本文主要是介绍【腾讯云 HAI域探秘】借助HAI,轻松部署StableDiffusion环境拿捏AI作画-体验实验赢大奖,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爆火的Ai生图你体验到了吗?
没有绘画能力、摄影能力也能随心所欲的创作出自己的作品!
但是很多人因为高昂的硬件和繁琐的安装对它望而却步。
腾讯云的高性能应用服务 HAI (Hyper Application Inventor)是一款专门为AI和科学计算设计的GPU应用服务产品。来看看如何利用HAI快速部署一个Stable Diffusion WebUI,实现AI绘画自由哈。
文章目录
- 🎁一、关于活动
- 📋前言
- 腾讯云高性能应用服务HAI
- 腾讯云Cloud Studio
- Stable Diffusion
- 👉二、开始体验
- 2.1 申请高性能应用服务 HAI
- 2.2 HAI控制台 配置StableDiffusion WebUI
- **如果不使用了,在`更多`-> `销毁` 以免产生费用**
- 2.3 使用HAI部署的 **StableDiffusionWebUI** 进行AI绘画
- 2.4 StableDiffusion API 服务
- 2.4.1 启用 **StableDiffusion API** 接口使用指南
- 2.4.2 向 **StableDiffusion API** 发送请求
- 2. 5 基于 [Cloud Studio](https://cloud.tencent.com/product/cloudstudio)构建的Web应用
- 2.5.1 快速开发核心功能
- 2.5.2 搭建完成,快速启动Web页面并测试
- 2.6 清理资源 及 销毁服务
- 2.7 使用HAI部署的 ChatGLM2-6B 快速进行AI对话实验
- 🌟三、Stable Diffusion 调参基础
- 3.1 模型选择
- 3.2 Stable Diffusion 模型
- 3.3 常用参数介绍
- 3.4 Sampling steps 迭代步数
- 3.5 Samplers 采样器
- 3.6 CFG Scale 提示词相关性
- 3.7 注意尺寸
- 3.8 Highres. fix 高清修复
- 3.9 Batch Count 与 Batch Size
- 3.10 随机种子
- 3.11 Denoising strength 降噪强度
- 📝 四、总结及建议
- 五、InsCode AI 创作助手
🎁一、关于活动

本次活动是由腾讯云和CSDN联合推出的开发者技术实践活动,旨在通过技术交流直播、动手实验、有奖征文等形式,为参与者提供深入沉浸式体验腾讯云高性能应用服务HAI的机会。活动将涵盖多个应用场景,无论您是技术新手还是经验丰富的开发者,我们都相信您将从中获得宝贵的技术知识和经验。
在活动中,参与者只需完成各个环节的任务,便有机会参与AIGC创作抽奖、优秀博文的评选,并获取相应的积分,进而参加最终的积分排行榜,赢取丰厚的活动礼品。我们希望通过这些奖励措施,鼓励大家积极参与活动,深入了解和学习腾讯云高性能应用服务HAI。
活动地址: https://marketing.csdn.net/p/b18dedb1166a0d94583db1877e49b039

📋前言
在体验和试用腾讯云高性能应用服务HAI之前,我们首先先认识一下高性能应用服务 HAI | Cloud Studio和 Stable Diffusion(简称 SD)
腾讯云高性能应用服务HAI
腾讯云的高性能应用服务 HAI (Hyper Application Inventor)是一款专门为AI和科学计算设计的GPU应用服务产品。它提供了即插即用的澎湃算力和常见环境,旨在帮助中小企业和开发者快速部署LLM、AI作画、数据科学等高性能应用。
以下是HAI的主要特点:
-
智能选型:根据用户的应用需求,智能匹配并推选出最适合的GPU算力资源,确保在数据科学、LLM、AI作画等高性能应用中获得最佳性价比。
-
一键部署:用户可以在几分钟内自动构建如StableDiffusion、ChatGLM等热门模型的应用环境。
-
可视化界面:为开发者提供了一个直观的图形界面,大大降低了AI研究的调试复杂度。支持jupyterlab、webui等多种算力连接方式,使AI研究和创新变得更加轻松。
-
即开即用:无需复杂的配置,用户即可享受即开即用的GPU云服务体验。
-
应用场景丰富:除了上述的应用外,HAI还可以广泛应用于数据科学、机器学习等领域,为用户提供了一片无限可能的高性能应用领域。
腾讯云Cloud Studio
腾讯云 Cloud Studio 是腾讯公司推出的一款集成开发环境(IDE),为开发者提供了一个能够随时随地进行工作的平台,它融合了云端编译、运行、调试、发布等功能,极大地方便了开发者的工作流程。开发者可以在浏览器中轻松地编写、运行和调试代码,同时实现代码的自动保存、版本控制和协同开发等功能。腾讯云 Cloud Studio 支持多种编程语言和框架,包括 JavaScript、Python、Java、C++、Node.js 等,满足不同开发者的需求。
腾讯云 Cloud Studio 功能特点
- 云端开发:用户无需安装本地开发环境,只需通过浏览器即可直接访问腾讯云 Cloud Studio,实现云端开发。
- 多种开发语言支持:腾讯云 Cloud Studio 支持多种编程语言,包括 Java、Python、Node.js、PHP 等,满足不同用户的需求。
- 高效团队协作:提供团队开发功能,支持多人协同编程,便于团队成员之间的协作与沟通。
- 智能代码补全:通过自然语言处理和机器学习技术,实现智能代码补全,提高编码效率。
- 实时调试与测试:具备实时调试和测试功能,开发者可以快速定位和解决问题,提高开发质量。
- 部署与发布:腾讯云 Cloud Studio 提供一键部署功能,用户可以将开发的应用程序快速部署到腾讯云服务器上,实现应用的发布
- 多版本控制:支持 Git、SVN 等版本控制工具,便于团队进行代码管理和版本控制。
Stable Diffusion
Stable Diffusion是一个文本到图像的潜在扩散模型,它使用潜在空间采样来模拟图像生成的扩散过程。这种模型基于深度学习技术,经过训练可以逐步对随机高斯噪声进行去噪以获得感兴趣的样本,例如生成图像。
Stable Diffusion 文字生成图片如何写提示词
接下来通过这篇文章带大家一起了解这款来自 腾讯云的 GPU应用服务。除此之外,还可以通过博主的这篇文章了解CSDN 的 AI 创作助手,不一样的创作体验。
👉二、开始体验
2.1 申请高性能应用服务 HAI
官方操作说明文档
① . 点击链接进入 高性能应用服务 HAI 申请体验资格
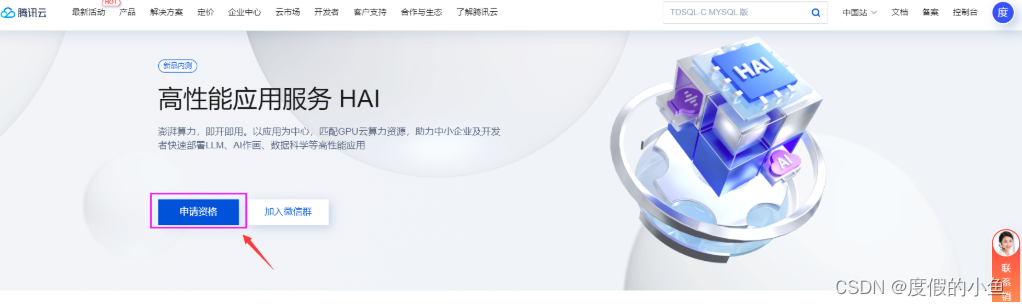
② . 等待审核通过后,进入 高性能应用服务 HAI
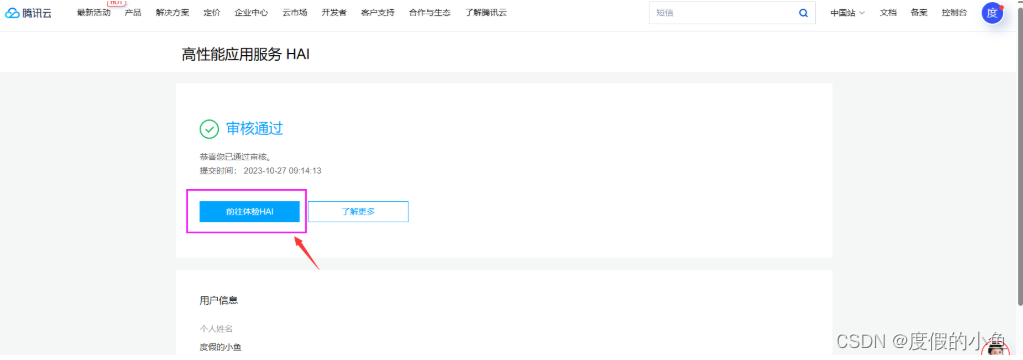
③ . 点击前往体验HAI,登录 高性能应用服务 HAI 控制台
2.2 HAI控制台 配置StableDiffusion WebUI
操作步骤大概以下几步:
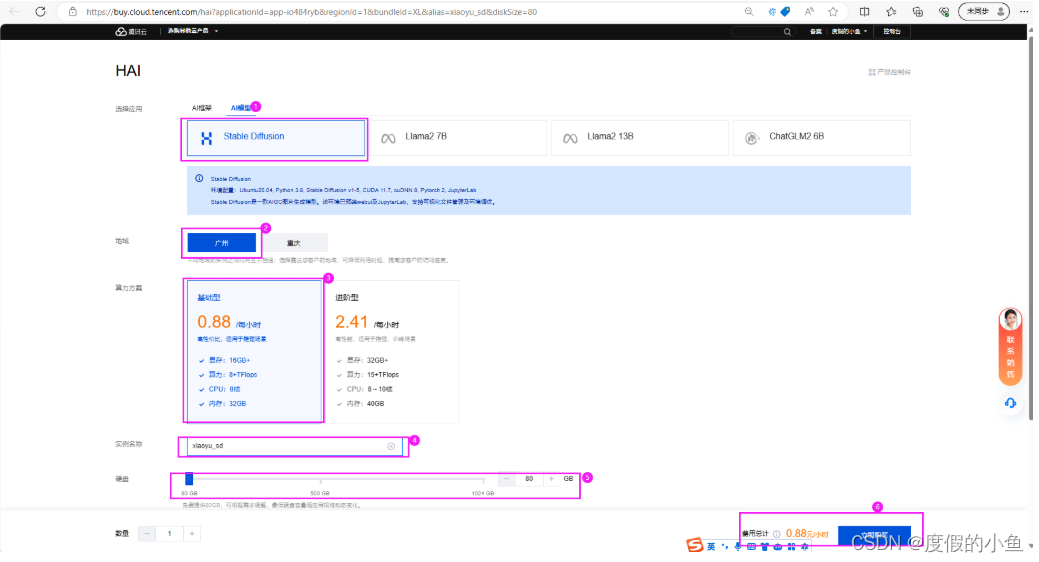
点击 新建 选择 AI模型(Stable Diffusion),参照下图进行配置即可
等待创建完成 (预计等待3-8分钟,等待时间不计费)
创建完成,查看状态为
运行中公网IP 后续会使用到进入 StableDiffusionWebUI
使用 高性能应用服务HAI 部署的 StableDiffusionWebUI 配置简体中文语言包

- 点击 新建 选择 AI模型(Stable Diffusion),参照下图进行配置即可
- 等待创建完成 (预计等待3-8分钟,等待时间不计费)
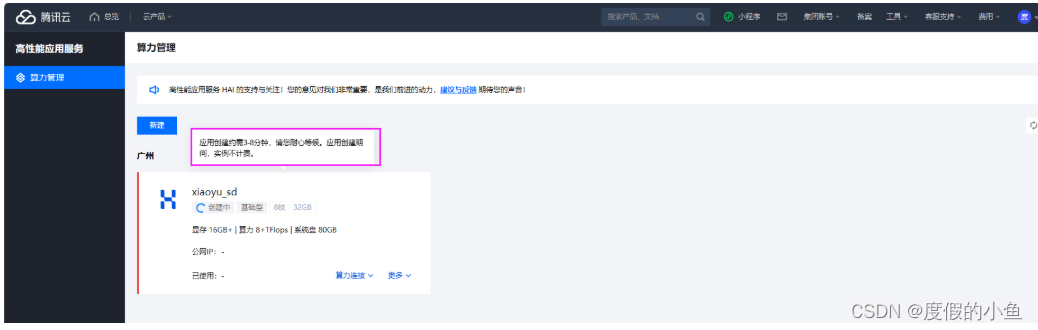
- 创建完成,查看状态为
运行中公网IP 后续会使用到
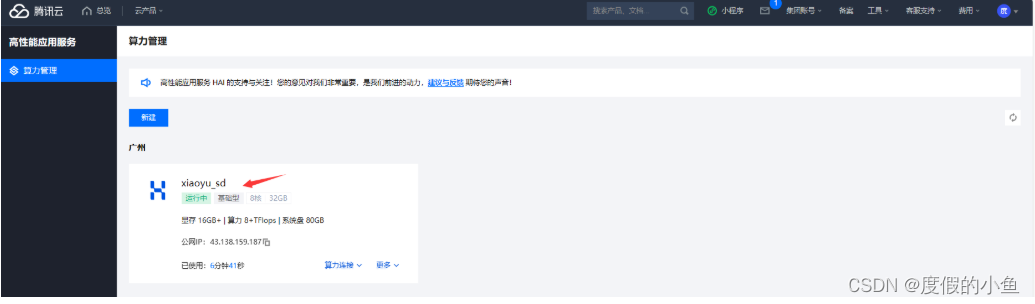
如果不使用了,在更多-> 销毁 以免产生费用

启动 高性能应用服务HAI 配置的 StableDiffusionWebUI 进行文生图模型推理
- 进入 StableDiffusionWebUI
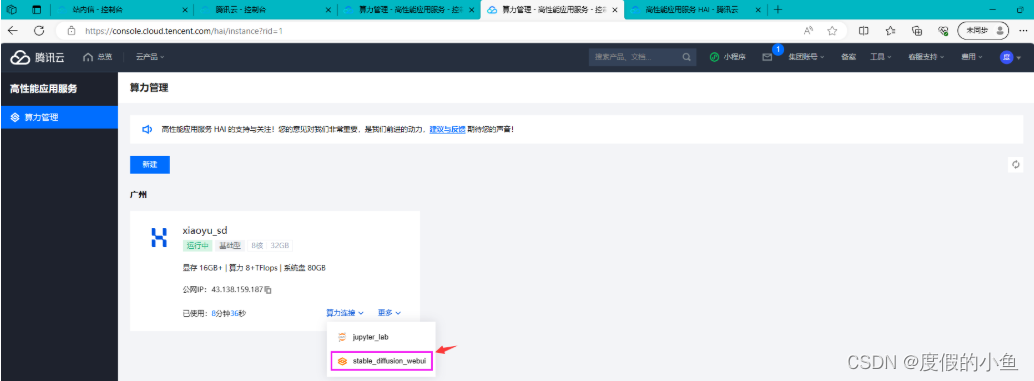
- 使用 高性能应用服务HAI 部署的 StableDiffusionWebUI 配置简体中文语言包
(1) 进入 StableDiffusionWebUI
(2)此扩展可以在 **Extension** 选项卡里面通过加载官方插件列表直接安装
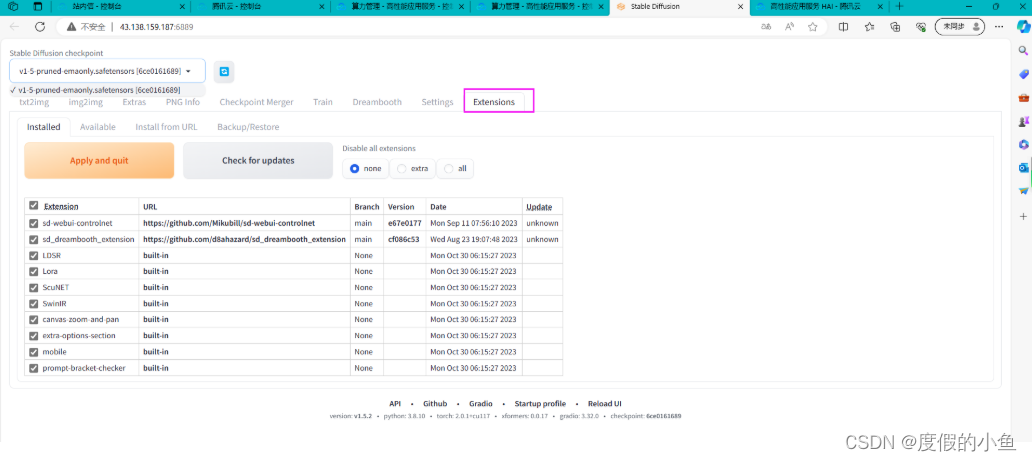
点击 Extension 选项卡,选择 Avaliable 子选项卡
取消勾选 localization ,再把其他勾上,然后点击 Load form,如下图,加载插件时,请耐心等待
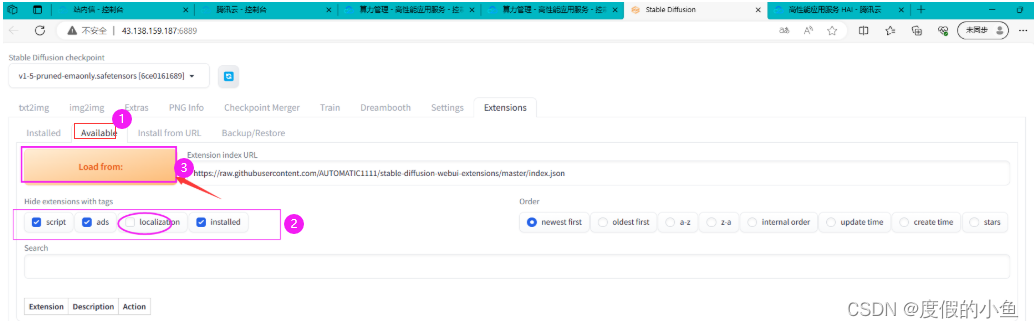
(3)在输入框中查找插件关键字: zh_CN 点击install 进行安装
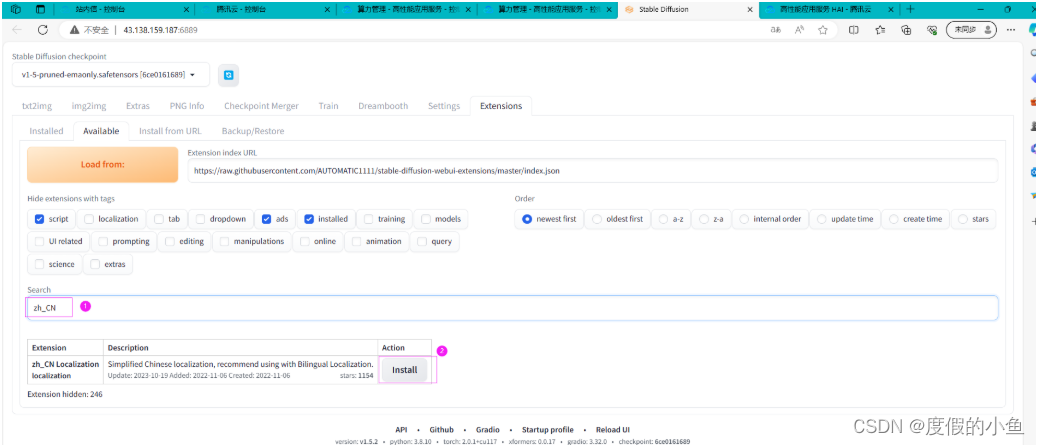
(4)确认插件安装完成后,重启服务(Reload UI)
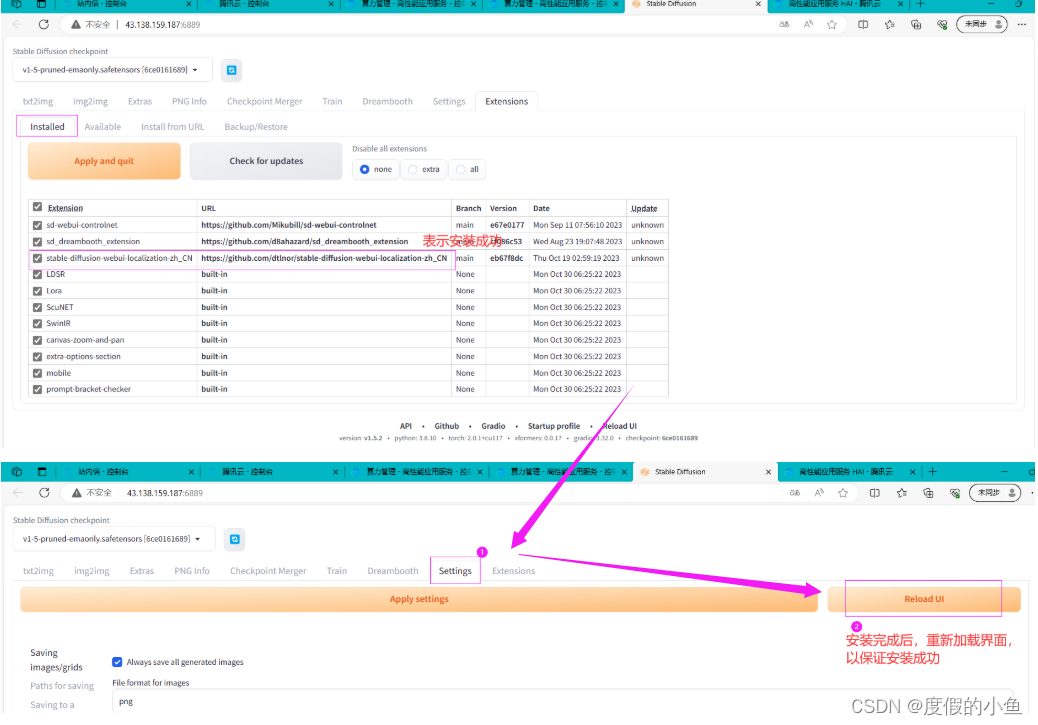
(5)重启后,选择 Settings 中 User Interface 选项,下拉选择语言 zh_CN ,点击 Apply settings 保存设置 ,并 Reload UI 重启服务。
这里我虽然安装成功了,但重启服务 好像中文插件没起效果,可以忽略不计
2.3 使用HAI部署的 StableDiffusionWebUI 进行AI绘画
使用 高性能应用服务HAI 部署的 StableDiffusionWebUI 快速进行AI绘画
注意:提示词(Prompt)越多,AI 绘图结果会更加精准。另外,目前中文提示词的效果不好,还得使用英文提示词。
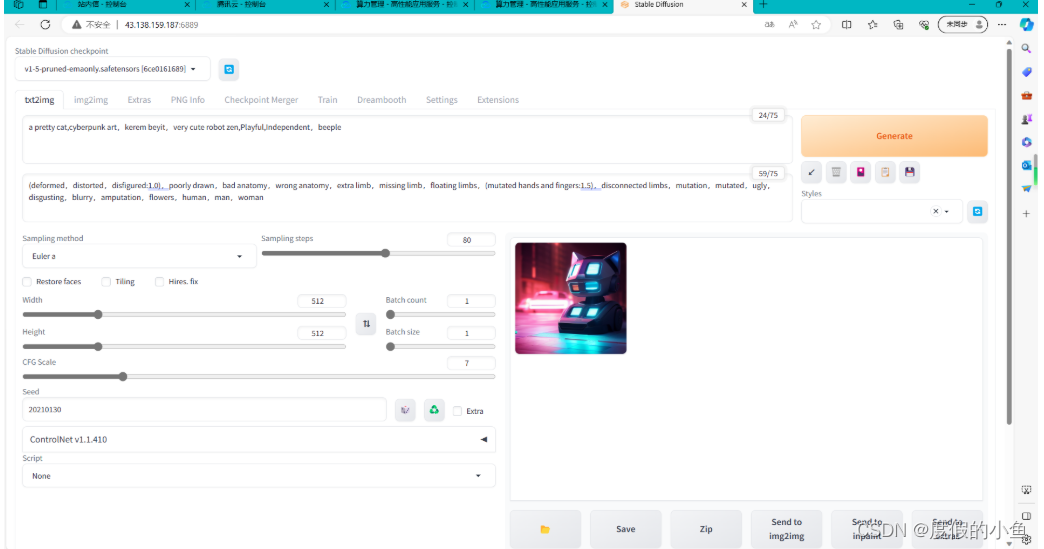
接下来我们使用 StableDiffusionWebUI 生成一张猫咪图片,配置以下参数后,点击 “生成” 即可
| 参数名 | 描述 | 值 |
|---|---|---|
| 提示词 | 主要描述图像,包括内容风格等信息,原始的webui会对这个地方有字数的限制,可以安装一些插件突破字数的限制 | a pretty cat,cyberpunk art,kerem beyit,very cute robot zen,Playful,Independent,beeple |
| 反向提示词 | 为了提供给模型,我们不需要的风格 | (deformed,distorted,disfigured:1.0),poorly drawn,bad anatomy,wrong anatomy,extra limb,missing limb,floating limbs,(mutated hands and fingers:1.5),disconnected limbs,mutation,mutated,ugly,disgusting,blurry,amputation,flowers,human,man,woman |
| 提示词相关性(CFG scale) | 分类器自由引导尺度——图像与提示符的一致程度——越低的值产生的结果越有创意,数值越大成图越贴近描述文本。一般设置为7 | 7 |
| 采样方法(Sampling method) | 采样模式,即扩散算法的去噪声采样模式会影响其效果,不同的采样模式的结果会有很大差异,一般是默认选择euler,具体效果我也在逐步尝试中。 | Euler a |
| 采样迭代步数(Sampling steps) | 在使用扩散模型生成图片时所进行的迭代步骤。每经过一次迭代,AI就有更多的机会去比对prompt和当前结果,并作出相应的调整。需要注意的是,更高的迭代步数会消耗更多的计算时间和成本,但并不意味着一定会得到更好的结果。然而,如果迭代步数过少,一般不少于50,则图像质量肯定会下降 | 80 |
| 随机种子(Seed) | 随机数种子,生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。不懂的话,用随机的即可 | 1791574510 |
配置并生成如下图:
2.4 StableDiffusion API 服务
高性能应用服务HAI 快速为开发者提供 StableDiffusion API 服务
操作步骤大概以下几步:
- 进入 jupyter_lab 操作界面
- 选择使用 终端命令行 操作
- 添加 高性能应用服务HAI 的端口配置,使外部网络能够顺利地访问该服务器提供的API服务
- 进入 jupyter_lab 操作界面
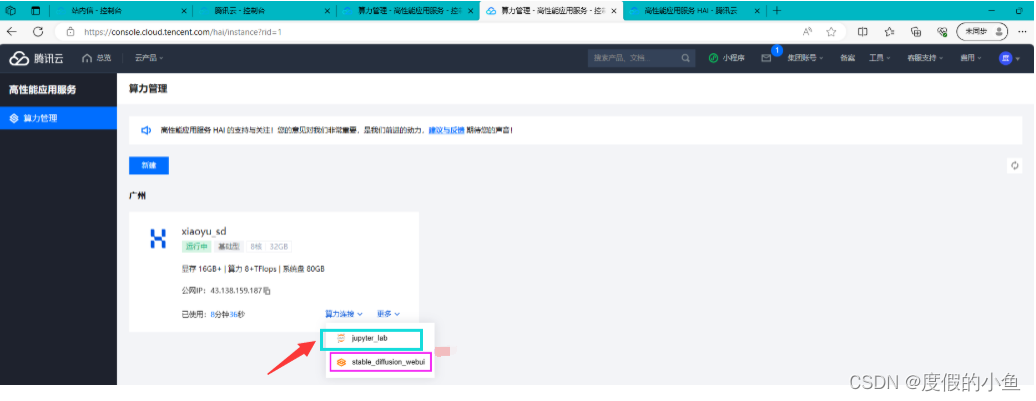
- 选择使用 终端命令行 操作
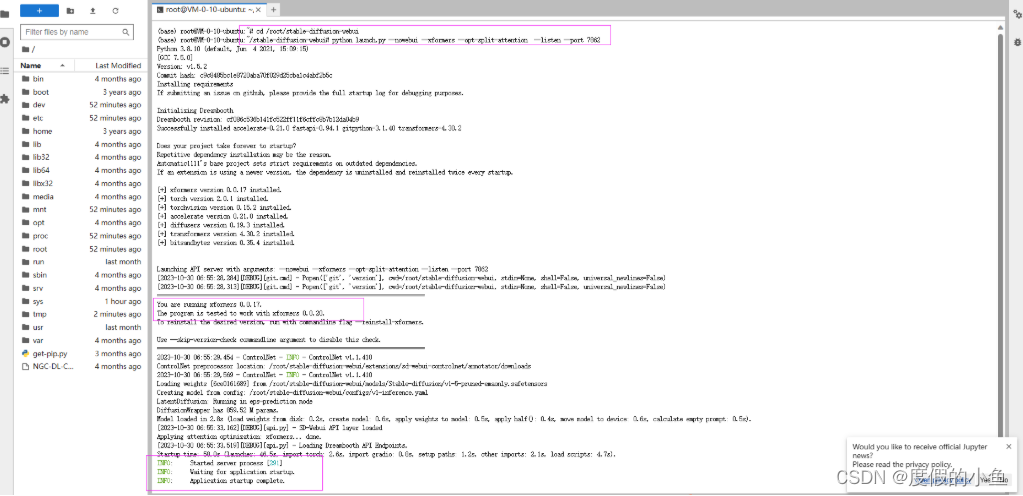
依次输入代码
cd /root/stable-diffusion-webui
python launch.py --nowebui --xformers --opt-split-attention --listen --port 7862
命令参数描述:
| 命令 | 描述 |
|---|---|
| –nowebui | 以 API 模式启动 |
| –xformers | 使用xformers库。极大地改善了内存消耗和速度。 |
| –opt-split-attention | Cross attention layer optimization 优化显着减少了内存使用,几乎没有成本(一些报告改进了性能)。黑魔法。默认情况下torch.cuda,包括 NVidia 和 AMD 卡。 |
| –listen | 默认启动绑定的 ip 是 127.0.0.1,只能是你自己电脑可以访问 webui,如果你想让同个局域网的人都可以访问的话,可以配置该参数(会自动绑定 0.0.0.0 ip)。 |
| –port | 默认端口是 7860,如果想换个端口,可以配置该参数,例如:–port 7862 |
| –gradio-auth username:password | 如果你希望给 webui 设置登录密码,可以配置该参数,例如:–gradio-auth GitLqr:123456。 |
- 添加 高性能应用服务HAI 的端口配置,使外部网络能够顺利地访问该服务器提供的API服务
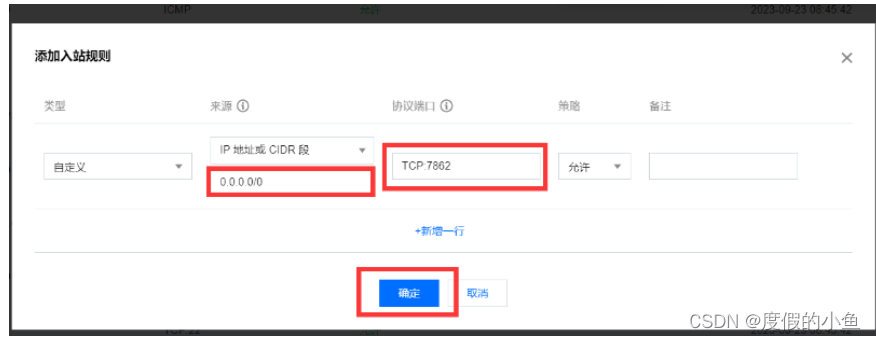
添加入站规则:
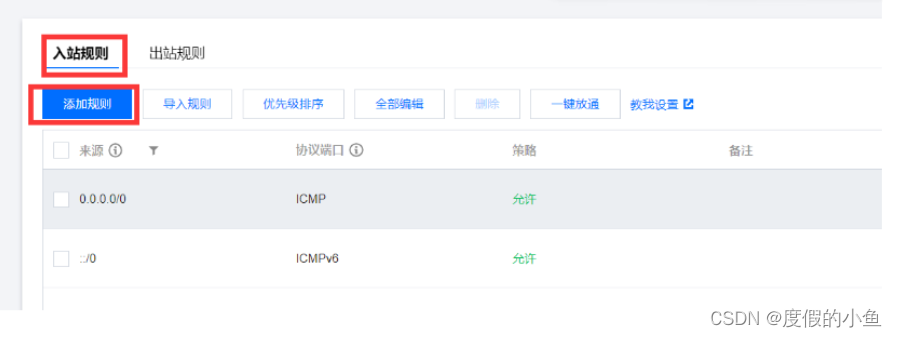
配置参考如下:
来源:0.0.0.0/0 协议端口:TCP:7862 (根据您配置的端口填写)
2.4.1 启用 StableDiffusion API 接口使用指南
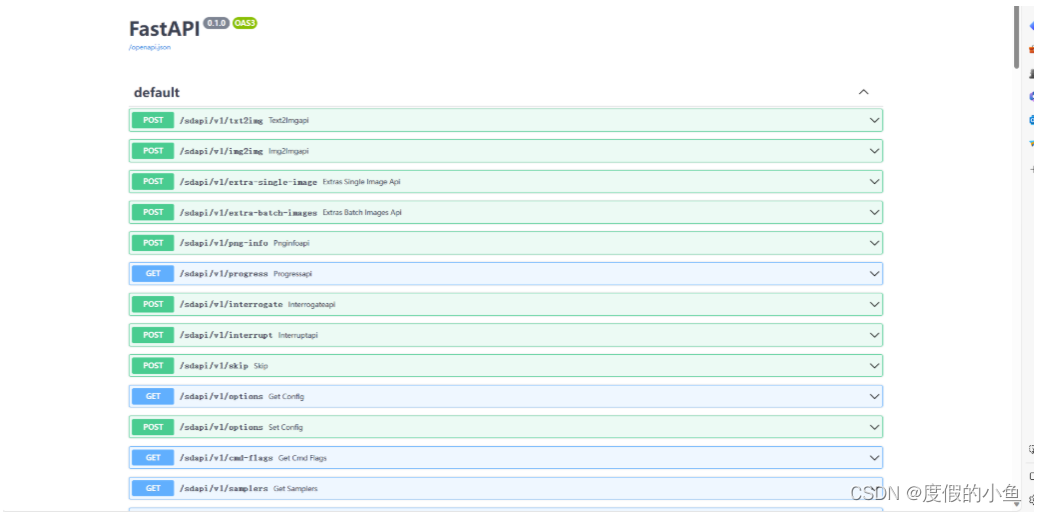
配置完成后输入 服务器IP地址:端口号/docs 可查看相关的 API 接口 swagger 使用指南
官方提供的api常用的有几个:
/sdapi/v1/txt2img 文字生图 POST
/sdapi/v1/img2img 图片生图 POST
/sdapi/v1/options 获取设置 GET | 更新设置 POST(可用来更新远端的模型)
/sdapi/v1/sd-models 获取所有的模型 GET
配置完成后在浏览器里输入地址:例如http://43.138.159.187:7862/docs看到如下图
查看相关接口示例 ( /sdapi/v1/txt2img ) :
常用输入如下
{"denoising_strength": 0,"prompt": "puppy dogs","negative_prompt": "","seed": -1,"batch_size": 2,"n_iter": 1,"steps": 50,"cfg_scale": 7,"width": 512,"height": 512,"restore_faces": false,"tiling": false,"sampler_index": "Euler"
}
可复制以上参数到 Request body 中
| 名称 | 说明 |
|---|---|
| prompt | 提示词 |
| negative_prompt | 反向提示词 |
| seed | 种子,随机数 |
| batch_size | 每次张数 |
| n_iter | 生成批次 |
| steps | 生成步数 |
| cfg_scale | 关键词相关性 |
| width | 宽度 |
| height | 高度 |
| restore_faces | 脸部修复 |
| tiling | 可平铺 |
| sampler_index | 采样方法 |
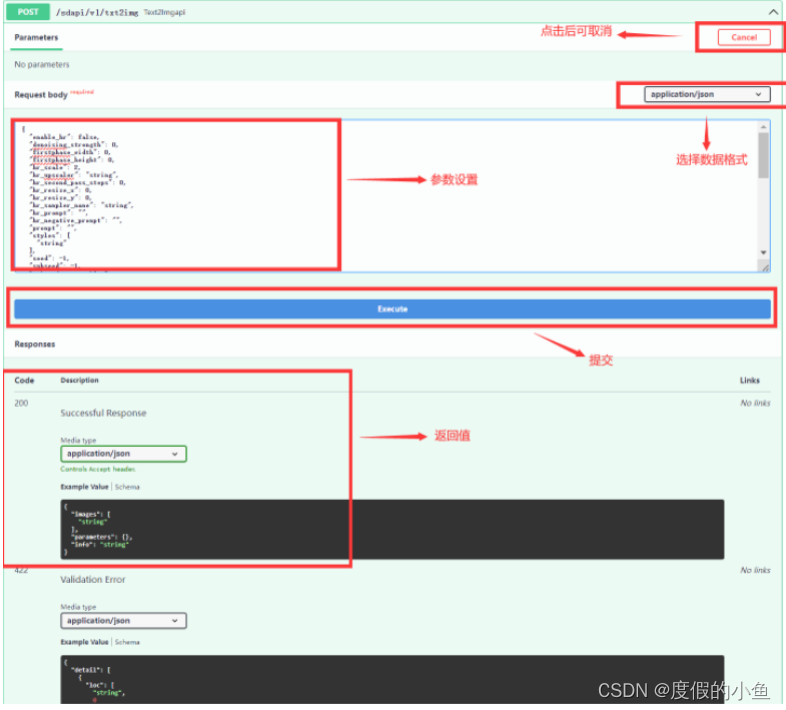
复制以上参数到 Request body 中后 点击 execute
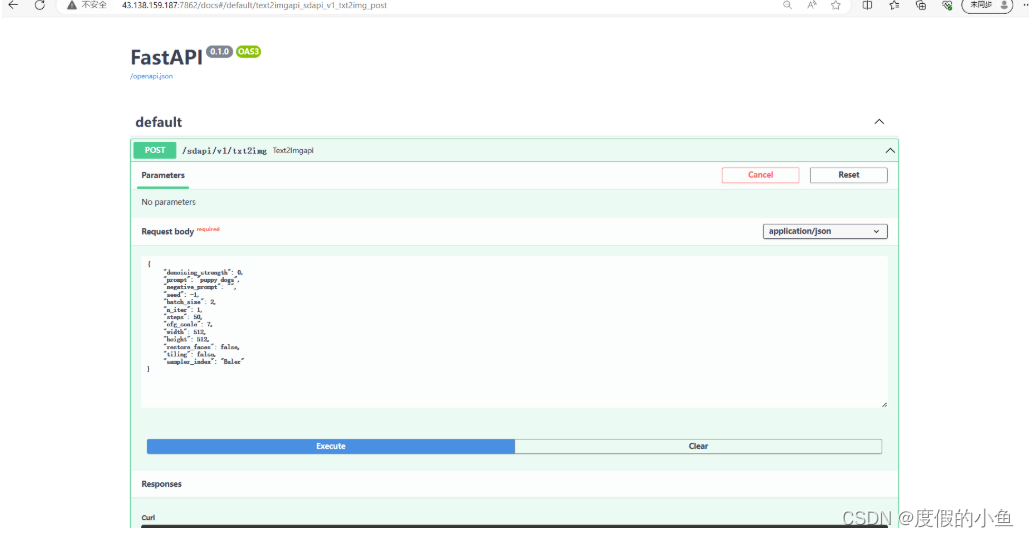
请求API接口成功截图如下:
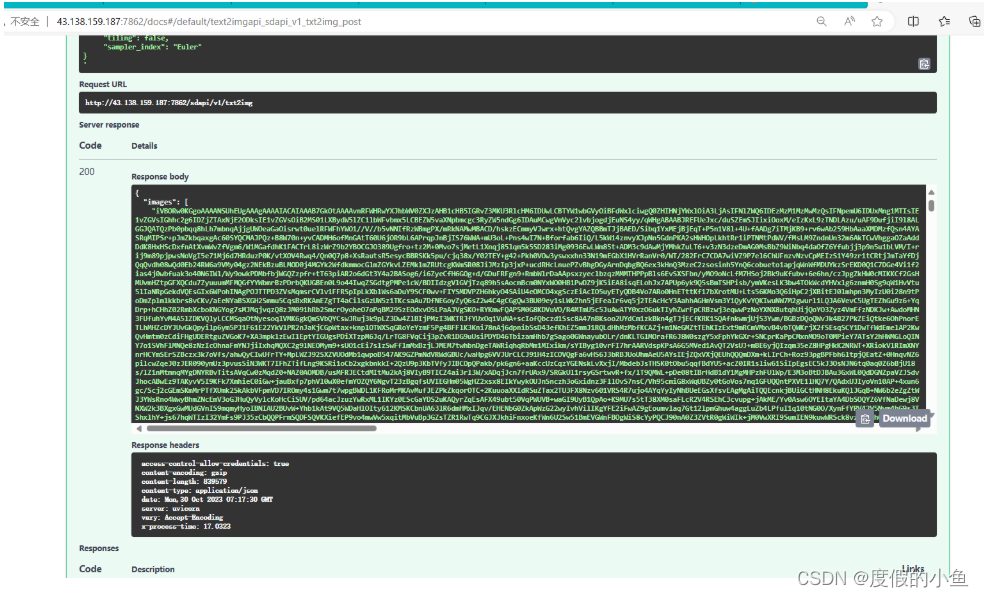
返回的格式如下:
{"images": [...],// 这里是一个base64格式的字符串数组,根据你请求的图片数量而定"parameters": { ... },//此处为你输入的body "info": "{...}"// 返回的图片的信息
}2.4.2 向 StableDiffusion API 发送请求
使用 python 向 高性能应用服务HAI 提供的 StableDiffusion API 发送请求
以下演示使用 python 如何向 StableDiffusion API 发出请求。 我们希望向应用程序的 txt2img(即“文本到图像”)API 发送 POST 请求以简单地生成图像。
我们将使用 requests 包,所以如果你还没有安装它,请使用安装脚本:
pip install requests
我们可以发送一个包含提示的请求作为一个简单的字符串。 服务器将返回一个图像作为 base64 编码的 PNG 文件,我们需要对其进行解码。 要解码 base64 图像,我们只需使用base64.b64decode(b64_image)。 以下使用python作为脚本代码测试:
import json
import base64
import requestsyour_ip = '0.0.0.0' # HAI服务器IP地址
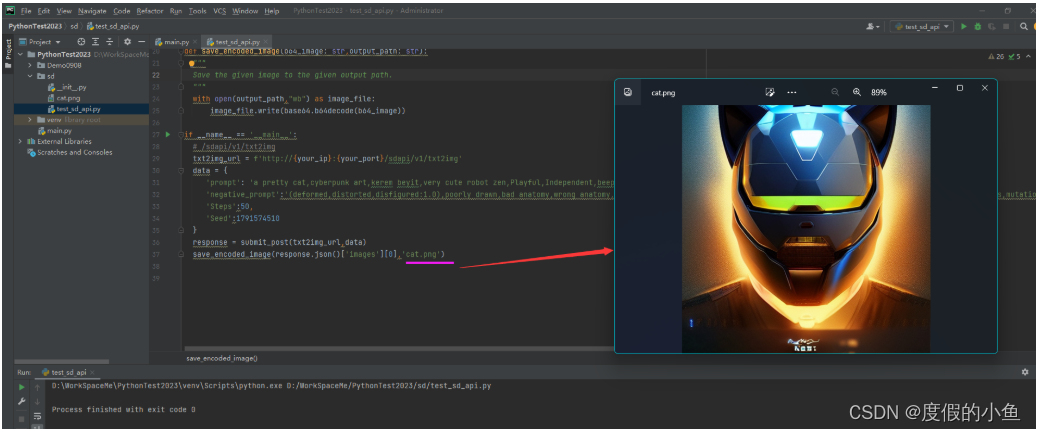
your_port = 7862 # SD api 监听的端口def submit_post(url: str,data: dict):"""Submit a POST request to the given URL with the given data."""return requests.post(url,data=json.dumps(data))def save_encoded_image(b64_image: str,output_path: str):"""Save the given image to the given output path."""with open(output_path,"wb") as image_file:image_file.write(base64.b64decode(b64_image))if __name__ == '__main__':# /sdapi/v1/txt2imgtxt2img_url = f'http://{your_ip}:{your_port}/sdapi/v1/txt2img'data = {'prompt': 'a pretty cat,cyberpunk art,kerem beyit,very cute robot zen,Playful,Independent,beeple |','negative_prompt':'(deformed,distorted,disfigured:1.0),poorly drawn,bad anatomy,wrong anatomy,extra limb,missing limb,floating limbs,(mutated hands and fingers:1.5),disconnected limbs,mutation,mutated,ugly,disgusting,blurry,amputation,flowers,human,man,woman','Steps':50,'Seed':1791574510}response = submit_post(txt2img_url,data)save_encoded_image(response.json()['images'][0],'cat.png')这里我使用Pycharm工具, python 向 StableDiffusion API 发出请求
请记住,你的结果会与我的不同。 如果遇到问题,请仔细检查运行 StableDiffusion API 应用程序的终端的输出。 可能是服务器尚未完成。 如果您遇到“404 Not Found”之类的问题,请仔细检查 URL 是否输入正确并指向正确的地址(例如 127.0.0.1)。
调用代码及图片生成截图:
2. 5 基于 Cloud Studio构建的Web应用
使用 高性能应用服务 HAI 搭建的 StableDiffusion API 作为服务端快速动手开发一个基于 Cloud Studio构建的Web应用
操作步骤大概以下几步:
点击链接进入 腾讯云 腾讯云链接 登录
在搜索框输入 Cloud Studio ,点击搜索
点击立即使用
选择 开发空间 下的 手动创建 并 立即创建
创建成功,并进入工作空间,1分钟内快速完成空间创建
为了您有更高效的产品体验,前端界面已完成,请下载压缩包后上传至工作空间并解压压缩包
开启web服务并查看需调试的页面
-
点击链接进入 腾讯云 腾讯云链接 登录
-
在搜索框输入 Cloud Studio ,点击搜索
- 点击立即使用
- 选择 开发空间 下的 手动创建 并 立即创建
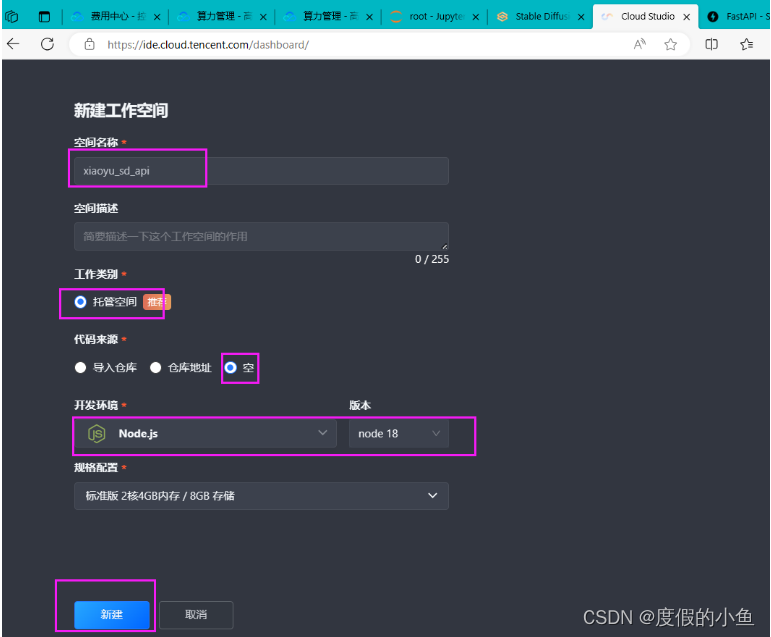
- 创建成功,并进入工作空间,1分钟内快速完成空间创建
空间(workspace)创建成功:
- 为了您有更高效的产品体验,前端界面已完成,请下载压缩包后上传至工作空间并解压压缩包
点击下载压缩包 : sd_api.zip
上传压缩包示意图:
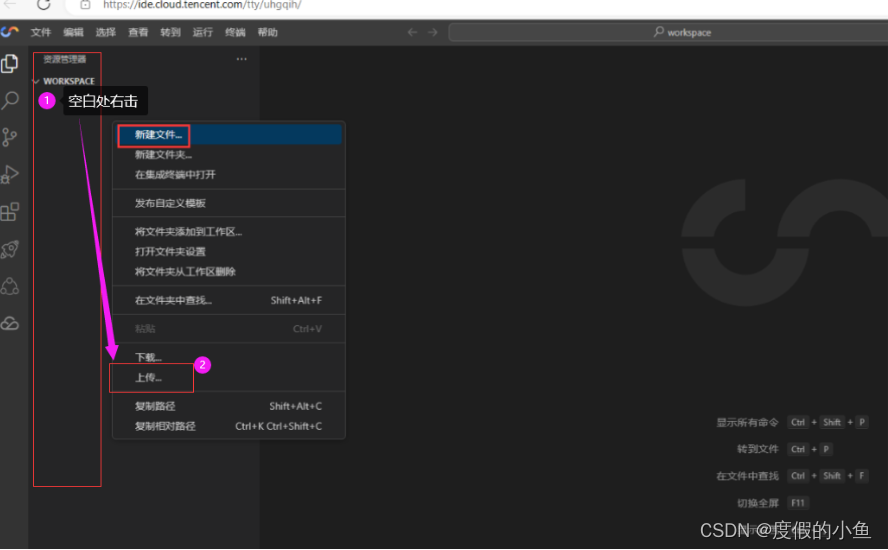
上传压缩包成功,终端操作解压压缩包:
输入解压命令 :
unzip sd_api.zip

- 开启web服务并查看需调试的页面
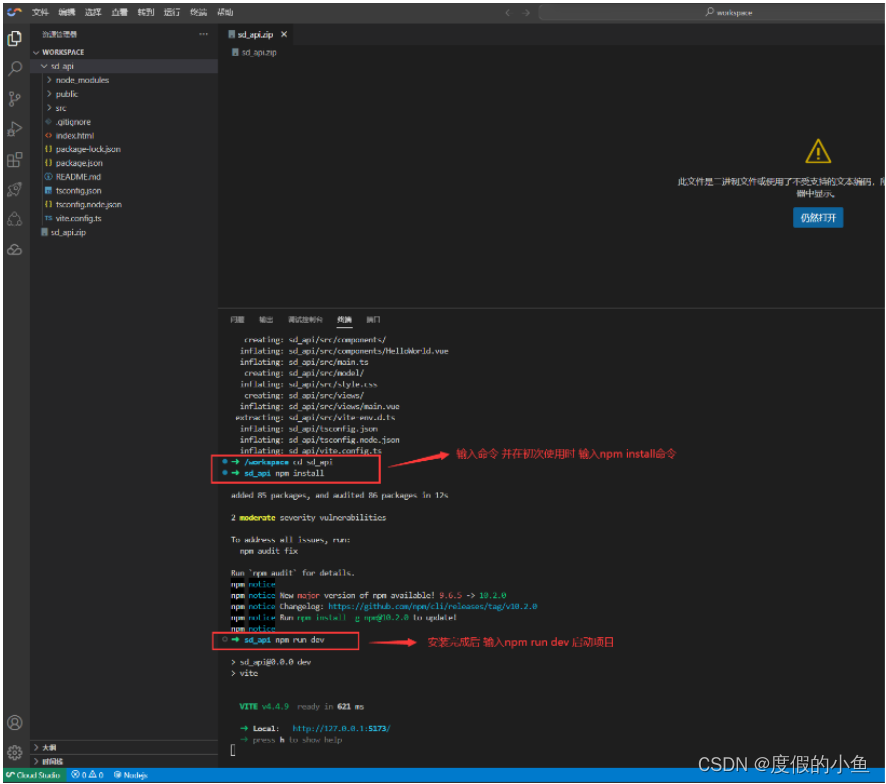
解压完成后,在终端窗口输入命令
cd sd_api #进入文件夹
npm install #安装依赖包
等待依赖完成安装后就可以启动Web项目了,输入命令:
npm run dev #启动web
进入项目内(sd_api)并安装依赖后启动Web项目截图:
2.5.1 快速开发核心功能
下面我们来开发项目的核心功能 :
操作步骤有以下几步:
- 在Vue项目下的 model 文件夹中创建一个名为 Txt2ImgModel.ts 的文件
- 同样,在Vue项目下的 model 文件夹中创建一个名为 ControlNetModel.ts 的文件
- 由于手动创建的环境中没有安装Vue插件,我们快速配置一个Vue的语言环境
- 下载代码文件:main.vue.zip进行修改
- 同时修改vue项目下的 vite.config 文件
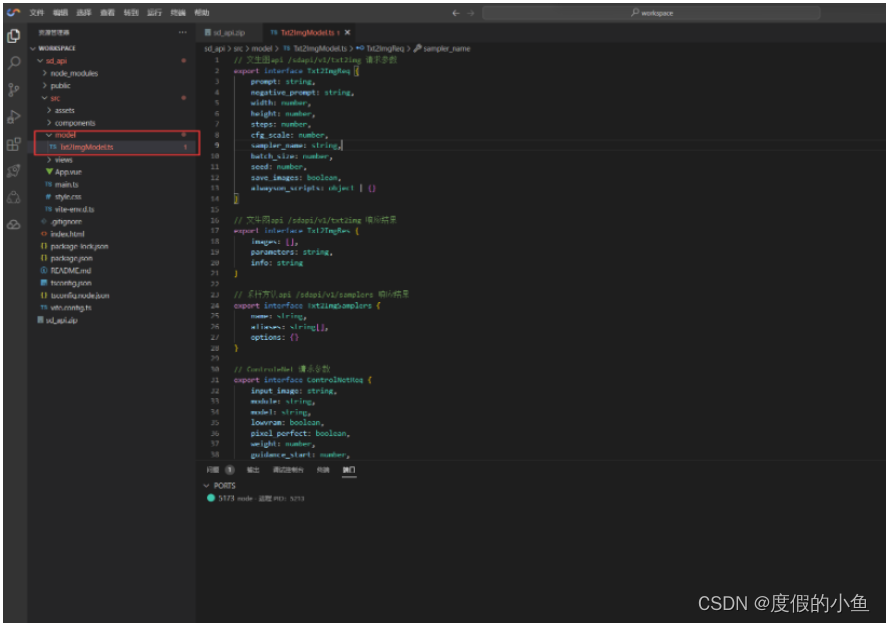
- 在Vue项目下的 model 文件夹中创建一个名为 Txt2ImgModel.ts 的文件,这个文件主要用于调用相关接口参数配置
// 文生图api /sdapi/v1/txt2img 请求参数
export interface Txt2ImgReq {prompt: string,negative_prompt: string,width: number,height: number,steps: number,cfg_scale: number,sampler_name: string,batch_size: number,seed: number,save_images: boolean,alwayson_scripts: object | {}
}// 文生图api /sdapi/v1/txt2img 响应结果
export interface Txt2ImgRes {images: [],parameters: string,info: string
}// 采样方法api /sdapi/v1/samplers 响应结果
export interface Txt2ImgSamplers {name: string,aliases: string[],options: {}
}// ControleNet 请求参数
export interface ControlNetReq {input_image: string,module: string,model: string,lowvram: boolean,pixel_perfect: boolean,weight: number,guidance_start: number,guidance_end: number,control_mode: number,resize_mode: number,processor_res: number,threshold_a: number,threshold_b: number
}import { useStorage } from '@vueuse/core'// 将所有组件的输入保存在浏览器的 localStorage 中,key为 txt2imgReqStorage
export const txt2imgReqStorage = useStorage<Txt2ImgReq>('txt2imgReq', {})// 将文生图调用结果图片保存在浏览器的 localStorage 中,key为 txt2img_imgs
export const txt2imgResultStorage = useStorage<string[]>('txt2img_imgs', [])
创建 model 文件夹中 Txt2ImgModel.ts 的截图:
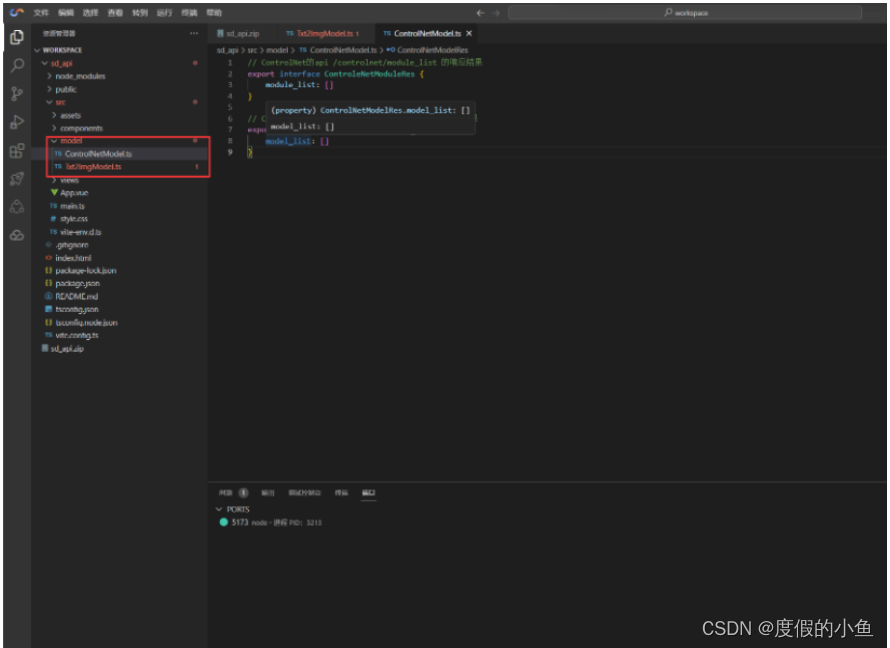
- 同样,在Vue项目下的 model 文件夹中创建一个名为 ControlNetModel.ts 的文件,这个文件主要用于添加 ControlNet 组件
// ControlNet的api /controlnet/module_list 的响应结果
export interface ControleNetModuleRes {module_list: []
}// ControlNet的api /controlnet/model_list 的响应结果
export interface ControlNetModelRes {model_list: []
}
创建 model 文件夹中 ControlNetModel.ts 的截图
- 由于手动创建的环境中没有安装Vue插件,我们快速配置一个Vue的语言环境,等待安装完成
安装完成后,下载附件 main.zip 解压后将 main.vue 文件覆盖至您项目下的 views 文件夹中的 main.vue 并保存,这个文件将用于数据绑定、图片渲染功能:
- 下载代码文件:main.vue.zip
view文件夹中的main.vue文件修改后截图:
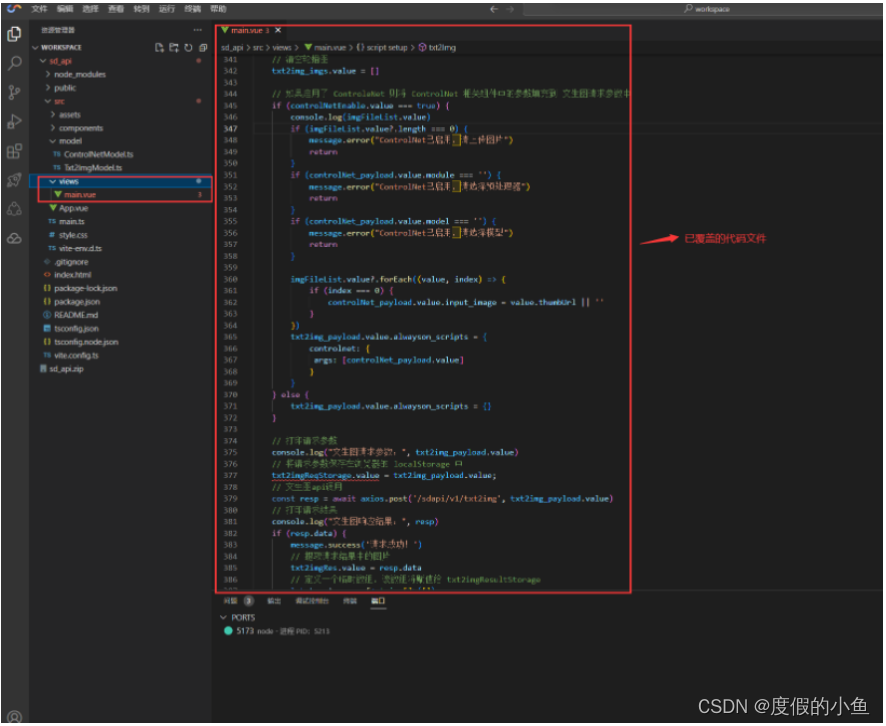
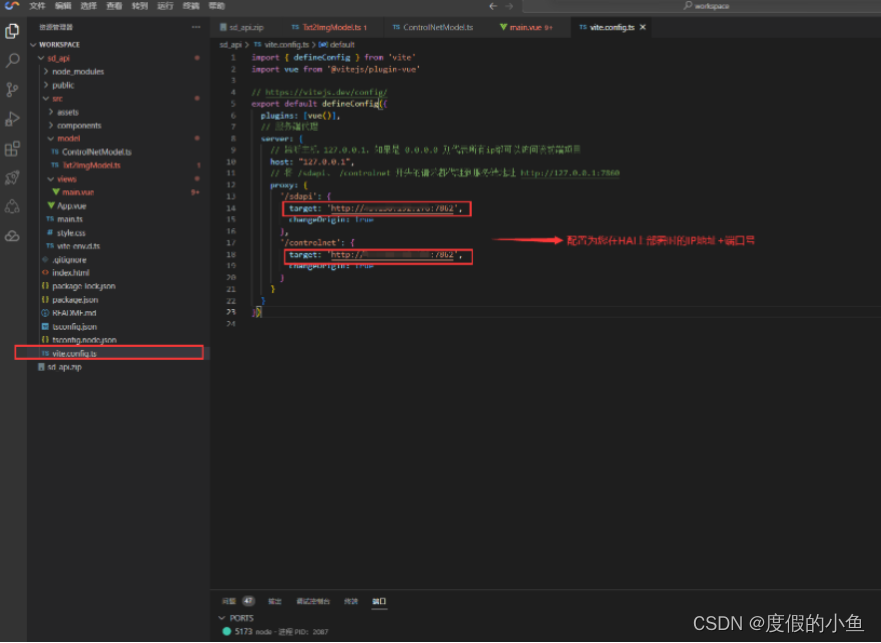
- 同时修改vue项目下的 vite.config 文件,配置信息修改为您部署在 高性能应用HAI服务器API 的相关信息:
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'// https://vitejs.dev/config/
export default defineConfig({plugins: [vue()],// 服务端代理server: {// 监听主机 127.0.0.1,如果是 0.0.0.0 则代表所有ip都可以访问该前端项目host: "127.0.0.1", //这里可不用管// 将 /sdapi、 /controlnet 开头的请求都代理到服务端地址 http://127.0.0.1:7862proxy: {'/sdapi': {target: 'http://your_ip:7862', //这里配置为您的服务端地址+端口changeOrigin: true},'/controlnet': {target: 'http://your_ip:7862', //这里配置为您的服务端地址+端口changeOrigin: true}}}
})修改vite.config文件:配置公网ip地址
保存文件后Web服务将自动重启:

2.5.2 搭建完成,快速启动Web页面并测试
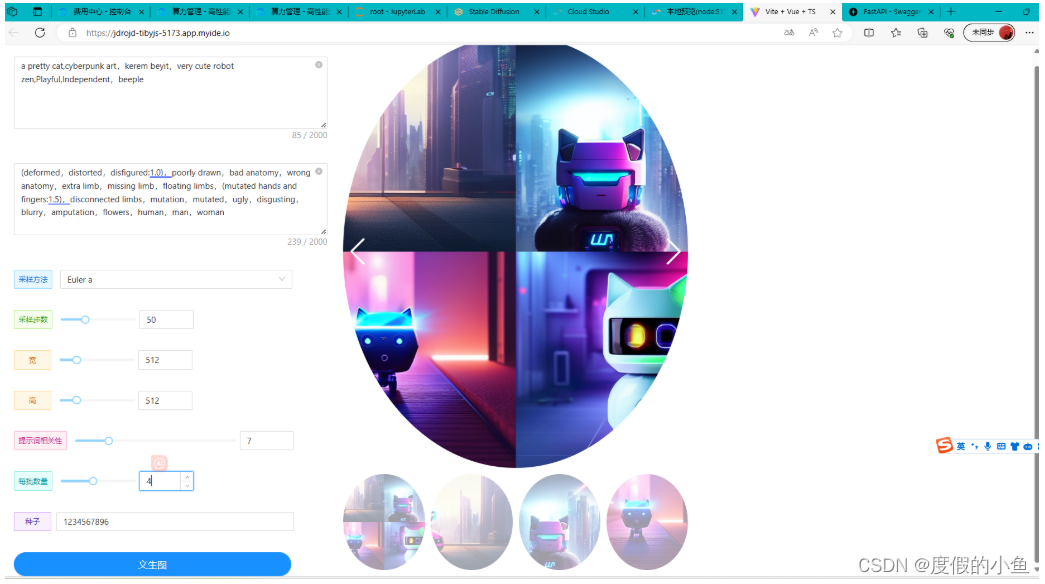
重新加载Web页面,并在相对应的输入框中填写对应的参数:
| 参数名 | 值 |
|---|---|
| 提示词 | a pretty cat,cyberpunk art,kerem beyit,very cute robot zen,Playful,Independent,beeple |
| 反向提示词 | (deformed,distorted,disfigured:1.0),poorly drawn,bad anatomy,wrong anatomy,extra limb,missing limb,floating limbs,(mutated hands and fingers:1.5),disconnected limbs,mutation,mutated,ugly,disgusting,blurry,amputation,flowers,human,man,woman |
| 提示词相关性(CFG scale) | 7 |
| 采样方法(Sampling method) | Euler a |
| 采样步数(Sampling steps) | 50 |
| 随机种子(Seed) | -1 |
| 每批次数量 | 3 |
前端页面展示效果-1(在浏览器中调试查看):
2.6 清理资源 及 销毁服务
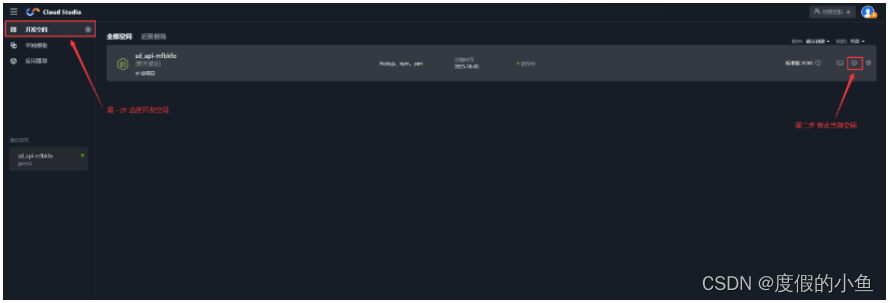
- 清理 Cloud Studio 中创建的工作空间
返回 开发空间-点击应用停止按钮-再点击 删除 按钮,释放空间
-
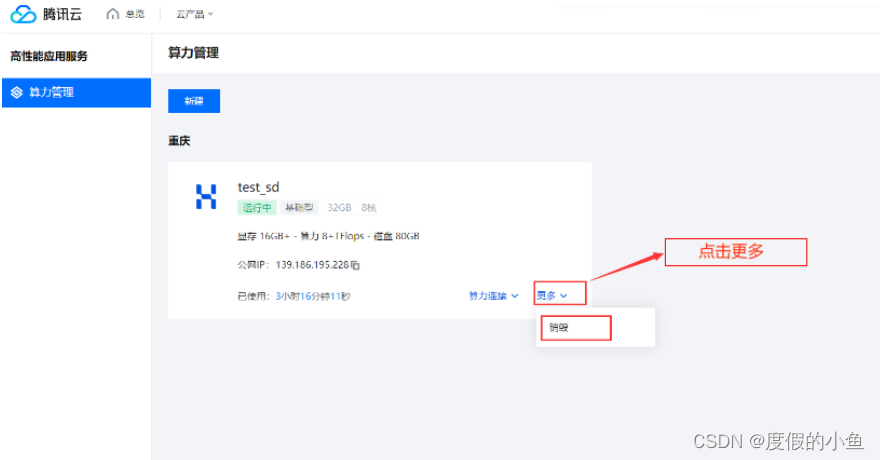
销毁 高性能应用服务HAI 创建的 StableDiffusion 服务
进入算力管理页面,点击销毁,选择确认即可销毁
2.7 使用HAI部署的 ChatGLM2-6B 快速进行AI对话实验
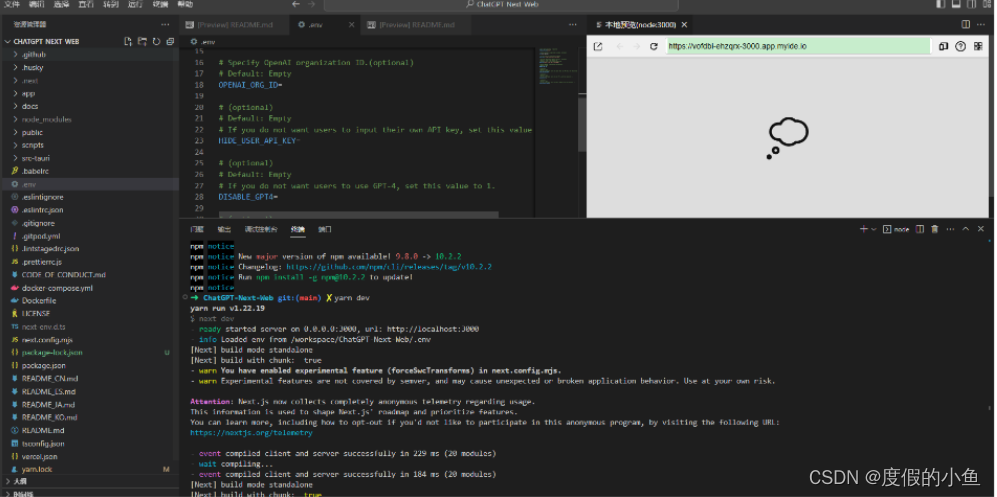
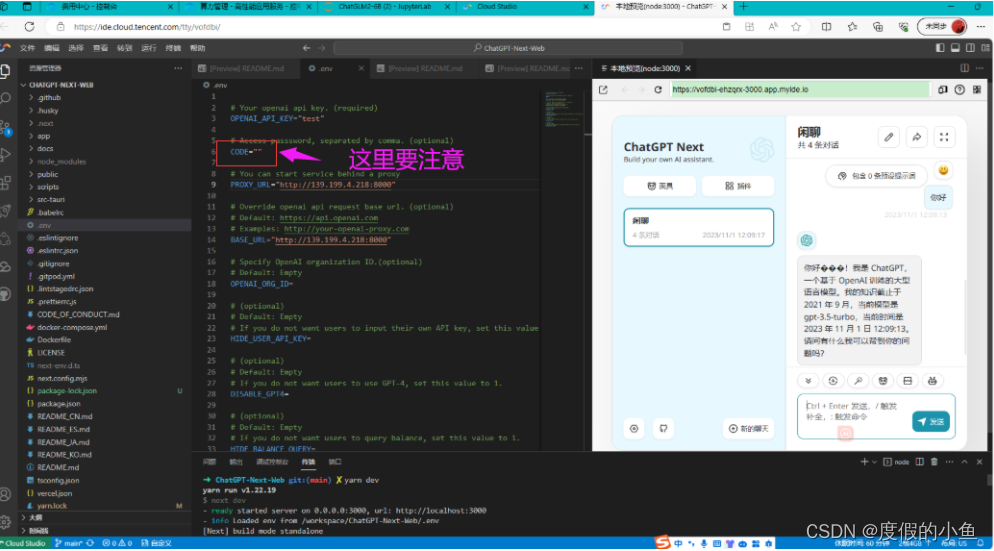
还可以体验一下基于HAI部署的 ChatGLM2-6B 快速进行AI对话实验,具体步骤可参考官方操作说明文档
实验的时候有个踩坑点
这个配置这个地方 要么去掉 要么就是像这样子 CODE=" "
🌟三、Stable Diffusion 调参基础
3.1 模型选择
模型使用的数据集和标签对于效果影响非常重要,在使用之前要先了解数据来源。
3.2 Stable Diffusion 模型
Stable Diffusion 模型适用于生成与照片、艺术品类似的图像。基于 LAION 数据集训练。
3.3 常用参数介绍
- Prompt(提示词):对你想要生成的东西进行文字描述。
- Negative prompt(反向提示词):用文字描述你不希望在图像中出现的东西。
- Sampling Steps(采样步数):扩散模型的工作方式是从随机高斯噪声向符合提示的图像迈出小步。这样的步骤应该有多少个。更多的步骤意味着从噪声到图像的更小、更精确的步骤。增加这一点直接增加了生成图像所需的时间。回报递减,取决于采样器。
- Sampling method(采样器):使用哪种采样器。Euler a(ancestral 的简称)以较少的步数产生很大的多样性,但很难做小的调整。随着步数的增加,非 ancestral 采样器都会产生基本相同的图像,如果你不确定的话,可以使用 LMS。
- Batch count/n_iter:每次生成图像的组数。一次运行生成图像的数量为 Batch count * Batch size。
- Batch size:同时生成多少个图像。增加这个值可以提高性能,但你也需要更多的 VRAM。图像总数是这个值乘以批次数。除 4090 等高级显卡以外通常保持为 1。
- CFG Scale(无分类指导规模):图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示(根据模型),但它也在一定程度上降低了图像质量。可以用更多的采样步骤来抵消。
- Width:图像的宽度,像素。要增加这个值,你需要更多的显存。大尺度的图像一致性会随着分辨率的提高而变差(模型是在 512x512 的基础上训练的)。非常小的值(例如 256 像素)也会降低图像质量。这个值必须是 8 的倍数。
- Height:图像高度。
- Seed:随机数的起点。保持这个值不变,可以多次生成相同(或几乎相同,如果启用了 xformers)的图像。没有什么种子天生就比其他的好,但如果你只是稍微改变你的输入参数,以前产生好结果的种子很可能仍然会产生好结果。
3.4 Sampling steps 迭代步数
更多的迭代步数可能会有更好的生成效果,更多细节和锐化,但是会导致生成时间变长。而在实际应用中,30 步和 50 步之间的差异几乎无法区分。
太多的迭代步数也可能适得其反,几乎不会有提高。
进行图生图的时候,正常情况下更弱的降噪强度需要更少的迭代步数(这是工作原理决定的)。你可以在设置里更改设置,让程序确切执行滑块指定的迭代步数。
3.5 Samplers 采样器
目前好用的有 Euler,Euler a(更细腻),和 DDIM。
推荐 Euler a 和 DDIM,新手推荐使用 Euler a
Euler a 富有创造力,不同步数可以生产出不同的图片。调太高步数 (>30) 效果不会更好。
DDIM 收敛快,但效率相对较低,因为需要很多 step 才能获得好的结果,适合在重绘时候使用
LMS 和 PLMS 是 Euler 的衍生,它们使用一种相关但稍有不同的方法(平均过去的几个步骤以提高准确性)。大概 30 step 可以得到稳定结果
PLMS 是一种有效的 LMS(经典方法),可以更好地处理神经网络结构中的奇异性
DPM2 是一种神奇的方法,它旨在改进 DDIM,减少步骤以获得良好的结果。它需要每一步运行两次去噪,它的速度大约是 DDIM 的两倍。但是如果你在进行调试提示词的实验,这个采样器效果不怎么样
Euler 是最简单的,因此也是最快的之一
3.6 CFG Scale 提示词相关性
cfg scale 是图像与提示词的契合度,该值越高,提示词对最终生成结果的影响越大,契合度越高。
过高的 CFG Scale 体现为粗犷的线条和过锐化的图像。
3.7 注意尺寸
出图尺寸太宽时,图中可能会出现多个主体。
要匹配好姿势,镜头和人物才不畸形,有时候需要限定量词,多人物时要处理空间关系和 prompt 遮挡优先级。人数->人物样貌->环境样式->人物状态
1024 之上的尺寸可能会出现不理想的结果!推荐使用 小尺寸分辨率 + 高清修复(下方介绍)。
3.8 Highres. fix 高清修复
通过勾选 txt2img(文生图) 页面上的 “Highres. fix” 复选框来启用。
默认情况下,txt2img(文生图) 在高分辨率下会生成非常混沌的图像。该选项会使得模型首先生成一张小图片,然后通过 img2img 将图片分辨率扩大,以实现高清大图效果。
3.9 Batch Count 与 Batch Size
Batch Count(生成批次)指定共生成几个批次。Batch Size(每批数量)指定每个批次并行生产多少张图片。
大的 Batch Size 需要消耗巨量显存。若您的显卡没有超过 12G 的显存,请不要调节 Batch Size。
对于显存极大的显卡而言,一次生成一张图片无法充分利用显卡计算容量,此时可将 Batch Size 提高以充分压榨算力。
3.10 随机种子
理论上,种子决定模型在生成图片时涉及的所有随机性。
实际的种子数值并不重要。它只是初始化一个定义扩散起点的随机初始值。
在应用完全相同参数(如 Step、CFG、Seed、prompts)的情况下,生产的图片应当完全相同。(不使用 xformers 等会带来干扰的优化器)
不同显卡由于微架构不同,可能会造成预料之外的不同结果。主要体现在 GTX 10xx 系列显卡上。
3.11 Denoising strength 降噪强度
Denoising strength 仅在 img2img(图生图)或 高清修复 时被应用,其表征最后生成图片对原始输入图像内容的变化程度。通过调整该值,可以降低对画风的影响,但也会弱化 img2img 能力。值越高 AI 对原图的参考程度就越低 (同时增加迭代次数)。
对于图生图来说,低 denoising 意味着修正原图,高 denoising 就和原图就没有大的相关性了。一般来讲阈值是 0.7 左右,超过 0.7 和原图基本上无关,0.3 以下就是稍微改一些。
实际执行中,具体的执行步骤为 Denoising strength * Sampling Steps。
📝 四、总结及建议
-
优点:
- 高性能:HAI采用了先进的架构和算法,能够处理大量并发请求,并提供高吞吐量和低延迟的服务。
- 稳定性:HAI具有高可用性和可扩展性,能够保证服务的稳定性和连续性。它采用了负载均衡和容错机制,可以在节点故障的情况下保持服务的正常运行。
- 安全性:HAI提供了完善的安全措施,包括身份认证、访问控制、数据加密等,确保数据的安全性和隐私性。
- 易用性:HAI提供了简单易用的API接口和友好的开发工具,方便开发者进行应用程序的开发和调试。
-
建议及优化:
-
既然已实现精确计费(按小时),那么是否可以考虑推出包天或包月的服务?这样的举措可以进一步满足用户的需求,并增加收益。
-
对于新建的应用服务,目前只能销毁而不能停止,这导致了资源浪费,并可能使用户产生额外的费用。这个问题需要得到关注和解决,以提升服务的效率和用户满意度。
-
总结:
HAI作为一种高性能应用服务,具有高性能、高稳定性、高安全性和易用性等优点。它适用于需要处理大规模并发请求和高吞吐量数据处理的应用场景,如电子商务、在线游戏、在线支付等。使用HAI可以有效地提高应用程序的性能和稳定性,并降低运维成本和风险。同时,由于HAI的开放性和可扩展性,它也适用于各种不同的业务场景和需求。
五、InsCode AI 创作助手
这篇关于【腾讯云 HAI域探秘】借助HAI,轻松部署StableDiffusion环境拿捏AI作画-体验实验赢大奖的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








