本文主要是介绍Elasticsearch:Bucket script 聚合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Bucket script 聚合是一个父管道(parent pipeline)聚合,它执行一个脚本,该脚本可以对父多桶聚合中的指定指标执行每个桶的计算。 指定的指标必须是数字,并且脚本必须返回一个数值。有关 pipeline 聚合的内容,你可以阅读文章 “Elasticsearch:pipeline aggregation 介绍”。
Bucket script 聚合
用法
单独的 bucket_script 聚合看起来像这样:
{"bucket_script": {"buckets_path": {"my_var1": "the_sum", "my_var2": "the_value_count"},"script": "params.my_var1 / params.my_var2"}
}这里,my_var1 是要在脚本中使用的存储桶路径的变量名称,the_sum 是要用于该变量的指标的路径。
| 参数名称 | 描述 | 强制要求 | 默认值 |
|---|---|---|---|
| script | 为此聚合运行的脚本。 该脚本可以是内联的、文件的或索引的。 (有关详细信息,请参阅脚本) | 必须 | |
| buckets_path | 脚本变量的映射及其到我们希望用于变量的存储桶的关联路径(有关更多详细信息,请参见 buckets_path 语法) | 必须 | |
| gap_policy | 在数据中发现差距时应用的策略(有关详细信息,请参阅处理数据中的差距) | 可选 | skip |
| format | 输出值的 DecimalFormat 模式。 如果指定,则在聚合的 value_as_string 属性中返回格式化的值 | 可选 | null |
在以下的展示中,我使用 Elastic Stack 8.4.3 来进行展示。
示例
为了说明问题的方便,我们来使用一个示例来进行详细说明。我将使用 Kibana 自带的 eCommerce 索引进行展示。我们的目的是:找出每天销售的 Men's Clothing 这个类别的销售额在总体销售额中的比例。
在本练习中,我们使用 Kibana 自带的一个例子来进行展示:

这样我能就在 Elasticsearch 中创建了一个叫做 kibana_sample_data_ecommerce 的索引。这个一个 eCommerce 的数据。我们可以在 Discover 中进行查看:
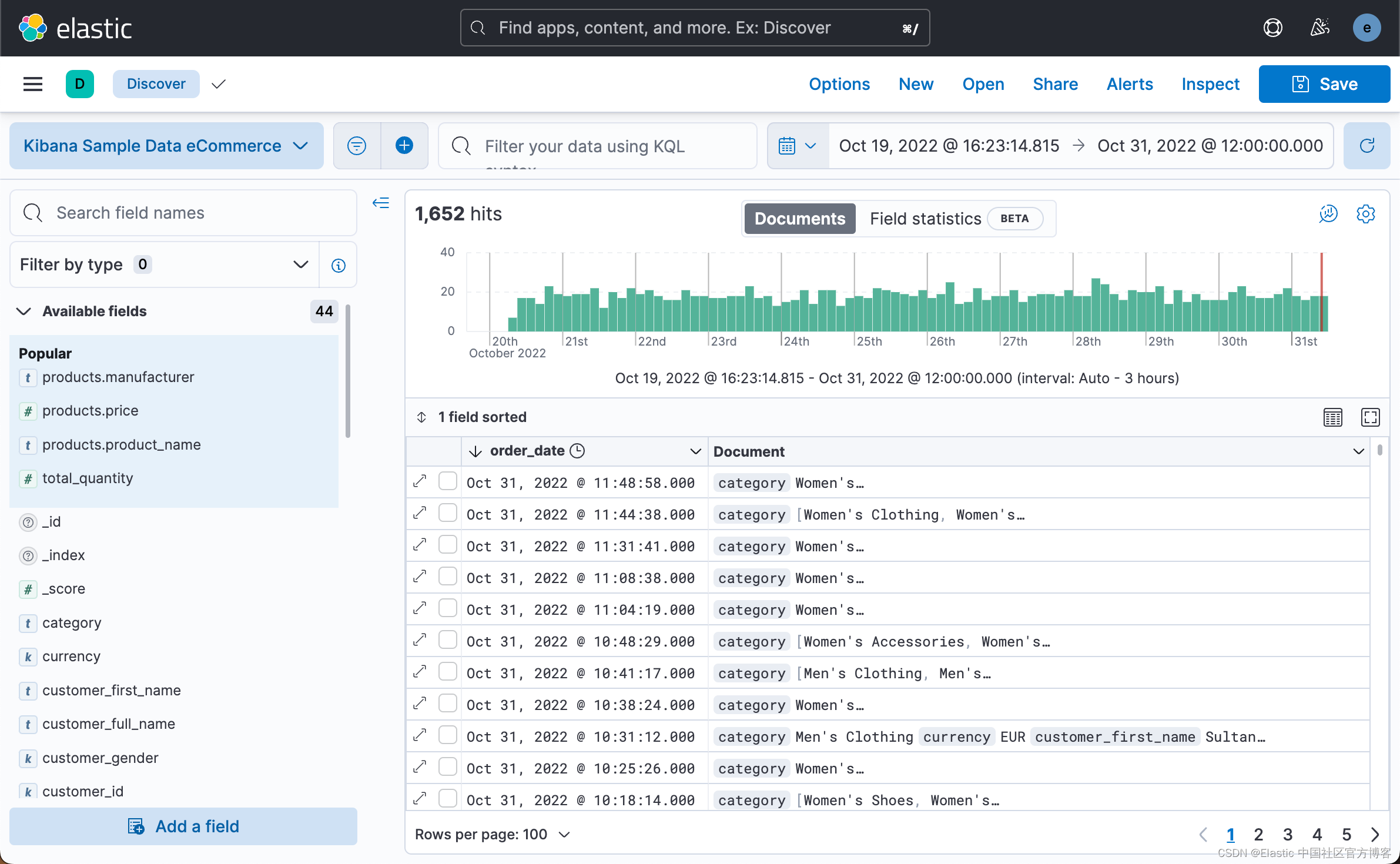
如上所示,上面的数据展示的是从 10 月 20 号到 10 月 31 号的数据。
我们可以使用 Lens 来展示每天的文档数:
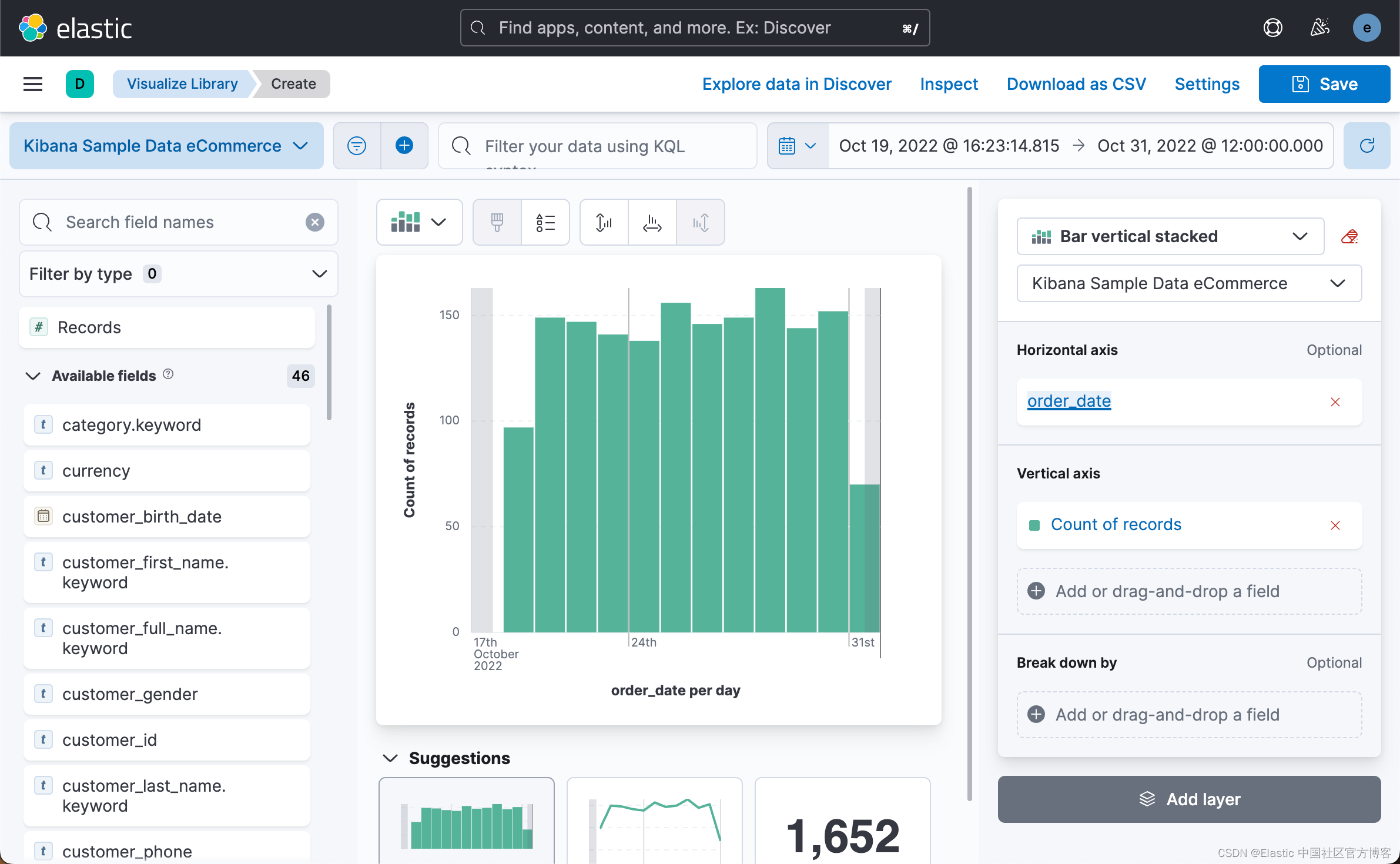
如上所示,每天都有一定数量的文档。上面的聚合相当于如下的命令:
GET kibana_sample_data_ecommerce/_search
{"size": 0,"aggs": {"sales_per_day": {"date_histogram": {"field": "order_date","calendar_interval": "day"}}}
}上面的聚合返回如下的数据:
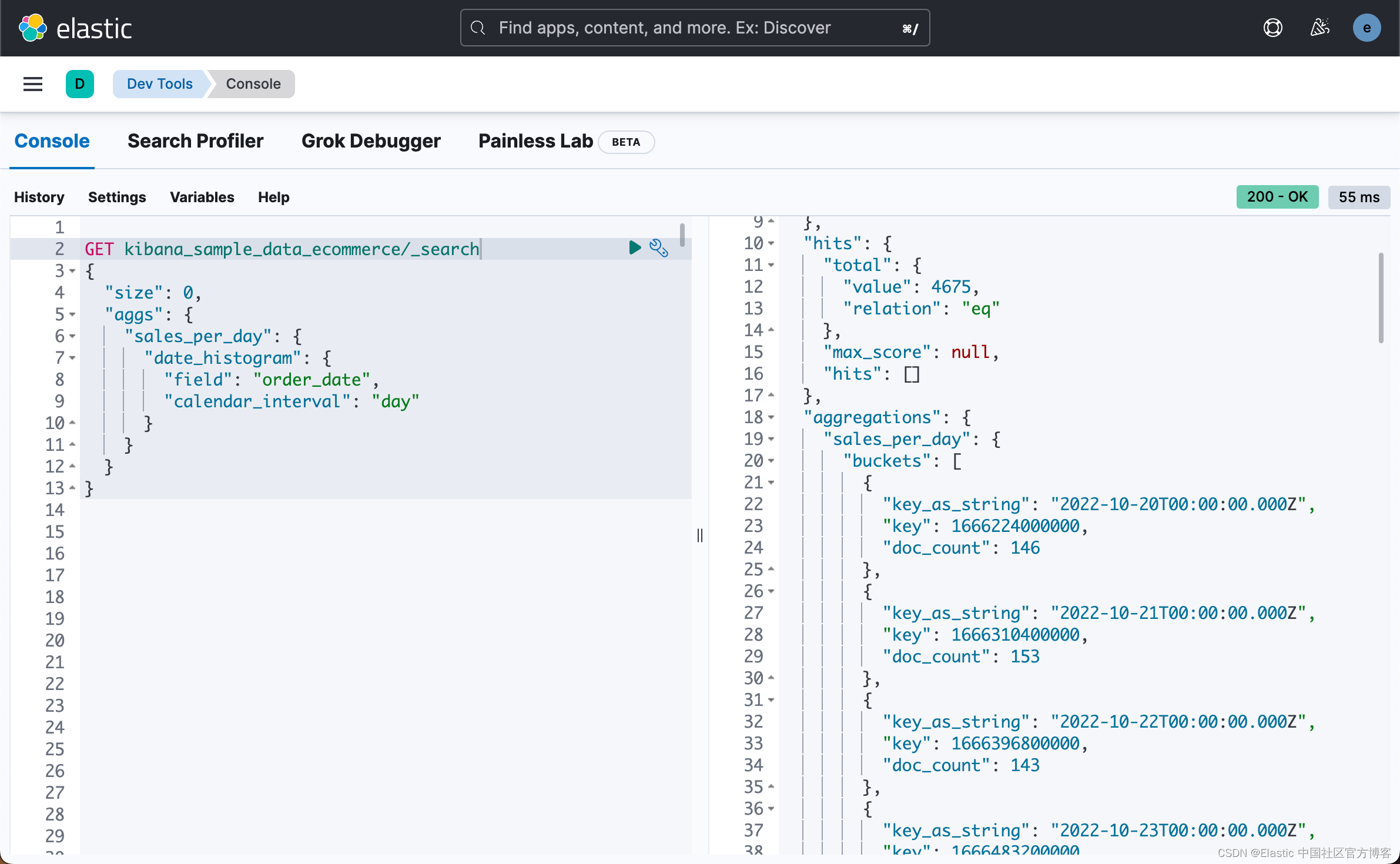
我们可以通过如下的命令来得到每天的总销售额:
GET kibana_sample_data_ecommerce/_search?filter_path=aggregations
{"size": 0,"aggs": {"sales_per_day": {"date_histogram": {"field": "order_date","calendar_interval": "day"},"aggs": {"total_sales": {"sum": {"field": "products.base_price"}}}}}
}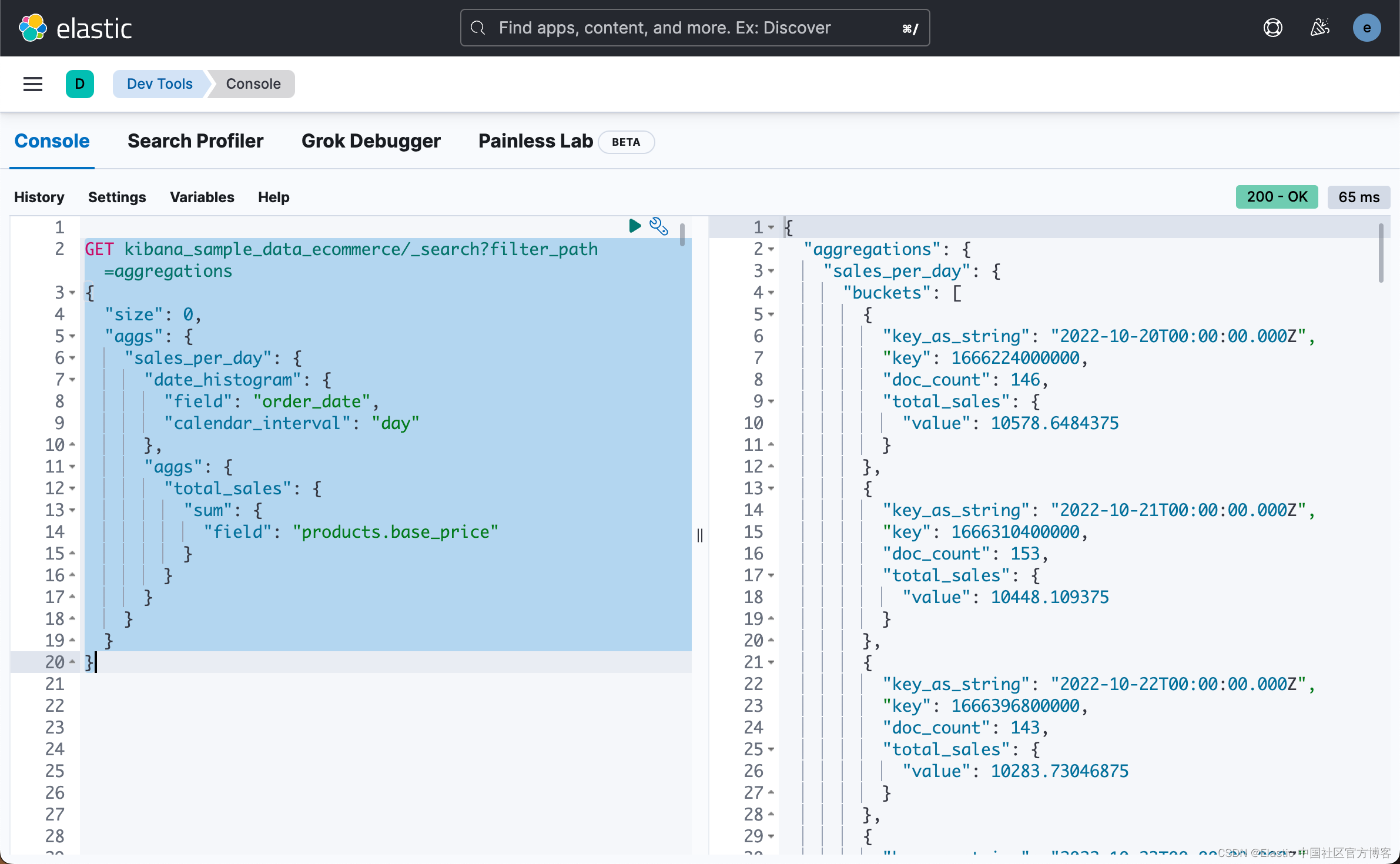
如上所示,我们求出了每天销售的总额。为了能够求出每天卖出的 Men's clothing 这个类别的总额,我们可以使用另外一个叫做 filter 的聚合:
GET kibana_sample_data_ecommerce/_search?filter_path=aggregations
{"size": 0,"aggs": {"sales_per_day": {"date_histogram": {"field": "order_date","calendar_interval": "day"},"aggs": {"total_sales": {"sum": {"field": "products.base_price"}},"man's_clothing": {"filter": {"term": {"category.keyword": "Men's Clothing"}},"aggs": {"sales": {"sum": {"field": "products.base_price"}}}}}}}
}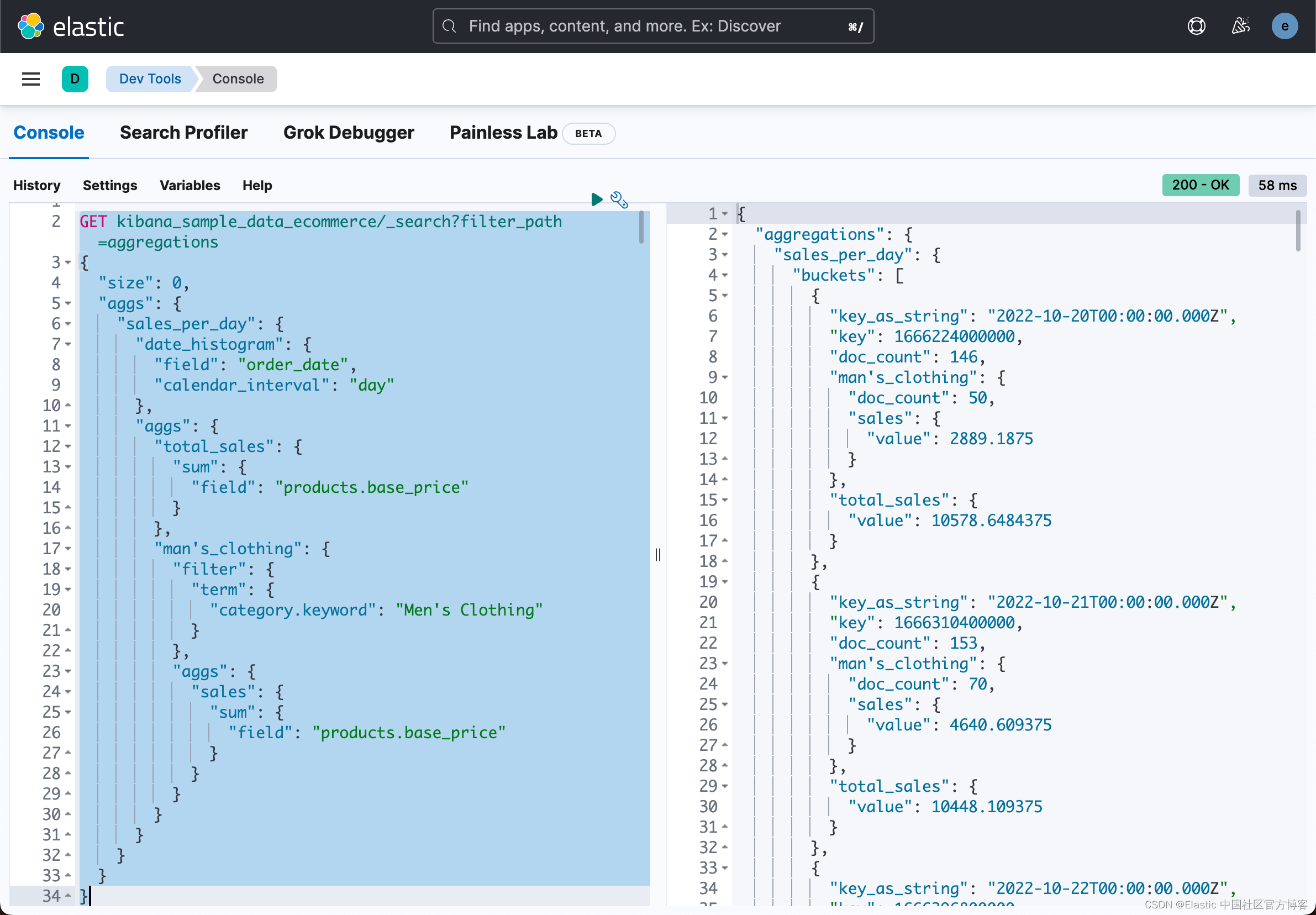
如上所示,我们至此求出了 Men's Clothing 这个类别的每天的销售总额。
我们接下来使用 bucket script 聚合来求出每天的 Men's Clothing 这个类别的总额和当天销售总额的百分比:
GET kibana_sample_data_ecommerce/_search?filter_path=aggregations
{"size": 0,"aggs": {"sales_per_day": {"date_histogram": {"field": "order_date","calendar_interval": "day"},"aggs": {"total_sales": {"sum": {"field": "products.base_price"}},"man's_clothing": {"filter": {"term": {"category.keyword": "Men's Clothing"}},"aggs": {"sales": {"sum": {"field": "products.base_price"}}}},"man's_clothing_percentage": {"bucket_script": {"buckets_path": {"mans_clothing": "man's_clothing>sales","total_sales": "total_sales"},"script": "params.mans_clothing / params.total_sales * 100"}}}}}
}在上面的 man's_clothing_percentage 聚合中,它使用了其它聚合的结果并算出新的聚合的值。这种聚合被称之为 pipeline 聚合。 特别需要指出的是 man's_clothing>sales 不是布尔比较大小的算式,而是引用聚合值的路径。
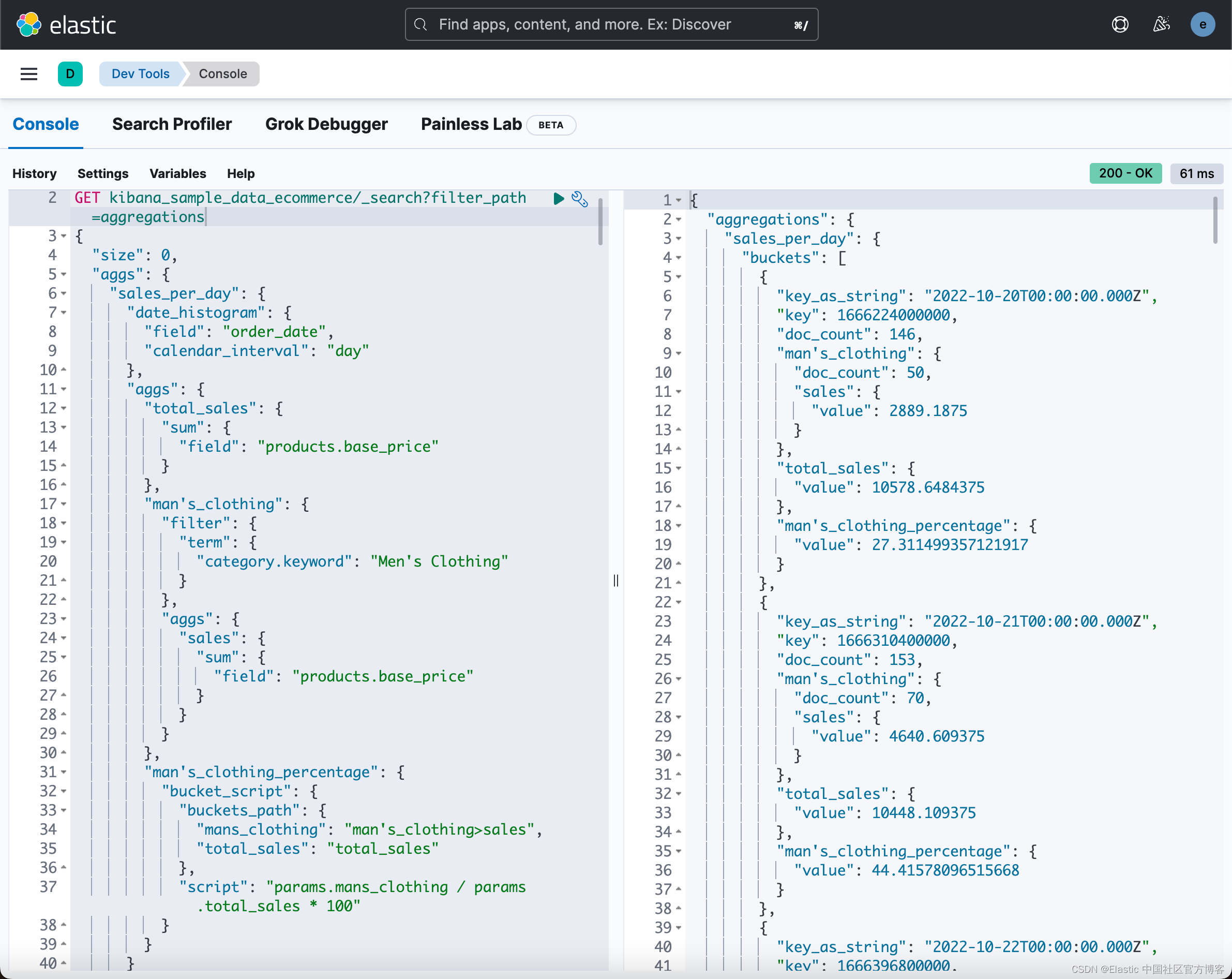
如上所示,我们可以看到每天的 Men's Clothing 的销售额的百分比。
这篇关于Elasticsearch:Bucket script 聚合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


