stablediffusion专题

一文教你StableDiffusion图生图批量处理!
今天给大家讲解一下SD图生图的批量处理功能应该如何使用~ 一、图生图批量处理功能的基本用法 首先打开webUI,在图生图页面下我们先找到批量处理的菜单: 最简单的批量处理方法只需要用到【输入目录】和【输出目录】两个功能: 第一步,需要建立一个输入目录的文件夹,大家注意不要用中文路径。 然后将要重绘的图片编号序号放到这个文件夹内: 接着我们将这个目录的路径粘贴到输入目录:

主流AI绘画工具-StableDiffusion本地部署方法(mac电脑版本)
Stable Diffusion是一款强大的AI生成图像模型,它可以基于文本描述生成高质量的图像。对于想要在本地运行此模型的用户来说,使用Mac电脑部署Stable Diffusion是一个非常吸引人的选择,特别是对于M1或M2芯片的用户。本文将详细介绍如何在Mac上本地部署Stable Diffusion,包括Web UI的设置。 一、准备工作 系统要求 • 操作系统:macOS 12

Stablediffusion有哪几种模型,小白入门必看!
前言 在Stable Diffusion中,模型有好几种,不同插件有不同的模型,分别作用于不同的功能。 今天卧龙君就带着大家一起来了解一下。 大模型:Stable Diffusion StableDiffusion大模型,可以理解为绘画风格集合,SD需要大模型来规定它生成的图片风格. 大模型是必选模型,你必须选择一个大模型才能开始生成工作。 记得选择checkpoint类型的文件,它们
【CVPR2024】面向StableDiffusion的编辑算法FreePromptEditing,提升图像编辑效果
近日,阿里云人工智能平台PAI与华南理工大学贾奎教授团队合作在深度学习顶级会议 CVPR2024 上发表 FPE(Free-Prompt-Editing) 算法,这是一种面向StableDiffusion的图像编辑算法。在这篇论文中,StableDiffusion可用于实现图像编辑的本质被挖掘,解释证明了基于StableDiffusion编辑的算法本质,并基于此设计了新的图像编辑算法,大幅度提升了

AI绘图StableDiffusion最强大模型盘点 - 诸神乱战
玩了这么久的StableDiffusion,Civitai和HF上的各种大模型和LORA也都基本玩了个遍。 自己也一直想做一期盘点,选出我自己心中最好或者最有意思的那几个大模型。 毕竟每次看着模型库里几十个大模型,是个人都遭不住。 我在这篇文章中,会列举5个大模型,你们也都只留这5个,足矣。 分别是: majicMIX(整体最好的真人大模型) GhostMix(整体最好的2.5D大模型

StableDiffusion简单使用教程
以下是一个简单的Stable Diffusion使用教程 一:准备工作 1. 安装所需软件:下载并安装 Stable Diffusion 相关程序。 2. 配置硬件:建议具备一定性能的显卡,以确保流畅运行。 二、启动软件 1. 打开 Stable Diffusion 应用程序。 三、模型加载 1. 根据需要选择加载合适的模型。 四、基本设置 1. 设置图像大小、分辨率

StableDiffusion Windows本地部署
检查电脑环境 启动CMD命令窗。 如上图,在CMD窗口输入python命令,可查看本地安装的python版本信息等。输入exit()退出python命令行 执行where命令,可查看python安装目录。 必须安装Python3.10.x,因为stable-diffusion-webui的一些依赖库对Python版本有一些要求。 Git不是必须安装,当我们不用git clone方式下
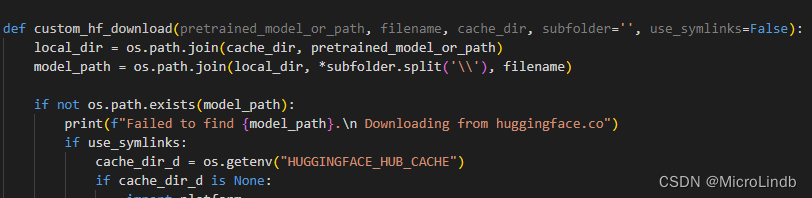
【StableDiffusion秋叶包反斜杠问题】Failed to find xxx\sd-webui-aki-v4.8\...\xxx.pth
一、问题发生 1.在我额外安装预处理器时报错 意思是没办法找到有这么一个包(但我已经把这个包扔进去了) 完整报错: Failed to find S:\app_AI\stableDiffusion-webui-aki\sd-webui-aki-v4.8\extensions\sd-webui-controlnet\annotator\downloads\hand_refiner\hr1

【stableDiffusion】HuggingFace模型下载(只要知道url,就直接开始下载)
一、方法 有人说,那我怎么知道 huggingface 上面我想要的资源的url,去哪儿找啊? 那就涉及到一些魔法手段了,或者你能在其他人的博客或者百度上搜索到合适的url。 我这个办法是用来节约我的魔法的流量的。 1.迅雷 1.1 打开迅雷,点击右上角的“新建”: 1.2 把你要下载的资源的url复制过来,请注意观察,在url后面我添加了参数,也就是添加了“?download=tr

StableDiffusion 文生视频教程,从Mov2mov到AnimateDiff
文章目录 0. 前言1. 简介2. 文生视频2.1 Mov2mov2.1.1 插件安装2.1.2 视频生成 2.2 ffmpeg + Ebsynth2.2.1 ffmpeg 安装2.2.2 Ebsynth安装2.2.3 Ebsynth 插件安装2.2.4 视频生成2.2.4.1 Step 1 蒙版裁剪2.2.4.2 Step2 识别关键帧2.2.4.3 Step3~4 关键帧重绘2.2.4.
StableDiffusion-02 LoRA上手使用实测 尝试生成图片 使用多个LoRA 调整LoRA效果 10分钟上手 多图
准备工作 请你确保,你已经完成了 StableDiffusion-01 这一节的内容,可以顺利的运行SD,并且可以正常的生成图片。 本节我们就尝试使用LoRA并生成图片。 介绍 LoRA Stable Diffusion中的LoRA(Low-Rank Adaptation,低秩自适应)是一种针对大型模型微调的技术,旨在加速模型的训练过程并显著减少模型文件的存储成本。这项技术通过冻结原有基础模

StableDiffusion Web UI开启FP8,极大节约显存
升级了Pytorch后,StableDiffusion最新版本就可以有使用FP8的基础了,因此把秋叶的LINUX包也升级到了最新的版本。 升级Pytorch参考我的升级记录: ComfyUI SDWebUI升级pytorch随记-CSDN博客 然后下一步就是如何开启FP8了。与ComfyUI不同,SDWebUI不是通过启动参数来开启,而是在配置界面找到这个位置: 记得点保存生效。

【深度学习】diffusers 学习过程记录,StableDiffusion扩散原理
教程地址:https://huggingface.co/docs/diffusers/quicktour 文章目录 环境扩散模型噪声残差的作用原理,文字编码如何给入Unetschedulerguidance_scalescheduler.init_noise_sigma训练时候的反向传播保存模型的方式 环境 python3.10安装环境: pip install --upgr

【DataWhale学习】用免费GPU线上跑StableDiffusion项目实践
用免费GPU线上跑SD项目实践 DataWhale组织了一个线上白嫖GPU跑chatGLM与SD的项目活动,我很感兴趣就参加啦。之前就对chatGLM有所耳闻,是去年清华联合发布的开源大语言模型,可以用来打造个人知识库什么的,一直没有尝试。而SD我前两天刚跟着B站秋叶大佬和Nenly大佬的视频学习过,但是生成某些图片显存吃紧,想线上部署尝试一下。 参考:DataWhale 学习手册链接

2024不可不会的StableDiffusion(一)
1. 引言 这是我在学习 StableDiffusion (稳定扩散模型 简称SD)的第一篇入门文章,主要用于介绍稳定扩散模型和该领域的其他研究。在本文中,我想简要介绍一下如何使用Diffuser扩散库,来创建自己生成图像。下一篇文章,我们将深入研究这个库的各级组件。 闲话少说,我们直接开始吧! 2. SD功能介绍 简单来说,稳定扩散模型是一种可以在给定文本提示词的情况下生成图像的深度学习模
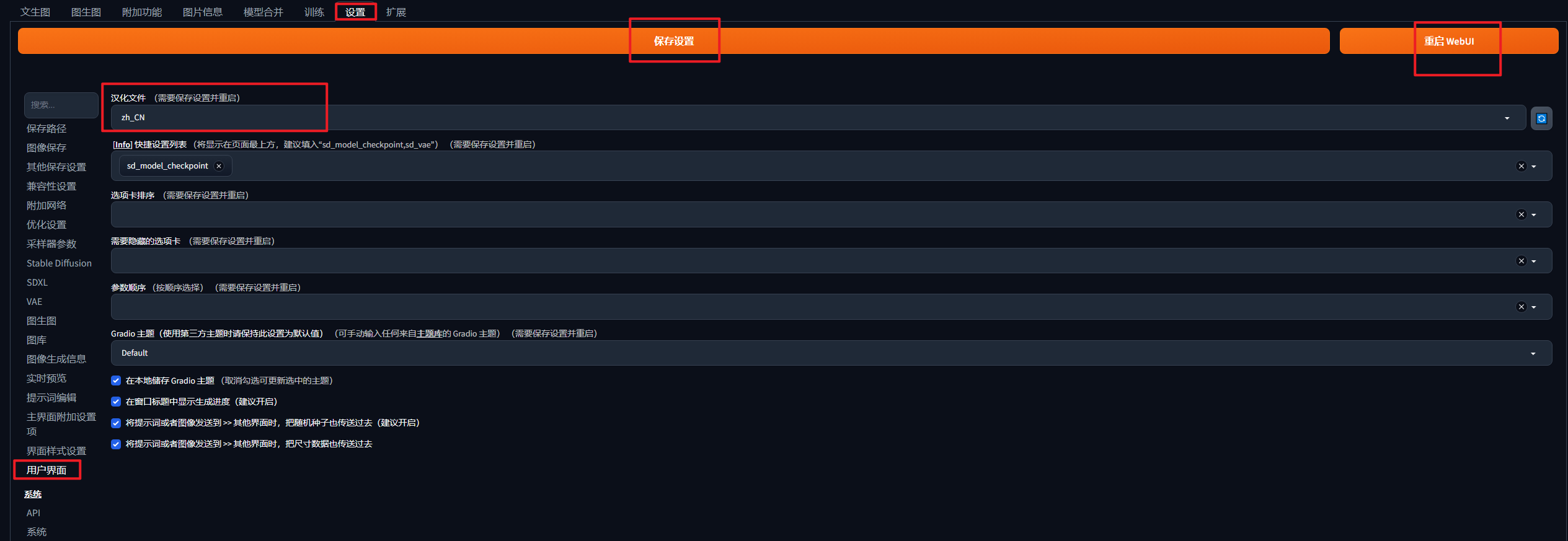
StableDiffusion新版汉化
新旧版不同,这里以新版为例,用的是带链接,可以更新的方法。 步骤: 1.找到这个位置,依次点击,注意选项。 2.点击加载,等待刷新。 ctrl+F搜索 zh_CN Localization 右边点击install,等待。 3.等待完成,切换,勾选。 4.点击应用重启,加载插件。 5.启用语言过程,找到用户界面,选中文,保存,再重启。

详解Keras3.0 KerasCV API: StableDiffusion image-generation model
Stable Diffusion 图像生成模型,可用于根据简短的文本描述(称为“提示”)生成图片 keras_cv.models.StableDiffusion(img_height=512, img_width=512, jit_compile=True) 参数说明 img_height:int,要生成的图像的高度,以像素为单位。请注意,仅支持128的倍数;所提供的值将四舍五入到最
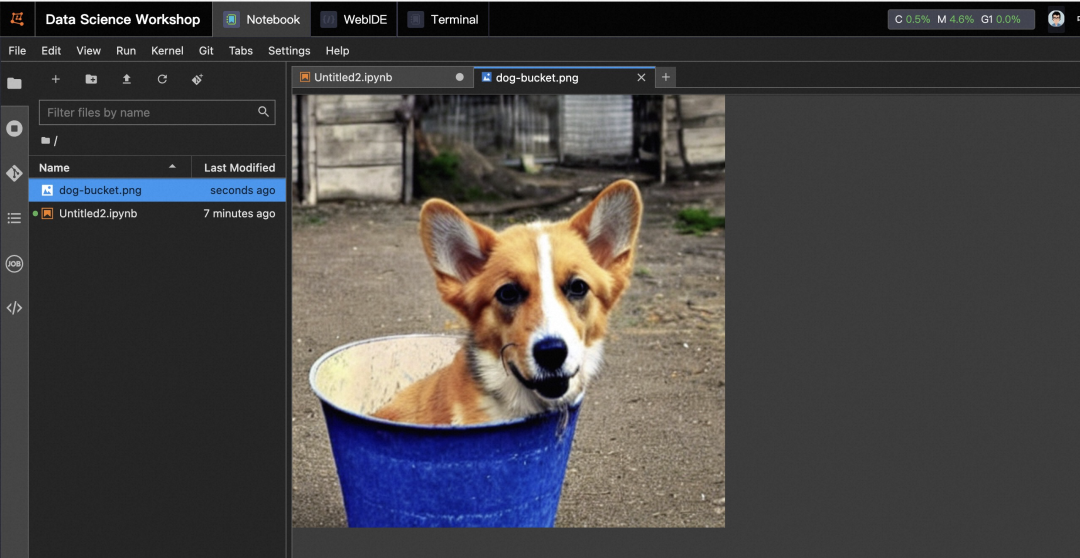
使用 PAI-Blade 加速 StableDiffusion Fine-Tuning
01 背景 Stable Diffusion 模型自从发布以来在互联网上发展迅猛,它可以根据用户输入的文本描述信息生成相关图片,用户也可以提供自己喜爱的风格的照片,来对模型进行微调。例如当我们输入 "A photo of sks dog in a bucket" ,StableDiffusion 模型会生成类似下面的图片: 02 PAI-Blade 加速 PyTorch
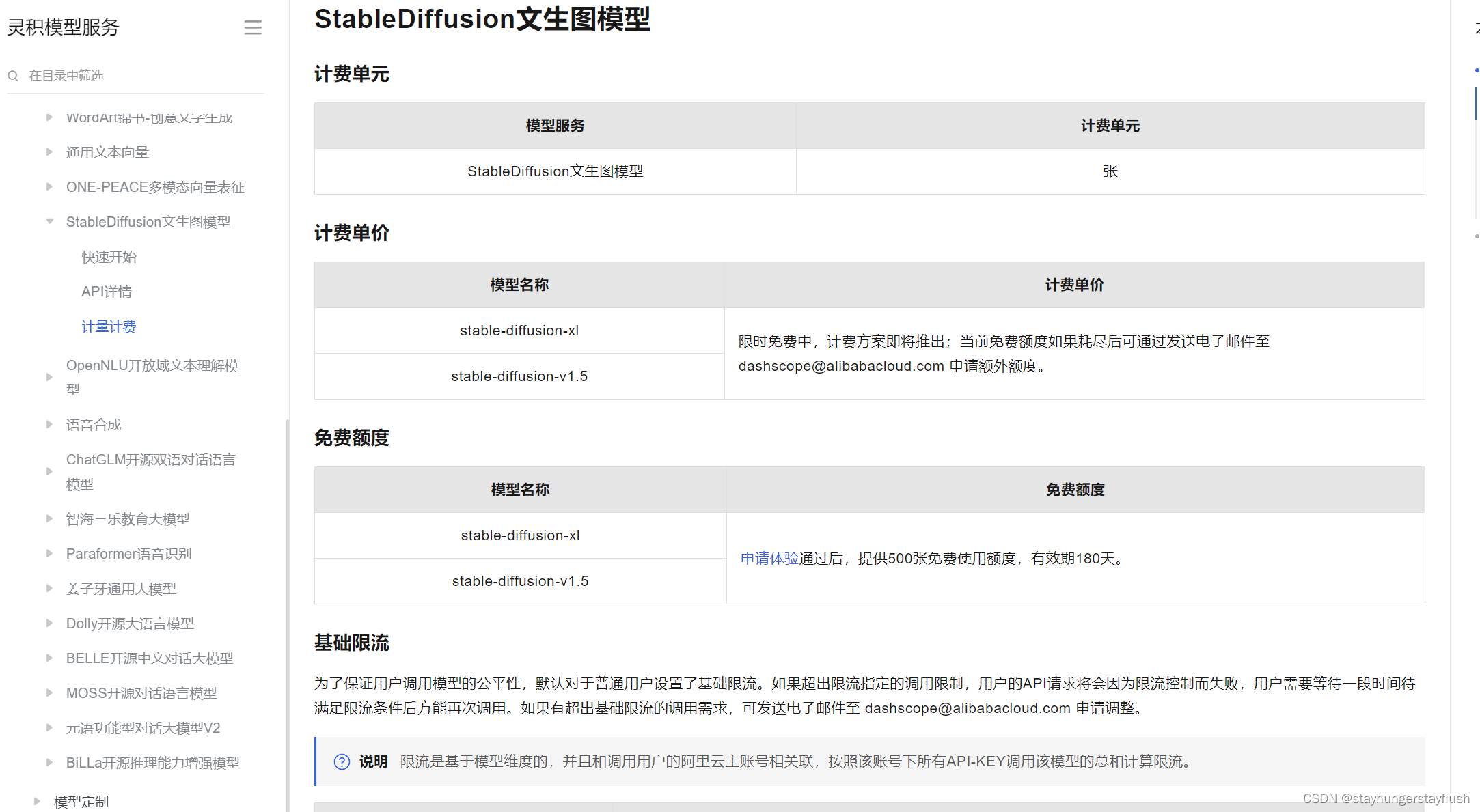
阿里云【stablediffusion】模型使用说明
stablediffusion介绍 Stable Diffusion是一种用于图像生成的人工智能技术,可以根据文本描述生成相应的图像。它基于Transformer语言模型,使用大型图像-文本数据集进行预训练,可以将图像与自然语言进行翻译,根据图像或文本描述生成新的图像。其主要特点包括开源、高质量、速度快、可控、可解释、多功能和可微调。 我们知道这个模型在本地很吃电脑的配置,我们可以使用阿里云的提

打工人副业变现秘籍,某多/某手变现底层引擎-StableDiffusion模型下载使用
一、模型的概念 首先要了解 Stable Diffusion 中的模型概念是什么?维基百科对模型的定义非常简单:用一个较为简单的东西来代表另一个东西。换句话说,模型代表的是对某一种事物的抽象表达。 在 AIGC 领域,为了使机器表现出智能,研发人员使用机器学习的方式让计算机从数据中汲取知识,并按照人类所期望的方向执行各种任务。对于 AI 绘画而言,我们通过对算法程序进行训练,让机器来

AI动画制作 StableDiffusion
1.brew -v 2.安装爬虫项目包所必需的python和git等系列系统支持部件 brew install cmake protobuf rust python@3.10 git wget pod --version brew link --overwrite cocoapods 3.从github网站克隆stable-diffusion-webui爬虫项目包至本地 ssh-add /Use
【腾讯云 HAI域探秘】借助HAI,轻松部署StableDiffusion环境拿捏AI作画-体验实验赢大奖
爆火的Ai生图你体验到了吗? 没有绘画能力、摄影能力也能随心所欲的创作出自己的作品! 但是很多人因为高昂的硬件和繁琐的安装对它望而却步。 腾讯云的高性能应用服务 HAI (Hyper Application Inventor)是一款专门为AI和科学计算设计的GPU应用服务产品。来看看如何利用HAI快速部署一个Stable Diffusion WebUI,实现AI绘画自由哈。 文章目录

AI绘图之 stablediffusion 从零到商业实战 超细教程(一)
AI绘图之 stablediffusion 从零到商业实战 超细教程(一) 目录 序言 一、AI绘图的发展历史 二、stablediffusion与midjouney的区别 1. midjouney的特点: 2. stablediffusion的特点: 3.midjouney和stablediffusion的优劣