本文主要是介绍第6.3章:StarRocks查询加速——Bucket Shuffle Join,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、StarRocks数据划分
1.1 分区
1.2 分桶
二、Bucket Shuffle Join实现原理
2.1 Bucket Shuffle Join概述
2.2 Bucket Shuffle Join工作原理
2.3 Bucket Shuffle Join规划规则
三、应用案例
注:本篇文章阐述的是StarRocks-3.2版本的Bucket Shuffle Join
一、StarRocks数据划分
在介绍Bucket Shuffle Join之前,再回顾下StarRocks的数据划分及tablet多副本机制。
StarRocks支持两层的数据划分,第一层是Range Partition,第二层是Hash Bucket(Tablet)。 StarRocks的数据表按照分区分桶规则,被水平切分成若干个数据分片(Tablet,也称作数据分桶 Bucket)存储在不同的be节点上,每个tablet都有多个副本(默认是3副本)。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。Tablet 是数据移动、复制等操作的最小物理存储单元。 一个 Tablet 只属于一个数据分区(Partition),而一个 Partition 包含若干个 Tablet。
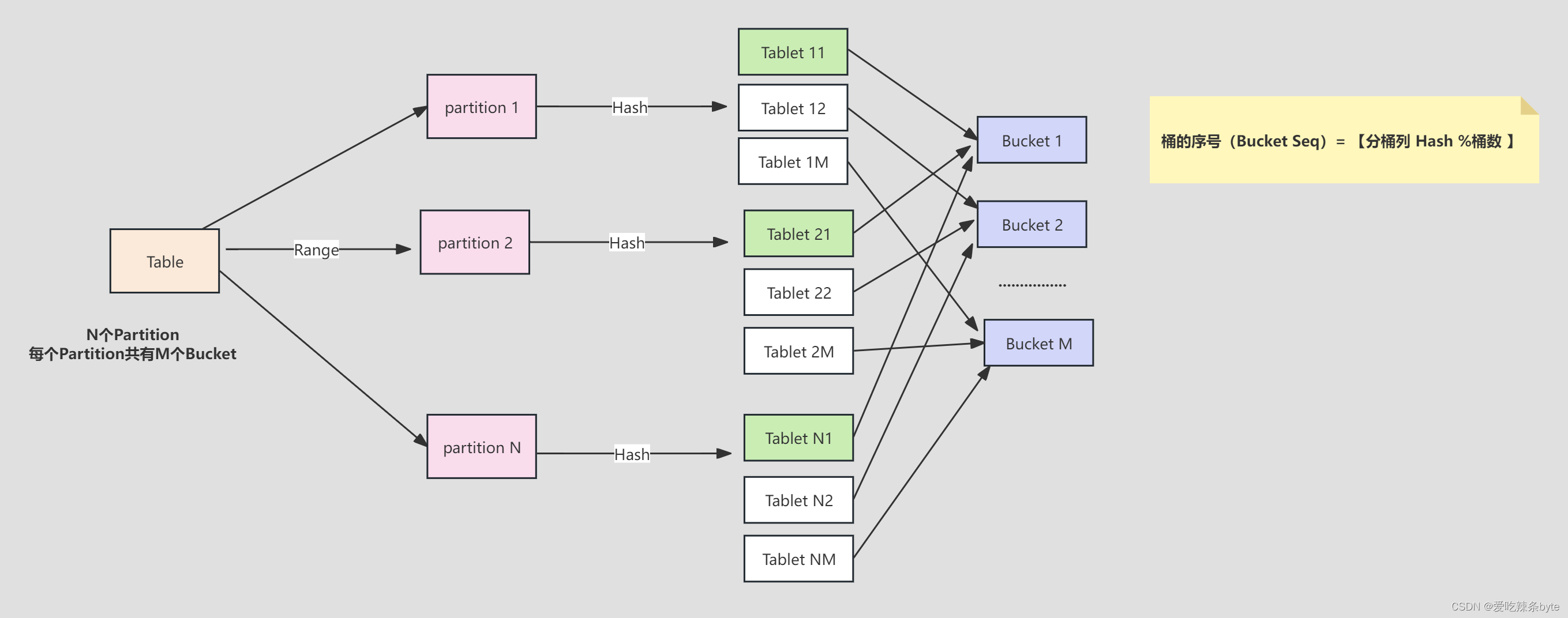
下图说明 Table、Partition、Bucket(Tablet) 的关系:
- Table按照Range的方式按照 date 字段进行分区,得到了 N 个Partition
- 每个 Partition 通过相同的 Hash 方式将其中的数据划分为 M个Bucket(Tablet)
- 从逻辑上来说,Bucket 1 可以包含 N 个 Partition 中划分得到的数据,比如下图中的 Tablet 11、Tablet 21、Tablet N1
1.1 分区
逻辑概念,分区用于将数据划分成不同的区间,主要作用是将一张表按照分区键拆分成不同的管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
1.2 分桶
物理概念,StarRocks一般采用Hash算法作为分桶算法。在同一分区内,分桶键哈希值相同的数据会划分到同一个tablet(数据分片),tablet以多副本冗余的形式存储,是数据均衡和恢复的最⼩单位,数据导入和查询最终都下沉到所涉及的 tablet副本上。
二、Bucket Shuffle Join实现原理
2.1 Bucket Shuffle Join概述
StarRocks支持的常规分布式Join方式包括了Shuffle Join和Broadcast Join,这两种join都会导致不小的网络开销。
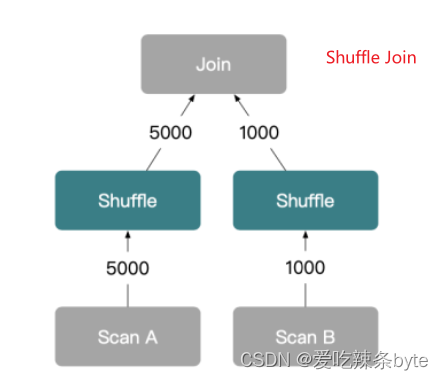
- Shuffle Join:会将 A、B 两表的数据根据哈希计算分散到集群的节点中,所以它的网络开销是A+B,内存开销是B。
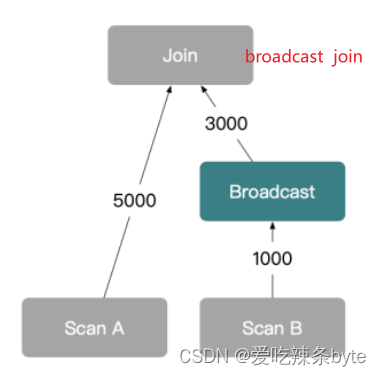
- Broadcast Join:如果根据数据分布,查询规划出A表有3个执行的HashJoinNode,那么需要将B表全量的发送到3个HashJoinNode,那么它的网络开销是
3B,它的内存开销也是3B。
如下图:通过将B表的数据全量广播到A表的机器上,在A表的机器上进行Join操作,相比较于Shuffle join ,节省了A表数据Shuffle,但是B表的数据是全量广播,适合B表是个小表的场景。
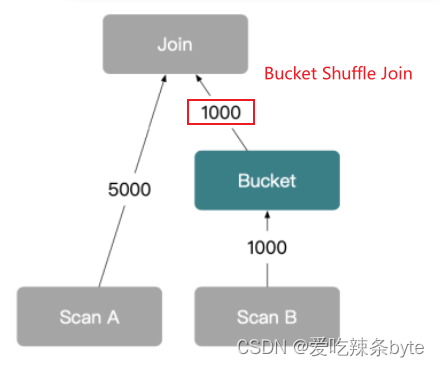
而Bucket Shuffle Join是在Broadcast的基础上进一步优化,将B表按照A表的分布方式,Shuffle到A表机器上进行Join操作,B表Shuffle的数据量全局只有一份,比Broadcast少传输了很多倍数量。所以它的网络开销是B,内存开销是B。
在FE之中保存了StarRocks每个表的数据分布信息,如果join语句命中了表的数据分布列,应该使用数据分布信息来减少join语句的网络与内存开销,这就是Bucket Shuffle Join的思路来源。
2.2 Bucket Shuffle Join工作原理
如下图展示了Bucket Shuffle Join的工作原理,sql语句是A表 join B表,并且join的等值表达式命中了A的数据分布列。而Bucket Shuffle Join会根据A表的数据分布信息,将B表的数据发送到对应的A表的数据存储计算节点。Bucket Shuffle Join的开销如下:
网络开销:Bucket Shuffle Join < min (Shuffle Join ,Broadcast Join ), 即:B < min(3B, A + B)
内存开销:Bucket Shuffle Join <= min (Shuffle Join ,Broadcast Join ), 即:B <= min(B, 3B)
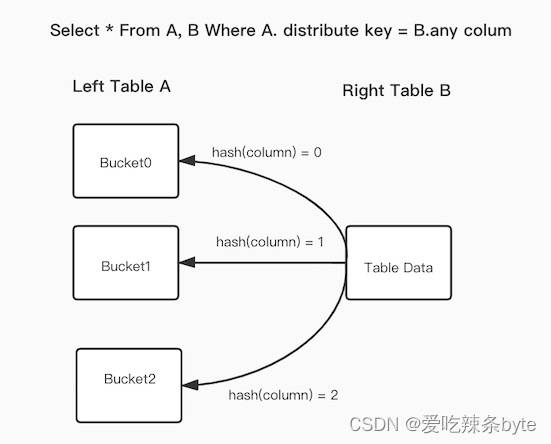
因此,和Shuffle Join、Broadcast Join相比较,Bucket Shuffle Join有着较为明显的性能优势,可以减少数据在节点间的传输耗时和Join时的内存开销,具备的优点有:
- Bucket Shuffle Join降低了网络和内存开销,使一些Join查询具有更好的性能,尤其是当FE能够执行左表的分区裁剪与桶裁剪时。
- 与Colocate Join不同, Bucket Shuffle Join对于表的数据分布方式并没有侵入性,对用户来说是透明的(无感知的),对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题。
- 可以为Join Reorder 提供更多可能分优化空间。
2.3 Bucket Shuffle Join规划规则
-
Bucket Shuffle Join 只生效于 Join 条件为等值的场景,原因与 Colocate Join 类似,它们都依赖 Hash 来计算确定的数据分布。
- 在等值Join条件之中包含两张表的分桶列,当左表的分桶列为等值的Join条件时,它有很大概率会被规划为Bucket Shuffle Join。
-
由于不同的数据类型的 Hash 值计算结果不同,所以 Bucket Shuffle Join 要求左表的分桶列的类型与右表等值 Join 列的类型需要保持一致,否则无法进行对应的规划。
-
Bucket Shuffle Join 只作用于StarRocks原生的OLAP表,对于ODBC,MySQL等外表,当其作为左表时是无法规划生效的。
- 对于分区表,由于每一个分区的数据分布规则可能不同,所以Bucket Shuffle Join只能保证左表为单分区时生效。所以在SQL执行之中,需要尽量使用
where条件使分区裁剪的策略能够生效。 - 假如左表为Colocate的表,那么它每个分区的数据分布规则是确定的,Bucket Shuffle Join能在Colocate表上表现更好。
三、应用案例
如果关联查询中Join等值表达式命中表 A 的分桶键 ,尤其是在表 A 和表 B 均是大表的情况下,可以设置 Join Hint 为 Bucket Shuffle Join。表 B 数据会按照表 A 数据的分布方式,Shuffle 到表 A 数据所在机器上,再进行 Join 操作。Bucket Shuffle Join 是在 Broadcast Join 的基础上进一步优化,Shuffle B 表的数据量全局只有一份,比 Broadcast Join 少传输了很多倍数据量。
在FE进行分布式查询规划时,优先选择的顺序为 Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。但是用户也可以通过显式 Hint来强制使用期望的 Join 类型,比如:
select k1 from t1 join [BUCKET] t2 on t1.k1 = t2.k2 group by t2.k2;
手动指定Join类型后,可以通过explain命令来查看Join是否为Bucket Shuffle Join:

ps: join hint 见文章: 分析查询 | StarRocks
参考文章:
Bucket Shuffle Join - Apache Doris
Apache Doris Join 优化原理介绍 - 掘金
这篇关于第6.3章:StarRocks查询加速——Bucket Shuffle Join的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






