本文主要是介绍Transformer的前世今生 day04(ELMO,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ELMO
前情回顾
- NNLM模型:主要任务是在预测下一个词,副产品是词向量
- Word2Vec模型:主要任务是生成词向量
- CBOW:训练目标是根据上下文预测目标词
- Skip-gram:训练目标是根据目标词预测上下文词
ELMO模型的流程
- 针对Word2Vec模型的词向量不能表示多义词的问题,产生了ELMO模型,模型图如下:
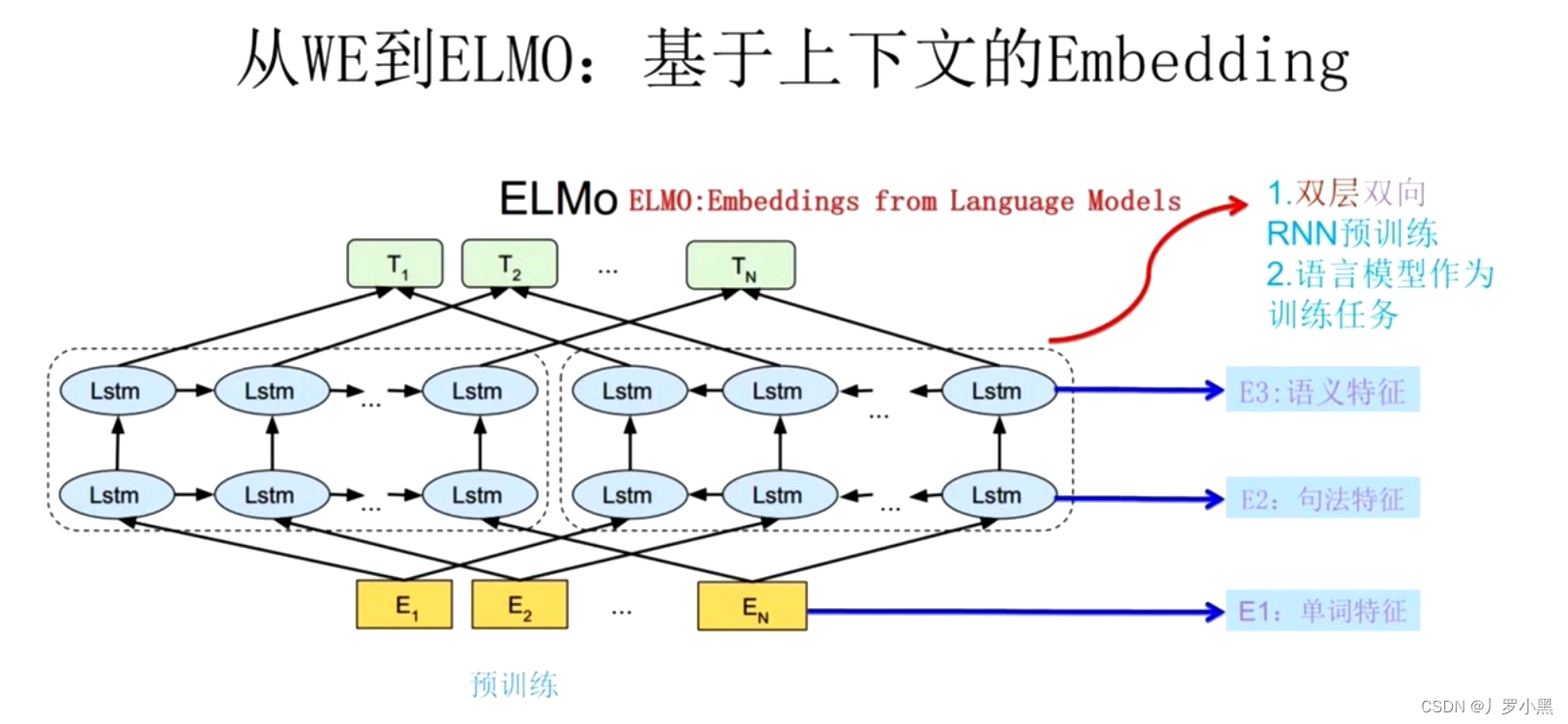
- 通过不只是训练单单一个单词的Q矩阵,而是把这个词的上下文信息也融入到这个Q矩阵中,从而解决一词多义的问题
- 注意:左侧的LSTM是融入上文信息,右侧的LSTM是融入下文信息。E已经是将独热编码经过一层Q矩阵得到的
- 在我们做具体任务T时,会先将E1、E2、E3三层的特征信息做一个叠加之后,得到新的词向量K,其中(E2、E3为双向的句法和语义特征),所以K1为第一个词的词向量,且包含了这个词的单词特征、句法特征、语义特征
- 注意:在Word2Vec中,只是单纯将几个连续的单词按顺序拼接输入,所以只有这个单词的词向量,并没有上下文信息的叠加
ELMO模型怎么使用
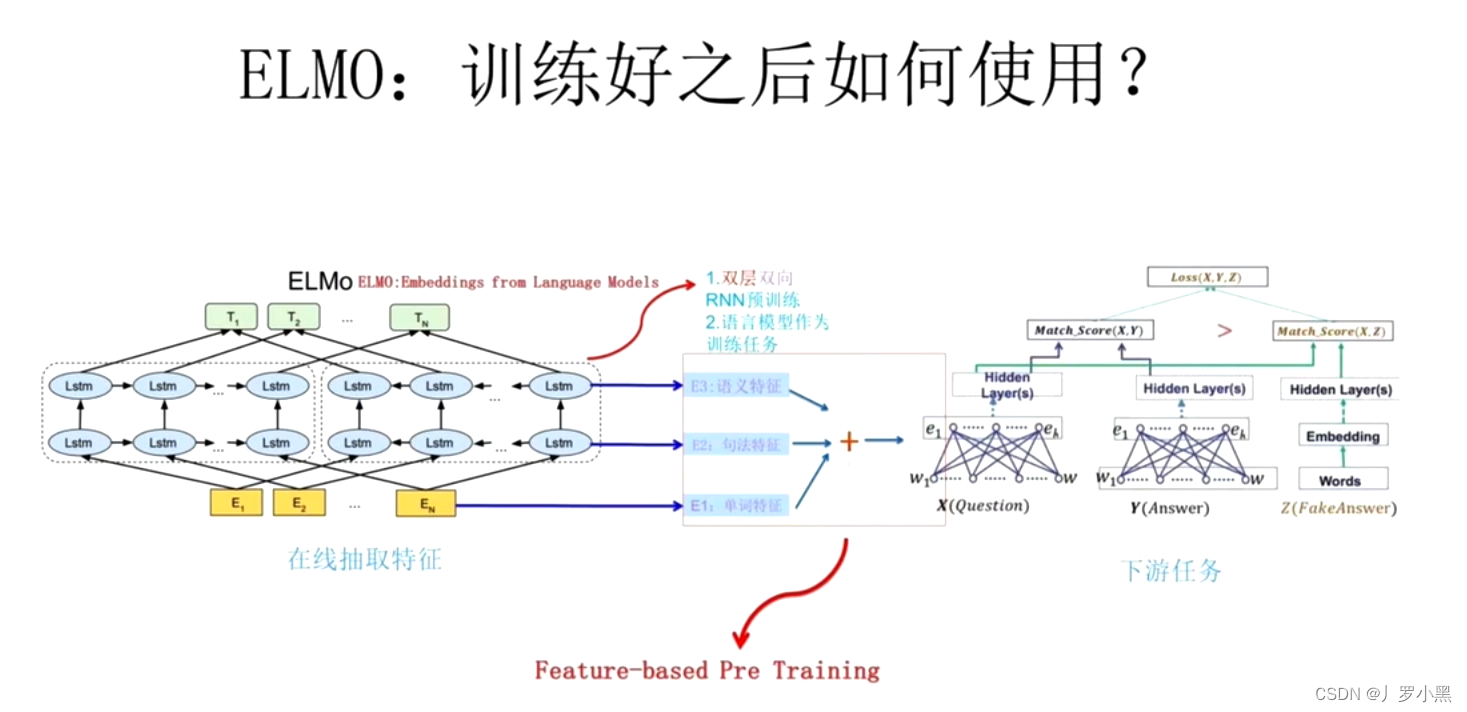
- 虽然同一个词的单词特征相同,但是在不同句子中的上下文信息会不同,也就代表着最后的词向量K会不同,如下:

- 我们可以用训练好的ELMO模型,去掉该模型针对任务的改造部分,比如只选用T层往下的部分,用它来替换下图其他任务中的W到e的这一部分,即替换之前Word2Vec预训练部分,从而实现ELMO模型的预训练效果,解决一词多义问题:
参考文献
- 08 ELMo模型(双向LSTM模型解决词向量多义问题)
这篇关于Transformer的前世今生 day04(ELMO的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








