diffusers专题

ModuleNotFoundError: No module named ‘diffusers.models.dual_transformer_2d‘解决方法
Python应用运行报错,部分错误信息如下: Traceback (most recent call last): File “\pipelines_ootd\unet_vton_2d_blocks.py”, line 29, in from diffusers.models.dual_transformer_2d import DualTransformer2DModel ModuleNotF
flux bitsandbytes bnb量化;diffusers 15G显卡加载使用
使用bitsandbytes进行bnb量化 在线参考: https://colab.research.google.com/gist/sayakpaul/4af4d6642bd86921cdc31e5568b545e1/scratchpad.ipynb 安装包 !pip install -U accelerate transformers bitsandbytes !pip install g

Diffusers代码学习-多个ControlNet组合
可以根据不同的图像输入组合多个ControlNet条件来创建MultiControlNet。为了获得更好的结果,比较有利的做法是: 1. 有选择的进行遮罩,使其不重叠(例如,遮罩canny图像中姿势条件所在的区域) 2. 使用controlnetconditioning_scale参数进行实验,以确定分配给每个条件输入的权重 下面将结合Canny 边缘检测图像和人体姿态估计图像来生成新图像。

Diffusers代码学习-ControlNet(Inpaint)
对于Inpaint,需要一个初始图像、一个蒙版图像和一个描述用什么替换蒙版的提示词。ControlNet模型允许添加另一个控制图片来调节模型。让我们用Inpaint蒙版来调整模型。这样,ControlNet可以使用修复掩模作为控件来引导模型在蒙版区域内生成图像。 # 以下代码为程序运行进行设置 import os os.environ["HF_ENDPOINT"] = "https://

Diffusers代码学习: T2I Adapter
T2I Adapter是一款轻量级适配器,用于控制文本到图像模型并为其提供更准确的结构指导。它通过学习文本到图像模型的内部知识与外部控制信号(如边缘检测或深度估计)之间的对齐来工作。 T2I Adapter的设计很简单,条件被传递到四个特征提取块和三个下采样块。这使得针对不同的条件快速而容易地训练不同的适配器,这些适配器可以插入到文本到图像模型中。T2I Adapter与ControlNet

Diffusers代码学习: 多个Adapter
T2I Adapter也是可组合的,允许您使用多个适配器对图像施加多个控制条件。例如,可以使用姿势贴图提供结构控制,使用深度贴图进行深度控制。这是由[MultiAdapter]类启用的。 让我们用姿势和深度适配器来调节文本到图像的模型。创建深度和姿势图像并将其放置在列表中。 # 以下代码为程序运行进行设置 import os os.environ["HF_ENDPOINT"] = "h

Diffusers代码学习: IP-Adapter Inpainting
IP-Adapter还可以通过Inpainting自动管道和蒙图方式生成目标图片。 # 以下代码为程序运行进行设置,使用Inpainting 的自动管道, import osos.environ["HF_ENDPOINT"] = "https://hf-mirror.com" from diffusers import AutoPipelineForInpainting # 程序需要能够

diffusers 使用脚本导入自定义数据集
在训练扩散模型时,如果附加额外的条件图片数据,则需要我们准备相应的数据集。此时我们可以使用官网提供的脚本模板来控制导入我们需要的数据。 您可以参考官方的教程来实现具体的功能需求,为了更加简洁,我将简单描述一下整个流程的关键点: 首先按照您的需求准备好所有的数据集文件,统一放到一个dataset_name(可以自己定义)目录下,可以划分多个子文件夹,但是需要在您的matadata.json中描述

Diffusers代码学习: IP-Adapter
从操作的角度来看,IP-Adapter和图生图是很相似的,都是有一个原始的图片,加上提示词,生成目标图片。但它们的底层实现方式是完全不一样的,我们通过源码解读来看一下。以下是ip adapter的实现方式 # 以下代码为程序运行进行设置,使用文生图的自动管道, # 图生图实现使用的图生图的自动管道(见这里Diffusers代码学习-图生图) import osos.environ["HF_

使用Docker配置深度学习环境——以diffusers为例
Docker的其他信息可以在我的网站上找到,这里假设安装完成了,直接上手。 git clone 仓库地址 打开docker目录,找到目标版本: sudo docker build diffusers-pytorch-cuda 如果失败,尝试使用换源: sudo nano /etc/docker/daemon.json 把 "registry-mirrors" : ["http
【Diffusers 学习(1)】from_petrained() 中的 use_safetensors 有什么作用?
use_safetensors(bool,可选,默认为None) 如果设置为 None,则在 safetensor 权重可用且已安装 safetensor 库的情况下下载这些权重。如果设置为 True,则会从 safetensor 权重中强制加载模型。如果设置为 False,则不会加载 safetensor 权重。 官方文档:https://huggingface.co/docs/diffus

【Diffusers库】第四篇 训练一个扩散模型(Unconditional)
目录 写在前面的话下载数据模型配置文件加载数据创建一个UNet2DModel创建一个调度器训练模型完整版代码: 写在前面的话 这是我们研发的用于 消费决策的AI助理 ,我们会持续优化,欢迎体验与反馈。微信扫描二维码,添加即可。 官方链接:https://ailab.smzdm.com/ *************************************

【深度学习】diffusers 学习过程记录,StableDiffusion扩散原理
教程地址:https://huggingface.co/docs/diffusers/quicktour 文章目录 环境扩散模型噪声残差的作用原理,文字编码如何给入Unetschedulerguidance_scalescheduler.init_noise_sigma训练时候的反向传播保存模型的方式 环境 python3.10安装环境: pip install --upgr

使用 Diffusers 实现 ControlNet 高速推理
自从 Stable Diffusion 风靡全球以来,人们一直在寻求如何更好地控制生成过程的方法。ControlNet 提供了一个简单的迁移学习方法,能够允许用户在很大程度上自定义生成过程。通过 ControlNet,用户可以轻松地使用多种空间语义条件信息 (例如深度图、分割图、涂鸦图、关键点等) 来控制生成过程。 具体来说,我们可以: 将卡通绘图转化为逼真的照片,同时保持极佳的布局连贯性。

【Diffusers库】第二篇 快速生成图片
目录 写在前面的话提速的几个条件1. 硬件2. 精度3. 推理步数3. 内存4. 管道组件 提质的几个条件1. 模型2. prompt 写在前面的话 这是我们研发的用于 消费决策的AI助理 ,我们会持续优化,欢迎体验与反馈。微信扫描二维码,添加即可。 官方链接:https://ailab.smzdm.com/ ***********************

sdxl-turbo、playground文生图模型diffusers使用案例
1、sdxl-turbo SDXL-Turbo是一种快速生成的文本到图像模型,可以在单个网络评估中从文本提示合成逼真的图像。 参考:https://huggingface.co/stabilityai/sdxl-turbo 对比效果相比PixArt模型差很多,参考https://blog.csdn.net/weixin_42357472/article/details/135520142
![2、 Scheduler介绍 代码解析 [代码级手把手解diffusers库]](https://img-blog.csdnimg.cn/direct/305a310816824097993c5bfa146a5319.png)
2、 Scheduler介绍 代码解析 [代码级手把手解diffusers库]
Scheduler简介分类老式 ODE 求解器(Old-School ODE solvers)初始采样器(Ancestral samplers)Karras噪声调度计划DDIM和PLMSDPM、DPM adaptive、DPM2和 DPM++UniPCk-diffusion 1.DDPM2.DDIM3.Euler4.DPM系列5. Ancestral6. Karras7. SDE

【AIGC】Diffusers:训练扩散模型
前言 无条件图像生成是扩散模型的一种流行应用,它生成的图像看起来像用于训练的数据集中的图像。通常,通过在特定数据集上微调预训练模型来获得最佳结果。你可以在HUB找到很多这样的模型,但如果你找不到你喜欢的模型,你可以随时训练自己的模型! 本教程将教您如何在 Smithsonian Butterflies 数据集的子集上从头开始训练 UNet2DModel 以生成您自己的🦋蝴蝶🦋。 💡 本

【AIGC】Diffusers:扩散模型的开发手册说明1
主要组件 最先进的扩散管道 diffusion pipelines,只需几行代码即可进行推理。可交替使用的各种噪声调度器 noise schedulers,用于平衡生成速度和质量。预训练模型 models,可作为构建模块,并与调度程序结合使用,来创建您自己的端到端扩散系统。 开始学习 一个快速的推理程序 from diffusers import DDPMPipelineddpm = D

【扩散模型】12、Stable Diffusion | 使用 Diffusers 库来看看 Stable Diffusion 的结构
文章目录 一、什么是 Stable Diffusion二、Diffusers 库三、微调、引导、条件生成3.1 微调3.2 引导3.3 条件生成 四、Stable Diffusion4.1 以文本为条件生成4.2 无分类器的引导4.3 其它类型的条件生成:超分辨率、图像修补、深度图到图像的转换4.4 使用 DreamBooth 微调 五、使用 Diffusers 库来窥探 Stable Di

【从零到一AIGC源码解析系列1】文本生成图片Stable Diffusion的diffusers实现
目录 1. 如何使用 StableDiffusionPipeline 1.1环境配置 1.2 Stable Diffusion Pipeline 1.3生成非正方形图像 2. 如何使用 diffusers 构造自己的推理管线 关注公众号【AI杰克王】 Stable Diffusion是由CompVis、StabilityAl和LAION的研究人员和工程师创建的文本到图像潜在扩散
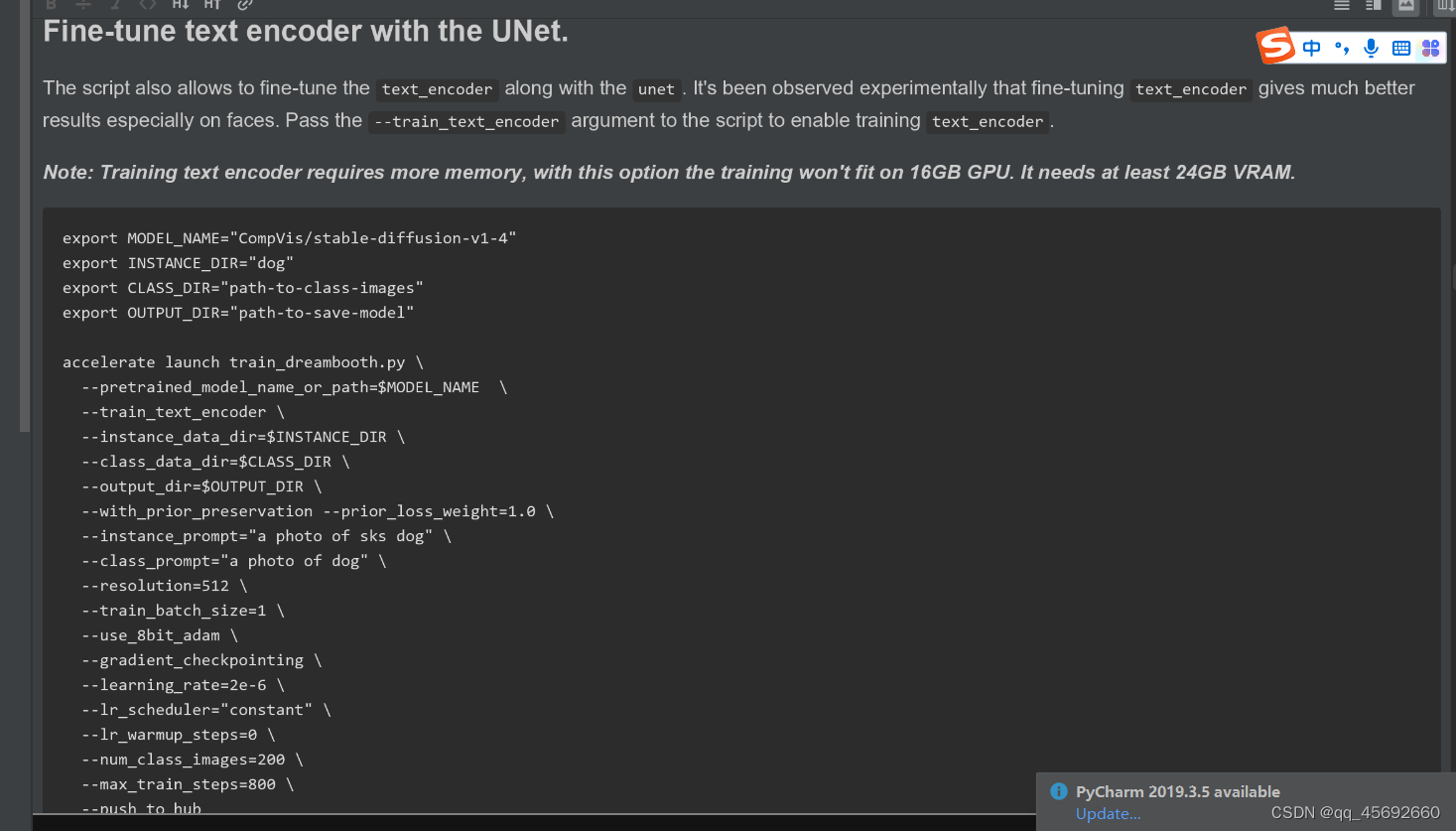
diffusers 源码待理解之处
一、训练DreamBooth时,相关代码的细节小计 ** class_labels = timesteps 时,模型的前向传播怎么走?待深入去看 ** 利用class_prompt去生成数据,而不是instance_prompt class DreamBoothDataset(Dataset):"""A dataset to prepare the instance and

ControlNet on diffusers
ControlNet on diffusers 参考:https://huggingface.co/docs/diffusers/using-diffusers/controlnet v0.24.0 ControlNet 通过输入给 diffusion 模型一个额外的输入图作为条件,来控制生成图的结果。这个条件输入图可以是各种形式,如 canny 边缘、用户的手稿、人体姿态、深度图等。这

diffusers pipeline拆解:理解pipelines、models和schedulers
diffusers pipeline拆解:理解pipelines、models和schedulers 翻译自:https://huggingface.co/docs/diffusers/using-diffusers/write_own_pipeline v0.24.0 diffusers 设计初衷就是作为一个简单且易用的工具包,来帮助你在自己的使用场景中构建 diffusion 系统。

using dapers on diffusers: Dreambooth, Texual Inversion, LoRA and IP-Adapter
using dapers on diffusers: Dreambooth, Texual Inversion, LoRA and IP-Adapter 参考自:https://huggingface.co/docs/diffusers/using-diffusers/loading_adapters 如今,对于 diffusion 模型,有许多高效的训练技术来微调一个定制化的模型,能够
Textual Inversion on diffusers
Textual Inversion on diffusers 参考自官方文档:https://huggingface.co/docs/diffusers/training/textual_inversion_inference、https://huggingface.co/docs/diffusers/training/text_inversion?installation=PyTorch