etl专题

使用 Apache Flink 开发实时ETL
来源:薄荷脑的博客 作者:薄荷脑 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! By 大数据技术与架构 场景描述:本文将介绍如何使用 Flink 开发实时 ETL 程序,并介绍 Flink 是如何保证

微信公众号《GIS 数据工程:开始您的 ETL 之旅 》 文章删除及原因
微信公众号多次限制付费文章发布,不太明确其原因。我猜可能是得罪了某位大神,这倒是也不是不可能。我这说话口无遮拦,得罪几个人偶尔搞我一下也是应该的 。当然也可能是部分喜欢白嫖的网友一看我收费就不太高兴,偶尔做点小动作也是有可能的。还有就是平台可能有其它我未知的情况。反正也不猜了,这类问题纠结起来太浪费时间,所以认怂是最好的处理方式。 因此我只能改为线下购买。如有需要线下与我联系。以后

ETL数据集成丨SQLServer到Doris的无缝数据同步策略
在现代企业数据架构中,数据整合是至关重要的一个环节,它不仅关乎数据的准确性与一致性,还直接影响到数据分析的有效性和业务决策的精确性。Doris(原名 Palo)与 Hive 是两大在大数据处理领域内广泛应用的数据存储与分析系统,它们各有千秋,适用于不同的场景。将Doris数据整合至Hive数据库,旨在融合两者的优势,构建更为强大、灵活的数据分析平台,以支撑复杂多变的业务需求。 Doris与Hiv

大数据-ETL工具:Sqoop【关系型数据库(MySQL,Oracle...) <==(业务)数据==> Hive/HBase/HDFS】【Hadoop与关系数据库之间传送数据的工具】
我们常用的 ETL 工具有Sqoop、Kettle、Nifi: Kettle虽然功能较完善,但当处理大数据量的时候瓶颈问题比较突出;NiFi的功能强大,且支持大数据量操作,但NiFi集群是独立于Hadoop集群的,需要独立的服务器来支撑,强大也就意味着有上手门槛,学习难度大,用人成本高;Sqoop专为关系型数据库和Hadoop之间的ETL而生,支持海量数据,符合项目的需求,且操作简单门槛低。

大数据-案例-离线数仓-在线教育:MySQL(业务数据)-ETL(Sqoop)->Hive数仓【ODS层-数据清洗->DW层(DWD-统计分析->DWS)】-导出(Sqoop)->MySQL->可视化
一、商业BI系统概述 商业智能系统,通常简称为商业智能系统,是商业智能软件的简称,是为提高企业经营绩效而采用的一系列方法、技术和软件的总和。通常被理解为将企业中的现有数据转换为知识并帮助企业做出明智的业务决策的工具。 BI系统中的数据来自企业的其他业务系统。例如,一个面向业务的企业,其业务智能系统数据包括业务系统订单、库存、交易账户、客户和供应商信息,以及企业所属行业和竞争对手的数据,以及其他

使用 Python 和 SQL 自动将 ETL 传输到 SFTP 服务器
了解如何在 Windows 上自动执行从 PostgreSQL 数据库到远程服务器的日常数据传输过程 欢迎来到雲闪世界。将文件从一个位置传输到另一个位置的过程显然是自动化的完美选择。重复执行这项工作可能令人望而生畏,尤其是当您必须对几组数据执行整个 ETL(提取、转换、加载)过程时。 假设您的公司将数据存放在数据仓库中,然后他们决定将部分分析工作外包给外部数据分析供应商。该供应

大数据技术之_05_Hadoop学习_03_MapReduce_MapTask工作机制+ReduceTask工作机制+OutputFormat数据输出+Join多种应用+计数器应用+数据清洗(ETL)
大数据技术之_05_Hadoop学习_03_MapReduce 3.3.4 WritableComparable排序3.3.5 WritableComparable排序案例实操(全排序)3.3.6 WritableComparable排序案例实操(区内排序)3.3.7 Combiner合并3.3.8 Combiner合并案例实操3.3.9 GroupingComparator分组(辅助排序/

ETL工具~Kettle调研
ETL工具~Kettle调研 2017.2Kettlekettle是其中Pentaho默认的ETL工具,下图为Pentaho的使用情况 什么是ETL 抽取(Extract):需要连接到不同的数据资源,以便为随后的步骤(转换、加载、分析、报表展示等)提供数据。数据抽取实际上是ETL解决方案的成功实施的一个主要障碍。转换(Transform):任何对数据的处理过程都是转换。通常包括:1、移

SSIS--如何在 ETL 项目中统一管理上百个 SSIS 包的日志和包配置框架
原文链接:http://www.cnblogs.com/biwork/p/biworklog.html
ETL自学之路-01(初识ETL)
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
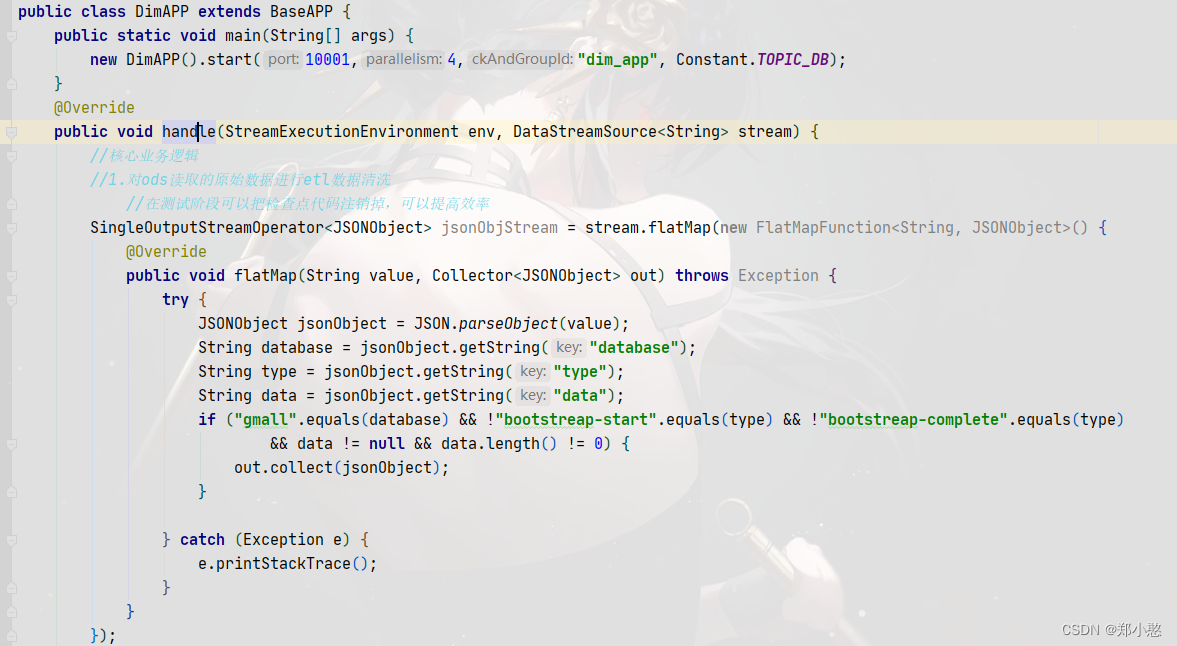
使用Flink接受kafka中的数据并对数据进行ETL
做这个开发是因为:在实际开发操作中,你的kafka主题中会有大量的数据但是需求并不需要所有数据,所有我们要对数据进行清洗,把需要的数据保存在flink流中,为下流的开发做好数据保障! 首先创建工具类 再写一个抽象类,测试阶段可以把状态后端和检查点给注释掉,可以提高效率 再写一个主程序继承抽象类中的方法,并在程序中对数据进行etl

kettle从入门到精通 第七十一课 ETL之kettle 再谈http post,轻松掌握body中传递json参数
场景: kettle中http post步骤如何发送http请求且传递body参数? 解决方案: http post步骤中直接设置Request entity field字段即可。 1、手边没有现成的post接口,索性用python搭建一个简单的接口,关键代码如下(安装python环境略): from flask import Flask, request, jsonifyap
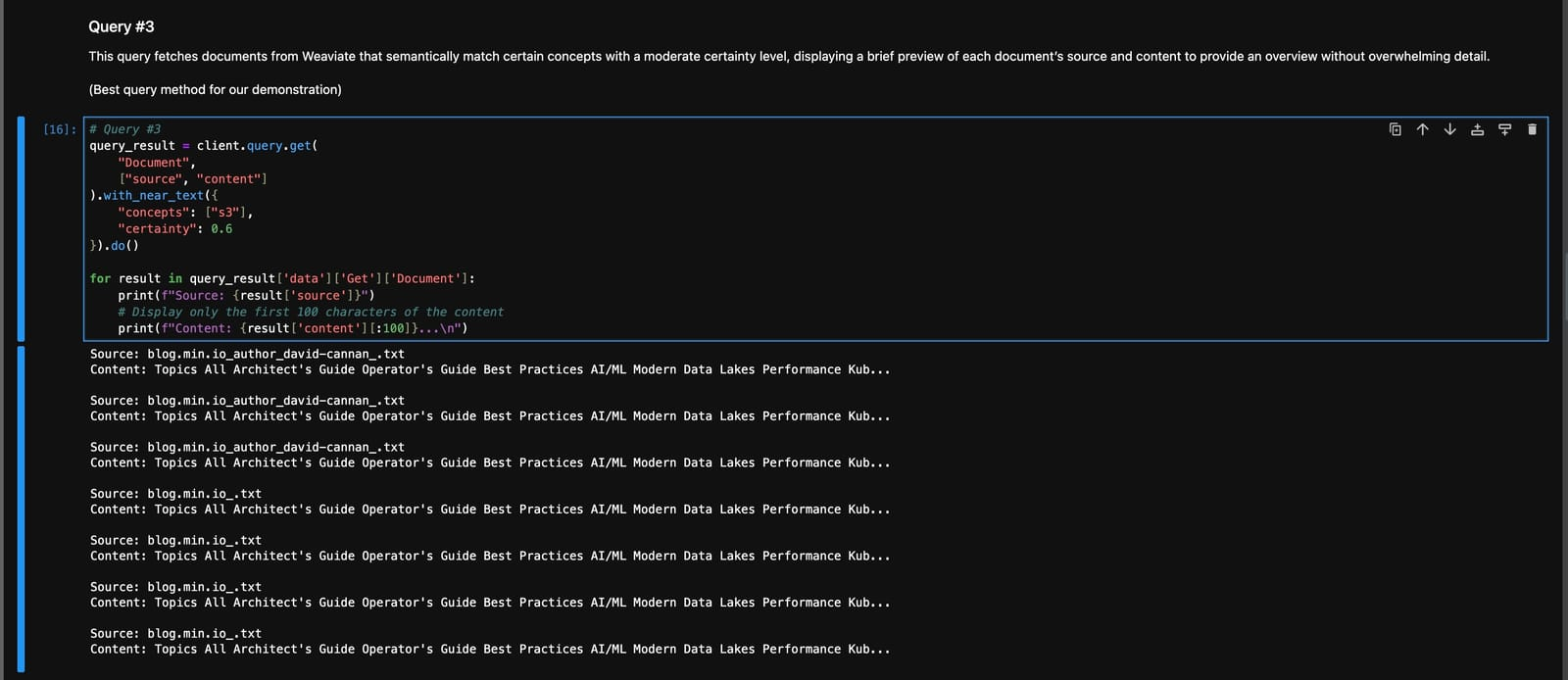
动态 ETL 管道:使用非结构化 IO 将 AI 与 MinIO 和 Weaviate 的 Web
在现代数据驱动的环境中,网络是一个无穷无尽的信息来源,为洞察力和创新提供了巨大的潜力。然而,挑战在于提取、构建和分析这片浩瀚的数据海洋,使其具有可操作性。这就是Unstructured-IO 的创新,结合MinIO的对象存储和Weaviate的AI和元数据功能的强大功能。它们共同创建了一个动态 ETL 管道,能够将非结构化 Web 数据转换为结构化的、可分析的格式。 本文探讨了这些强大技术的
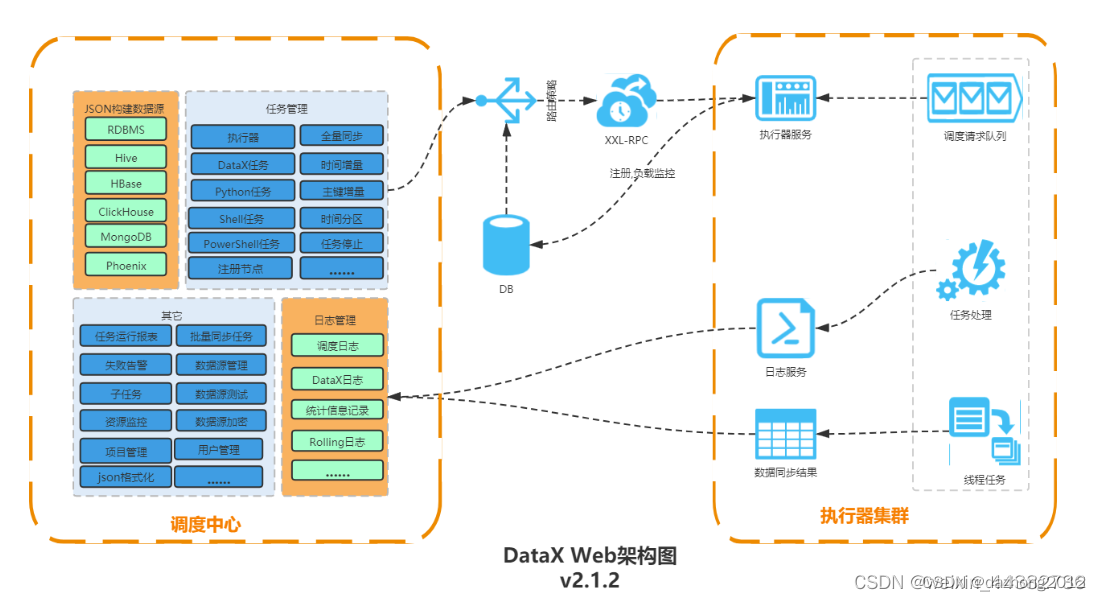
ETL可视化工具 DataX -- 简介( 一)
引言 DataX 系列文章: ETL可视化工具 DataX – 安装部署 ( 二) 1.1 DataX 1.1.1 Data X概览 DataX 是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、
ETL可视化工具 DataX -- 安装部署 ( 二)
引言 DataX 系列文章: ETL可视化工具 DataX – 简介 ( 一) DataX 私有仓库 : https://gitee.com/dazhong000/datax.git https://gitee.com/dazhong000/datax-web.git 本地地址:E:\soft\2023-08-datax 2.1 DataX安装 安装文档 git地址:https://g

MLSQL:一分钟让 Kylin 装备 ETL 能力
在上周举办的 Apache Kylin + MLSQL Meetup 中,我们邀请了来自 MLSQL 社区的技术大佬 祝威廉 来进行分享。大家都知道 Kylin 一向以强大的分析能力和丰富的周边生态而备受欢迎,但是 Kylin 自身还欠缺一些 ETL 能力。在本次分享中,祝威廉演示了如何在 Kylin 中快速完成数据处理,用户不用离开 Kylin 即可完成大规模数据分析整个 Pipeline,同

kettle从入门到精通 第六十五课 ETL之kettle 执行动态SQL语句,轻松实现全量增量数据同步
本次课程的逻辑是同步t1表数据到t2表,t1和t2表的表机构相同,都有id,name,createtime三个字段。 CREATE TABLE `t1` (`id` bigint NOT NULL AUTO_INCREMENT,`name` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,`cr
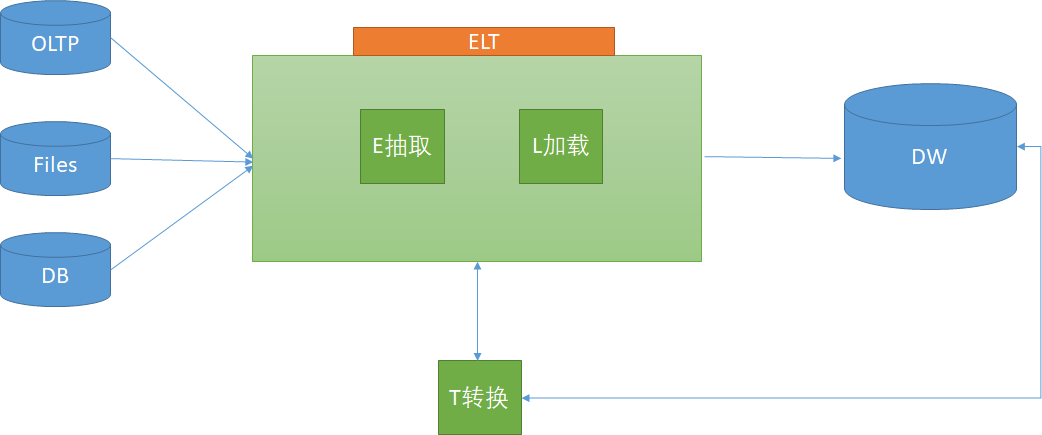
深入解析ETL与ELT架构:数据集成技术的演进与发展
摘要:随着大数据时代的到来,数据集成成为企业信息化建设的重要环节。本文将深入探讨ETL与ELT两种架构,分析它们在数据处理、性能、可扩展性等方面的差异,为企业数据集成提供技术指导。 一、引言 在大数据时代,企业需要从各种数据源中提取、转换和加载(ETL)数据,以支持业务决策和数据分析。传统的ETL架构已经无法满足现代企业对实时性、可扩展性和灵活性等方面的需求。因此,ELT架构逐渐崭露头角

kettle从入门到精通 第六十四课 ETL之kettle kettle中执行SQL脚本步骤,使用需当心
1、群里有不定时会有同学反馈执行SQL脚本步骤使用有问题,那么咱们今天一起来学习下该步骤。trans中的执行SQL脚本有两方面功能,使用时需小心,不然很容易踩坑。 官方定义: 翻译: 您可以使用此步骤执行 SQL 脚本,可以选择在转换的初始化阶段执行一次,或者针对步骤接收的每一行输入执行一次。第二个选项可用于在 SQL 脚本中使用参数。 2、执行 SQL 脚本的默认功能是只在转换
Lambda架构,Kappa架构和去ETL化的IOTA架构
经过这么多年的发展,已经从大数据1.0的BI/Datawarehouse时代,经过大数据2.0的Web/APP过渡,进入到了IOT的大数据3.0时代,而随之而来的是数据架构的变化。 ▌Lambda架构 在过去Lambda数据架构成为每一个公司大数据平台必备的架构,它解决了一个公司大数据批量离线处理和实时数据处理的需求。一个典型的Lambda架构如下: Lambda架构 数据从底层
大数据测试/ETL开发,如何造测试数据
相信很多的小伙伴,有些是大数据测试岗位,有些是ETL开发,都面临着如何要造数据的情况。 1,造数背景 【大数据测试岗位】,比较出名的就是宁波银行,如果你在宁波银行做大数据开发,对着需求开发完代码之后,可能需要把代码提交给测试人员,那么测试人员会根据这个业务需求,他们会自己造一批数据,然后看看你的sql脚本,是不是有一些明显的sql错误,以及开发规范的问题。当然,还有最重要的一点是,他们会拿着你

数据图同步软件ETL
ETL介绍 ETL(Extract, Transform, Load)软件是专门用于数据集成和数据仓库过程中的工具。ETL过程涉及从多个数据源提取数据,对数据进行转换以满足业务需求,然后将数据加载到目标数据库或数据仓库中。以下是ETL软件的一些关键功能和特点: 关键功能 数据提取(Extract): 从各种数据源(如关系数据库、文件、API、云服务等)提取数据。 支持多种数据格式和协议

ETL工具:Kettle(Spoon)实现跨库跨表迁移不同表结构的数据
最近在项目重构,重构过程中对数据库旧表进行重新设计,去掉一些无用的字段,且新表加入了一些新的字段,现在需要把旧的数据迁移到新的表中,经过一番的折腾,最终选择Kettle(Spoon)实现跨库跨表,迁移不同表结构的数据,此文希望对有类似需求的小伙伴提供一点帮助。 一、Kettle(Spoon)安装及配置 JDK环境配置,不会配置请自行百度JDK配置教程。 Kettle(Spoon)安装 直接

Kafka connect 构建ETL方案
一.背景介绍 Kafka connect是Confluent公司(当时开发出Apache Kafka的核心团队成员出来创立的新公司)开发的confluent platform的核心功能. 大家都知道现在数据的ETL过程经常会选择kafka作为消息中间件应用在离线和实时的使用场景中,而kafka的数据上游和下游一直没有一个 无缝衔接的pipeline来实现统一,比如会选择flume或者logs

liunx下ETL(kettle)脚本定时任务(crontab)启动失败定位及解决
现象: 最近项目有使用ETL工具kettle进行数据抽取更新,最终在服务器上执行时需要进行定时启动;通过crontab-e配置之后发现没有启动成功,由于只有子用户权限,没有root用户及sudo权限,经过一番排查及操作才得以解决,故记录下来; 原有步骤: 1.kettle脚本的编写 Date=`date +%Y%m%d%H%M%S`/app/ETL/kettle/kitch