本文主要是介绍2020李宏毅学习笔记——20.ELMO,BERT,GPT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.机器理解文字演化历史:
1-of-N encoding——word class——word embedding

- 1-of-N encoding:把每一个词汇表示成一个向量,每一个向量都只有一个地方为1,其他地方为0。但是这么做词汇之间的关联没有考虑,因为不同词之间的距离都是一样的。
- word class:分类,比如动物类,但是同类之间也有区别,比如哺乳动物和鸟类。
- word embedding:我们用一个向量来表示一个单词,相近的词汇距离较近,如cat和dog。那word embedding怎么训练呢?比较熟知的就是word2vec方法。
word embedding局限性:
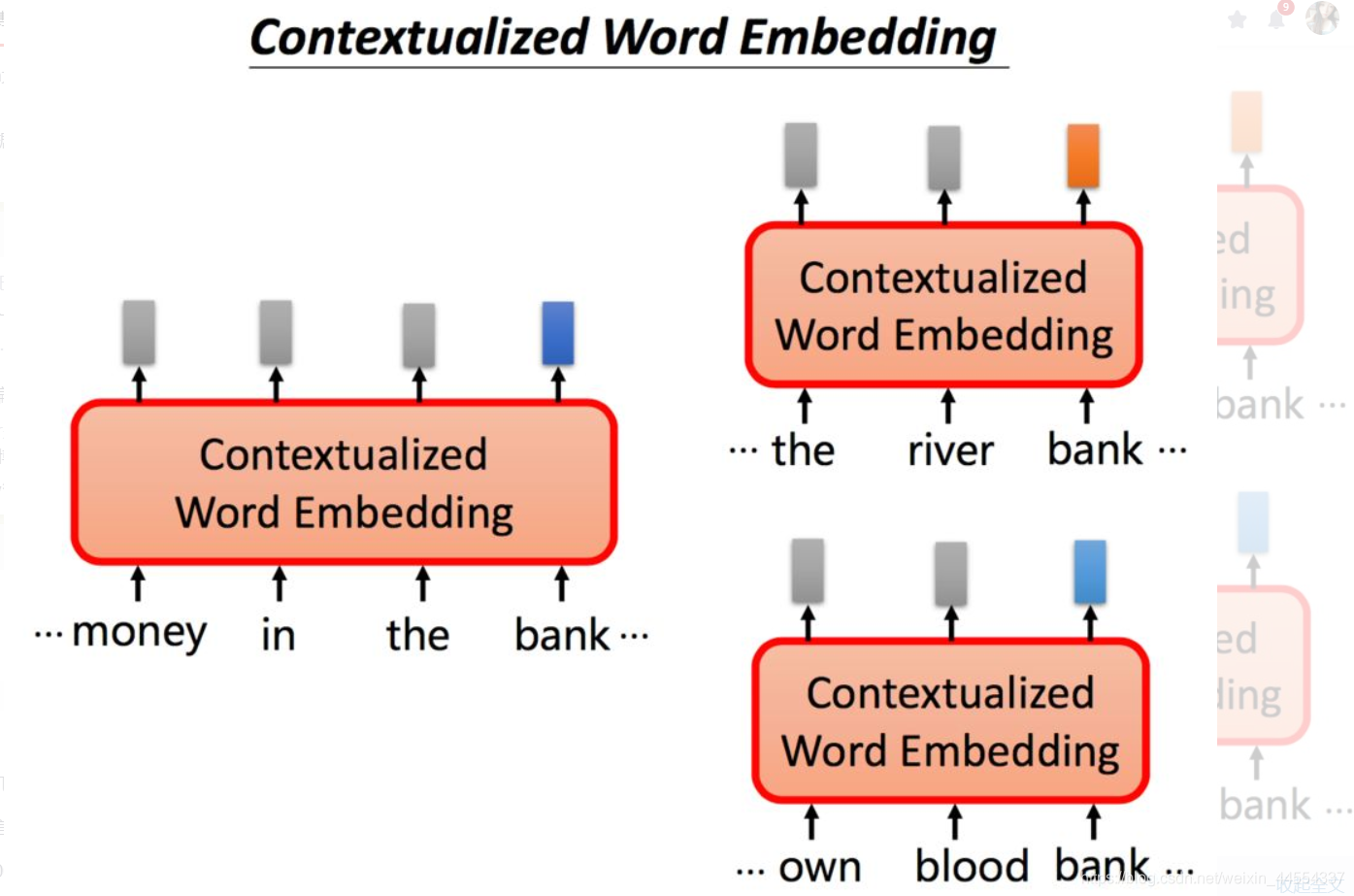
一词多义怎么办?如bank的多意

Q:那我们能不能标记一词多义的形式呢?
A:不太现实,首先是词很多,而且“bank”也不止有2种意思,下面这句话:The hospital has its own blood bank.这里“bank”有人认为是第三种意思“库”,也有人认为是“银行”的延伸意思,所以也难界定到底有几种意思。
而且:使用传统的word embedding的方法,相同的单词都会对应同样的embedding
如果我们希望针对不同意思的bank,可以给出不同的embedding表示。根据上下文语境的不同,同一个单词bank我们希望能够得到不同的embedding,如果bank的意思是银行,我们期望它们之间的embedding能够相近,同时能够与河堤意思的bank相距较远。
于是谁诞生?ELMO
2.ELMO
2.1背景
ELMO模型(Embeddings from Language Model ):可以实现Contextualized Word Embedding技术。
ELMO是《芝麻街》中的一个角色。它是一个RNN-based的语言模型,其任务是学习句子中的下一个单词或者前一个单词是什么。
例如现在有一句话: “潮水 退了 就 知道 誰 沒穿 褲子”,需要找到“退了”这个词的编码,就可以根据这个词的上下文来获取。

2.2简介
它是一个双向的RNN网络,这样每一个单词都对应两个hidden state,进行拼接便可以得到单词的Embedding表示。当同一个单词上下文不一样,得到的embedding就不同。
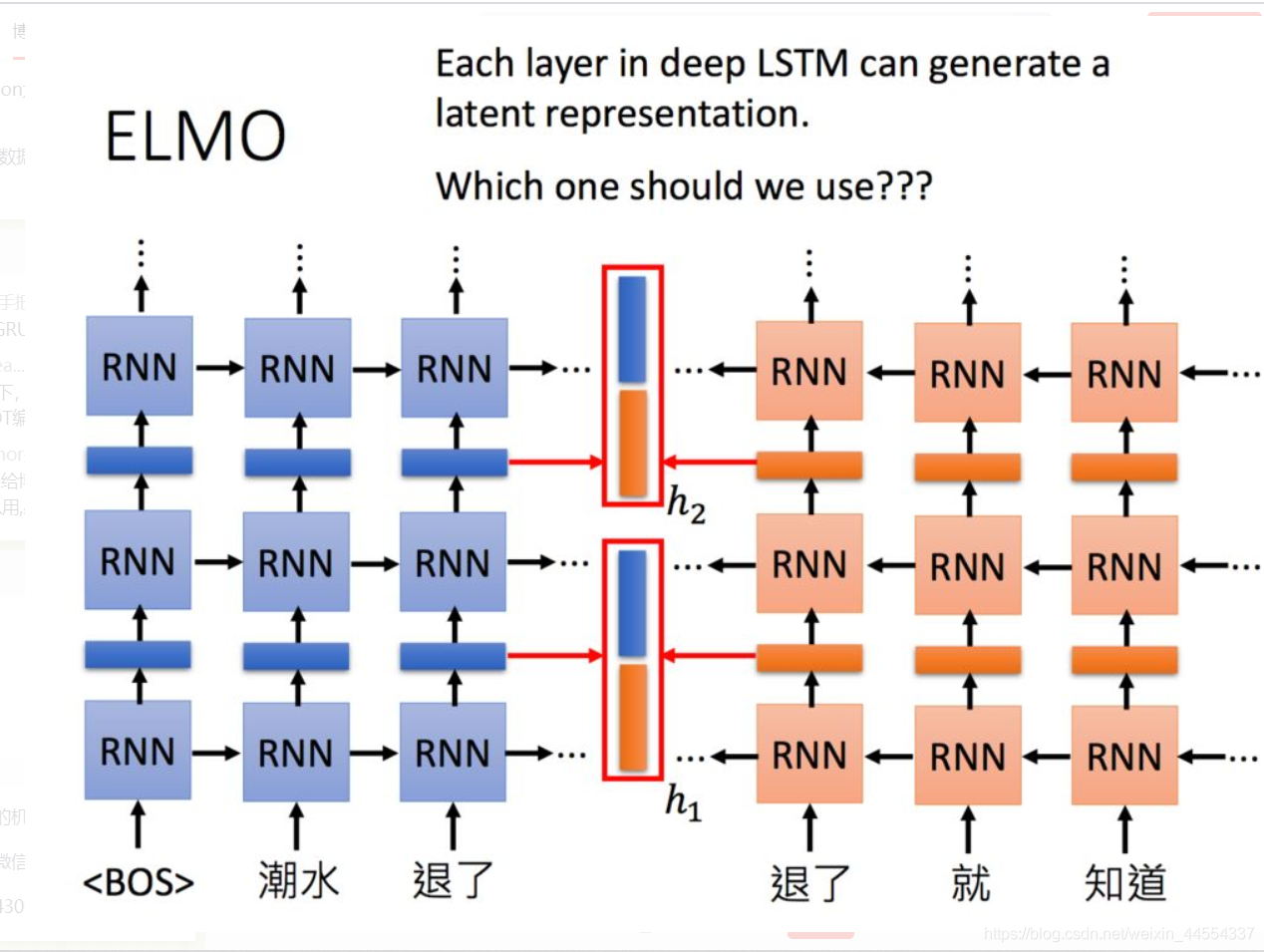
“退了”这个词经过RNN层的输出之后得到前文对它的编码,经过反向的RNN层的输出作为下文对它的编码,之后进行连接得到“退了”这个词的整个编码。
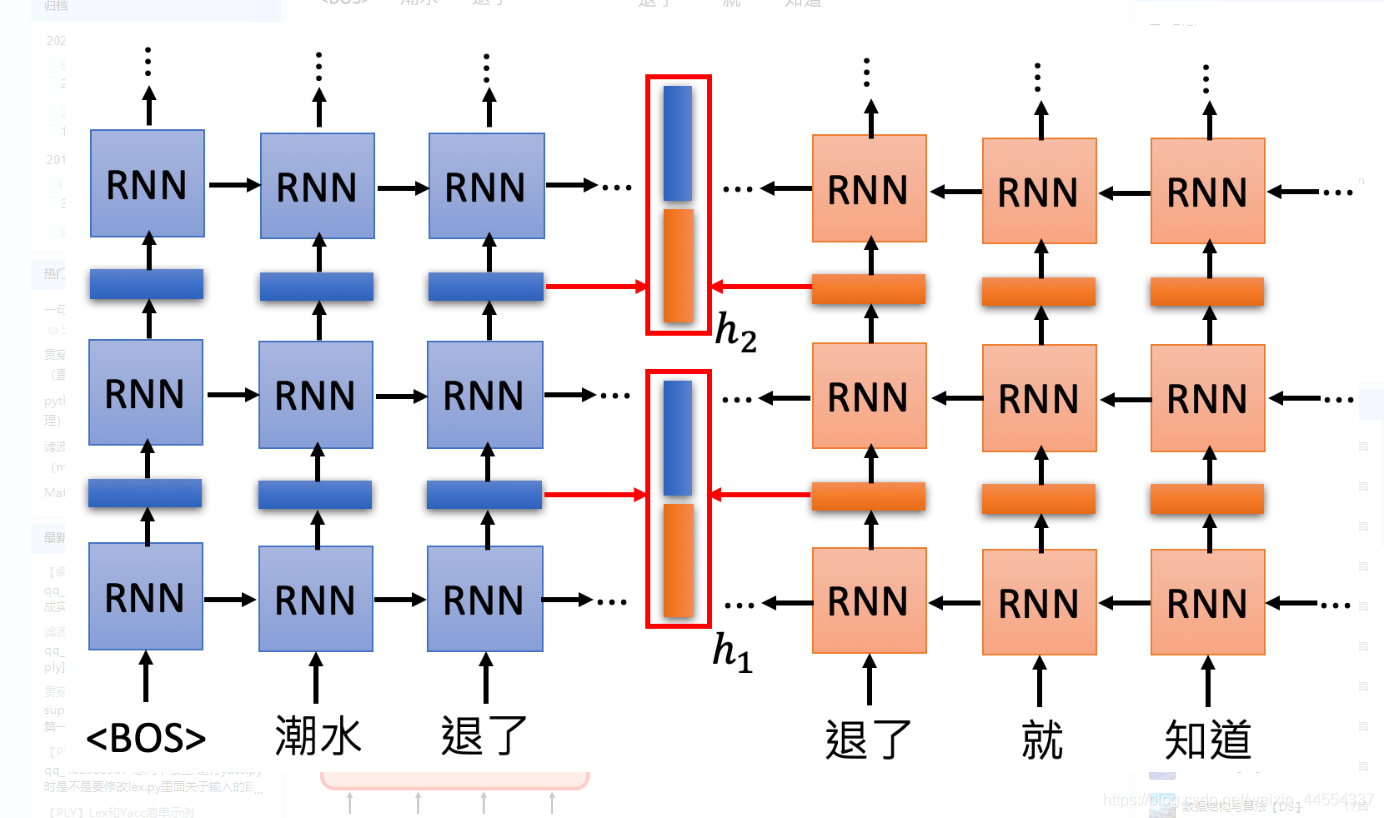
有一个问题:
这么多层的RNN,内部每一层输出都是单词的一个表示,那我们取哪一层的输出来代表单词的embedding呢?ELMO的做法就是我全都要:
在ELMO中,一个单词会得到多个embedding,对不同的embedding进行加权求和,可以得到最后的embedding用于下游任务。要说明一个这里的embedding个数,下图中只画了两层RNN输出的hidden state,其实输入到RNN的原始embedding也是需要的,所以你会看到说右下角的图片中,包含了三个embedding。但不同的权重是基于下游任务学习出来的,
每一层都会给出一个Embedding(上图展示了两层),ELMO把这些加起来生成一个Embedding(蓝色向量),加的时候需要的参数根据模型学出来。

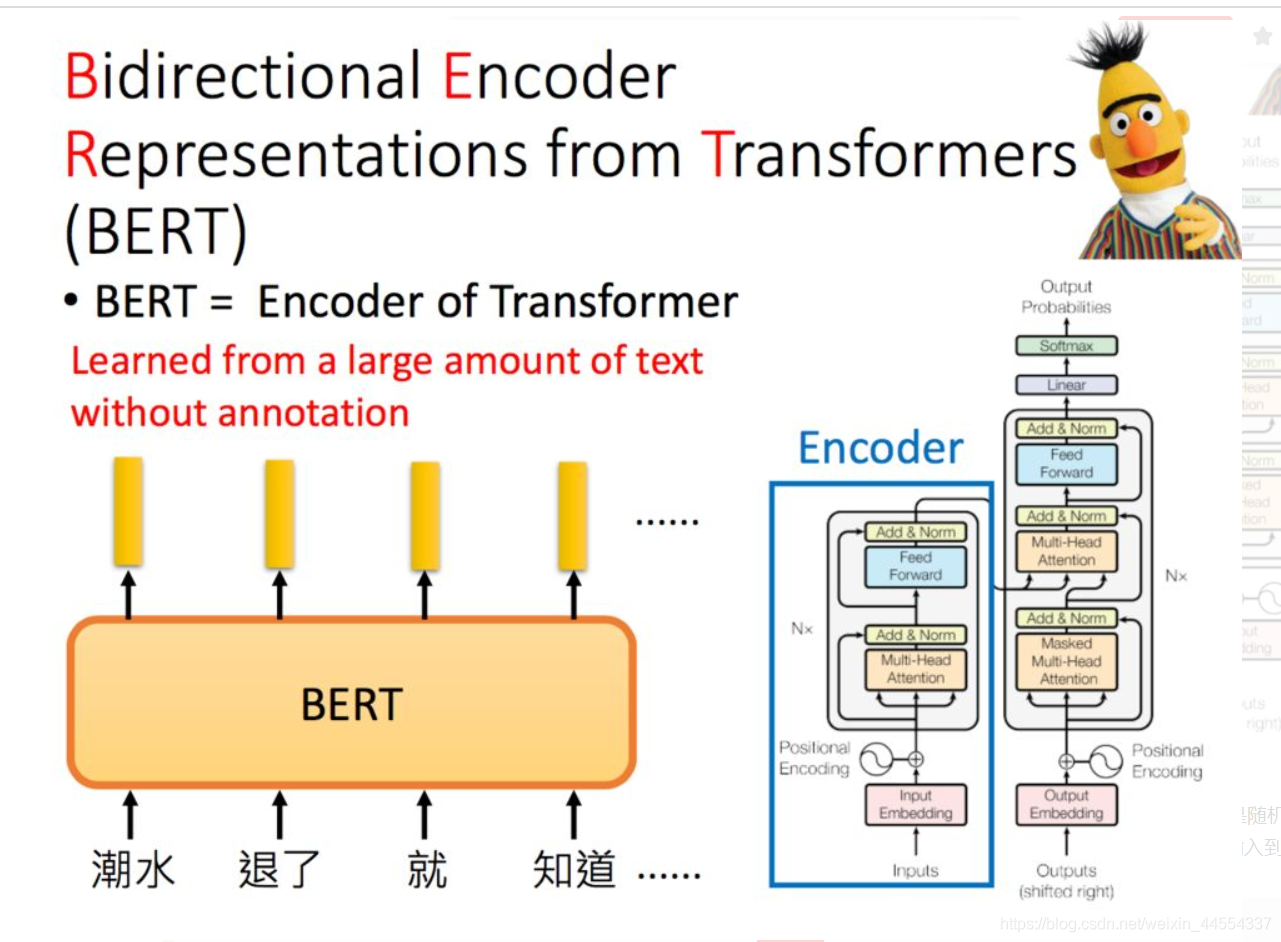
3.BERT:来自变压器的双向编码器表示
3.1:背景由来
Bert是Bidirectional Encoder Representations from Transformers的缩写,它也是芝麻街的人物之一。Transformer中的Encoder就是Bert预训练的架构。李宏毅老师特别提示:如果是中文的话,可以把字作为单位,而不是词。
其实就是输入一个句子进去,给你一串embedding,对应到每一个word
由于中文字太多,one-hot太大,所以如果用26个字母呢,那就不会 太大。,字母同样可以表示中文。
3.2如何训练BERT?
训练BERT的方法分为2种:
方法1和方法2的方法在BERT中是同时使用的。
1、Masked LM做法是随机把一些单词的token变为Mask:挖空,让模型去猜测盖住的地方是什么单词。假设输入里面的第二个词汇是被盖住的,把其对应的embedding输入到一个多分类模型中,来预测被盖住的单词。
2、Next Sentence Prediction
预测下一个句子,这里,先把两句话连起来,中间加一个[SEP]作为两个句子的分隔符。而在两个句子的开头,放一个[CLS]标志符,将其得到的embedding输入到二分类的模型,输出两个句子是不是接在一起的。
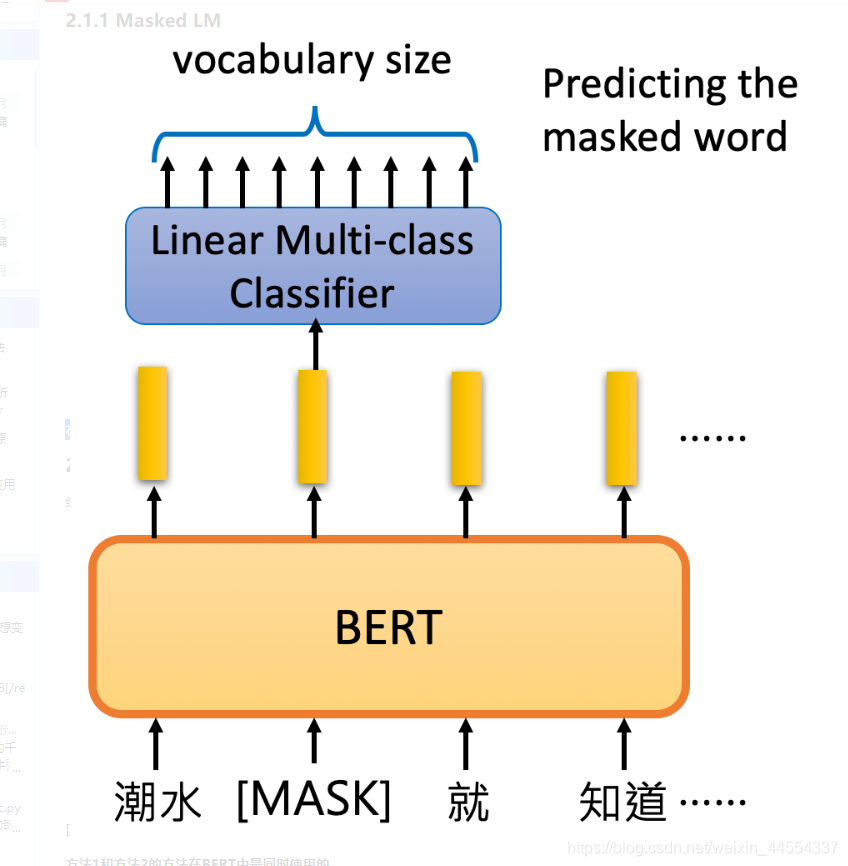
3.21Masked LM
在这种方法里面,会以一定的概率将一个词用[MASK]替代,把盖住的地方丢进一个classifier来预测是哪一个词汇,然后往里面填充相应的编码,如果填进去并没有违和感,则表示预测准确。
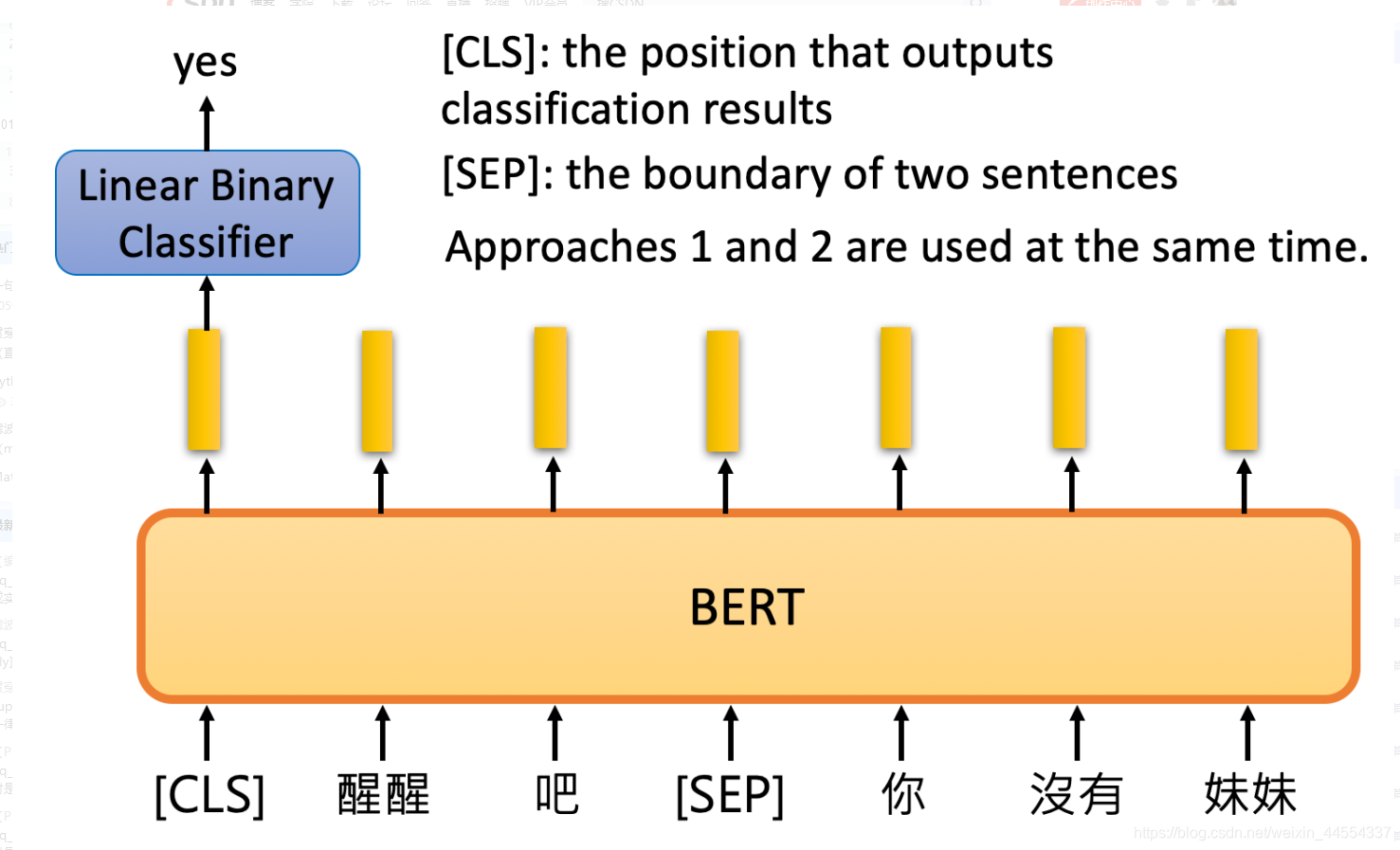
3.22Next Sentence Prediction
给出两个句子,BERT判断两个句子是否是接在一起的。
[CLS]放在句子开头,输出的embedding,丢进classifier,来看到看是否要接在一起,bert的内部不是rnn,是self attention,:特点,放在开头和结尾,影响不大,所以开头和结尾没有区别,用于存储判断的结果。
3.3 如何利用BERT?:得到一个新的整体的。
BERT论文中给出的例子是将BERT和接下来的任务一起训练的.
在ELMO中,训练好的embedding是不会参与下游训练的,下游任务会训练不同embedding对应的权重,但在Bert中,Bert是和下游任务一起训练的:
如果是分类任务,在句子前面加一个标志,将其经过Bert得到的embedding输出到二分类模型中,得到分类结果。二分类模型从头开始学,而Bert在预训练的基础上进行微调(fine-tuning)。
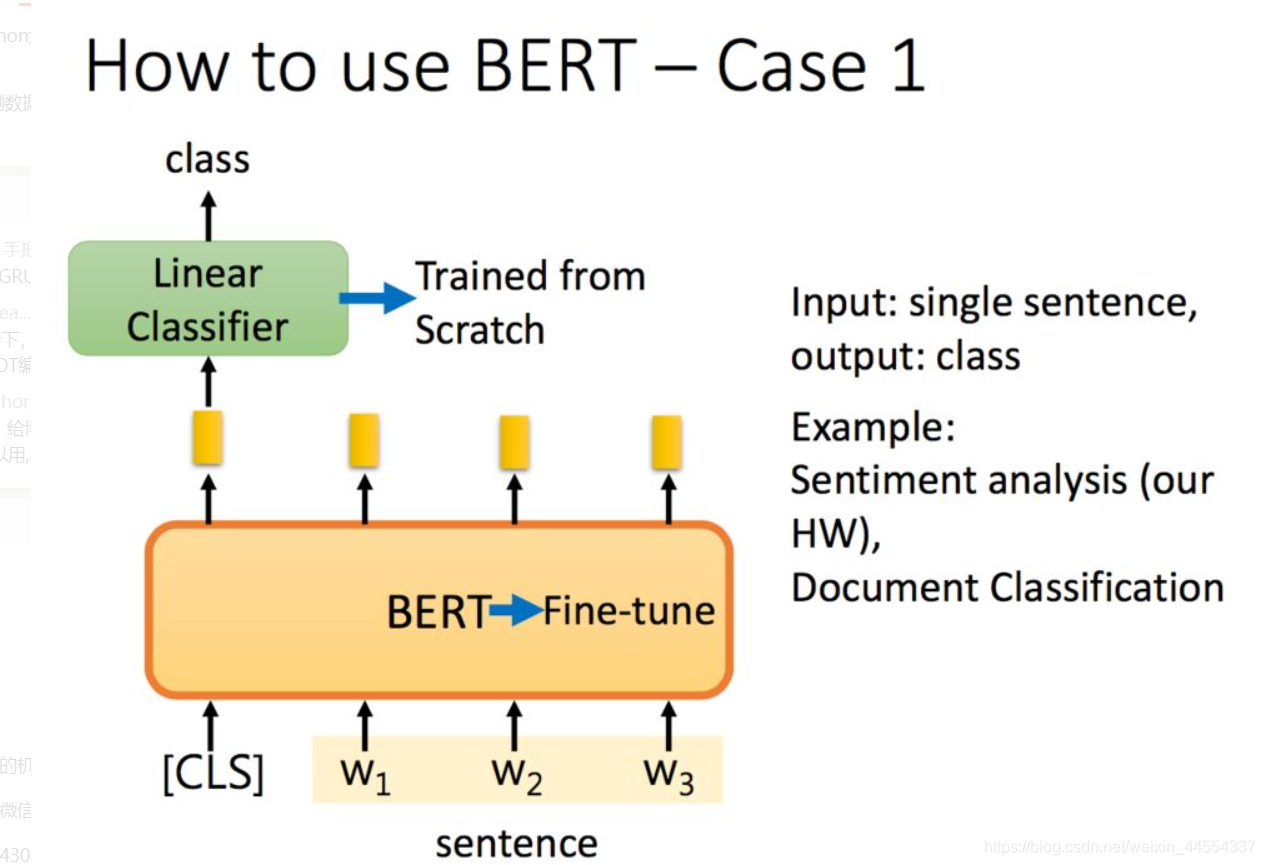
- 例1:分类
Input: single sentence,
output: class
Example: Sentiment analysis (our HW),Document Classification:文章分类
对于分类任务可以给句子前加一个[CLS],然后在进行线性的分类。分类器的参数是随机初始化的,分类器也和bert一起调整学习。也可以加上标签训练线性分类起,同时对BERT进行微调(Fine-tune)。
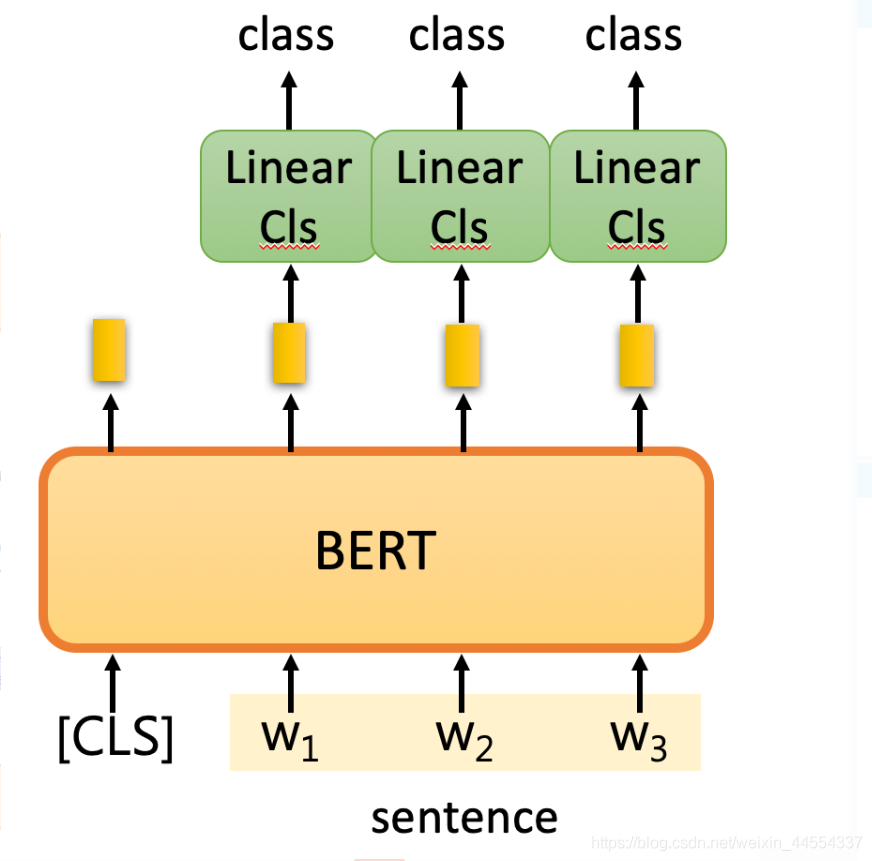
- 例2:词性标注
Input: single sentence,
output: class of each word
Example:Slot filling
比如,到达台北
到达的output是other,台北是地点
- 例3:自然语言推理:只有三个输出的问题,对,错,不知道
Input: two sentences,
output: class
Example: Natural Language Inference

- 例4:阅读理解
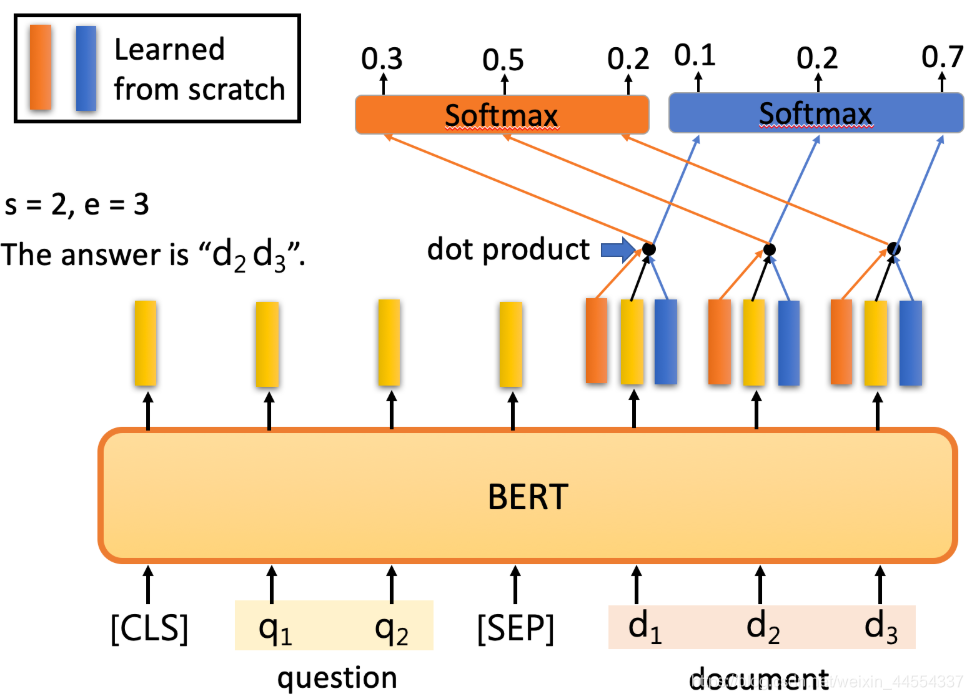
两个问题落到第s的doken和第e的token,也就是说答案就是s到e,output是s到e。

- 最后一个例子是抽取式QA,抽取式的意思是输入一个原文和问题,输出两个整数start和end,代表答案在原文中的起始位置和结束位置,两个位置中间的结果就是答案
具体怎么解决刚才的QA问题呢?把问题 - 分隔符 - 原文输入到BERT中,每一个单词输出一个黄颜色的embedding,这里还需要学习两个(一个橙色一个蓝色)的向量,这两个向量分别与原文中每个单词对应的embedding进行点乘,经过softmax之后得到输出最高的位置。正常情况下start <= end,但如果start > end的话,说明是矛盾的case,此题无解。
Bert一出来就开始在各项比赛中崭露头角,百度提出的ERNIE,ERNIE也是芝麻街的人物,而且还是Bert的好朋友。ernie是专为u中文设计的。
bert的这马多层,就像一个NLP,是一个阶层的关系,输出层做笔记困难的任务,如果24层,就是学24层的weight,比如词性分析,虽好的解决的是第13层到17层,更难的问题解决可能需要更下面的层。
bert神奇到什么程度:给英文分类,自动就能学会中文文章的分类。
4.GPT-2
GPT是Generative Pre-Training 的简称,但GPT不是芝麻街的人物。GPT-2的模型非常巨大,它其实是Transformer的Decoder。
比如ELMO需要94M,BERT需要340M,但GPT就像个巨大的独角兽,1532M
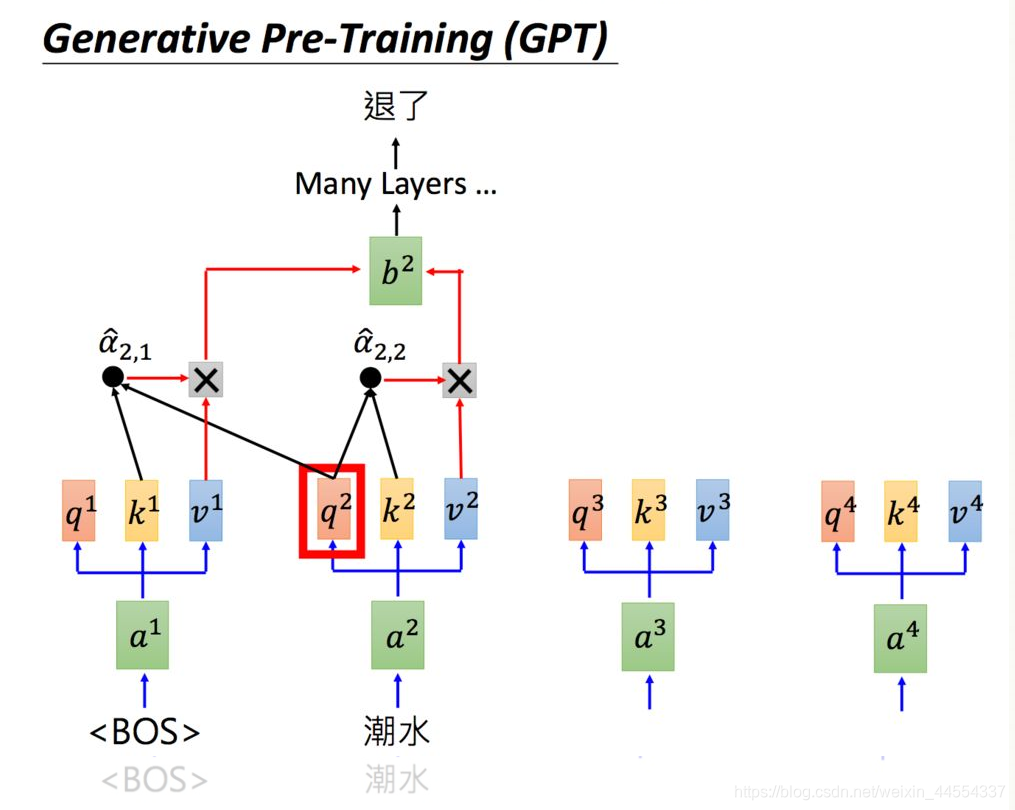
GPT-2是Transformer(变压器)的Decoder(解码器)部分,输入一个句子中的上一个词,我们希望模型可以得到句子中的下一个词。根据“潮水”预测下一个词语“退了”,中间做self attension:有很多层,分别做attntion,得到一个embedding,来做预测。
由于GPT-2的模型非常巨大,它在很多任务上都达到了惊人的结果,甚至可以做到zero-shot learning(简单来说就是模型的迁移能力非常好),如阅读理解任务,不需要任何阅读理解的训练集,就可以得到很好的结果。
比如给一篇文章,然后给一个 问题,直接就给答案,
还可以做翻译,特别快。

GPT-2可以自己进行写作,写得还是不错的!
阅读理解:变现不错哦,GPT参数越高,争取率越高,自动看到A冒号就输出问题的答案
Summarization:上表现就比较差。
这篇关于2020李宏毅学习笔记——20.ELMO,BERT,GPT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







