本文主要是介绍diffusers 源码待理解之处,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、训练DreamBooth时,相关代码的细节小计

**
class_labels = timesteps 时,模型的前向传播怎么走?待深入去看
**
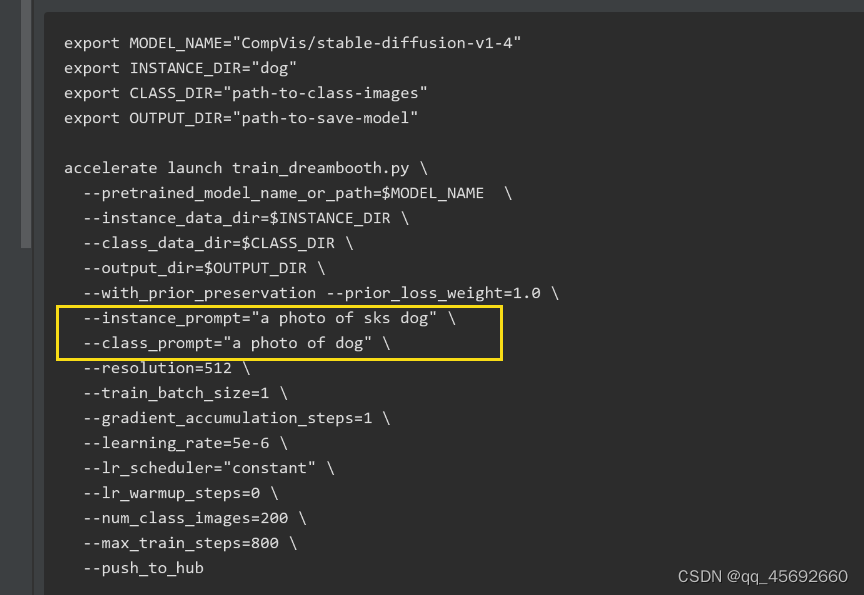
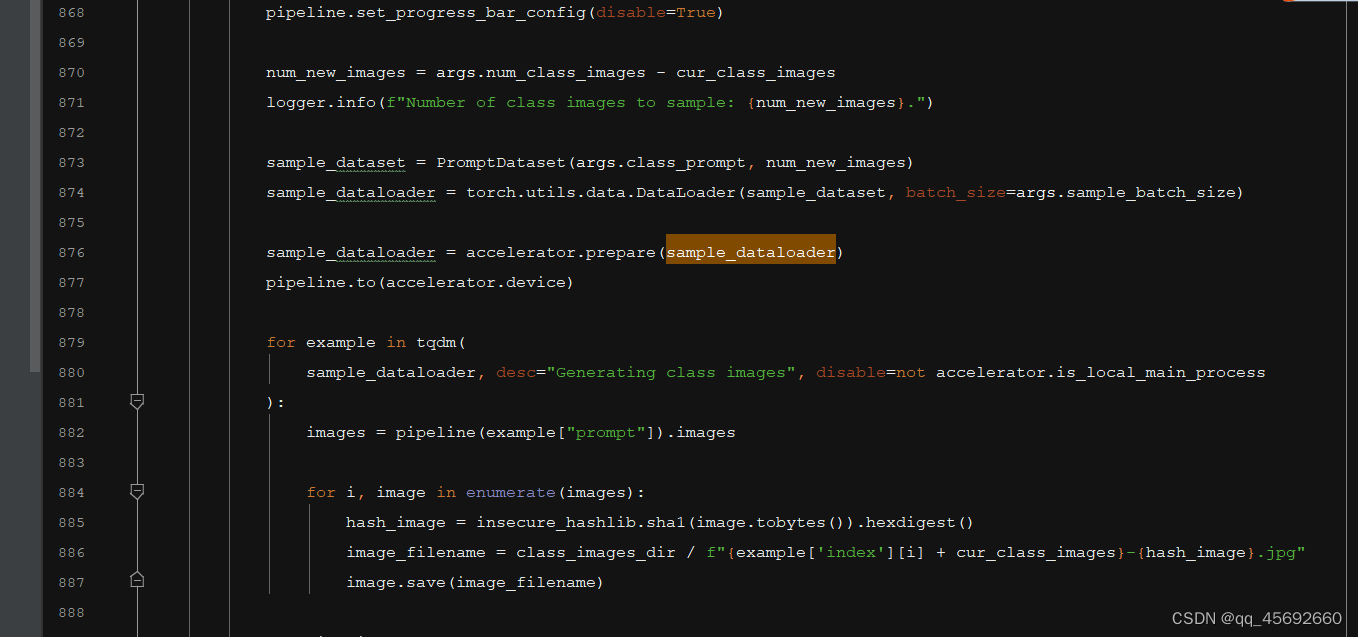
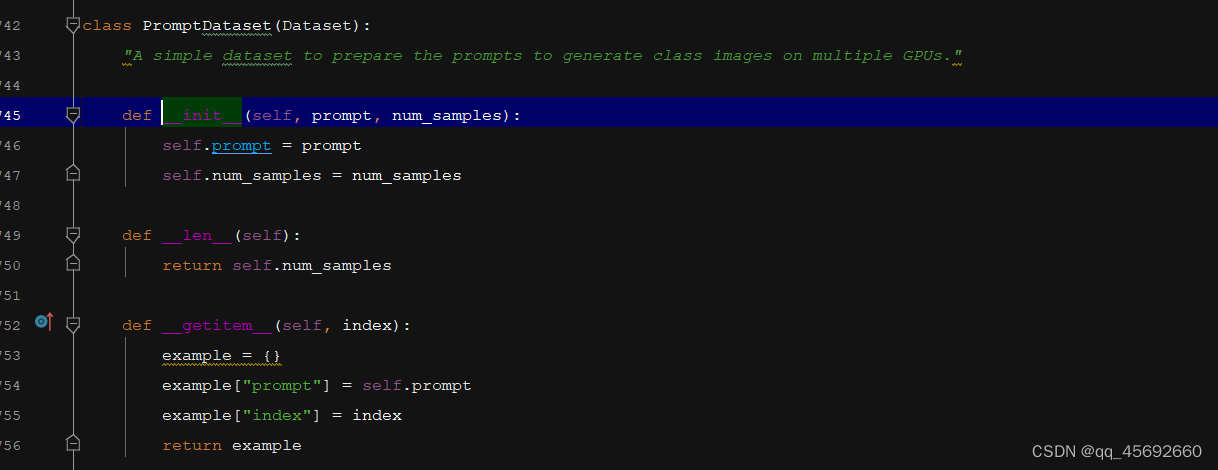
利用class_prompt去生成数据,而不是instance_prompt
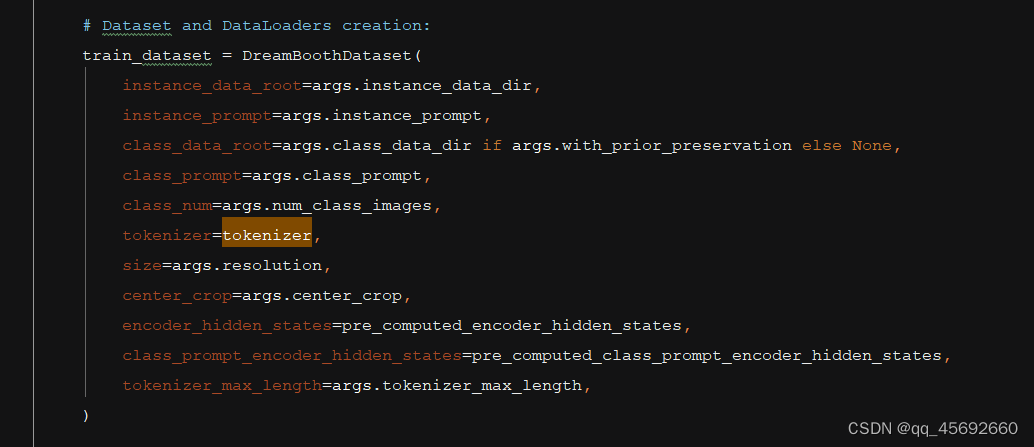
class DreamBoothDataset(Dataset):"""A dataset to prepare the instance and class images with the prompts for fine-tuning the model.It pre-processes the images and the tokenizes prompts."""def __init__(self,instance_data_root,instance_prompt,tokenizer,class_data_root=None,class_prompt=None,class_num=None,size=512,center_crop=False,encoder_hidden_states=None,class_prompt_encoder_hidden_states=None,tokenizer_max_length=None,):self.size = sizeself.center_crop = center_cropself.tokenizer = tokenizerself.encoder_hidden_states = encoder_hidden_statesself.class_prompt_encoder_hidden_states = class_prompt_encoder_hidden_statesself.tokenizer_max_length = tokenizer_max_lengthself.instance_data_root = Path(instance_data_root)if not self.instance_data_root.exists():raise ValueError(f"Instance {self.instance_data_root} images root doesn't exists.")self.instance_images_path = list(Path(instance_data_root).iterdir())self.num_instance_images = len(self.instance_images_path)self.instance_prompt = instance_promptself._length = self.num_instance_imagesif class_data_root is not None:self.class_data_root = Path(class_data_root)self.class_data_root.mkdir(parents=True, exist_ok=True)self.class_images_path = list(self.class_data_root.iterdir())if class_num is not None:self.num_class_images = min(len(self.class_images_path), class_num)else:self.num_class_images = len(self.class_images_path)self._length = max(self.num_class_images, self.num_instance_images)self.class_prompt = class_promptelse:self.class_data_root = Noneself.image_transforms = transforms.Compose([transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),])def __len__(self):return self._lengthdef __getitem__(self, index):example = {}instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])instance_image = exif_transpose(instance_image)if not instance_image.mode == "RGB":instance_image = instance_image.convert("RGB")example["instance_images"] = self.image_transforms(instance_image)if self.encoder_hidden_states is not None:example["instance_prompt_ids"] = self.encoder_hidden_stateselse:text_inputs = tokenize_prompt(self.tokenizer, self.instance_prompt, tokenizer_max_length=self.tokenizer_max_length)example["instance_prompt_ids"] = text_inputs.input_idsexample["instance_attention_mask"] = text_inputs.attention_maskif self.class_data_root:class_image = Image.open(self.class_images_path[index % self.num_class_images])class_image = exif_transpose(class_image)if not class_image.mode == "RGB":class_image = class_image.convert("RGB")example["class_images"] = self.image_transforms(class_image)if self.class_prompt_encoder_hidden_states is not None:example["class_prompt_ids"] = self.class_prompt_encoder_hidden_stateselse:class_text_inputs = tokenize_prompt(self.tokenizer, self.class_prompt, tokenizer_max_length=self.tokenizer_max_length)example["class_prompt_ids"] = class_text_inputs.input_idsexample["class_attention_mask"] = class_text_inputs.attention_maskreturn example
def tokenize_prompt(tokenizer, prompt, tokenizer_max_length=None):if tokenizer_max_length is not None:max_length = tokenizer_max_lengthelse:max_length = tokenizer.model_max_lengthtext_inputs = tokenizer(prompt,truncation=True,padding="max_length",max_length=max_length,return_tensors="pt",)return text_inputs
def collate_fn(examples, with_prior_preservation=False):has_attention_mask = "instance_attention_mask" in examples[0]input_ids = [example["instance_prompt_ids"] for example in examples]pixel_values = [example["instance_images"] for example in examples]if has_attention_mask:attention_mask = [example["instance_attention_mask"] for example in examples]# Concat class and instance examples for prior preservation.# We do this to avoid doing two forward passes.if with_prior_preservation:input_ids += [example["class_prompt_ids"] for example in examples]pixel_values += [example["class_images"] for example in examples]if has_attention_mask:attention_mask += [example["class_attention_mask"] for example in examples]pixel_values = torch.stack(pixel_values)pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()input_ids = torch.cat(input_ids, dim=0)batch = {"input_ids": input_ids,"pixel_values": pixel_values,}if has_attention_mask:attention_mask = torch.cat(attention_mask, dim=0)batch["attention_mask"] = attention_maskreturn batch
Dataset和Dataloader的构成
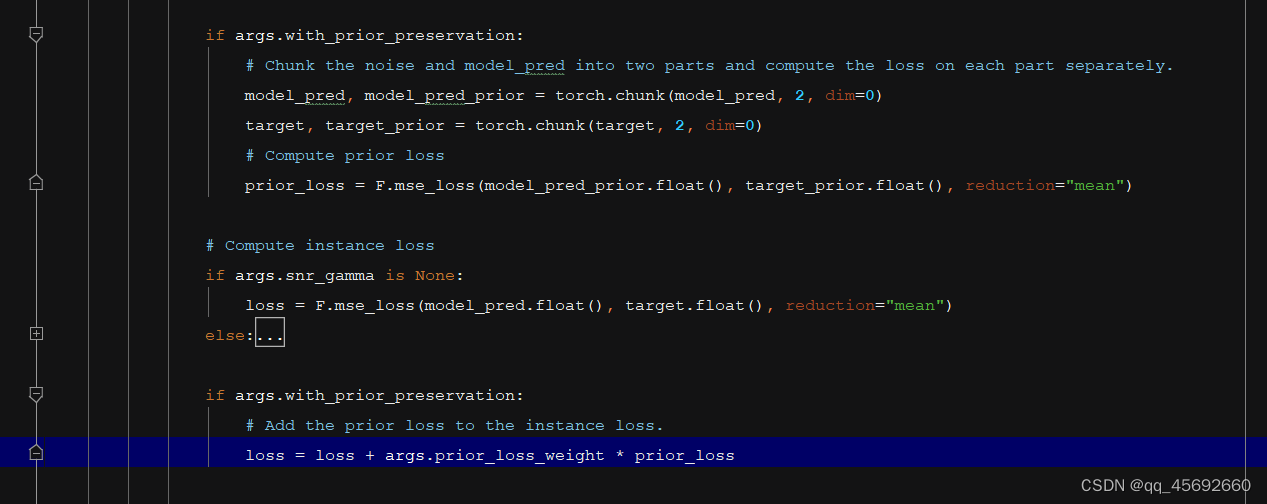
为了避免模型过拟合或者是说语言漂移的情况,需要用模型去用一个普通的prompt先生成样本。
fine-tune text-encoder,但是对显存要求更高
二、训练text to image,相关代码的细节小计
**
1、Dataloader的构建如下,但是为啥没有attention_mask呢?训练DreamBooth时有
2、训练或者微调模型时需要图文数据对,如果没有文本数据,可以用BLIP去生成图像描述的文本,但是文本描述不一定可靠
**
# Get the datasets: you can either provide your own training and evaluation files (see below)# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).# In distributed training, the load_dataset function guarantees that only one local process can concurrently# download the dataset.if args.dataset_name is not None:# Downloading and loading a dataset from the hub.dataset = load_dataset(args.dataset_name,args.dataset_config_name,cache_dir=args.cache_dir,data_dir=args.train_data_dir,)else:data_files = {}if args.train_data_dir is not None:data_files["train"] = os.path.join(args.train_data_dir, "**")dataset = load_dataset("imagefolder",data_files=data_files,cache_dir=args.cache_dir,)# See more about loading custom images at# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder# Preprocessing the datasets.# We need to tokenize inputs and targets.column_names = dataset["train"].column_names# 6. Get the column names for input/target.dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)if args.image_column is None:image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]else:image_column = args.image_columnif image_column not in column_names:raise ValueError(f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}")if args.caption_column is None:caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]else:caption_column = args.caption_columnif caption_column not in column_names:raise ValueError(f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}")# Preprocessing the datasets.# We need to tokenize input captions and transform the images.def tokenize_captions(examples, is_train=True):captions = []for caption in examples[caption_column]:if isinstance(caption, str):captions.append(caption)elif isinstance(caption, (list, np.ndarray)):# take a random caption if there are multiplecaptions.append(random.choice(caption) if is_train else caption[0])else:raise ValueError(f"Caption column `{caption_column}` should contain either strings or lists of strings.")inputs = tokenizer(captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt")return inputs.input_ids# Preprocessing the datasets.train_transforms = transforms.Compose([transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),])def preprocess_train(examples):images = [image.convert("RGB") for image in examples[image_column]]examples["pixel_values"] = [train_transforms(image) for image in images]examples["input_ids"] = tokenize_captions(examples)# images text pixel_values input_ids 4种keyreturn exampleswith accelerator.main_process_first():if args.max_train_samples is not None:dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))# Set the training transformstrain_dataset = dataset["train"].with_transform(preprocess_train)def collate_fn(examples):pixel_values = torch.stack([example["pixel_values"] for example in examples])pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()input_ids = torch.stack([example["input_ids"] for example in examples])return {"pixel_values": pixel_values, "input_ids": input_ids}# DataLoaders creation:train_dataloader = torch.utils.data.DataLoader(train_dataset,shuffle=True,collate_fn=collate_fn,batch_size=args.train_batch_size,num_workers=args.dataloader_num_workers,)
三、训ControlNet
Dataloader的搭建的代码如下:
1、新增conditioning_pixel_values图像数据,用于做可控的生成
2、输入中依旧没有attention-mask,待思考
def make_train_dataset(args, tokenizer, accelerator):# Get the datasets: you can either provide your own training and evaluation files (see below)# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).# In distributed training, the load_dataset function guarantees that only one local process can concurrently# download the dataset.if args.dataset_name is not None:# Downloading and loading a dataset from the hub.dataset = load_dataset(args.dataset_name,args.dataset_config_name,cache_dir=args.cache_dir,)else:if args.train_data_dir is not None:dataset = load_dataset(args.train_data_dir,cache_dir=args.cache_dir,)# See more about loading custom images at# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script# Preprocessing the datasets.# We need to tokenize inputs and targets.column_names = dataset["train"].column_names# 6. Get the column names for input/target.if args.image_column is None:image_column = column_names[0]logger.info(f"image column defaulting to {image_column}")else:image_column = args.image_columnif image_column not in column_names:raise ValueError(f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}")if args.caption_column is None:caption_column = column_names[1]logger.info(f"caption column defaulting to {caption_column}")else:caption_column = args.caption_columnif caption_column not in column_names:raise ValueError(f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}")if args.conditioning_image_column is None:conditioning_image_column = column_names[2]logger.info(f"conditioning image column defaulting to {conditioning_image_column}")else:conditioning_image_column = args.conditioning_image_columnif conditioning_image_column not in column_names:raise ValueError(f"`--conditioning_image_column` value '{args.conditioning_image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}")def tokenize_captions(examples, is_train=True):captions = []for caption in examples[caption_column]:if random.random() < args.proportion_empty_prompts:captions.append("")elif isinstance(caption, str):captions.append(caption)elif isinstance(caption, (list, np.ndarray)):# take a random caption if there are multiplecaptions.append(random.choice(caption) if is_train else caption[0])else:raise ValueError(f"Caption column `{caption_column}` should contain either strings or lists of strings.")inputs = tokenizer(captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt")return inputs.input_idsimage_transforms = transforms.Compose([transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(args.resolution),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),])conditioning_image_transforms = transforms.Compose([transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(args.resolution),transforms.ToTensor(),])def preprocess_train(examples):images = [image.convert("RGB") for image in examples[image_column]]images = [image_transforms(image) for image in images]conditioning_images = [image.convert("RGB") for image in examples[conditioning_image_column]]conditioning_images = [conditioning_image_transforms(image) for image in conditioning_images]examples["pixel_values"] = imagesexamples["conditioning_pixel_values"] = conditioning_imagesexamples["input_ids"] = tokenize_captions(examples)return exampleswith accelerator.main_process_first():if args.max_train_samples is not None:dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))# Set the training transformstrain_dataset = dataset["train"].with_transform(preprocess_train)return train_datasetdef collate_fn(examples):pixel_values = torch.stack([example["pixel_values"] for example in examples])pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()conditioning_pixel_values = torch.stack([example["conditioning_pixel_values"] for example in examples])conditioning_pixel_values = conditioning_pixel_values.to(memory_format=torch.contiguous_format).float()input_ids = torch.stack([example["input_ids"] for example in examples])return {"pixel_values": pixel_values,"conditioning_pixel_values": conditioning_pixel_values,"input_ids": input_ids,}
这篇关于diffusers 源码待理解之处的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








