本文主要是介绍CVer从0入门NLP(二)———LSTM、ELMO、Transformer模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊专栏推荐:深度学习网络原理与实战
🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
CVer从0入门NLP(二)———LSTM、ELMO、Transformer模型
写在前面
Hello,大家好,我是小苏👦🏽👦🏽👦🏽
在上一节为大家介绍了词向量和RNN模型,并基于Pytorch实现了一个RNN模型,不清楚的可以点击下列链接查看详情:
- CVer从0入门NLP(一)———词向量与RNN模型🍁🍁🍁
今天这节将为大家介绍LSTM、ELMO和Transformer模型,学完今天这些内容,在下一讲我们就来介绍我们的正主了————GPT和BERT。🍄🍄🍄
今天这节的内容都和GPT、BERT息息相关,因此大家耐心的看完喔,对于你后续的理解会非常有帮助。那我话不多说,让我们快快发车叭。🚖🚖🚖
LSTM模型
上文为大家介绍RNN模型,大家掌握的怎么样呢?🥦🥦🥦在RNN的原理介绍部分,我们谈到其存在长距离依赖的问题,为了解决这一问题,LSTM应运而生。那就让我们一起来见识见识LSTM是怎么实现的,如下图所示:

其实LSTM的整个流程是和标准RNN差不多的,区别主要就在于结构A中,大家乍一看是不是觉得还挺复杂的呢,不用担心,我们一点点的来为大家解析。首先第一步我们需要了解图中的关键图标含义,如下:

LSTM的核心就是细胞状态,也就是下图中的 C t C_t Ct。

这个细胞状态可以保持信息在上面流动而保持相对小的改变。LSTM最关键的结构就是精心设计了三个门结构,分别是遗忘门、输入门和输出门,下面分别来介绍:【加上介绍细胞状态】
- 遗忘门
先来上图,遗忘门的输入有 h t − 1 h_{t-1} ht−1和 x t x_t xt,输出一个0~1之间的数字, σ \sigma σ表示sigmoid函数。这个0~1之间的数字 f t f_t ft表示了我们应该保留什么信息,应该忘记什么信息,0表示完全丢弃,1表示完全保留。

- 输入门
同样的,看图说话,输入门的输入同样是 h t − 1 h_{t-1} ht−1和 x t x_t xt。输入门包括两个部分,第一部分是公式 i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i \cdot [h_{t-1},x_t]+b_i) it=σ(Wi⋅[ht−1,xt]+bi)表示的部分,其决定了我们将要更新什么值;另一部分是公式 C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_{t}=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right) C~t=tanh(WC⋅[ht−1,xt]+bC)表示的部分,其表示创建了一个新的候选细胞状态。

- 细胞状态
上文介绍输入门时谈到了创建一个新的候选细胞状态,创建好好,我们就可以更新细胞状态了,如下图所示:

- 输出门
输出门的输入有三个,细胞状态 C t C_t Ct、 h t − 1 h_{t-1} ht−1和 x t x_t xt。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们会把细胞状态通过 tanh 进行处理并将它和 sigmoid 门的输出相乘,最终得到输出 h t h_t ht,此过程如下图所示:

注1:LSTM模型原理就讲到这里了,不知道大家能否听懂。我认为LSTM的核心就是选择性的记住一些事,又选择性的忘记一些事,大家也不用特别纠结内部的结构为什么会是这样,为什么不这样设计。其实LSTM有很多变体,感兴趣的可以去看看,如果你决定你有什么改进的思路,大可以去试试,说不定会达到不错的效果。🍭🍭🍭
注2:本节就不带大家手写LSTM了,看兴趣的可以去看参考连接6。🍄🍄🍄
ELMO模型
在词向量那一小节中,我们介绍了可以由word2vec模型来得到词向量,但是呢,这样得到的词向量会存在一个问题,即无法处理NLP任务中的多义词问题。这是什么意思呢?我们来看下面两句话:
- 我想吃一个
苹果,补充补充维生素。 - 我想买一个
苹果,嘎嘎打游戏上分。
对于上面两句话,都有苹果这个词,我们一眼就能看出这两个苹果不是一种苹果,但是在使用word2vec对苹果这个词进行编码时是区分不开两个苹果的不同含义的。也就是说,对于苹果这个词,我们使用word2vec将其转化成词向量的时候只会产生一种固定的词向量,这个词向量包含了两种苹果的语义。也就是说,如果对于一个新句子,如我爱吃苹果,能够很容易的知道他是苹果(🍎),但是词向量却不会变,依旧包含两种语义。🌼🌼🌼
我想不用说,大家也知道这样不好,因为这样我们就无法区别很多词的含义了。更何况中文博大精深,多义词更是数不胜数,这样无法区分的情况自然是不妙滴。那么我们能不能采取一些措施来应对一下这种情况呢?我给出以下两点,大家看看可不可行:🍟🍟🍟
- 给每个单词分配多个向量,并通过训练的方式学出每个单词对应的不同的向量。
- 先学习每个单词的基础向量,然后当这个单词应用在某一个上下文的时候,我们做动态的调整。
行不行呢,大家觉得行不行呢?我也不卖关子了,其实这两种方式都是可以的。先来说第一种方式,就是训练的前就给单词分配多个向量,这样学习出来的苹果就有多个向量了,一个向量可以表示水果苹果,一个向量可以表示手机苹果。但是呢,这种方式回大大增加计算成本,不同多义词的不同语义之间可能出现数据不平衡的问题,更为重要的是,我们往往也很难事先穷究单词的所有语义,就拿苹果来说,它也会是一手歌的名字(小苹果),也可能会是一个人的名字 ⋯ ⋯ \cdots \cdots ⋯⋯总之,这种方式存在一定的缺陷。🍚🍚🍚
上面说了第一种方法不好,那么现在再来谈谈第二种方法,自然就是不错了哈哈哈。这种方式便是这节我们要讲的ELMO模型的核心思想——事先学习一个单词的词向量(word Embedding),然后在使用这个词向量的时候,根据单词的上下文的语义去适当的调整词向量的表示,这样经过调整后的词向量就能够表达这个词在上下文中的含义了,也就解决了多义词的问题了。
ELMO模型采用了预训练+特征融合的方式,即采用了俩阶段过程,两个阶段如下:
- 第一阶段使用基于LSTM模型设计的结构进行预训练
- 第二阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的词向量作为新特征补充到下游任务中。
下面我们分别来看ELMO的两个阶段,第一阶段主要来分析ELMO的模型,如下:
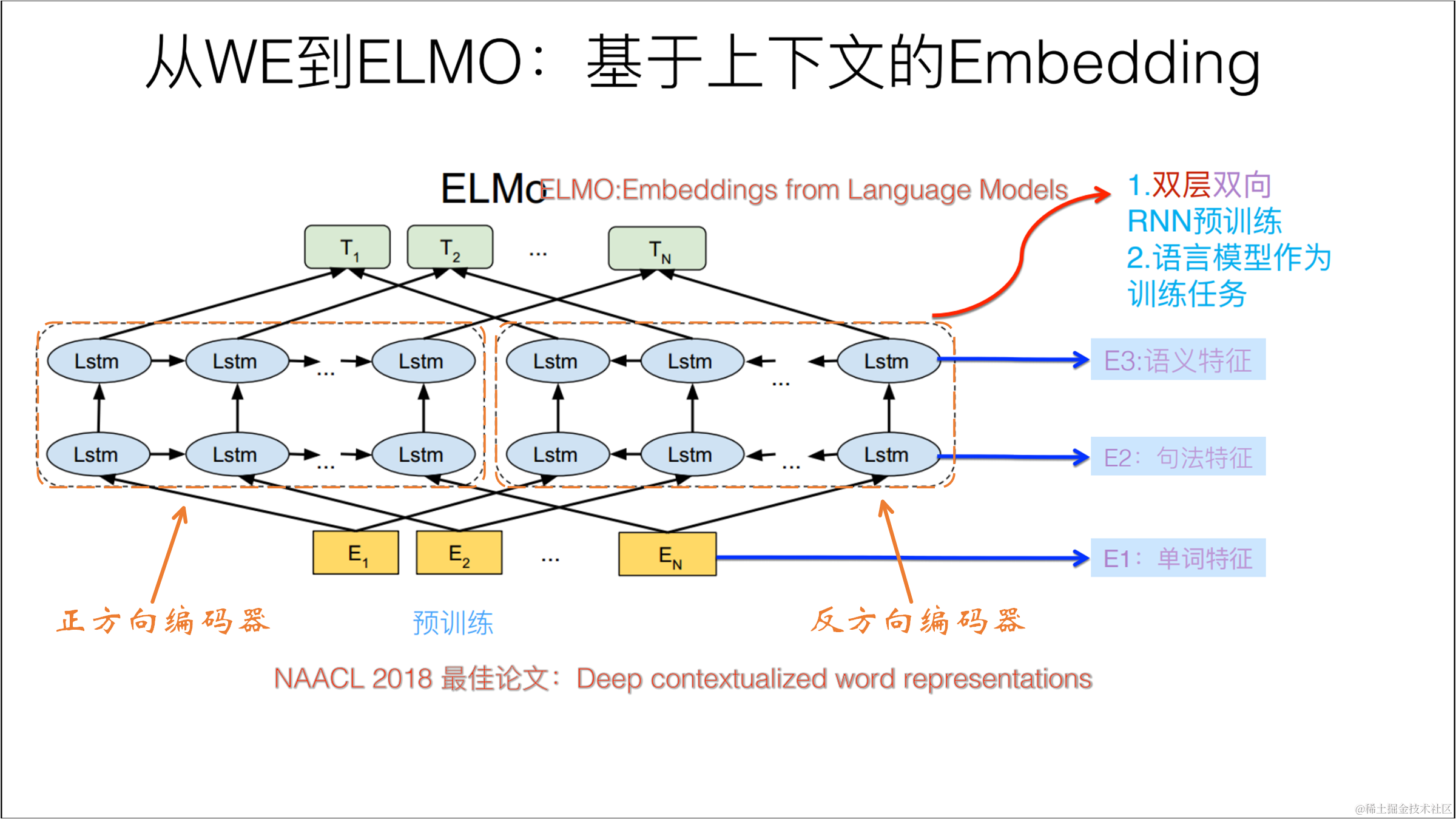
若上图模型训练的目标是根据单词 w i w_i wi 的上下文去正确预测单词 w i w_{i} wi , w i w_i wi 之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。
从图中可以看出,ELMO模型使用的基础结构是LSTM,还是一个两层双向的LSTM**(伪双向)**。
你或许会问,两层的LSTM是什么意思???enmmm,其实就是两个单层的LSTM的叠加,从上图中可以看出,第一层LSTM接受输入序列并产生一个中间的输出序列。然后,第二层LSTM接受第一层的输出作为其输入,并产生最终的输出。这种堆叠LSTM的结构有助于网络更好地捕捉数据中的抽象特征和时序关系,因为第二层LSTM可以进一步建模第一层LSTM的输出。
你或许会问,双向的LSTM是什么???可以看到,上图左端的结构的输入是从左到右的,是正方向编码器;而上图右端的输入是从右向左的,是反方向编码器。这就是双向LSTM。🥗🥗🥗
你或许会问,双向的LSTM有什么用???其实呢,它和单向的LSTM用处是一样的,可以用来预测单词,但是双向的LSTM可以根据单词上下文去预测单词,而普通的LSTM只可以通过上文去预测,多数情况下根据上下文预测单词会更准确些。🥗🥗🥗
你或许会问,根据上下文去预测单词,还预测个嘚啊,这不就是看着答案去做题嘛。🍋🍋🍋确实是这样,如果是纯纯的双向LSTM,确实会存在这种问题,但是ELMO虽然采用了双向结构,却是一个伪双向,不会产生see itself的问题。【后面讲的ERAT就是真正的双向,后面在来介绍其是怎么解决see itself的问题的】🍄🍄🍄
你或许会问,什么是伪双向啊???大家注意到图中正方向编码器和反方向编码器都有一个虚线框框住了嘛,其表示正方向编码器和反方向编码器是独立训练的,只是最后训练好将两个方向的loss进行相加。即无论是正方向编码器还是反方向编码器,一个是从左向右预测,一个是从右往左预测,其实本质都是一个单向的LSTM。总而言之,LSTM的伪双向有以下两个关键点:
- 对于每个方向上的单词来说,因为两个方向彼此独立训练,故在一个方向被encoding的时候始终是看不到它另一侧的单词的,从而避免了see itself的问题
- 而再考虑到句子中有的单词的语义会同时依赖于它左右两侧的某些词,仅仅从单方向做encoding是不能描述清楚的,所以再来一个反向encoding,故称双向
那么其实到这里ELMO的结构就介绍的差不多了,那么如果我们训练好这个网络后,可以得到什么呢?比如你输入一个“我爱吃苹果”这句话,那么ELMO网络会对句子中的每个单词输出三个词向量,分别为:
- 最底层的单词的word Embedding
- 第一层双向LSTM得到的对应单词的Embedding
- 第二层双向LSTM得到的对应单词的Embedding
这三个Embeding往往包含单词不同的信息,这和计算机视觉中卷积很像,越深层的网络越能得到单词的语义信息,如下:

也就是说,ELMo 的第一阶段的预训练过程得到了三个不同的词向量,这些词向量都会应用在后面的下游任务中。🍡🍡🍡
这里,我还是想强调补充一点,就是为什么ELMO可以识别多语义问题?🥱🥱🥱
其实这个答案就是由于ELMO的双向LSTM结构,因为这个结构会使得每个单词考虑了当前单词的上下文信息,从而使得得到的Embedding向量具有了上下文的信息。🌱🌱🌱
这样在我们进行下游任务的时候,会先将输入送到训练好的ELMO网络中,这时ELMO会根据当前的输入的上下文信息得到合适的词向量,然后应用这个词向量进行下游任务。🍀🍀🍀
上面介绍了ELMO的第一阶段即预训练阶段的过程,下面将来介绍如何将预训练好的网络,应用到下游任务当中去,如下图所示🍖🍖🍖
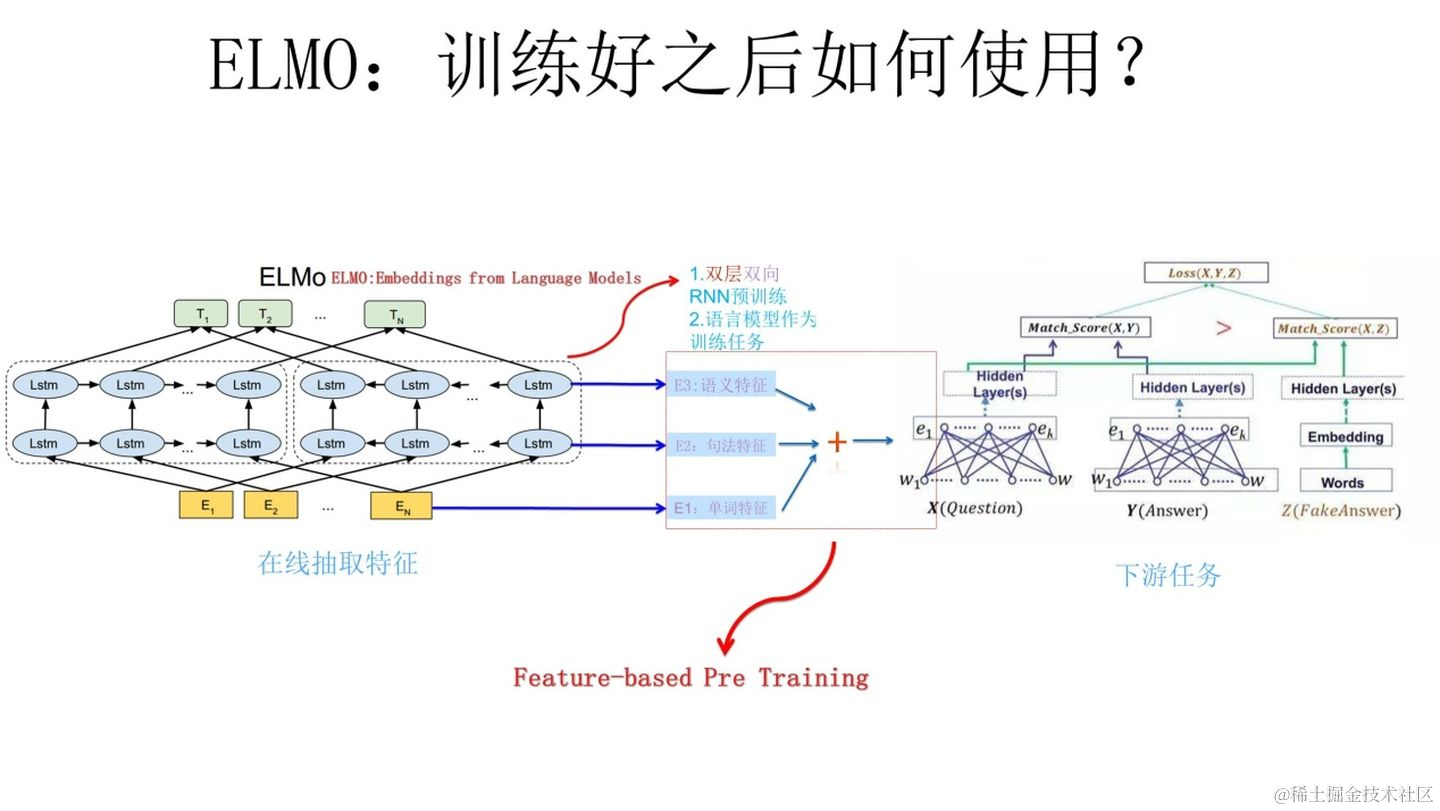
上图很清晰的展示了ELMO预训练摸摸胸如何在下游任务中使用,以下游任务为QA(提问解答)问题为例,对于问句X,有以下几步进行下游任务:
- 将句子X作为训练好的ELMO网络的输入,经过ELMO网络后我们会得到三个Embedding。
- 分别给予三个Embedding一个权重a,根据这个权重将三个Embedding通过加权和的方式整合成一个新的Embedding,这个权重可以学习得来。【这个就非常像CV中的特征金字塔等结构来融合不同层的信息】
- 再将上一步整合后的Embedding作为X句在自己任务的那个网络中对应单词的输入,以此作为新的特征给下游任务使用。
这整个就是ELMO的全部内容了,大家仔细的消化消化,多揣摩揣摩,一定会有收获的。🥗🥗🥗
Transformer模型
前面为大家介绍了RNN、LSTM、ELMO模型,大家学的怎么样了呢?这节要为大家介绍Transformer模型了,我实在是太开心啦!!!
开心???为什么???因为这个我之前写过啦,不用一个字一个字的敲咯。🍉🍉🍉大家可以点击下方链接阅读:
- CV攻城狮入门VIT(vision transformer)之旅——近年超火的Transformer你再不了解就晚了!🍁🍁🍁
关于这篇文章我也想简单说两句,这篇文章从知识的输入,到文章结构的安排,再到作图,下笔直至最后的完成花费了两周时间,参考了很多资料,把一些资料中比较好的观点融入文章之中,用通俗的语言带你了解transformer,希望大家阅读后能够有所收获!
这篇文章也收获了一小笔奖金,一个微果C1的投影仪和500元激励,嘻嘻嘻。🍭🍭🍭
同时这篇文章也收获一些好评和一键三连,所以自己也是非常开心滴。🥂🥂🥂

说了这么多,不是炫耀哈哈哈,也不是凑字数啊,我想说的是我们应该更加注重文章的质量,这样其实不论是读者还是自己都会受益良多,是双赢的结果。🍡🍡🍡当然了,如果大家对Transformer感兴趣的话可以去读读看,还是比较容易理解的,一起加油。🍻🍻🍻
小结
今天的内容就为大家分享到这里啦,大家学会了多少呢。下一节我们将以这两节的内容为基础,为大家介绍GPT和BERT模型,一起加油叭。🌱🌱🌱
参考连接
1、The Illustrated Word2vec
2、理解 LSTM 网络
3、Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
4、Understanding LSTM Networks
5、预训练语言模型的前世今生
6、PyTorch源码教程与前沿人工智能算法复现讲解
如若文章对你有所帮助,那就🛴🛴🛴

这篇关于CVer从0入门NLP(二)———LSTM、ELMO、Transformer模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









