本文主要是介绍Apache Doris的Bucket Shuffle Join实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1. 介绍
- 2. 原理
- 3. 使用
1. 介绍
两个表进行join时,让右表根据左边的数据分布,进行数据的shuffle,再进行join。减少跨节点的数据传输。加速查询
2. 原理
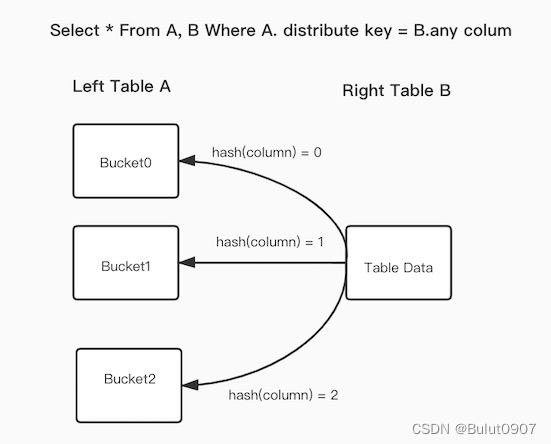
SQL语句为A表join B表,并且join的等值表达式命中了A的数据分布列。而Bucket
Shuffle Join会根据A表的数据分布信息,将B表的数据发送到对应的A表的数据存储节点。Bucket Shuffle Join的网络开销和内存开销都是B
对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题
3. 使用
设置session变量。该变量默认是开启的。开启后是否命中Bucket Shuffle Join对用户来说是透明的
mysql> show variables like '%bucket_shuffle_join%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| enable_bucket_shuffle_join | true |
+----------------------------+-------+
1 row in set (0.02 sec)mysql>
在FE进行分布式查询规划时,优先选择的顺序为Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。但是如果用户显式hint了Join的类型,则上述的选择优先顺序则不生效。如:
mysql> select * from click a join [shuffle] user_live b on a.user_id = b.user_id and a.city = b.city;
提升命中Bucket Shuffle Join的条件
- 只作用于Doris原生的OLAP表,对于外部表,当其作为左表时是无法生效的
- Bucket Shuffle Join只生效于Join条件为等值的场景,因为依赖hash来计算确定的数据分布
-
- 要求左表的分桶列的类型与右表等值join列的类型需要保持一致
- 在等值Join条件之中包含两张表的分桶列。或者当左表的分桶列为等值的Join条件时,它有很大概率会被规划为Bucket Shuffle Join
- 对于分区表,由于每一个分区的数据分布规则可能不同(比如分桶数),所以 Bucket Shuffle Join只能保证左表为单分区时生效。所以在SQL中尽量使用where 条件进行分区裁剪,以便策略能够生效。对于左表为多分区可能会生效
查看查询语句的执行计划
mysql> explain select * from click a join user_live b on a.user_id = b.user_id and a.city = b.city;
+------------------------------------------------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------------------------------------------------+
......省略部分......
| 2:VHASH JOIN |
| | join op: INNER JOIN(BUCKET_SHUFFLE)[Tables are not in the same group] |
| | equal join conjunct: `a`.`user_id` = `b`.`user_id` |
| | equal join conjunct: `a`.`city` = `b`.`city` |
| | runtime filters: RF000[in_or_bloom] <- `b`.`user_id`, RF001[in_or_bloom] <- `b`.`city` |
| | cardinality=0 |
| | vec output tuple id: 2 | |
| |----3:VEXCHANGE |
| | |
| 0:VOlapScanNode |
......省略部分......
34 rows in set (0.01 sec)mysql>
join op的join为BUCKET_SHUFFLE,表示使用的是Bucket Shuffle Join
这篇关于Apache Doris的Bucket Shuffle Join实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


