本文主要是介绍机器学习-32-ELMO、BERT、GPT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- ELMO、BERT、GPT
- 背景
- Embeddings from Language Model(ELMO)
- Bidirectional Encoder Representations from Transformers(BERT)
- Training of BERT
- Approach 1:MaskedLM
- Approach 2:Next Sentence Prediction(NSP)
- How to use BERT
- case 1: classification
- case 2: Slot Filling(classification)
- case 3: NLI(自然语言推理)
- case 4: QA(问答)
- Enhanced Representation through Knowledge Integration(ERNIE)
- What does BERT learn(BERT 结果分析)
- Generative Pre-Training(GPT)
- 介绍
- 无监督的 Pretraining
- 有监督fine-tuning
- GPT2
- 例子
ELMO、BERT、GPT
背景
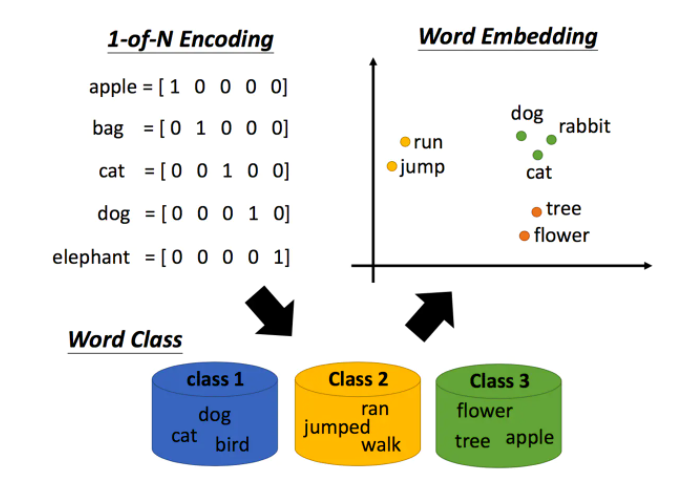
机器是如何理解我们的文字的呢?最早的技术是1-of-N encoding,把每一个词汇表示成一个向量,每一个向量都只有一个地方为1,其他地方为0。但是这么做词汇之间的关联没有考虑,因为不同词之间的距离都是一样的。
所以,接下来有了word class的概念,举例说dog、cat和bird都是动物,它们应该是同类。但是动物之间也是有区别的,如dog和cat是哺乳类动物,和鸟类还是有些区别的。
后来有了更进阶的想法,称作word embedding,我们用一个向量来表示一个单词,相近的词汇距离较近,如cat和dog。那word embedding怎么训练呢?比较熟知的就是word2vec方法。
关于上面几个概念的介绍,可以参看这里👉 机器学习-21-Unsupervised Learning: Word Embedding(无监督学习之词嵌入)
但是呢,同一个词是可能有不同的意思的,如下图中的bank,前两个指银行,后两个指河堤:

尽管有不同的意思,但使用传统的word embedding的方法,相同的单词都会对应同样的embedding。但我们希望针对不同意思的bank,可以给出不同的embedding表示。
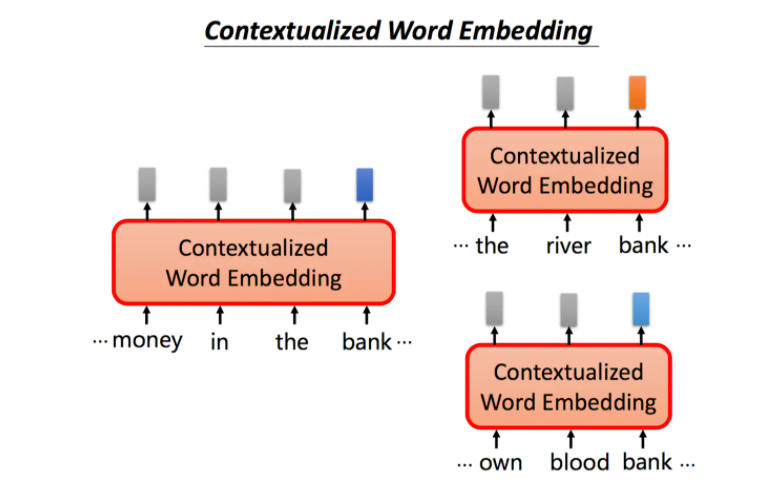
根据上下文语境的不同,同一个单词bank我们希望能够得到不同的embedding,如果bank的意思是银行,我们期望它们之间的embedding能够相近,同时能够与河堤意思的bank相距较远。
基于这个思想,首先有了ELMO。
Embeddings from Language Model(ELMO)
ELMO是Embeddings from Language Model的简称,ELMO是《芝麻街》中的一个角色。它是一个RNN-based的语言模型,其任务是学习句子中的下一个单词或者前一个单词是什么。

它是一个双向的RNN网络,这样每一个单词都对应两个hidden state,进行拼接便可以得到单词的Embedding表示。当同一个单词上下文不一样,得到的embedding就不同。
当然,我们也可以搞更多层:
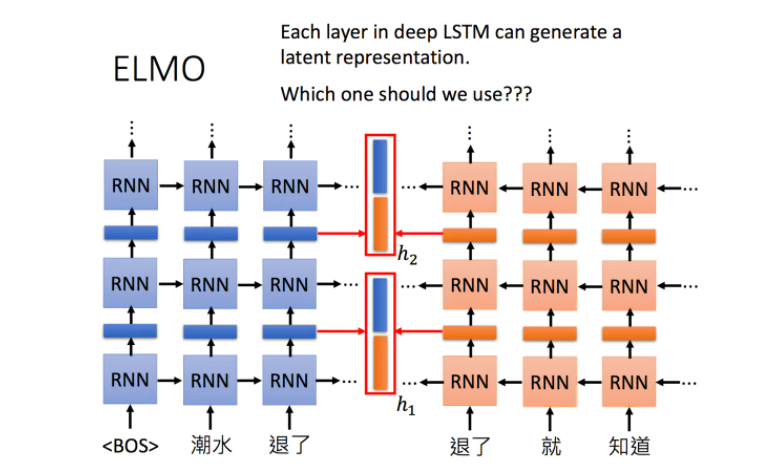
这么多层的RNN,内部每一层输出都是单词的一个表示,那我们取哪一层的输出来代表单词的embedding呢?ELMO的做法就是我全都要:

在ELMO中,一个单词会得到多个embedding,对不同的embedding进行加权求和,可以得到最后的embedding用于下游任务。要说明一个这里的embedding个数,下图中只画了两层RNN输出的hidden state,其实输入到RNN的原始embedding也是需要的,所以你会看到说右下角的图片中,包含了三个embedding。
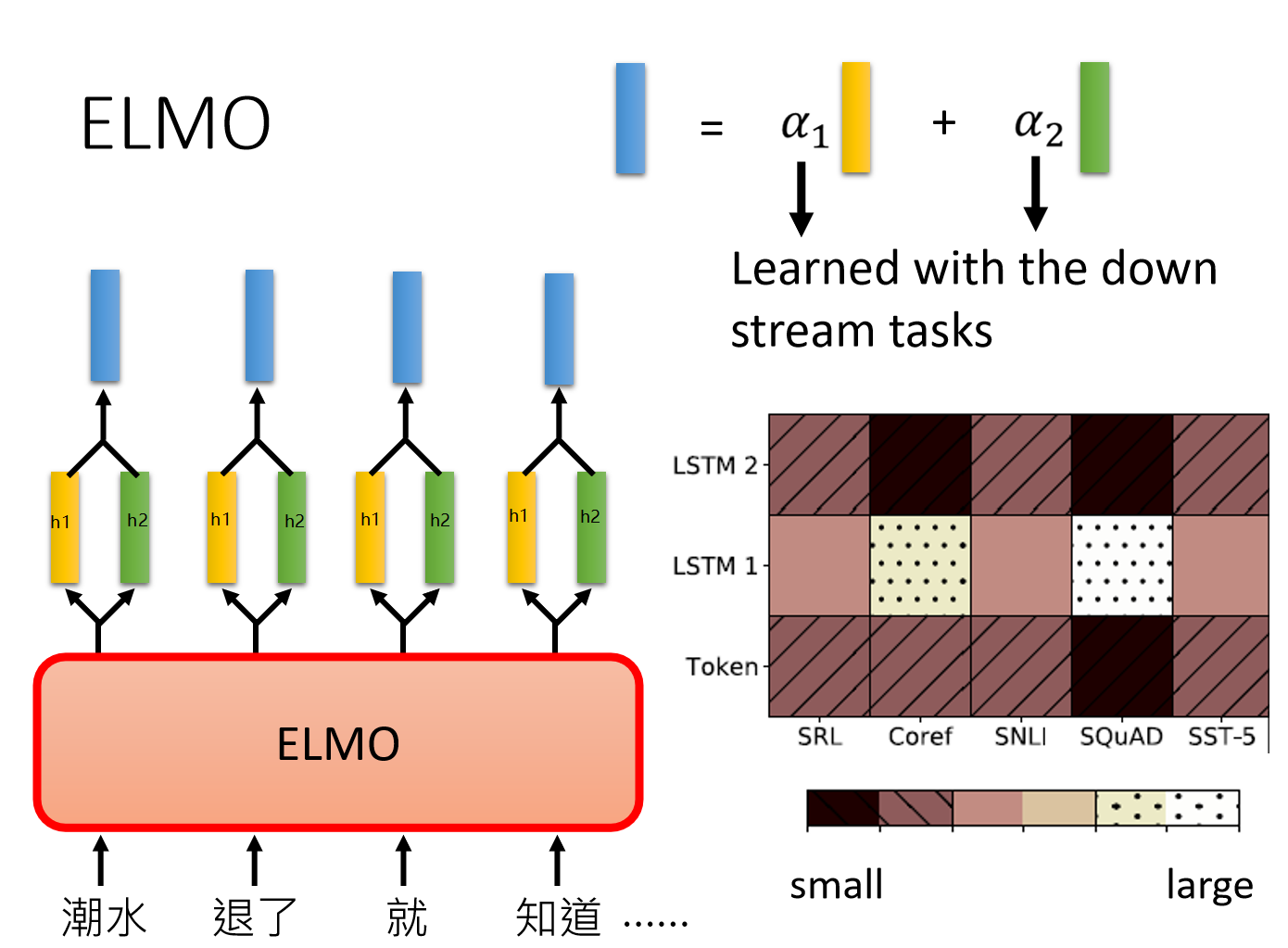
但不同的权重是基于下游任务学习出来的,上图中右下角给了5个不同的任务,其得到的embedding权重各不相同。
Bidirectional Encoder Representations from Transformers(BERT)
Bert是Bidirectional Encoder Representations from Transformers的缩写,中文意思就是来自于转换器的双向编码表示,它也是芝麻街的人物之一。Transformer中的Encoder就是Bert预训练的架构。李宏毅老师特别提示:如果是中文的话,可以把字作为单位,而不是词。
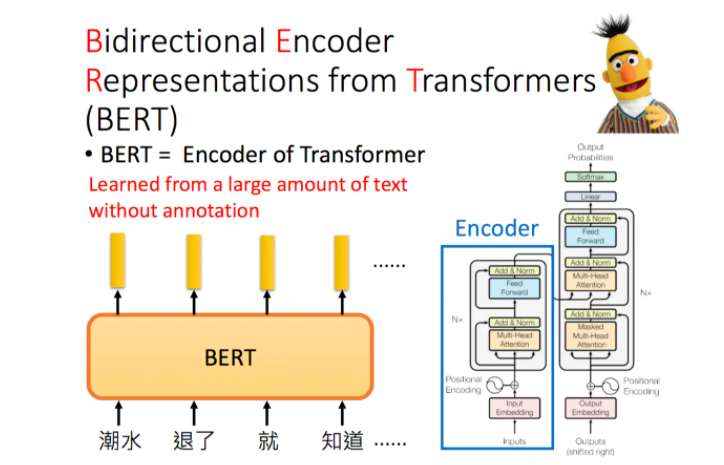
Training of BERT
只是Transformer中的Encoder,那Bert怎么训练呢?文献中给出了两种训练的方法,第一个称为Masked LM,做法是随机把一些单词变为Mask,让模型去猜测盖住的地方是什么单词。假设输入里面的第二个词汇是被盖住的,把其对应的embedding输入到一个多分类模型中,来预测被盖住的单词。
Approach 1:MaskedLM
由于BERT需要通过上下文信息,来预测中心词的信息,同时又不希望模型提前看见中心词的信息,因此提出了一种 Masked Language Model 的预训练方式,即随机从输入预料上 mask 掉一些单词,然后通过的上下文预测该单词,类似于一个完形填空任务。
在预训练任务中,15%的 Word Piece 会被mask,这15%的 Word Piece 中,80%的时候会直接替换为 [Mask] ,10%的时候将其替换为其它任意单词,10%的时候会保留原始Token
- 没有100%mask的原因
- 如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词
- 加入10%随机token的原因
- Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’hairy‘
- 另外编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个token的表示向量
- 另外,每个batchsize只有15%的单词被mask的原因,是因为性能开销的问题,双向编码器比单项编码器训练要更慢

如果两个词填在同一个地方没有违和感那它就有类似的embedding
Approach 2:Next Sentence Prediction(NSP)
仅仅一个MLM任务是不足以让 BERT 解决阅读理解等句子关系判断任务的,因此添加了额外的一个预训练任务,即 Next Sequence Prediction。
具体任务即为一个句子关系判断任务,即判断句子B是否是句子A的下文,如果是的话输出’IsNext‘,否则输出’NotNext‘。
训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
先把两句话连起来,中间加一个[SEP]作为两个句子的分隔符。而在两个句子的开头,放一个[CLS]标志符,将其得到的embedding输入到二分类的模型,输出两个句子是不是接在一起的。

How to use BERT
训练BERT后不但可以获得词向量表示,由于训练BERT一般和下游任务模型一起训练,所以还会获得别的信息,下面看四种使用BERT的方法。
case 1: classification
如果现在的任务是 classification,首先在输入句子的开头加一个代表分类的符号 [CLS],然后将该位置的 output,丢给 Linear Classifier,让其 predict 一个 class 即可。整个过程中 Linear Classifier 的参数是需要从头开始学习的,而 BERT 中的参数微调(fine-tuning)就可以了。
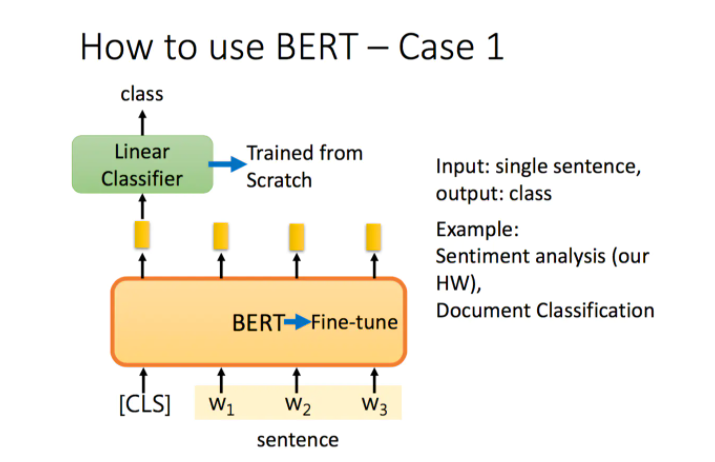
这里李宏毅老师有一点没讲到,就是为什么要用第一个位置,即 [CLS] 位置的 output。这里我看了网上的一些博客,结合自己的理解解释一下。因为 BERT 内部是 Transformer,而 Transformer 内部又是 Self-Attention,所以 [CLS] 的 output 里面肯定含有整句话的完整信息,这是毋庸置疑的。但是 Self-Attention 向量中,自己和自己的值其实是占大头的,现在假设使用 w 1 w_1 w1 的 output 做分类,那么这个 output 中实际上会更加看重 w 1 w_1 w1,而 w 1 w_1 w1 又是一个有实际意义的字或词,这样难免会影响到最终的结果。但是 [CLS] 是没有任何实际意义的,只是一个占位符而已,所以就算 [CLS] 的 output 中自己的值占大头也无所谓。当然你也可以将所有词的 output 进行 concat,作为最终的 output。
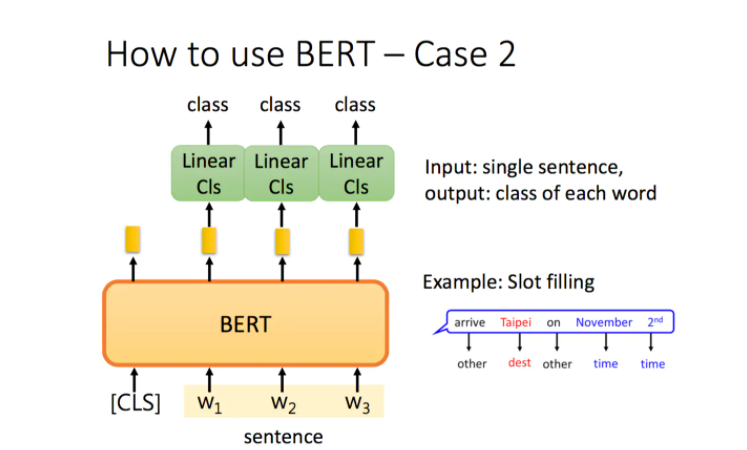
case 2: Slot Filling(classification)
如果现在的任务是 Slot Filling,将句子中各个字对应位置的 output 分别送入不同的 Linear,预测出该字的标签。其实这本质上还是个分类问题,只不过是对每个字都要预测一个类别
case 3: NLI(自然语言推理)
如果现在的任务是 NLI(自然语言推理)。即给定一个前提,然后给出一个假设,模型要判断出这个假设是 正确、错误还是不知道。这本质上是一个三分类的问题,和 Case 1 差不多,对 [CLS] 的 output 进行预测即可

case 4: QA(问答)
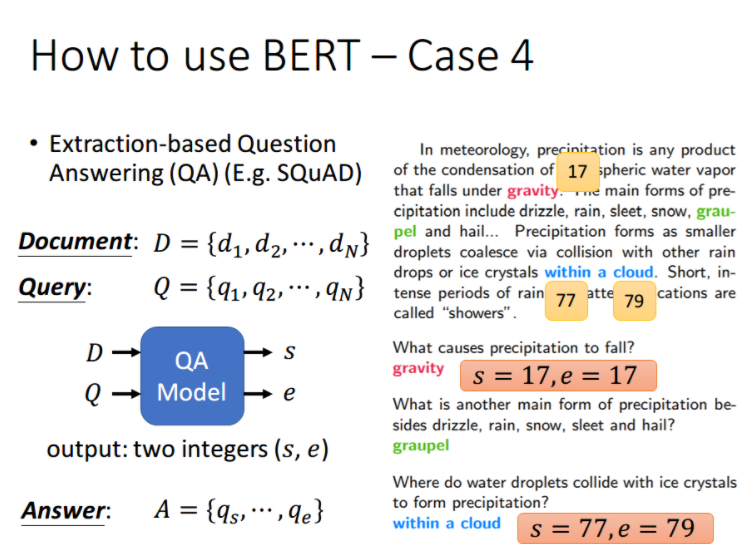
如果现在的任务是 QA(问答),举例来说,如上图,将一篇文章,和一个问题(这里的例子比较简单,答案一定会出现在文章中)送入模型中,模型会输出两个数 s,e,这两个数表示,这个问题的答案,落在文章的第 s 个词到第 e 个词。具体流程我们可以看下面这幅图
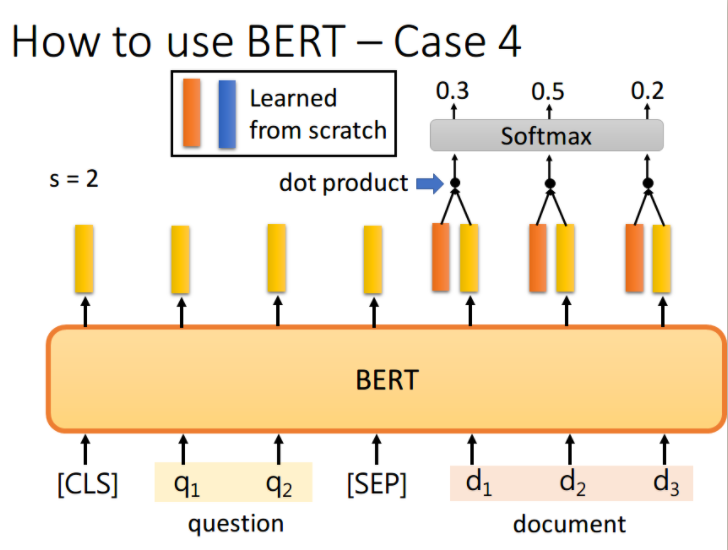
首先将问题和文章通过 [SEP] 分隔,送入 BERT 之后,得到上图中黄色的输出。此时我们还要训练两个 vector,即上图中橙色和蓝色的向量。首先将橙色和所有的黄色向量进行 dot product,然后通过 softmax,看哪一个输出的值最大,例如上图中 d 2 d_2 d2 对应的输出概率最大,那我们就认为 s=2。
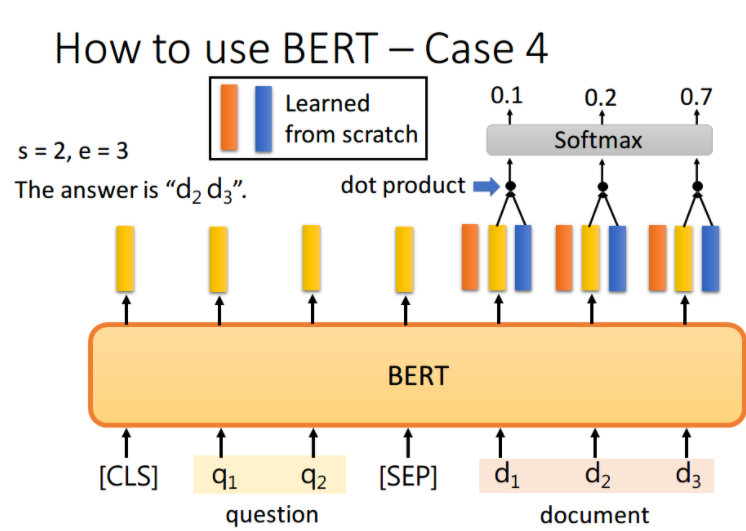
同样地,我们用蓝色的向量和所有黄色向量进行 dot product,最终预测得 d 3 d_3 d3 的概率最大,因此 e=3。最终,答案就是 s=2,e=3
你可能会觉得这里面有个问题,假设最终的输出 start>end 怎么办,那不就矛盾了吗?
正常情况下start <= end,但如果start > end的话,说明是矛盾的case,此题无解。其实在某些训练集里,有的问题就是没有答案的,因此此时的预测搞不好是对的,就是没有答案。
Bert一出来就开始在各项比赛中崭露头角:

Enhanced Representation through Knowledge Integration(ERNIE)
ERNIE也来自芝麻街,而且还和BERT还是好朋友。整个模型专门用于中文。
ERNIE是百度在2019年4月的时候,基于BERT模型,做的进一步的优化,在中文的NLP任务上得到了state-of-the-art的结果。它主要的改进是在mask的机制上做了改进,它的mask不是基本的word piece的mask,而是在pretrainning阶段增加了外部的知识,由三种level的mask组成,分别是basic-level masking(word piece)+ phrase level masking(WWM style) + entity level masking。在这个基础上,借助百度在中文的社区的强大能力,中文的ernie还是用了各种异质(Heterogeneous)的数据集。此外为了适应多轮的贴吧数据,所以ERNIE引入了DLM (Dialogue Language Model) task。
因为用BERT来做的时候,只猜单个字太简单,于是有了ERNIE来猜整个词的。

这里不细说了,以下资料可以参考:
- 👉 ERNIE: Enhanced Representation through Knowledge Integration
- 👉 ERNIE 百度1/2 详解
What does BERT learn(BERT 结果分析)

竖向是一个个NLP任务,然后横着的是通过BERT和对应任务进行联动训练以后,把BERT的24层每个单独抽取出来,进行加权相加(和ELMO一样的操作)得到的结果,可以看到各个NLP任务对应的BERT层有哪些最敏感,例如最上面的POS(词性分析)第11到13层的向量贡献最大。
更加详细的请看以下资料:
- 👉 BERT Rediscovers the Classical NLP Pipeline
- 👉 What do you learn from context? Probing for sentence structure in contextualized word representations
Generative Pre-Training(GPT)
介绍
GPT是Generative Pre-Training 的简称,但GPT不是芝麻街的人物。从名字上就可以看出其是一个生成式的预训练模型,即与ELMo类似,是一个自回归语言模型。与ELMo不同的是,其采用多层Transformer Decoder作为特征抽取器,多项研究也表明,Transformer的特征抽取能力是强于LSTM的。它的思想也很简单,使用单向 Transformer 学习一个语言模型,对句子进行无监督的 Embedding,然后根据具体任务对 Transformer 的参数进行微调。
- 由于GPT仍然是一个生成式的语言模型,因此需要采用Mask Multi-Head Attention的方式来避免预测当前词的时候会看见之后的词,因此将其称为单向Transformer,这也是首次将Transformer应用于预训练模型,预测的方式就是将position-wise的前向反馈网络的输出直接送入分类器进行预测
- 此外整个GPT的训练包括
预训练和微调两个部分,或者说,对于具体的下游任务,其模型结构也必须采用与预训练相同的结构,区别仅在于数据需要进行不同的处理
GPT2 与 GPT 的大致模型框架和预训练目标是一致的,而区别主要在于以下几个方面:
- 其使用了更大的模型
- 使用了数量更大、质量更高、涵盖范围更广的预训练数据
- 采用了无监督多任务联合训练的方式,即对于输入样本,给予一个该样本所属的类别作为引导字符串,这使得该模型能够同时对多项任务进行联合训练,并增强模型的泛化能力

无监督的 Pretraining
我们知道transformer里有encoder层和decoder层,而GPT里主要用的是decoder层,不过做了一点改变,就是去掉了中间的Encoder-Decoder Attention层(因为没有encoder层,所以也就不需要Encoder-Decoder Attention这一层)。也有人说用到的是encoder层,做的改变是将Multi-Head Attention换成了Masked Multi-Head Attention。
那么可能有人会问,这两种说法到底哪个正确呢?其实,这两种说法都对,因为仔细分析一下就会发现这两种说法是一个意思,不就是 Masked Multi-Head Attention + Feed Forward 嘛 如下图所示:

整个过程如上图所示,词向量(token embedding)和位置向量(position embedding)的和作为输入,经过12层的Masked Multi-Head Attention和Feed Forward(当然中间也包括Layer Norm),得到预测的向量和最后一个词的向量,最后一个词的词向量会作为后续fine-tuning的输入。
问题1:无监督训练的终止条件是什么呢?训练到什么时候可以停止呢?像聚类是训练到分类比较稳定的情况下就停止了~
**答:**我们可以通过准确率来评价训练何时停止。训练的时候生成的文本和原文本进行比对,得到准确率,通过准确率是否达到预期值或是准确率是否一直上下波动等来确定是否该停止训练。
有监督fine-tuning
先将大部分的参数通过无监督预训练训练好,然后通过微调确定最后一个参数w的值,以适应不同的任务。利用无监督最后一个词的向量作为微调的输入(个人认为其实可以整句话的词向量作为输入,但是没必要)。
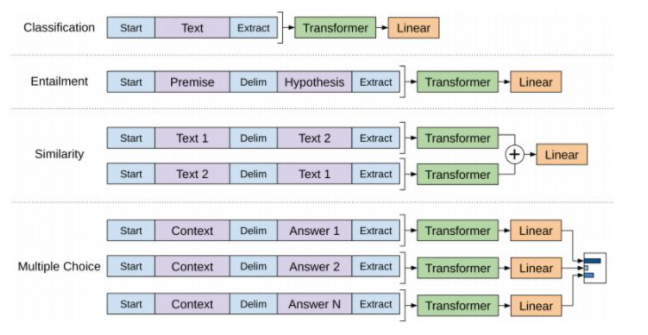
上图展示了对于不同NLP任务的微调过程:
分类任务:输入就是文本,最后一个词的向量直接作为微调的输入,得到最后的分类结果(可以多分类)
推理任务:输入是 先验+分隔符+假设,最后一个词的向量直接作为微调的输入,得到最后的分类结果,即:是否成立
句子相似性:输入是 两个句子相互颠倒,得到的最后一个词的向量再相加,然后进行Linear,得到最后分类结果,即:是否相似
问答任务:输入是上下文和问题放在一起与多个回答,中间也是分隔符分隔,对于每个回答构成的句子的最后一个词的向量作为微调的输入,然后进行Linear,将多个Linear的结果进行softmax,得到最后概率最大的
问题2:对于问答任务,最后多个Linear的结果如何进行softmax?
对于问答任务来说,一个问题对应多个回答,而最后我要取最准确的回答(分值最高)作为结果,我通过对多对问题答案做transformer后,再分别做linear,可以将维度统一,然后对多个linear进行softmax~之前都是对一个linear做softmax,直接取概率值最大的即可,但是现在多个linear如何进行softmax呢?
以上就是GPT的大致描述,采用无监督的预训练和有监督的微调可以实现大部分的NLP任务,而且效果显著,但是还是不如Bert的效果好。不过GPT采用单向transformer可以解决Bert无法解决的生成文本任务。
GPT2
GPT-2依然沿用GPT单向transformer的模式,只不过做了一些改进与改变。那GPT-2相对于GPT有哪些不同呢?看看下面几方面:
-
GPT-2去掉了fine-tuning层:不再针对不同任务分别进行微调建模,而是不定义这个模型应该做什么任务,模型会自动识别出来需要做什么任务。这就好比一个人博览群书,你问他什么类型的问题,他都可以顺手拈来,GPT-2就是这样一个博览群书的模型。
-
增加数据集:既然要博览群书,当然得先有书,所以GPT-2收集了更加广泛、数量更多的语料组成数据集。该数据集包含800万个网页,大小为40G。当然这些数据集是过滤后得到的高质量文本,这样效果才能更好的哦。
-
增加网络参数:GPT-2将Transformer堆叠的层数增加到48层,隐层的维度为1600,参数量更是达到了15亿。15亿什么概念呢,Bert的参数量也才只有3亿哦。当然,这样的参数量也不是说谁都能达到的,这也得取决于money的多少啊。
-
调整transformer:将layer normalization放到每个sub-block之前,并在最后一个Self-attention后再增加一个layer normalization。论文中这块感觉说的模棱两可,如果给个图就好了。不过可以通过代码了解这一细节,下图是我理解如何加layer normalization的示意图,给大家做个参考。
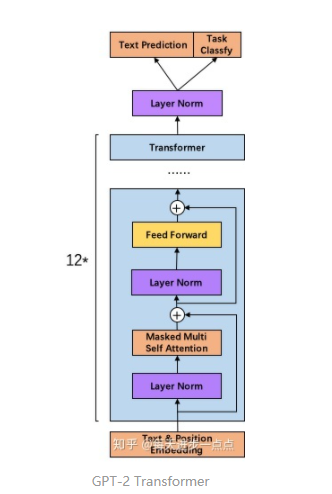
- 其他:GPT-2将词汇表数量增加到50257个;最大的上下文大小 (context size) 从GPT的512提升到了1024 tokens;batchsize增加到512。
GPT-2理论部分基本就是这样,可以看到GPT-2在GPT基础上的创新不大,都是用transformer单向建预研模型,只不过是规模要大很多。因此效果也是真的好,目前的效果甚至超过了Bert。
值得一提的是,GPT-2将fine-tuning去掉后,引入大量的训练文本,效果就非常好,这也说明只要训练文本够大,网络够大,模型是可以自己根据输入内容判断需要做的任务是什么的。
GPT-2的输入是完全的文本,什么提示都不加吗?
当然不是,它也会加入提示词,比如:“TL;DR:”,GPT-2模型就会知道是做摘要工作了**。**输入的格式就是 文本+TL;DR:,然后就等待输出就行了。
例子
输入一个句子中的上一个词,我们希望模型可以得到句子中的下一个词。
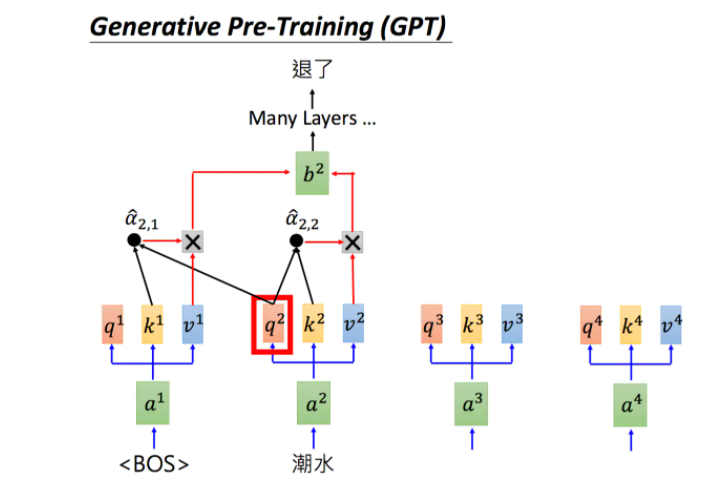

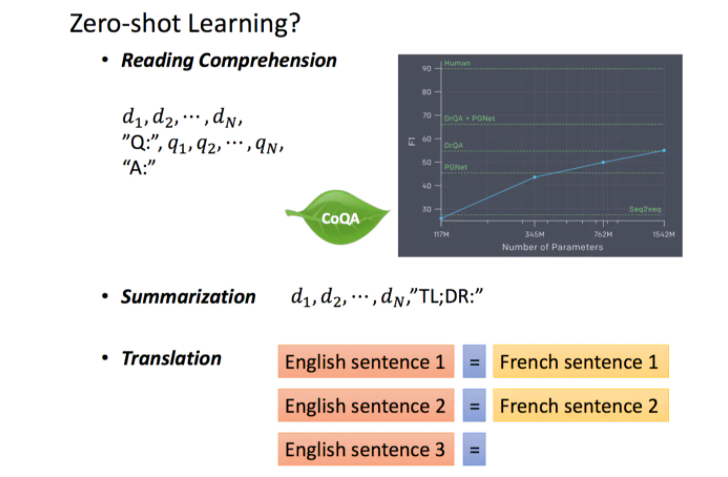
由于GPT-2的模型非常巨大,它在很多任务上都达到了惊人的结果,甚至可以做到zero-shot learning(简单来说就是模型的迁移能力非常好),如阅读理解任务,不需要任何阅读理解的训练集,就可以得到很好的结果。
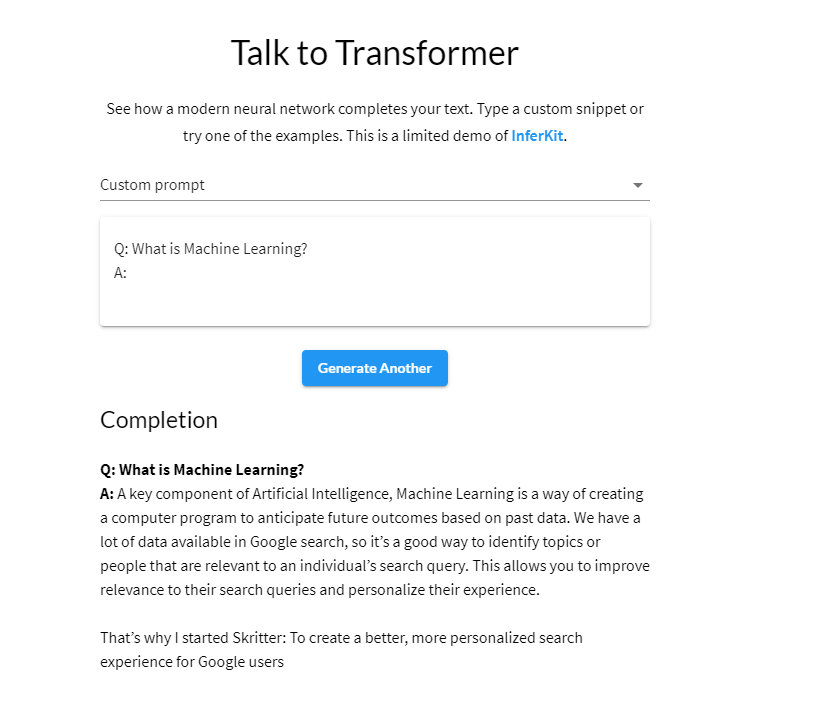
GPT-2可以自己进行写作,写得还是不错的!

推荐一个transformer demo网站👉 Talk to Transformer
下面举几个例子:


这篇关于机器学习-32-ELMO、BERT、GPT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







