本文主要是介绍知识图谱在提升大语言模型性能中的应用:减少幻觉与增强推理的综述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
幻觉现象指的是模型在生成文本时可能会产生一些听起来合理但实际上并不准确或相关的输出,这主要是由于模型在训练数据中存在知识盲区所致。 为了解决这一问题,研究人员采取了多种策略,其中包括利用知识图谱作为外部信息源。知识图谱通过将信息组织成结构化格式,捕捉现实世界实体之间的关系,从而为机器和人类提供了一种理解复杂关系的方式。

本文中减少幻觉方面的有效性的方法分为三个主要类别:知识感知推理(Knowledge-Aware Inference)、知识感知学习(Knowledge-Aware Learning)和知识感知验证(Knowledge-Aware Validation)。每个类别都包含了不同的技术,它们在提升LLMs性能方面都有独特的贡献。

知识感知推理 在知识感知推理方面,讨论了如何通过整合KGs来增强LLMs的推理能力。例如,通过将知识图谱与语言模型结合,可以在输入层提供结构化的知识,从而增强模型对上下文的理解。这种方法特别适用于需要多步推理的问题,它可以帮助模型通过一系列的中间推理步骤来模拟人类的思考过程,从而提高复杂推理任务的性能。 此外,我们还探讨了如何利用知识图谱来增强模型的检索能力和控制生成过程。例如,通过知识图谱增强的检索方法,模型能够在生成过程中检索相关信息,减少幻觉现象,而不改变LLM的架构。这些方法通过提供更准确的上下文信息,提高了输出的准确性和相关性。

知识感知学习 在知识感知学习方面,分析了如何利用KGs来优化LLMs的学习过程。这包括在模型预训练阶段改进训练数据的质量,以及通过微调预训练语言模型来适应特定任务或领域。我们特别关注了如何通过知识增强的模型、知识引导的掩蔽、知识融合和知识探测来提升LLMs的性能。 知识增强的模型,如ERNIE和KALM,通过在预训练阶段引入知识图谱,增强了模型的语言表示能力。知识引导的掩蔽方法,如SKEP和GLM,通过在文本中掩盖特定的实体,并利用知识图谱中的关系知识来预测这些实体,从而提高了模型在问答和知识库完成等任务上的性能。知识融合方法,如JointLK和LKPNR,通过将知识图谱与LLMs结合,增强了模型对复杂文本的语义理解能力。知识探测方法则通过评估模型的事实性和常识知识来提升模型性能。
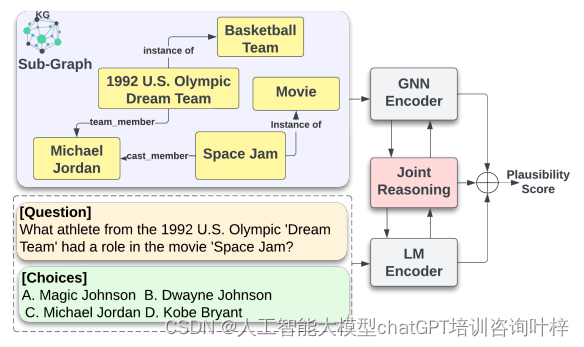
知识感知验证 最在知识感知验证方面,讨论了如何使用结构化数据作为事实检查机制,以验证模型的信息。知识图谱可以提供全面解释,并用于证明模型的决策。这些方法有助于确保事实的一致性,并提高生成内容的可靠性。 例如,fact-aware语言模型KGLM通过引用知识图谱来生成与上下文相关的实体和事实。SURGE方法检索与上下文高度相关的三元组作为子图,以验证模型生成的文本。FOLK方法使用一阶逻辑(FOL)谓词进行在线错误信息的声明验证,并生成明确的解释,帮助人类事实检查者理解和解释模型的决策。
研究表明,虽然在整合知识图谱以增强LLMs方面已经取得了实质性进展,但仍需要持续的创新。我们提出了未来研究方向,以促进更先进的知识图谱增强LLMs的发展。这包括改进知识图谱的质量、开发专家混合(MoE)LLMs、统一符号和次符号方法、加强LLM和KG的协同作用,以及引入因果关系意识。
论文链接:https://arxiv.org/pdf/2311.07914
这篇关于知识图谱在提升大语言模型性能中的应用:减少幻觉与增强推理的综述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





