本文主要是介绍【深度学习】diffusers 学习过程记录,StableDiffusion扩散原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
教程地址:https://huggingface.co/docs/diffusers/quicktour
文章目录
- 环境
- 扩散模型
- 噪声残差的作用
- 原理,文字编码如何给入Unet
- scheduler
- guidance_scale
- scheduler.init_noise_sigma
- 训练时候的反向传播
- 保存模型的方式
环境
python3.10安装环境:
pip install --upgrade diffusers accelerate transformers
扩散模型
不同的调度器具有不同的去噪速度和质量权衡。找出哪种对您最有效的方法是尝试它们!🧨 Diffusers 的主要特点之一是允许您轻松切换调度器。例如,要用 EulerDiscreteScheduler 替换默认的 PNDMScheduler,请使用 from_config() 方法加载它:
扩散模型(如Stable Diffusion)通过逐步添加和去除噪声的过程生成数据(如图像或音频)。这一过程包括两个主要阶段:正向扩散(forward diffusion)和逆向扩散(reverse diffusion)。
正向扩散(添加噪声)
正向扩散阶段是一个逐步的过程,其中原始数据(比如一张图像)逐渐被加入噪声,直到完全变为随机噪声。这一过程通常通过多个时间步骤进行,每一步都会在图像上添加一层噪声。正向扩散的最终结果是一张与原始图像毫无关系的纯随机噪声图像。这个过程是预设的,并不涉及学习。
逆向扩散(去除噪声)
逆向扩散是一个更为复杂的过程,其目的是将加噪后的图像逐步恢复到原始状态或生成新的数据。这个过程从纯噪声开始,逐步去除噪声,最终生成清晰的图像或数据。逆向扩散的每一步都需要预测给定噪声图像与其更少噪声状态之间的噪声残差,然后使用这个预测来更新当前噪声图像,使其更接近无噪声的状态。这一步骤是通过训练深度学习模型完成的,模型学会如何基于当前的噪声图像预测噪声残差。
噪声残差的作用
在逆向扩散过程中,噪声残差的概念至关重要。噪声残差是指当前噪声图像与去除一定噪声后应有的状态之间的差异。模型的任务是预测这一残差,然后用它来更新当前的噪声图像,从而一步步减少图像中的噪声。通过这种方式,模型能够从纯随机噪声中逐步构造出有意义的图像或数据。
总之,扩散模型通过正向扩散将数据转换为噪声,然后通过训练一个深度学习模型来逆向这一过程,从噪声中恢复出有意义的数据。噪声残差的预测是逆向扩散阶段的核心,使模型能够逐步减少噪声,最终生成清晰的图像或其他类型的数据。
原理,文字编码如何给入Unet
http://shiyanjun.cn/archives/2212.html
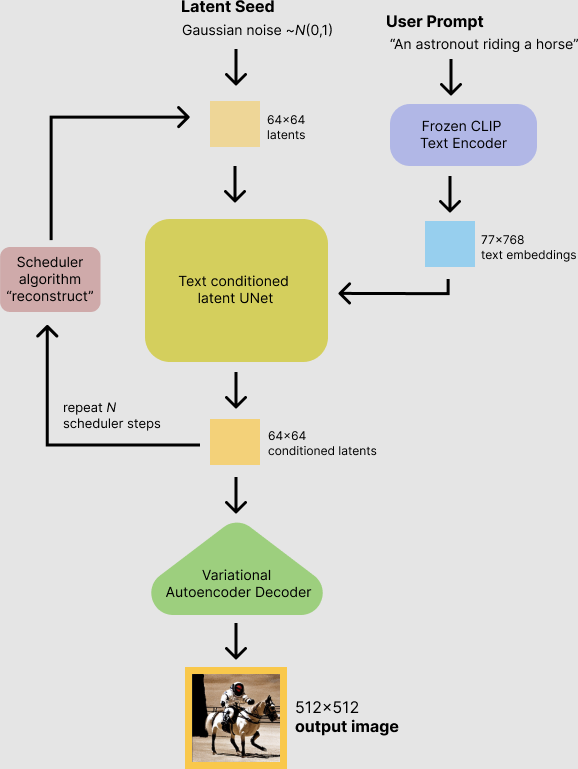
scheduler
scheduler.timesteps是什么,为什么是这样的数字:
[980, 960, 940, 920, 900, 880, 860, 840, 820, 800, 780, 760, 740, 720,
700, 680, 660, 640, 620, 600, 580, 560, 540, 520, 500, 480, 460, 440,
420, 400, 380, 360, 340, 320, 300, 280, 260, 240, 220, 200, 180, 160,
140, 120, 100, 80, 60, 40, 20, 0]
scheduler.timesteps 是一组数字,代表在扩散过程中使用的时间步。这些数字从高到低排列,表示从纯噪声开始逐步去除噪声的过程,直至生成最终图像。数字之所以是这样的(从980递减到0),是因为它们代表了不同的噪声级别。在扩散模型中,较高的数字对应于更多的噪声,而0表示没有噪声。这个序列是根据模型的训练和预期输出精细调整的,以最优化图像生成过程。
**scheduler(调度器)**的作用是在每个时间步管理噪声的减少过程。具体来说,scheduler.step函数接受模型预测的噪声残差、当前时间步t和当前的图像(或噪声)状态input,然后计算并返回下一个时间步的图像状态。这个步骤是通过将预测的噪声残差与当前状态结合,按照时间步指示的噪声级别调整,从而实现逐步去噪的目的。
guidance_scale
guidance_scale 是一个参数,它控制了在生成图像时,文本提示(prompt)的权重有多大。较高的guidance_scale值意味着文本提示将对生成的图像有更大的影响,这通常用于提高图像与文本描述之间的一致性。这是一种在无条件和有条件路径之间进行权衡的方法,可以帮助模型更准确地按照文本提示生成图像。
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
通过加权调整这两部分的差异,应用引导尺度(guidance_scale),增强文本条件对最终生成效果的影响。这个过程有助于在遵循文本提示的同时,增加生成图像的多样性和质量。
scheduler.init_noise_sigma
latents = latents * scheduler.init_noise_sigma 这一步意味着用初始噪声标准差(init_noise_sigma)缩放随机噪声(latents)。init_noise_sigma是一个预设值,决定了随机噪声的初始强度,对应于扩散过程的开始。这是准备初始随机噪声以匹配模型期望的噪声分布的一种方式。
训练时候的反向传播
https://huggingface.co/docs/diffusers/tutorials/basic_training
在这个程序中,反向传播的过程是通过 accelerator.backward(loss) 实现的。首先,来看一下整个训练循环中与反向传播相关的几个关键步骤,并解释其中的每一步。
关键步骤解释
正向传播(Forward Pass): 在正向传播阶段,模型接收带有噪声的图像 noisy_images 和对应的时间步 timesteps 作为输入,然后输出预测的噪声 noise_pred。
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
损失计算: 使用预测的噪声和实际加到干净图像上的噪声之间的均方误差(Mean Squared Error, MSE)来计算损失。
loss = F.mse_loss(noise_pred, noise)
F.mse_loss 计算预测噪声和实际噪声之间的差异,这是模型优化的目标。
反向传播(Backward Pass): 通过 accelerator.backward(loss) 调用反向传播。这一步计算了 loss 相对于模型参数的梯度。
accelerator.backward(loss)
在这里,accelerator 对象自动处理了梯度的计算和反向传播。accelerator 是 Accelerate 库的一个组件,它简化了在不同硬件上进行混合精度训练和梯度累积的复杂性。
梯度裁剪: 为了防止梯度爆炸,对模型参数的梯度进行裁剪。
accelerator.clip_grad_norm_(model.parameters(), 1.0)
参数更新: 使用优化器(如SGD、Adam等)更新模型参数。
optimizer.step()
在这一步中,根据梯度和学习率调整模型权重,以最小化损失函数。
学习率调整: 根据学习率调度器更新学习率,以改善训练过程中的学习效率。
lr_scheduler.step()
梯度清零: 在下一次训练迭代开始前,清除旧的梯度,防止梯度累加。
optimizer.zero_grad()

保存模型的方式
管道
您还可以将整个管道及其所有组件推送到 Hub。例如,使用您想要的参数初始化 StableDiffusionPipeline 的组件:
from diffusers import (UNet2DConditionModel,AutoencoderKL,DDIMScheduler,StableDiffusionPipeline,
)
from transformers import CLIPTextModel, CLIPTextConfig, CLIPTokenizerunet = UNet2DConditionModel(block_out_channels=(32, 64),layers_per_block=2,sample_size=32,in_channels=4,out_channels=4,down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),cross_attention_dim=32,
)scheduler = DDIMScheduler(beta_start=0.00085,beta_end=0.012,beta_schedule="scaled_linear",clip_sample=False,set_alpha_to_one=False,
)vae = AutoencoderKL(block_out_channels=[32, 64],in_channels=3,out_channels=3,down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],latent_channels=4,
)text_encoder_config = CLIPTextConfig(bos_token_id=0,eos_token_id=2,hidden_size=32,intermediate_size=37,layer_norm_eps=1e-05,num_attention_heads=4,num_hidden_layers=5,pad_token_id=1,vocab_size=1000,
)
text_encoder = CLIPTextModel(text_encoder_config)
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")# 将所有组件传递给 StableDiffusionPipeline 并调用 push_to_hub() 将管道推送到 Hub:
components = {"unet": unet,"scheduler": scheduler,"vae": vae,"text_encoder": text_encoder,"tokenizer": tokenizer,"safety_checker": None,"feature_extractor": None,
}pipeline = StableDiffusionPipeline(**components)
pipeline.push_to_hub("my-pipeline")
push_to_hub() 函数将每个组件保存到存储库的子文件夹中。现在,您可以从 Hub 上的存储库重新加载管道:
pipeline = StableDiffusionPipeline.from_pretrained("your-namespace/my-pipeline")
这篇关于【深度学习】diffusers 学习过程记录,StableDiffusion扩散原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








