elmo专题

自然语言处理(NLP)-预训练模型:别人已经训练好的模型,可直接拿来用【ELMO、BERT、ERNIE(中文版BERT)、GPT、XLNet...】
预训练模型(Pretrained model):一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型. 在NLP领域,预训练模型往往是语言模型,因为语言模型的训练是无监督的,可以获得大规模语料,同时语言模型又是许多典型NLP任务的基础,如机器翻译,文本生成,阅读理解等,常见的预训练模型有BERT, GPT, roBERTa, transf
通俗易懂ELMO原理+中文词嵌入实现(训练神雕侠侣小说)
1. 前言 今天给大家介绍一篇2018年提出的论文《Deep contextualized word representations》,在这篇论文中提出了一个很重要的思想ELMo。本文作者推出了一种新的基于深度学习框架的词向量表征模型,这种模型不仅能够表征词汇的语法和语义层面的特征,也能够随着上下文语境的变换而改变。简单来说,本文的模型其实本质上就是基于大规模语料训练后的双向语言模型内部隐状态特

自然语言处理实战项目29-深度上下文相关的词嵌入语言模型ELMo的搭建与NLP任务的实战
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目29-深度上下文相关的词嵌入语言模型ELMo的搭建与NLP任务的实战,ELMo(Embeddings from Language Models)是一种深度上下文相关的词嵌入语言模型,它采用了多层双向LSTM编码器构建语言模型,并通过各层LSTM的隐藏状态与初始的word embedding构成下游任务的输入。ELMo模型能够捕捉到词汇的多
谷歌浏览器必用AI插件 - elmo,好用,还免费
功能: 1、即时生成网站内容摘要; 2、支持提问并从页面获得直接回答; 3、通过关键词获取相关信息; 4、可以与 PDF 对话,方便理解大型文档、学习或审阅报告; 5、与 YouTube 视频交互问答(测试版本)。 地址: Elmo - Your AI web copilot, a chrome extension to create summaries, insights
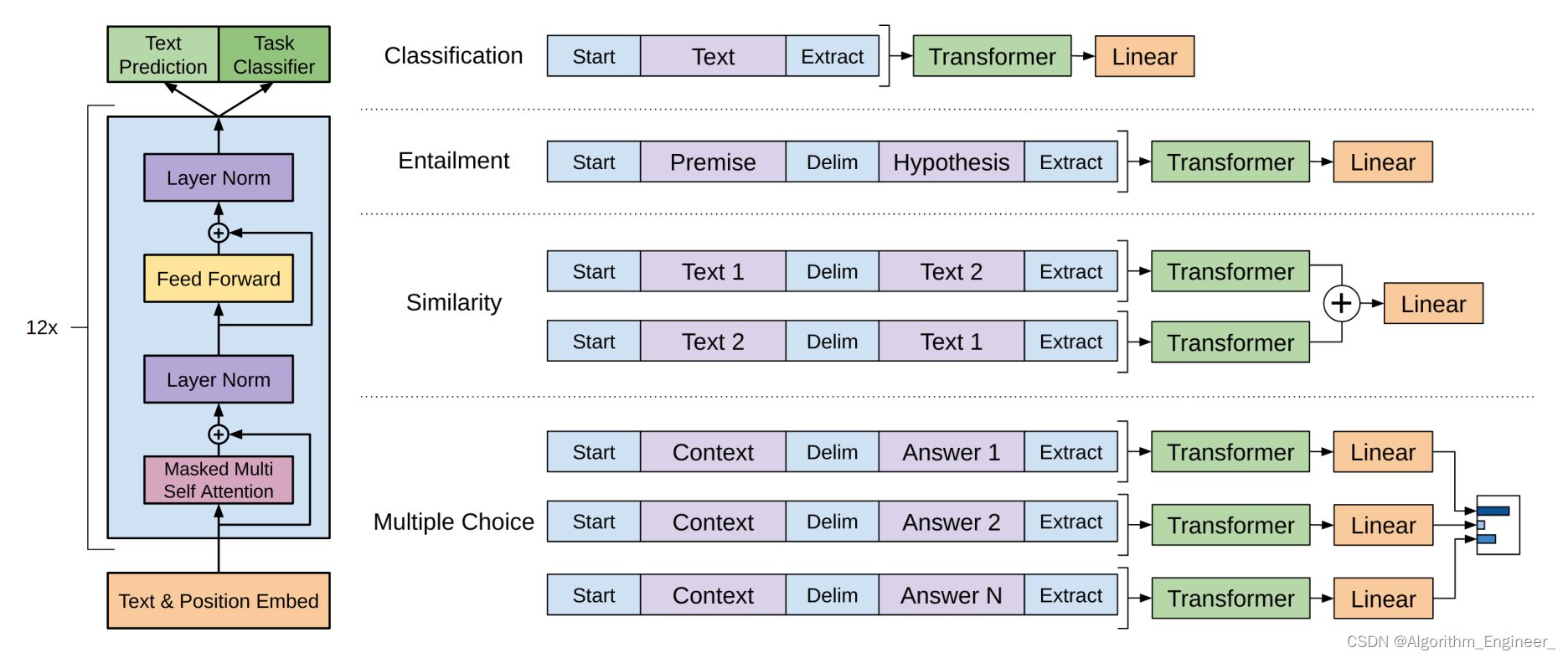
语境化语言表示模型-ELMO、BERT、GPT、XLnet
一.语境化语言表示模型介绍 语境化语言表示模型(Contextualized Language Representation Models)是一类在自然语言处理领域中取得显著成功的模型,其主要特点是能够根据上下文动态地学习词汇和短语的表示。这些模型利用了上下文信息,使得同一词汇在不同语境中可以有不同的表示。以下是一些著名的语境化语言表示模型: ELMo(Embeddings from Lan
Transformer的前世今生 day04(ELMO
ELMO 前情回顾 NNLM模型:主要任务是在预测下一个词,副产品是词向量Word2Vec模型:主要任务是生成词向量 CBOW:训练目标是根据上下文预测目标词Skip-gram:训练目标是根据目标词预测上下文词 ELMO模型的流程 针对Word2Vec模型的词向量不能表示多义词的问题,产生了ELMO模型,模型图如下: 通过不只是训练单单一个单词的Q矩阵,而是把这个词的上下文信息也融入到这

BERT学习笔记(4)——小白版ELMo and BERT
由于我没有读过原论文,该博客写的内容几乎来自于李宏毅老师的BERT课程,链接放在的最后。该博客用于梳理笔记,以便后面复习的时候使用。如果后面读了相关论文或者有了新的理解会进行更改补充。 由于是小白版本的内容,所以不会涉及到任何公式,仅用于理解该模型的作用。 目录 1 ELMo2 BERT2.1 Why Encoder?2.2 BERT如何做pre-train2.2.1 Masked

Bert and its family——ELMO
在写bert and its family之前呢,还是磨蹭了很久,主要是最近一直在喝酒,然后牌桌上的失意,愈发的难过。 在写之前呢,我们先了解一个问题:机器怎么看懂人类文字?换句话说,我们怎么把文字输入到电脑里面去,让电脑能够看懂人类文字。那在bert、ELMO之前,机器是这样去读人类文字的:最早的做法是说每一个人类的词汇就当作是一个不同的符号,每一个符号都用一个独特的编码来表示这个符号。那最常

ELMO、BERT、ERNIE、GPT
这一讲承接了上一讲关于Transformer的部分,依次介绍了基于Transformer的多个模型,包括ELMO、BERT、GPT。 因为上述的模型主要是应用在NLP中,因此首先我们必须清楚如何将离散的文本数据喂给模型,即如何用向量的方式来表征输入到模型的中的文本数据。最简单的一种方式就是one-hot向量,假设现在文档中只有apple、bag、cat、dog、elephant五个单词,那么就可

手把手教你用ELMo模型提取文本特征(附代码实现细节)
说明:本文是A Step-by-Step NLP Guide to Learn ELMo for Extracting Features from Text(Prateek Joshi — March 11, 2019)的译文以及代码实现细节说明。文中黑色文字为译文,紫色文字为本人代码实现的细节说明以及环境配置心得。 介绍 我致力于解决不同的自然语言处理 (NLP) 问题(成为数据科学家的好处
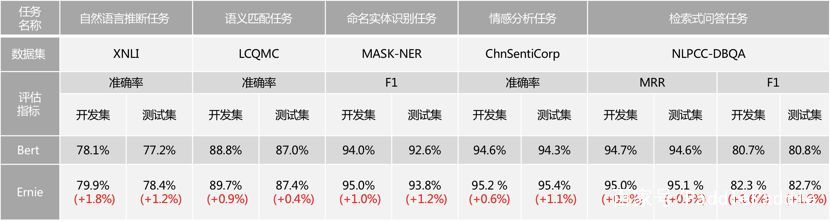
基于百科类数据训练的 ELMo 中文预训练模型
在NLP世界里,有一支很重要的家族,英文叫做LARK(LAnguage Representations Kit),翻译成中文是语言表示工具箱。目前LARK家族最新最重要的三种算法,分别是ELMo,BERT和ERNIE。 你一定不知道,这三个普通的名字,竟然包含着一个有趣的秘密。 真相,即将揭开! 我们先从算法模型的名字寻找一些蛛丝马迹 第一位,ELMo: 来自英文Embedding
李宏毅学习笔记14.ELMO、BERT、GPT
文章目录 前言之前的做法独热编码Word ClassWord Embedding缺点一词多义 Embeddings from Language Model(ELMO)Bidirectional Encoder Representations from TransformersTraining of BERTApproach 1:MaskedLMApproach 2:Next Sentenc

机器学习-32-ELMO、BERT、GPT
文章目录 ELMO、BERT、GPT背景Embeddings from Language Model(ELMO)Bidirectional Encoder Representations from Transformers(BERT)Training of BERTApproach 1:MaskedLMApproach 2:Next Sentence Prediction(NSP) How
飞桨带你了解:基于百科类数据训练的 ELMo 中文预训练模型
在NLP世界里,有一支很重要的家族,英文叫做LARK(LAnguage Representations Kit),翻译成中文是语言表示工具箱。目前LARK家族最新最重要的三种算法,分别是ELMo,BERT和ERNIE。 你一定不知道,这三个普通的名字,竟然包含着一个有趣的秘密。 真相,即将揭开! 我们先从算法模型的名字寻找一些蛛丝马迹 第一位,ELMo: 来自英文Embedding from

NLP详细教程:手把手教你用ELMo模型提取文本特征(附代码论文)
作者:PRATEEK JOSHI 翻译:韩国钧 校对:李 浩 本文约3500字,建议阅读15分钟。 本文将介绍ELMo的原理和它与传统词嵌入的区别,然后通过实践来展示其效果。 简介 我致力于研究自然语言处理(NLP)领域相关问题。每个NLP问题都是一次独特的挑战,同时又反映出人类语言是多么复杂、美丽又绝妙。 但是一个让NLP从业者头疼的问题是机器无法理解语句的真正含义。是的,我指的是自然

2020李宏毅机器学习笔记-ELMO, BERT, GPT
目录 摘要 1. Background 2. ELMO 3. BERT 3.1 Training of BERT 3.1.1 Approach 1:MaskedLM 3.1.2 Approach 2:Next Sentence Prediction(NSP) 3.2 How to use BERT 3.2.1 case 1: classification 3.2.2 case

李宏毅-ELMO, BERT, GPT讲解笔记
背景知识 NLP 中词的表示 one-hot embedding(1-of-N Encoding) 缺点:词汇之间的关联没有考虑,因为不同词之间的距离都是一样的 word classword embedding(word2vec) 缺点:一词多义的问题无法解决 Have you paid that money to the bank yet? They stood on the

2020李宏毅学习笔记——20.ELMO,BERT,GPT
1.机器理解文字演化历史: 1-of-N encoding——word class——word embedding 1-of-N encoding:把每一个词汇表示成一个向量,每一个向量都只有一个地方为1,其他地方为0。但是这么做词汇之间的关联没有考虑,因为不同词之间的距离都是一样的。word class:分类,比如动物类,但是同类之间也有区别,比如哺乳动物和鸟类。word embeddin
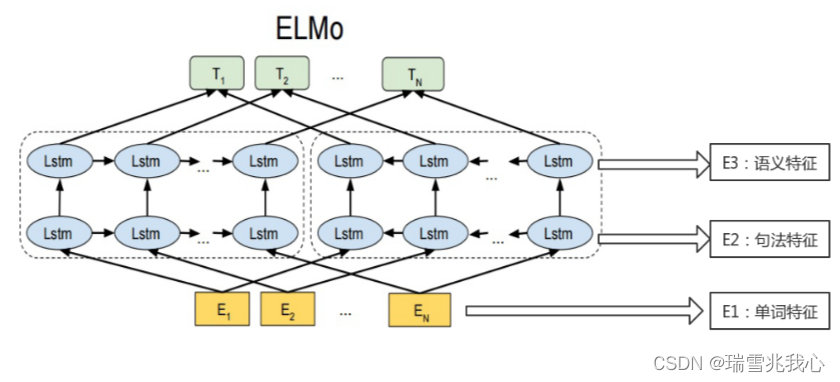
九、ELMo 语言模型
ELMo(Embeddings from Language Models)兼顾了两个问题:一是词语用法在语义和语法上的复杂特点;二是随着语言环境的改变,这些用法也应该随之改变,解决多义词的问题。 ELMo 语言模型原理图: ELMo 模型原理图中虚线的部分是两个双层的 LSTM 网络结构。 左侧的是一个从左到右顺序的正向的双层LSTM 网络,主要用来理解预测词的上文 Context

WDK李宏毅学习笔记第十二周01_ELMO,BERT,GPT
ELMO,BERT,GPT 文章目录 ELMO,BERT,GPT摘要1、Contextualized Word Embedding2、Embeddings from Language Model(ELMO)3、Bidirectional Encoder Representations from Transformers(BERT)3.1 How to use BERT-Case 13.2

elmo、GPT、bert三者之间有什么区别?
elmo、GPT、bert三者之间有什么区别? 特征提取器: elmo采用LSTM进行提取,GPT和bert则采用Transformer进行提取。很多任务表明Transformer特征提取能力强于LSTM,elmo采用1层静态向量+2层LSTM,多层提取能力有限,而GPT和bert中的Transformer可采用多层,并行计算能力强。 单/双向语言模型: GPT采用单向语言模型,elmo和ber

理解 Word Embedding,全面拥抱 ELMO
原文链接:https://www.infoq.cn/article/B8-BMA1BUfuh5MxQ687T 理解 Word Embedding,全面拥抱 ELMO DataFun社区 阅读数:4238 2019 年 6 月 15 日 提到 Word Embedding ,如果你的脑海里面冒出来的是 Word2Vec ,Glove ,Fasttext 等。那我猜你有

CVer从0入门NLP(二)———LSTM、ELMO、Transformer模型
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、收藏⭐、留言📩 CVer从0入门NLP(二)———LSTM、ELMO、Transformer模型 写在前面 Hello,大家好,我是小苏👦🏽👦🏽👦🏽 在上一节为大家介绍了词向量和RNN模型,并基于Pyto
图解NLP:BERT和ELMo
(给机器学习算法与Python学习加星标,提升AI技能) 新智元报道 来源:jalammar.github.io 2018年已经成为自然语言处理机器学习模型的转折点。我们对如何以最能捕捉潜在意义和关系的方式、最准确地表示单词和句子的理解正在迅速发展。 此外,NLP社区开发了一些非常强大的组件,你可以免费下载并在自己的模型和pipeline中使用。 ULM-FiT跟甜饼怪没有任何关系


ELMo - Deep contextualized word representations
Deep contextualized word representations (ELMo) 最近NLP突飞猛进,现有ELMo,后有BERT。 glove以及word2vec的word embedding在nlp任务中都取得了最好的效果, 现在几乎没有一个NLP的任务中不加word embedding. 常用的获取embedding方法都是通过训练language model, 将lang