本文主要是介绍Bert and its family——ELMO,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在写bert and its family之前呢,还是磨蹭了很久,主要是最近一直在喝酒,然后牌桌上的失意,愈发的难过。
在写之前呢,我们先了解一个问题:机器怎么看懂人类文字?换句话说,我们怎么把文字输入到电脑里面去,让电脑能够看懂人类文字。那在bert、ELMO之前,机器是这样去读人类文字的:最早的做法是说每一个人类的词汇就当作是一个不同的符号,每一个符号都用一个独特的编码来表示这个符号。那最常见的做法叫做one-hot embedding。假设说现在世界上只有5个词汇,那我们把这五个词汇都用一个向量来描述它,这个向量里面只有一维是1,其他都是0。

那用这个方法显然是不足的,因为假设对机器来说,每一个词汇都有一个独一无二的编码的话,那也就意味着词汇跟词汇之间是完全没有任何关联的。 举例来说,cat跟dog的关系应该是比较近的,而cat跟bag的关系应该是比较远的,但是这种关系从one-hot embadding上面是无法看出来的。所以后来呢又有了word class的概念。word class是说dog、cat、bird应该是同一类,flower、apple、tree应该算同一类,但这种用word class的方法显然太粗糙了,因为即便是同一类,那dog、cat相较于bird属于哺乳类,从这一点来说还是存在不同的。所以怎么办呢,后来有了更进阶的想法,叫做word embedding。word embedding的意思是说每一个词汇都用一个向量来表示它,这个向量的某一个维度可能就表示了这个词汇的某种意思。那语义相近的词汇它们的向量会比较接近,比如说cat跟dog,语义不同的词汇它们的向量就存在一定的距离,比如说cat跟flower。那word embedding怎么训练呢?比较熟知的就是word2vec方法。

那上面写到的是以前的方法,接下来呢,就进入今天我们要讲的主题。
首先我们知道,同一个词汇可能有不同的意思。举例来说,在下面的图片中,每一个句子都有"bank"这个词汇,这四个“bank”它们是不同的token。但是是同样的type。你可以这样理解,这四个“bank”它们有着不同的含义,但在形式type上都是"bank"。好像有点绕,不过没关系,你肯定明白我在说什么。过去在做word embedding的时候,如果不同的token有着同样的type,那它们的embedding就是一样的。但现在我们知道事实上并不是如此,不同的token就算它们有着同样的type,它们也可能有着不同的embedding。举例来说,下图中的"bank",前两个指的是银行,后两个指河堤。

我们期待机器今天可以做到:每一个word token都有一个embedding。我们之前是每一个type都有一个embedding,现在是每一个 token都有一个embedding。那怎么知道一个token应该有什么样的embedding呢?做法就是看这个token的上下文,上下文越相近的token他们就有着越相近的embedding,那这个技术就叫做Contextualized Word Emdedding。那我们会知道,根据上下文语境的不同,同一个单词bank我们希望能够得到不同的embedding,如果bank的意思是银行,我们期望它们之间的embedding能够相近,同时能够与河堤意思的bank相距较远。基于这个思想,首先有了ELMO。

一、ELMO
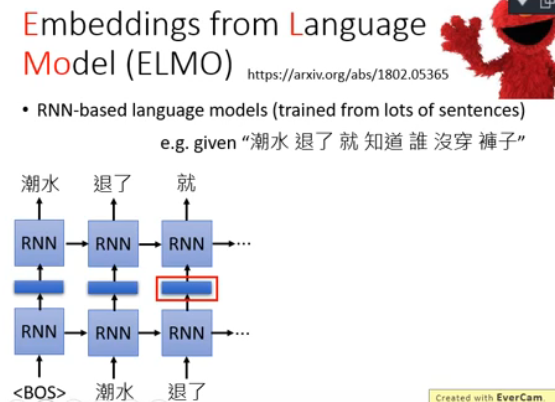
ELMO是Embeddings from Language Model的简称,ELMO就是下图右上角这个红色的怪物,也是《芝麻街》中的一个角色。它是一个RNN-based的language module。那什么是RNN-based的language module呢?你要训练一个RNN-based的language module其实不需要做什么labeling,你只需要收集一大堆一大堆的句子,这些句子不需要做任何的标注。举例来说下图有一行句子:潮水退了就知道谁没穿裤子,那你就告诉你的RNN-based的language module说如果看到一个beginning of sentence的符号,那你就要输出"潮水";那接下来再给你"潮水"这个符号,你就要输出"退了";然后给你"潮水"跟"退了"这俩个符号,你就要输出"就"...就这样子训练下去。RNN-based的language module要做的事情就是去预测句子中的下一个token会是什么。

那怎么预测呢?就是给它很多的句子让它去学怎么预测下一个token。学完以后呢你就有Contextualized Word Emdedding,因为我们可以把RNN的hidden layer拿出来(下图中红色框的部分),它就是现在输入的那个词汇的contextualized word emdedding。假设你把“退了”输进去,RNN会吐出一个embedding给你,那这个embedding呢就是“退了”这个词汇的embedding
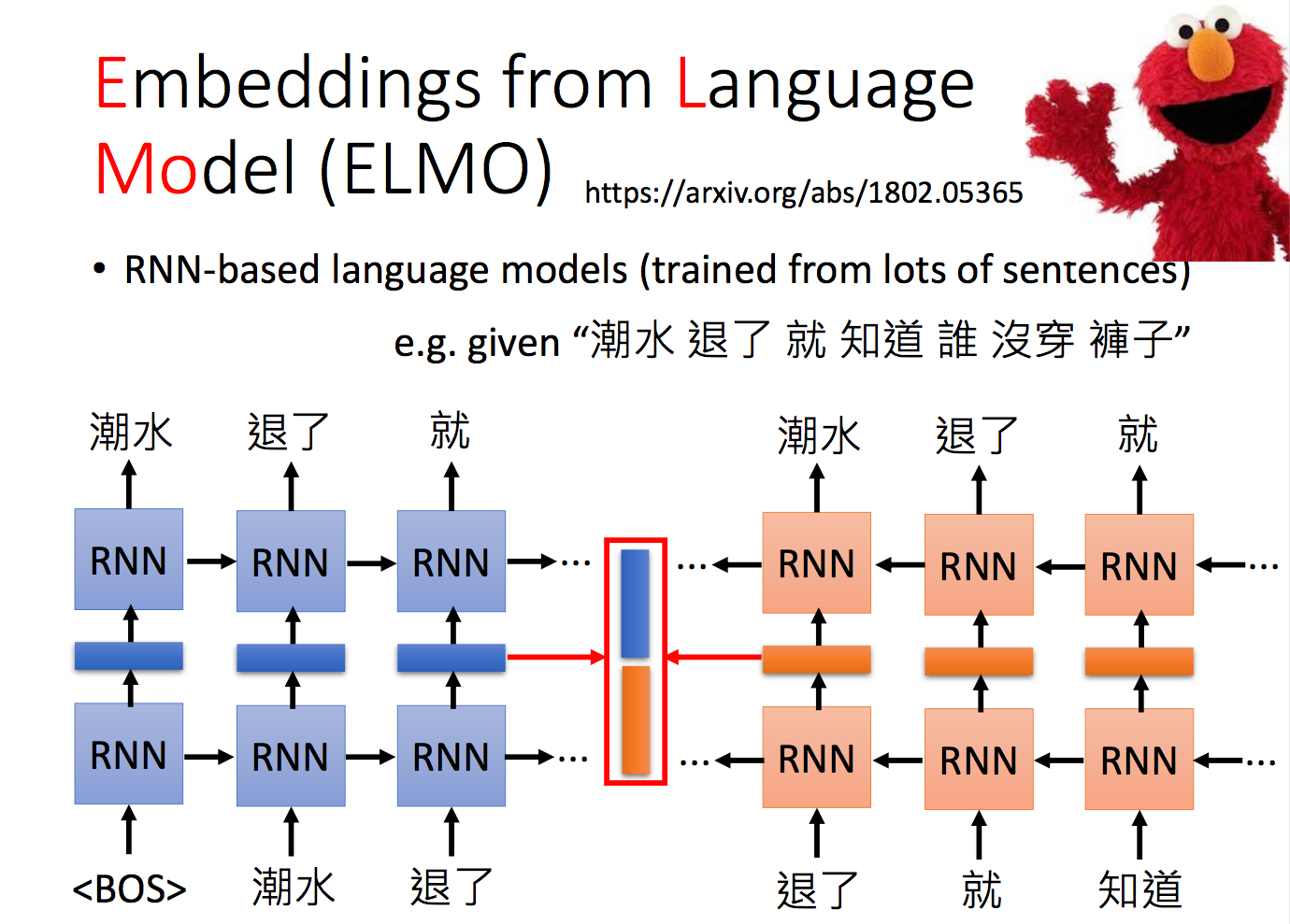
那有一个疑问,为什么吐出来的这个embedding是 contextualized的呢?你可以想象说同样都是“退了”这个词汇,它的上下文如果不同的话,那RNN吐出来的embedding就会不一样。举例来说呢,“高烧退了”或者“臣退了”给RNN,输出的embedding就会不一样。也就是说,RNN在输出这个embedding的时候会参考整个句子。那这个就是ELMO的基本概念。那你可会疑惑说,这样子只考虑了每一个词汇它的前文,没有考虑它的后文。那怎么办呢?你可以再train一个反向的RNN,从句子的尾巴读过来。这个反向RNN要做的事情是:你给它吃“知道”,它就要预测“就”;给它吃“就”,就要预测“退了”;给它吃“退了”,它就要预测“潮水”。所以现在你不止只考虑一个词汇的前文,也考虑了这个词汇的下文。那很明显,如果我要得到“退了”这个词汇的contextualized word emdedding,我就把“退了”这个词汇在正向的RNN embedding和负向的RNN embedding接起来,就最终得到了“退了”这个词的contextualized word emdedding
那可不可以train deep些呢?当然可以,但这会带来什么问题呢?由于更深的RNN有着更多层,每一层都有embedding,那同一个词汇到底应该要用哪一个embedding1呢?

ELMO的做法就是我全都要!

那ELMO是怎么做的呢?从上所述知道,现在每一层都会给我们一个contextualized word emdedding,把这些embedding统统都加起来,一起用,如下图所示。但是怎么把embedding加起来呢?假设现在我们的RNN就只有两层,吐出两个embedding:h1跟h2。那ELMO会做的事情是把第一层吐出来的embedding乘上,把第二层吐出来的embedding乘上
,再加起来得到图中蓝色的embedding,然后再把蓝色的embedding做接下来的Downstream Tasks下游任务。那这个
是怎么来的呢?
是learn出来的。怎么learn出来的呢?在你还有没有使用ELMO抽出embedding之前,你是不知道这些
的值是多少的,
是跟着不同的任务不同的nerve一起学出来。

未完待续...
这篇关于Bert and its family——ELMO的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!