本文主要是介绍深入解析ETL与ELT架构:数据集成技术的演进与发展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:随着大数据时代的到来,数据集成成为企业信息化建设的重要环节。本文将深入探讨ETL与ELT两种架构,分析它们在数据处理、性能、可扩展性等方面的差异,为企业数据集成提供技术指导。
一、引言
在大数据时代,企业需要从各种数据源中提取、转换和加载(ETL)数据,以支持业务决策和数据分析。传统的ETL架构已经无法满足现代企业对实时性、可扩展性和灵活性等方面的需求。因此,ELT架构逐渐崭露头角,成为企业数据集成的新选择。本文将对比分析ETL与ELT架构,探讨各自的优势与应用场景。

二、ETL架构
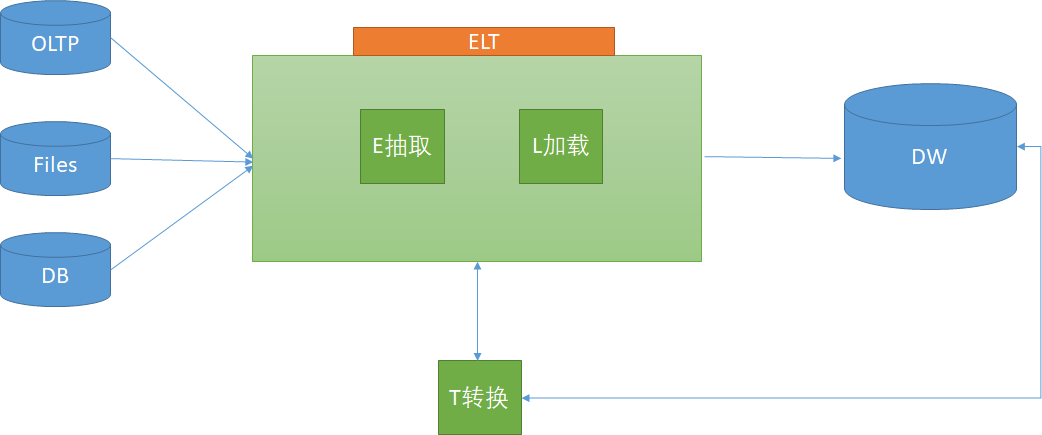
ETL(Extract, Transform, Load)架构是传统的数据集成方式,它将数据从源系统提取出来,经过一系列转换处理后,再加载到目标系统中。ETL架构主要包括以下几个步骤:
-
数据提取(Extract):从源系统中提取所需数据,可以是数据库、文件、API等多种数据源。
-
数据转换(Transform):对提取的数据进行清洗、过滤、合并、计算等操作,以满足业务需求。
-
数据加载(Load):将转换后的数据加载到目标系统中,如数据仓库、数据湖等。
ETL架构的优势在于:
-
数据质量:在数据加载到目标系统之前进行转换,可以确保数据质量和一致性。
-
性能优化:通过预先设计好的转换流程,可以优化数据处理性能,提高效率。
-
易于维护:ETL流程通常由专业的ETL工具实现,便于维护和管理。
然而,ETL架构也存在一定的局限性:
-
批处理延迟:ETL流程通常是批处理的,导致数据实时性较差。
-
扩展性受限:随着数据量的增长,ETL架构可能面临性能瓶颈。
-
灵活性不足:业务需求变化时,ETL流程需要重新设计和开发。
三、ELT架构
ELT(Extract, Load, Transform)架构是近年来兴起的一种数据集成方式,它将数据提取和加载到目标系统后,再进行转换处理。ELT架构主要包括以下几个步骤:
-
数据提取(Extract):从源系统中提取所需数据。
-
数据加载(Load):将提取的数据直接加载到目标系统中,如数据仓库、数据湖等。
-
数据转换(Transform):在目标系统内进行数据转换处理,如使用SQL、Spark等计算引擎。
ELT架构的优势在于:
-
实时性:数据提取和加载后立即进行转换,提高了数据的实时性。
-
可扩展性:借助分布式计算引擎,ELT架构可以轻松应对大数据量的处理。
-
灵活性:业务需求变化时,只需调整转换逻辑,无需重新设计ETL流程。
然而,ELT架构也存在一定的挑战:
-
数据质量:数据加载到目标系统后进行转换,可能导致数据质量问题。
-
性能压力:在目标系统内进行转换处理,可能对系统性能产生压力。
四、总结
ETL与ELT架构各有优势,企业应根据自身业务需求和数据特点选择合适的架构。对于实时性、可扩展性和灵活性要求较高的场景,ELT架构具有明显优势;而对于数据质量、性能和易于维护方面有较高要求的场景,ETL架构仍然适用。随着大数据技术的发展,未来ETL与ELT架构将不断融合和演进,为企业的数据集成提供更强大的支持。
这篇关于深入解析ETL与ELT架构:数据集成技术的演进与发展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





