本文主要是介绍基于百科类数据训练的 ELMo 中文预训练模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在NLP世界里,有一支很重要的家族,英文叫做LARK(LAnguage Representations Kit),翻译成中文是语言表示工具箱。目前LARK家族最新最重要的三种算法,分别是ELMo,BERT和ERNIE。
你一定不知道,这三个普通的名字,竟然包含着一个有趣的秘密。
真相,即将揭开!

我们先从算法模型的名字寻找一些蛛丝马迹
第一位,ELMo:
来自英文Embedding from Language Models 的缩写,来自论文名为Deep contextualized word representation
第二位,BERT:
来自英文Bidirectional Encoder Representations from Transformers的缩写,来自论文名为Pre-training of Deep Bidirectional Transformers for LanguageUnderstanding
第三位,ERNIE:
来自英文Enhanced Representation through kNowledge IntEgration) 的缩,来自论文名为Enhanced Representation through Knowledge Integration
看完了,是不是,还是一头雾水,哪里有什么秘密?

不卖关子了,直接上图!

What??
再回头看看,你还记得那三个算法的名字么?
ELMo,BERT,ERNIE
竟然都是美国经典动画片,《Sesame Street(芝麻街)》里面的卡通人物!!!
好吧,如果你说,没看过这个动画片,没感觉啊。那我举个例子,如果把《芝麻街》类比成中文《舒克和贝塔》。那么,第一篇论文把模型取做“舒克”,第二篇很有爱的就叫做“贝塔”,第三篇就硬把模型叫做“皮皮鲁”,也许不久的下一个模型就命名为“鲁西西”啦。
谁说科学家们很无聊,是不是也很童趣?
好了,扯远了,今天我们先给大家介绍LARK家族的ELMo! 提出它的论文获得2018年NAACL最佳paper,它在NLP领域可是有着响当当的名头,让我们来认识它!
ELMo模型简介
ELMo(Embeddings from Language Models) 是重要的通用语义表示模型之一,以双向 LSTM 为网路基本组件,以 Language Model 为训练目标,通过预训练得到通用的语义表示,将通用的语义表示作为 Feature 迁移到下游 NLP 任务中,会显著提升下游任务的模型性能。
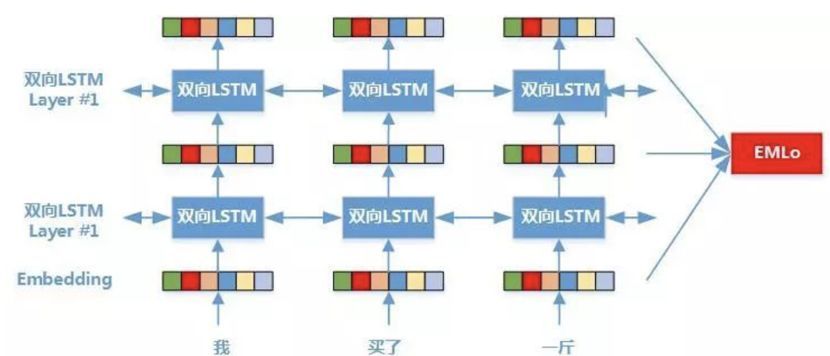
ELMo模型核心是一个双层双向的LSTM网络,与传统的word2vec算法中词向量一成不变相比,ELMo会根据上下文改变语义embedding。
一个简单的例子就是 “苹果”的词向量:
句子1:“我 买了 1斤 苹果”
句子2:“我 新 买了 1个 苹果 X”
在word2vec算法中,“苹果”的词向量固定,无法区分这两句话的区别,而ELMo可以解决语言中的二义性问题,可以带来性能的显著提升。
ELMo项目的飞桨(PaddlePaddle)实现
为了方便广大的开发者,飞桨(PaddlePaddle) 完成了ELMo的开源实现(依赖于 Paddle Fluid 1.4),发布要点如下。
注意啦,下面划重点!!!



接下来,我们看看怎么可以快速把ELMo用到我们的项目中来吧!
ELMo训练过程介绍
(1)数据预处理
将文档按照句号、问号、感叹以及内容分词预处理。预处理后的数据文件,每行为一个分词后的句子。给出了训练数据 data/train 和测试数据 data/dev的数据示例如下:
本 书 介绍 了 中国 经济 发展 的 内外 平衡问题 、 亚洲 金融 危机 十 周年 回顾 与 反思 、 实践 中 的 城乡 统筹 发展 、 未来 十 年 中国 需要 研究 的 重大 课题 、 科学 发展 与新型 工业 化 等 方面 。
吴 敬 琏 曾经 提出 中国 股市 “ 赌场 论 ” , 主张 维护 市场 规则 , 保护 草根 阶层 生计, 被 誉 为 “ 中国 经济 学界 良心 ” , 是 媒体 和公众 眼中 的 学术 明星
(2)模型训练
利用提供的示例训练数据和测试数据,进行单机多卡预训练。在开始预训练之前,需要把 CUDA、cuDNN、NCCL2 等动态库路径加入到环境变量 LD_LIBRARY_PATH 之中,然后执行run.sh即可开始单机多卡预训练,run.sh文件内容如下:
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
python train.py \
--train_path='data/train/sentence_file_*' \
--test_path='data/dev/sentence_file_*' \
--vocab_path data/vocabulary_min5k.txt \
--learning_rate 0.2 \
--use_gpu True \
--all_train_tokens 35479 \
--local True $@
其中,all_train_tokens为train和dev统计出来的tokens总量,训练过程中,默认每个epoch后,将模型参数写入到 checkpoints 路径下,可以用于迁移到下游NLP任务。
(3)ELMo模型迁移
以 LAC 任务为示例, 将 ELMo 预训练模型的语义表示迁移到 LAC 任务的主要步骤如下:
#step1: 在已经搭建好的LAC 网络结构之后,加载 ELMo 预训练模型参数:
from bilm import
init_pretraining_params
init_pretraining_params(exe,args.pretrain_elmo_model_path, fluid.default_main_program())
#step2: 基于ELMo 字典 将输入数据转化为 word_ids,利用 elmo_encoder接口获取 ELMo embedding:
from bilm import elmo_encoder
elmo_embedding = elmo_encoder(word_ids)
#step3: ELMoembedding与 LAC 原有 word_embedding 拼接得到最终的 embedding:
-
word_embedding=fluid.layers.concat(input=[elmo_embedding, word_embedding], axis=1)
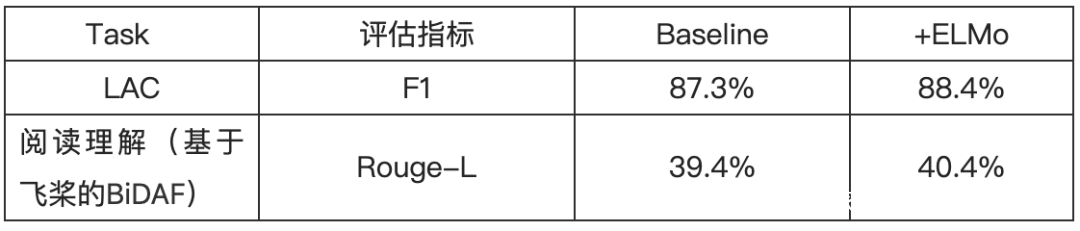
好的,到这里,模型的迁移就完成了,再来回顾一下加入ELMo后对性能的提升,心动不如行动,赶紧用起来吧!
ERNIE模型简介
学习完了ELMo,我们再来了解一下LARK家族的学习成绩最好的重磅成员ERNIE,在多项NLP中文任务上表现非凡。
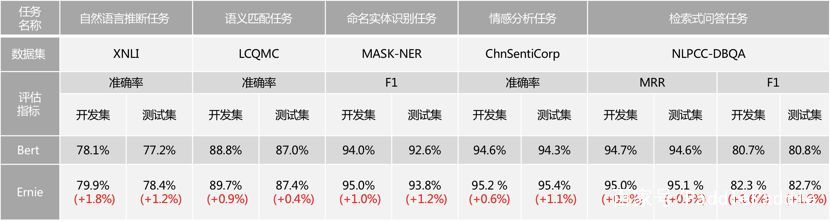
ERNIE通过建模海量数据中的实体概念等先验语义知识,学习真实世界的语义关系。具体来说,ERNIE 模型通过对词、实体等语义单元的掩码,使得模型学习完整概念的语义表示。相较于BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。
ERNIE在多个公开的中文数据集上进行了效果验证,包括语言推断、语义相似度、命名实体识别、情感分析、问答匹配等自然语言处理各类任务上,均超越了语义表示模型 BERT 的效果。
更多详细内容请点击文末阅读原文或参见:
https://github.com/PaddlePaddle/LARK
这篇关于基于百科类数据训练的 ELMo 中文预训练模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






