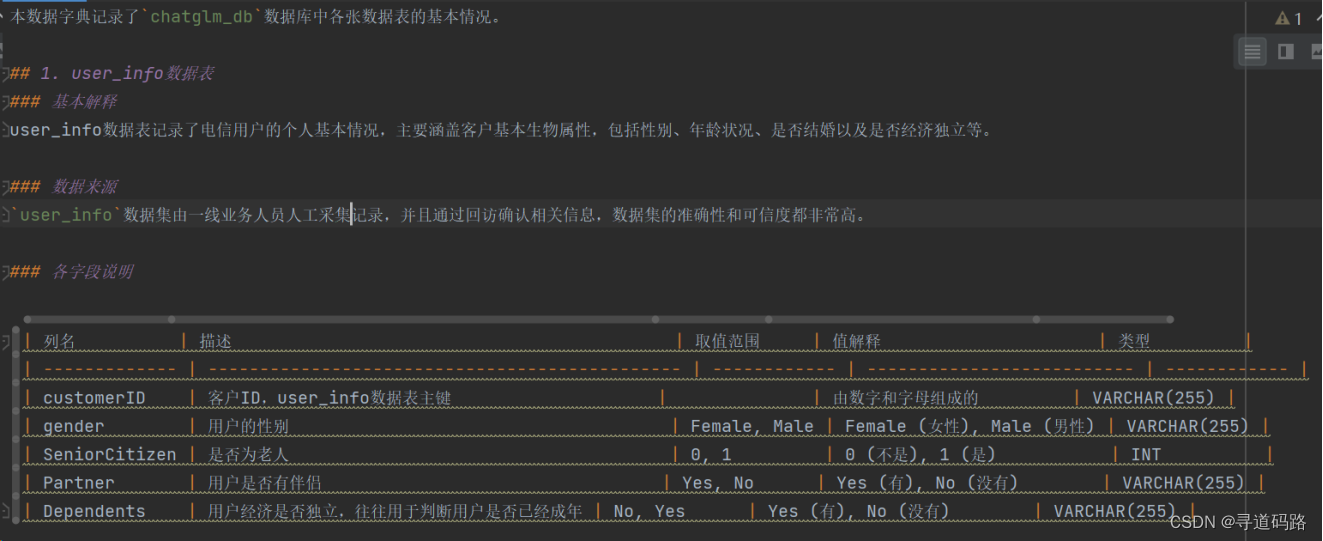
大模型擅长将输出转化为不同格式,比如从一种语言翻译成另一种语言,帮助拼写、语法纠正以及编写正则表达式;整个平台有两个基础支持的部分,第一部分就是数据字典,我们先将所有需要查询的数据库、表、字段信息结构化整理成数据字典,作为本地知识库。
三、SQLServer服务
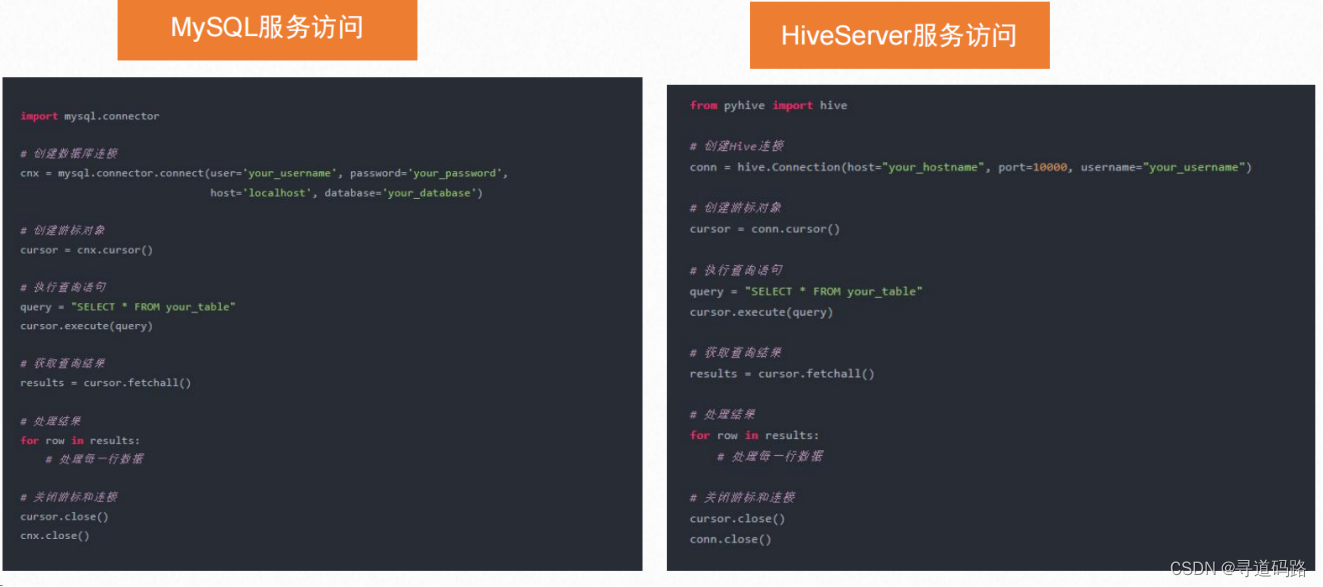
平台中两个核心支撑中另外一个就是数据服务的开发,基于不同的数据库类型,开发不同的数据服务,用于支撑LLM的数据查询;包括但不限于:MySQL数据服务,Hive数据服务、Spark数据服务、Flink数据服务等;
1. 数据库准备
步骤1:安装MySQL数据库
sudo apt-get update
sudo apt-get install mysql-server
步骤2:启动MySQL数据库
sudo service mysql start
sudo systemctl start mysqld
步骤3:登录MySQL数据库
mysql -u root -p
步骤4:创建数据库用户glm
CREATE USER 'glm'@'localhost' IDENTIFIED BY 'glm';
步骤5:给数据库用户赋权限
GRANT ALL PRIVILEGES ON *.* TO 'glm'@'localhost';
FLUSH PRIVILEGES;
步骤6:创建数据库
CREATE DATABASE glm;
USE glm;
2. 数据准备
CREATE TABLE user_info (
customerID VARCHAR(255),
gender VARCHAR(255),
SeniorCitizen INT,
Partner VARCHAR(255),
Dependents VARCHAR(255)
);
INSERT INTO user_info (customerID, gender, SeniorCitizen, Partner, Dependents)
VALUES
('1', 'Female', 0, 'Yes', 'No'),
('2', 'Male', 1, 'No', 'Yes'),
('3', 'Male', 0, 'No', 'No'),
('4', 'Female', 1, 'Yes', 'Yes'),
('5', 'Male', 0, 'No', 'No'),
('6', 'Female', 0, 'Yes', 'Yes'),
('7', 'Male', 1, 'Yes', 'No'),
('8', 'Female', 0, 'No', 'No'),
('9', 'Male', 1, 'Yes', 'Yes'),
('10', 'Female', 0, 'No', 'No'),
('11', 'Male', 0, 'Yes', 'Yes'),
('12', 'Female', 1, 'No', 'No'),
('13', 'Male', 0, 'No', 'Yes'),
('14', 'Female', 0, 'Yes', 'No'),
('15', 'Male', 1, 'Yes', 'Yes'),
('16', 'Female', 0, 'No', 'No'),
('17', 'Male', 0, 'No', 'Yes'),
('18', 'Female', 1, 'Yes', 'No'),
('19', 'Male', 0, 'No', 'No'),
('20', 'Female', 1, 'No', 'Yes');
3. SQL服务封装
安装依赖:! pip install pymysql
封装SQL执行函数(将传入的SQL代码传输至MySQL环境中进行运行,并最终返回SQL代码运行结果)。
import pymysql
import json
def sql_inter(sql_query):"""用于执行一段SQL代码,并最终获取SQL代码执行结果,\核心功能是将输入的SQL代码传输至MySQL环境中进行运行,\并最终返回SQL代码运行结果。需要注意的是,本函数是借助pymysql来连接MySQL数据库。:param sql_query: 字符串形式的SQL查询语句,用于执行对MySQL中telco_db数据库中各张表进行查询,并获得各表中的各类相关信息:return:sql_query在MySQL中的运行结果。"""connection = pymysql.connect(host="localhost", # 数据库地址user='glm', # 数据库用户名passwd="glm", # 数据库密码db=glm', # 数据库名charset='utf8' # 字符集选择utf8)try:with connection.cursor() as cursor:# SQL查询语句sql = sql_querycursor.execute(sql)# 获取查询结果results = cursor.fetchall()finally:connection.close()return json.dumps(results)
#函数测试
sql_inter("select count(*) from user_info")
'[[20]]'
四、核心代码落地
接收前端用户的输入信息,LLM基于本地知识库,生成SQL;自主判断(根据提示和描述信息的相关性)通过Funcation Call调用不同数据服务;返回结果给到前端用户;
1.模型加载
从huggingface拉取分词器模型和基础大模型,进行加载运行到本地服务器
##测试模型
from transformers import AutoTokenizer, AutoModeltokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b",
trust_remote_code=True)#model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(8).cuda()
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True,device='cuda')model = model.eval()
2.本地知识库读取
将数据库、表、字段等数据字典信息,整理成一个Markdown文件
# 打开并读取Markdown文件
with open('user_info.md', 'r', encoding='utf-8') as f:data_dictionary = f.read()## 定义一个简单的数据库测试服务
sql_inter(sql_query='SELECT COUNT(*) FROM user_info;')
3.function call函数封装
sql_inter_function_info = [{'name': 'sql_inter','description': '用于执行一段SQL代码,并最终获取SQL代码执行结果,核心功能是将输入的SQL代码传输至MySQL环境中进行运行,并最终返回SQL代码运行结果。','parameters': {'type': 'object','properties': {'sql_query': {'type': 'string','description': '字符串形式的SQL代码,可以在MySQL中运行,并获取运行结果'}},'required': ['sql_query']}
}
]
4.工具函数封装
def run_conv_glm(query,tokenizer, history, model,functions_list=None, functions=None, return_function_call=True):"""能够自动执行外部函数调用的Chat对话模型:param messages: 必要参数,输入到Chat模型的messages参数对象:param functions_list: 可选参数,默认为None,可以设置为包含全部外部函数的列表对象:param model: Chat模型,可选参数,默认模型为chatglm3-6b:return:Chat模型输出结果"""# 如果没有外部函数库,则执行普通的对话任务if functions_list == None:response, history = model.chat(tokenizer, query, history=history)final_response = response# 若存在外部函数库,则需要灵活选取外部函数并进行回答else:# 创建调用外部函数的system_messagesystem_info = {"role": "system","content": "Answer the following questions as best as you can. You have access to the following tools:","tools": functions,}# 创建外部函数库字典available_functions = {func.__name__: func for func in functions_list}history=[system_info]## 第一次调用,目的是获取函数信息 response,history = model.chat(tokenizer, query, history=history)print(response)# 需要调用外部函数function_call = response# 获取函数名function_name = function_call["name"]# 获取函数对象fuction_to_call = available_functions[function_name]# 获取函数参数function_args = function_call['parameters']# 将函数参数输入到函数中,获取函数计算结果function_response = fuction_to_call(**function_args)# print("答案")# print(function_response)# ## 第二次调用,带入进去函数# history=[]# history.append(# {# "role": "observation",# "name": function_name,# "content":function_response,# }# ) # print(history)# query= "请帮我到查询一下有多少电信用户,并给出答案"# response, history = model.chat(tokenizer, query, history=history)final_response=function_responsereturn final_response,history
5. 调用查询测试
query = data_dictionary + ",请帮我到查询一下有多少电信用户,并给出答案?"
history=[]
functions_list = [sql_inter]
functions=sql_inter_function_info
response,history = run_conv_glm(query=query,functions=functions,model=model,functions_list=functions_list,history=history,tokenizer=tokenizer)
第一次:执行输出如下: (结果很正确😀)
{'name': 'sql_inter', 'parameters': {'sql_query': 'SELECT COUNT(*) FROM user_info'}}
打印:print(response) 输出结果正确: [[20]]
第二次:执行输出如下:(结果也没啥问题😀)
{'name': 'sql_inter', 'parameters': {'sql_query': 'SELECT COUNT(*) FROM user_info WHERE gender IN("Male", "Female")'}}
第三次:执行输出如下:(条件中出现了未知字段 is_senior ,很明显翻车了😂)
{'name': 'sql_inter', 'parameters': {'sql_query': 'SELECT COUNT(*) FROM user_info WHERE is_senior = 0;'}}
第四次:执行输出如下:(不知道怎么查询了,彻底蒙圈了🤣)
您好,我可以帮您查询这个问题。请问您需要使用哪种编程语言进行查询?
第五次:执行输出如下:(还是回答错误😂)
{'name': 'sql_inter', 'parameters': {'sql_query': 'SELECT COUNT(*) FROM user_info WHERE gender = "Male"'}}
第五次:执行输出如下:(又回答对了😀)
{'name': 'sql_inter', 'parameters': {'sql_query': 'SELECT COUNT(*) FROM user_info'}}
五、结束思考
1)大模型的问世,为我们带来了前所未有的便捷性。众多传统应用正从全新的角度,借助大模型的力量进行着颠覆性的重构。然而,大模型的稳定性尚存变数,这一点在功能设计时必须予以充分考虑。
2)对于本平台的本地知识库,如果采纳微调的策略来丰富和优化大模型,将显得更为合理。鉴于知识库涵盖的内容广泛,数据字典信息繁多,这种微调方式有助于提升大模型的理解力和应用效果。
👉上一篇: AI大模型探索之路-应用篇16:GLM大模型-ChatGLM3 API开发实践
🔖更多专栏系列文章:AIGC-AI大模型探索之路
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,还望各位老铁多多关注并给予支持。
这篇关于AI大模型探索之路-应用篇17:GLM大模型-大数据自助查询平台架构实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







