bucket专题

常用的限流算法-令牌桶(Token Bucket)php版
令牌桶(Token Bucket)是一种常用的限流算法,用于控制流量的速率。其核心思想是以固定速率向桶中放入令牌,当请求到来时,从桶中取走一定数量的令牌,如果桶中没有足够的令牌,则拒绝请求或进行排队等待。 下面是如何在 PHP 中实现一个简单的令牌桶算法。 1. 令牌桶的基本概念 令牌的生成速度:令牌以固定速率生成并加入到桶中。桶的容量:桶中可以容纳的最大令牌数,防止令牌无限增长。请求的消耗
ElasticSearch学习笔记(五)Bucket聚合、Metric聚合
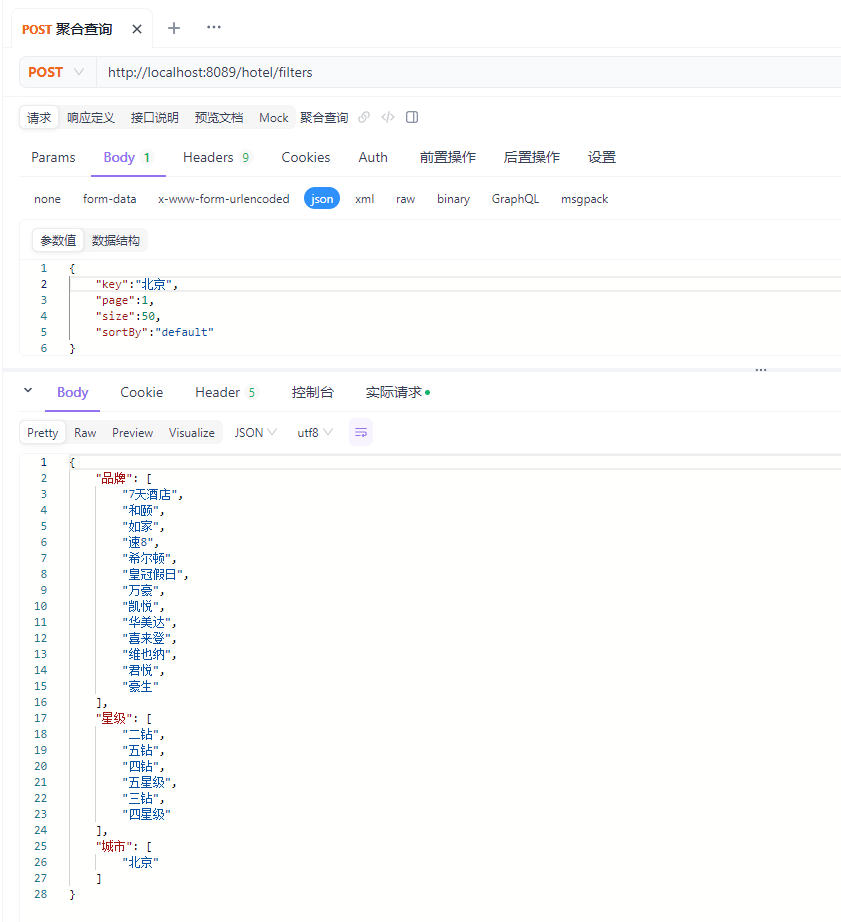
文章目录 前言9 项目实战9.3 我周边的酒店9.4 酒店竞价排名 10 数据聚合10.1 聚合的分类10.2 DSL实现聚合10.2.1 Bucket聚合10.2.2 聚合结果排序10.2.3 限定聚合范围10.2.4 Metric聚合 10.3 RestAPI实现聚合10.3.1 API语法10.3.2 业务需求10.3.3 业务实现10.3.4 功能测试 前言 Elas

02.elasticsearch bucket aggregation查询
文章目录 1. bucket aggregation 查询类型概览2. 数据准备3. 使用样例1. Terms Aggregation:1. 普通的terms agg2. 嵌套一个metric agg 作为sub agg查询3. 嵌套一个terms agg作为sub agg查询 2. Range Aggregation:3. Date Histogram Aggregation:4. Dat
漏斗限流(leaky bucket)
漏斗限流(leaky bucket) 介绍工作原理leaky bucket实现示例:搭配pool池pool.lua示例搭配示例 对象池(pool)结合漏斗限流(leaky bucket)的好处: 介绍 漏斗限流(leaky bucket)是一种流量控制算法,用于限制在网络或系统中通过的数据量或请求速率。通常用于平滑网络流量或请求到达的速率,防止突发流量导致系统负载过高或网络拥塞

Base上关于CMS、GC碎片、大缓存的一种解决方案:Bucket Cache----没看懂
介绍BucketCache前,先对HBase的Cache做个介绍: 一.HBase在读取时,会以Block为单位进行cache,用来提升读的性能; 二.Block可以分类为DataBlock(默认大小64K,存储KV)、BloomBlock(默认大小128K,存储BloomFilter数据)、IndexBlock(默认大小128K,索引数据,用来加快Row所在DataBlock的定位) 三.对于一

oss bucket 挂载ecs文件夹
# ecs文件夹与oss实现文件共享# https://help.aliyun.com/document_detail/32196.html?spm=a2c4g.11186623.6.904.c44f2315vaZh9d# centos7及以上# 下载安装包wget http://gosspublic.alicdn.com/ossfs/ossfs_1.80.6_centos7.0_x86_6
循环队列的实现及应用——桶排序bucket_sort、基数排序radix_sort
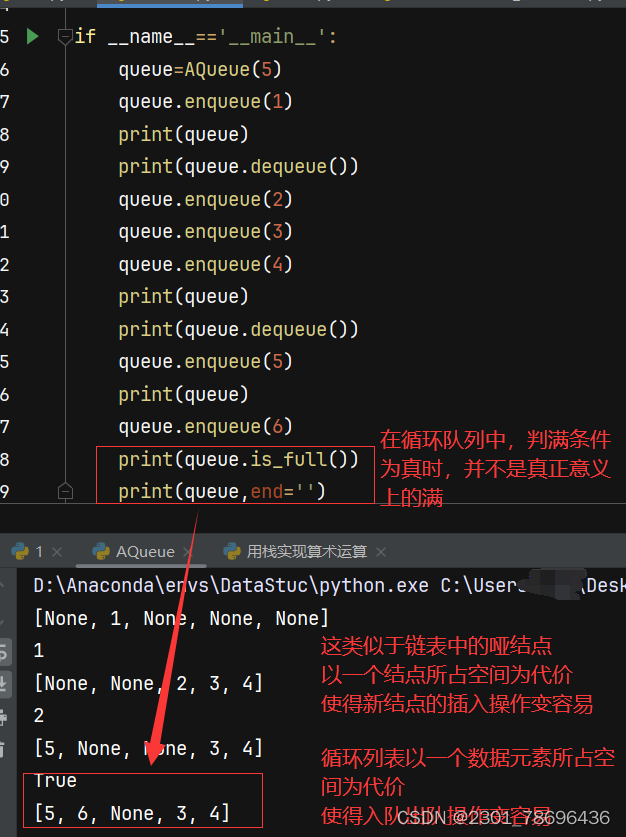
一、循环队列的实现 代码解释 1、完成初始化 2、定义方法 3、测试实例 4、完整代码 class AQueue:def __init__(self, size=10):self.__mSize = sizeself.__front=0self.__rear = 0self.__listArray = [None] * size#清空元素def clear(self):se
《啊哈!算法》简单桶排序(Simple Bucket Sort)
《啊哈!算法》简单桶排序(Simple Bucket Sort) 首先想想如何简单地排序? 假设我们有5个学生,分数分别是5, 3, 5, 2, 8,满分10分。 由实际可知,分数范围在[0,10],闭区间范围内。 首先申请一个一维数组int arr[11], 是从[0, 10]。 这里认为第i个元素代表得i分的人的数目。 比如i=0,arr[0]=3,那么代表得0分的人有三个。 首
Java排序算法--桶式排序(Bucket Sort)
任何只使用比较的一般排序算法的最坏情况下需要运行时间Ω(NlogN),但是记住,在某些特殊情况下以线性时间进行排序仍然是可能的。 一个简单的例子是桶式排序(bucket sort)。为使桶式排序能够正常工作,必须要有一些附加的信息。输入数据A1,A2,A3,…,AN必须只由小于M的正整数组成(显然还可以对其进行扩充)。如果是这种情况,那么算法很简单:使用一个大小为M的称为count的数组

第6.3章:StarRocks查询加速——Bucket Shuffle Join
目录 一、StarRocks数据划分 1.1 分区 1.2 分桶 二、Bucket Shuffle Join实现原理 2.1 Bucket Shuffle Join概述 2.2 Bucket Shuffle Join工作原理 2.3 Bucket Shuffle Join规划规则 三、应用案例 注:本篇文章阐述的是StarRocks-3.2版本的Bucket Shuffle

阿里云OSS图片处理如何借助CDN将多个域名绑定一个bucket(channel)上
阿里云OSS 图片处理如何借助CDN将多个域名绑定一个bucket(channel)上 无论是从优化浏览器行为上还是处于其他原因(比如说oss对外限制bucket个数为10个),现在有很多用户想在一个bucket上绑定多个域名,目前OSS已经对此做了支持,但是阿里云图片处理控制台上只允许一个bucket(channel)绑定一个域名,还不支持将多个域名绑定到同一个bucket(channel)上
CentOS7挂载AWS的S3存储bucket到Linux本地文件目录,使用nginx/openresty直接静态文件方式访问
安装AWS s3fs yum install epel-release yum install s3fs-fuse AWS的S3访问密钥 echo ACCESS_KEY_ID:SECRET_ACCESS_KEY > ${HOME}/.passwd-s3fschmod 600 ${HOME}/.passwd-s3fs 挂载s3存储到/mnt/s3bucket目录,并把文件设置为ngi
Java如何对OSS存储引擎的Bucket进行创建【OSS学习】
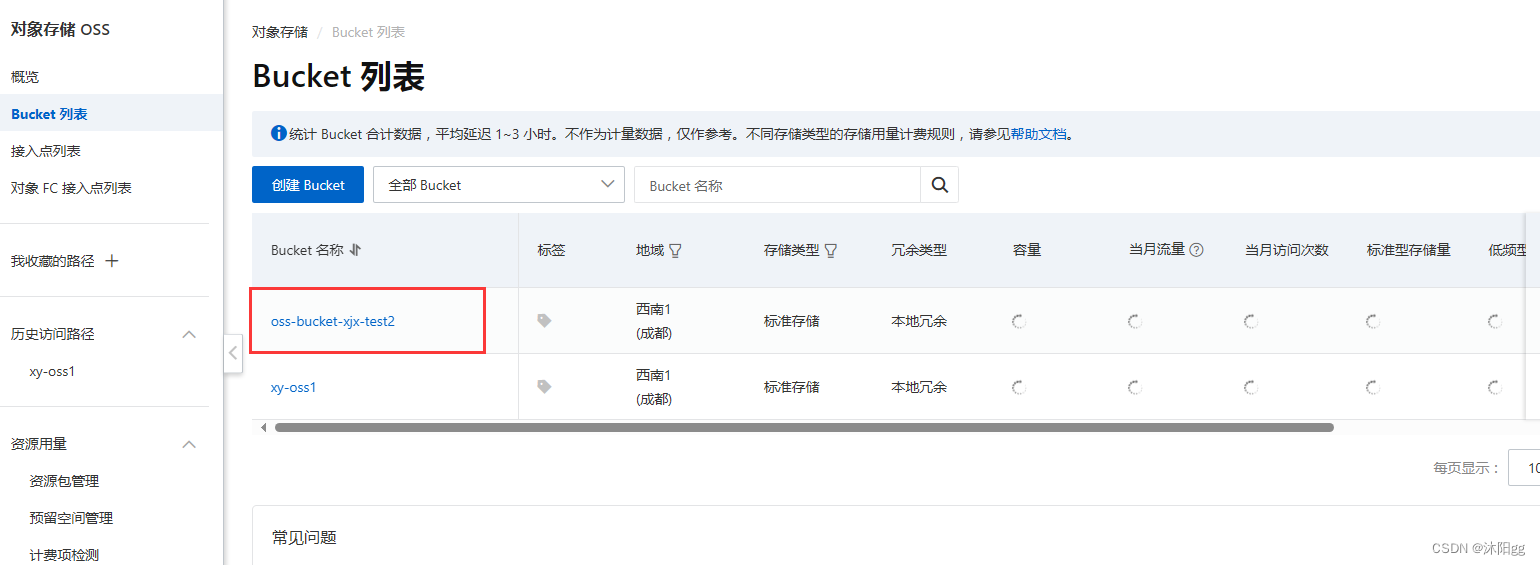
在前面学会了如何开通OSS,对OSS的一些基本操作,接下来记录一下如何通过Java代码通过SDK对OSS存储引擎里面的Bucket存储空间进行创建。 目录 1、先看看OSS: 2、代码编写: 3、运行效果: 1、先看看OSS: 此时OSS存储引擎里面只有一个存储空间 2、代码编写: package www.xjxwc666;import com.aliyu
算法 - 桶排序(Bucket Sort)
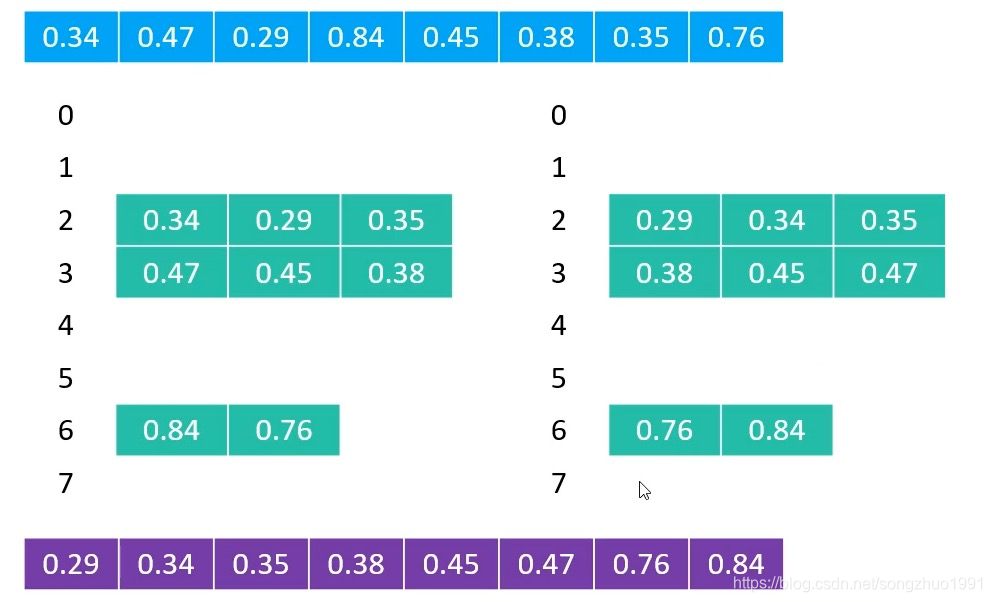
执行流程: 创建一定数量的桶(比如用数组、链表作为桶)按照一定的规制(不同类型的数据,规则不同),将序列中的元素均匀分配到对应的桶分别对每个桶进行单独排序将所有非空桶的元素合并成有序序列 元素在同种的索引元素值*元素数量 实现 double[] array = {0.34, 0.47, 0.29, 0.84, 0.45, 0.38, 0.35, 0.76} // 桶数组List<D

Ceph入门到精通-通过 CloudBerry Explorer 管理对象bucket
简介 CloudBerry Explorer 是一款可用于管理对象存储(Cloud Object Storage,COS)的客户端工具。通过 CloudBerry Explorer 可实现将 COS 挂载在 Windows 等操作系统上,方便用户访问、移动和管理 COS 文件。 支持系统 支持 Windows、macOS 系统。 下载地址 前往 CloudBerry 官方下载。 安装和
HiveSql语法优化四 :Bucket Map Join和Sort Merge Bucket Map Join优化
Bucket Map Join 之前的map join适用场景是大表join小表的情况,但是两张表都相对较大,若采用普通的Map Join算法,则Map端需要较多的内存来缓存数据,当然可以选择为Map段分配更多的内存,来保证任务运行成功。但是,Map端的内存不可能无上限的分配,所以当参与Join的表数据量均过大时,就可以考虑采用Bucket Map Join算法。

es - elasticsearch - aggs - bucket - rare_terms
世界上并没有完美的程序,但是我们并不因此而沮丧,因为写程序就是一个不断追求完美的过程。 问:rare_terms有什么特点? 答: 问:rare_terms如何使用? 答: # 删除DELETE /rare_terms_test# 映射PUT /rare_terms_test{"mappings": {"properties": {"name": {"type": "keywor
排序——桶排序(Bucket sort)
算法思路 桶排序是将待排序集合中处于同一个值域的元素存入同一个桶中,也就是根据元素值特性将集合拆分为多个区域,则拆分后形成的多个桶,从值域上看是处于有序状态的。对每个桶中元素进行排序,则所有桶中元素构成的集合是已排序的。 算法详解 桶排序的思想近乎彻底的分治思想。算法的过程描述如下: 根据待排序集合中最大元素和最小元素的差值范围和映射规则,确定申请的桶个数;遍历待排序集合,将每一个元素移动
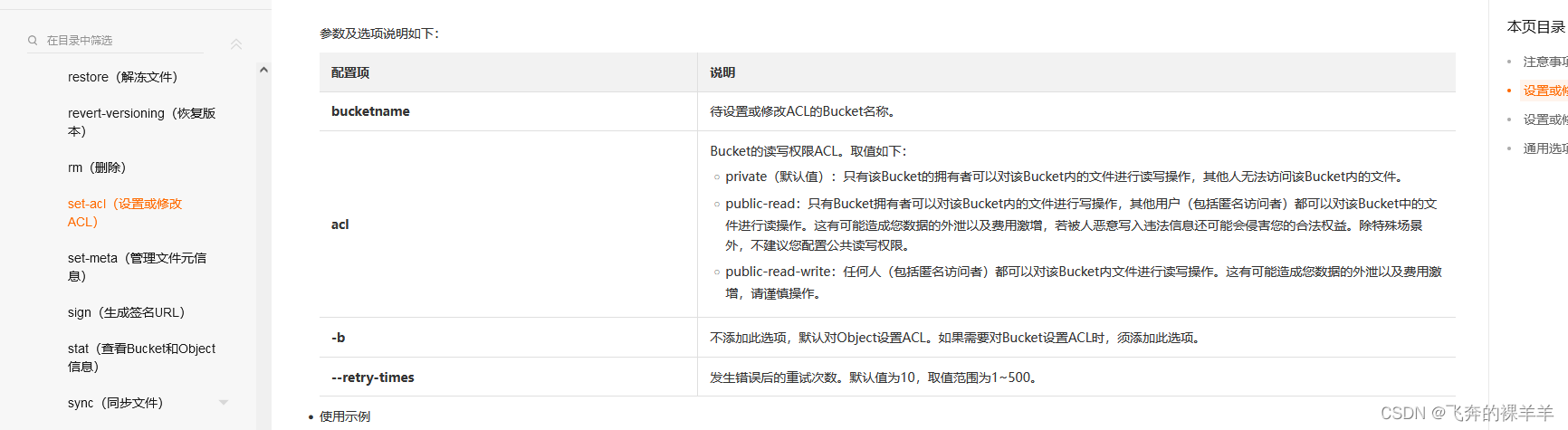
OSS-修改BUCKET权限
OSS 访问文件报错 You have no right to access this object because of bucket acl <Error><Code>AccessDenied</Code><Message>You have no right to access this object because of bucket acl.</Message><RequestId
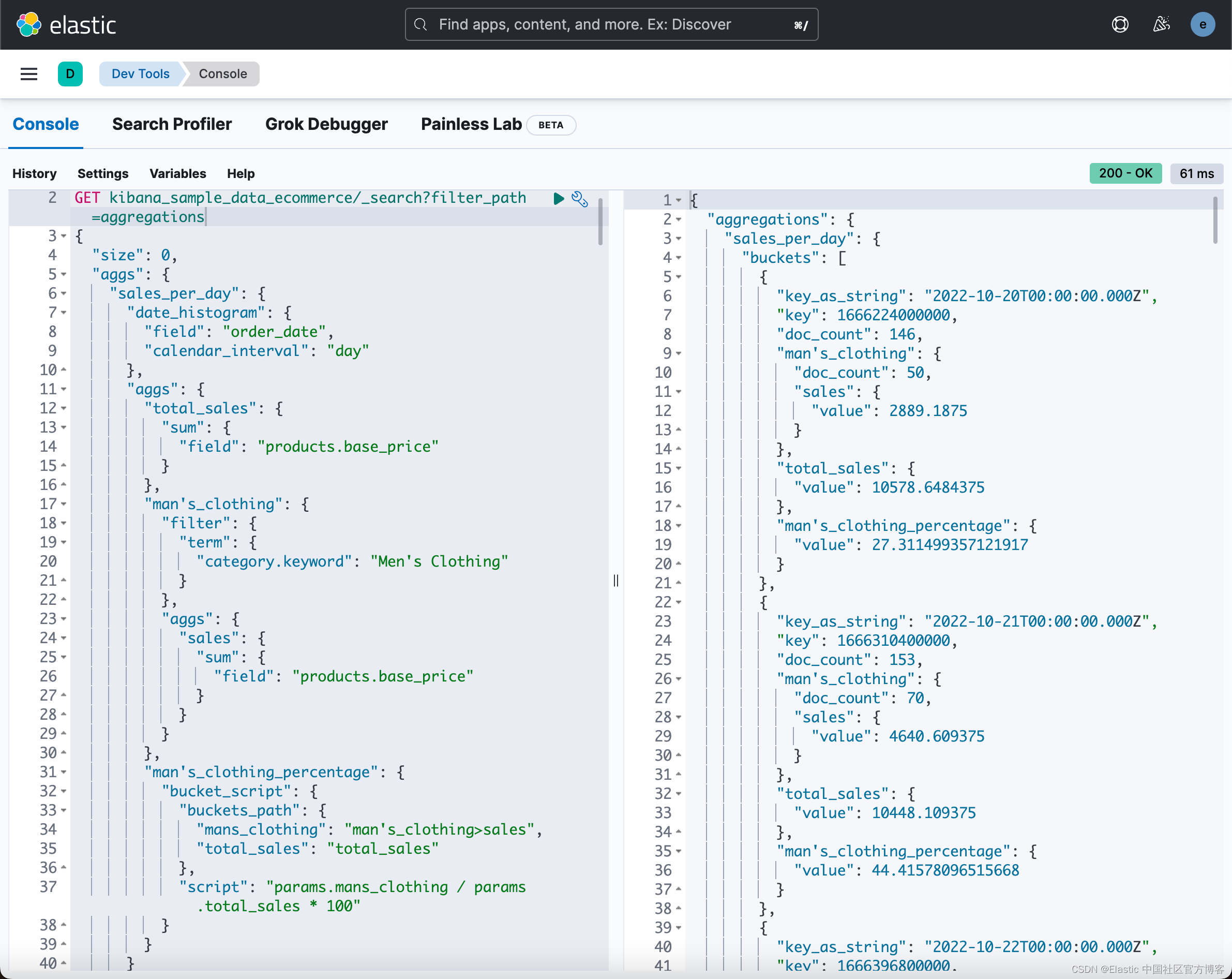
Elasticsearch:Bucket script 聚合
Bucket script 聚合是一个父管道(parent pipeline)聚合,它执行一个脚本,该脚本可以对父多桶聚合中的指定指标执行每个桶的计算。 指定的指标必须是数字,并且脚本必须返回一个数值。有关 pipeline 聚合的内容,你可以阅读文章 “Elasticsearch:pipeline aggregation 介绍”。 Bucket script 聚合 用法 单独

浅谈bucket x out of y on condition
首先,我们先来理解"X"表达的是什么 这里的"x"表达的是在把原本的桶分成 y 份后的顺序的第 x 个,来个简单的例子:例如有个表被分成了4个buckets,那么这个时候运行 bucket 1 out of 4 on id(我们暂时默认以id分),这句话表示就是把原本的buckets分成4份,取第一份的数据,即取第一桶的数据。到这里只是最简单的形式。 然后我们来看"Y" 表达

Apache Doris (五十四): Doris Join类型 - Bucket Shuffle Join
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录
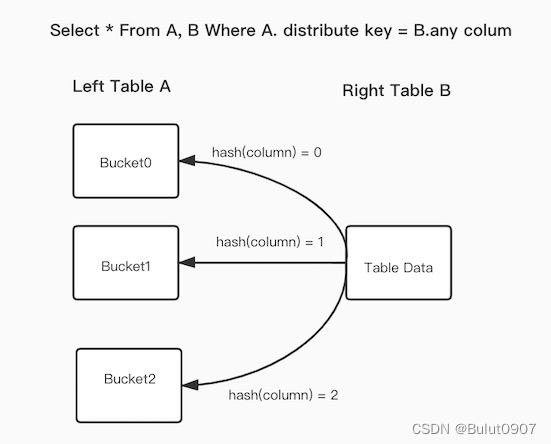
Apache Doris的Bucket Shuffle Join实现
目录 1. 介绍2. 原理3. 使用 1. 介绍 两个表进行join时,让右表根据左边的数据分布,进行数据的shuffle,再进行join。减少跨节点的数据传输。加速查询 2. 原理 SQL语句为A表join B表,并且join的等值表达式命中了A的数据分布列。而Bucket Shuffle Join会根据A表的数据分布信息,将B表的数据发送到对应的A表的数据存储节点。B

delphi七牛云对象存储OSS(支持上传文件、分片上传文件、下载文件、断点上传下载、Bucket管理、目录创建删除、复制移动文件等操作等)
作者QQ:(648437169) 下载链接:https://download.csdn.net/download/liushenglin123/13129055 【delphi七牛云对象存储OSS】获取Bucket列表、设置Bucket权限、创建Bucket、删除Bucket、获取文件列表、上传文件、分片上传文件、下载文件、断点上传下载、复制文件、移动文件、删除文件、创建目录、删除目录等功能。
Boltdb源码分析(四)----bucket结构
本文公众号文章链接:https://mp.weixin.qq.com/s/Cet4TTTTc6_OWWvmNgjOKA 本文csdn博客文章链接:https://blog.csdn.net/screscent/article/details/79912742 boltdb是一个纯粹的key Value数据库,其宗旨是提供一个简单,快速,可信的数据库。此数据库广泛应用于各大开源
分区、桶、Sort Merge Bucket Join
Hive 已是目前业界最为通用、廉价的构建大数据时代数据仓库的解决方案了,虽然也有 Impala 等后起之秀,但目前从功能、稳定性等方面来说,Hive 的地位尚不可撼动。 其实这篇博文主要是想聊聊 SMB join 的,Join 是整个 MR/Hive 最为核心的部分之一,是每个 Hadoop/Hive/DW RD 必须掌握的部分,之前也有几篇文章聊到过 MR/Hive 中的 join,其实底层