幻觉专题

大语言模型的32种消除幻觉的技术,你都了解吗?
大模型幻觉问题是计算机语言学中一个重要的研究方向。为减轻幻觉,研究人员提出了多种策略,比如反馈机制、外部信息检索等,但一直缺少一篇详细综述将近期关于幻觉的研究工作串联起来。 今天介绍的这篇文章详细梳理了大语言模型幻觉消除技术,将其系统的分为提示工程和模型开发两大类。 提示工程涉及基于检索增强的方法、基于反馈的策略或提示微调;模型开发则可分为多种方法,包括新的解码策略、基于知识图谱的优化、新增的

ICLR2024: 大视觉语言模型中对象幻觉的分析和缓解
https://arxiv.org/pdf/2310.00754 https://github.com/YiyangZhou/LURE 背景 对象幻觉:生成包含图像中实际不存在的对象的描述 早期的工作试图通过跨不同模式执行细粒度对齐(Biten et al.,2022)或通过数据增强减少对象共现模式(Rohrbach et al.,2018; Kim et al.,2023)来解决小规模多

【杂记】裂脑人实验和语言模型幻觉
【杂记】裂脑人实验和语言模型幻觉 模型的自主意识在哪里,人的自我认知在哪里?自然而然的,“裂脑人” 这个词突然出现在我脑海里。然后随意翻了翻相关的文章,觉得这个问题和目前大模型面临的幻觉问题也高度相关,遂随笔记录。 裂脑人 什么是裂脑人?人的大脑左右半脑本来是一个整体,因为先天或者后天的原因让左右半脑分开不产生连接,就是“裂脑”。过去这个方法被作为控制恶性癫痫的治疗手段。 一些铺垫知识
![[240620] 英特尔将使用其 3纳米级工艺技术大批量投入生产 | 科学家开发新算法来发现人工智能的“幻觉”](/front/images/it_default2.jpg)
[240620] 英特尔将使用其 3纳米级工艺技术大批量投入生产 | 科学家开发新算法来发现人工智能的“幻觉”
目录 英特尔将使用其 3纳米级工艺技术大批量投入生产科学家开发新算法来发现人工智能的“幻觉” 英特尔将使用其 3纳米级工艺技术大批量投入生产 英特尔周三表示,其名为 Intel 3 的 3纳米级工艺技术已经在两个生产基地进入大规模生产 新工艺不仅提升了性能和晶体管密度,还支持用于超高性能应用的 1.2V 电压近期推出的英特尔至强 6 Sierra Forest 和 Grani
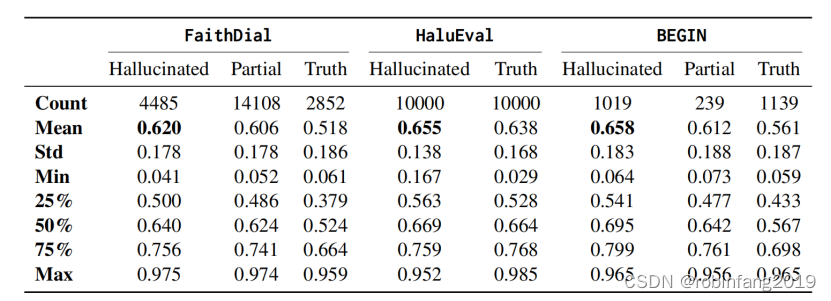
有待挖掘的金矿:大模型的幻觉之境
人工智能正在迅速变得无处不在,在科学和学术研究中,自回归的大型语言模型(LLM)走在了前列。自从LLM的概念被整合到自然语言处理(NLP)的讨论中以来,LLM中的幻觉现象一直被广泛视为一个显著的社会危害和一个关键的瓶颈,阻碍了LLM在现实世界中的应用。无论是在流行且全面的学术调查中,还是在面向公众的技术报告中,都将幻觉问题定位为LLM的主要伦理和安全陷阱之一,应该与其他问题(如偏见和毒

【大模型认识】警惕AI幻觉,利用插件+微调来增强GPT模型
文章目录 一. 大模型的局限1. 大模型不会计算2. 甚至明目张胆的欺骗 二. 使用插件和微调来增强GPT模型1. 模型的局限性2. 插件来增强大模型的能力3. 微调技术-提高特定任务的准确性 一. 大模型的局限 1. 大模型不会计算 LLM根据给定的输入提示词逐个预测下一个词(也就是标记),从而生成回答。在大多数情况下,模型的输出是与提问相关的,并且完全可用,但是在使用语言
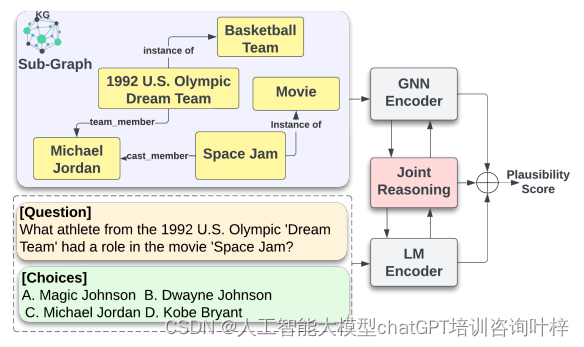
知识图谱在提升大语言模型性能中的应用:减少幻觉与增强推理的综述
幻觉现象指的是模型在生成文本时可能会产生一些听起来合理但实际上并不准确或相关的输出,这主要是由于模型在训练数据中存在知识盲区所致。 为了解决这一问题,研究人员采取了多种策略,其中包括利用知识图谱作为外部信息源。知识图谱通过将信息组织成结构化格式,捕捉现实世界实体之间的关系,从而为机器和人类提供了一种理解复杂关系的方式。 本文中减少幻觉方面的有效性的方法分为三个主要类别:知识感知推理(Know
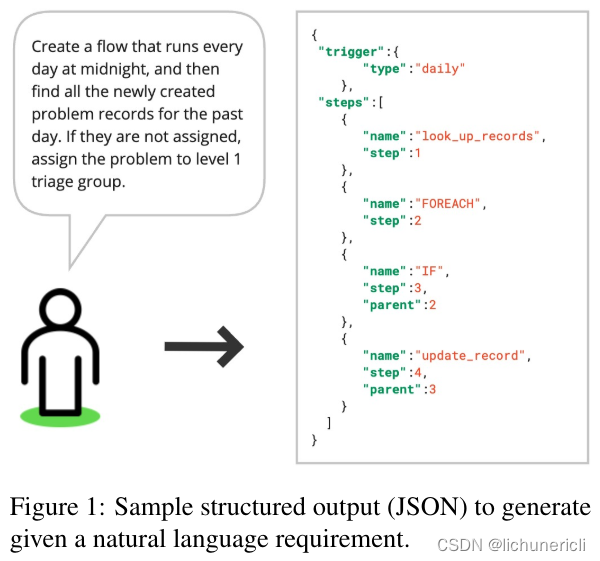
ServiceNow 研究:通过RAG减少结构化输出中的幻觉
论文地址:https://arxiv.org/pdf/2404.08189 原文地址:rag-hallucination-structure-research-by-servicenow 在灾难性遗忘和模型漂移中,幻觉仍然是一个挑战。 2024 年 4 月 18 日 灾难性遗忘: 这是在序列学习或连续学习环境中出现的问题,其中一个模型被训练来执行多个任务,但是学习新任务时会导致模型在先前

【AIGC调研系列】大型语言模型如何减少幻觉生成
在解读大型语言模型(LLMs)中的长格式事实性问题时,我们首先需要认识到这些模型在生成内容时可能会产生与既定事实不一致的情况,这种情况通常被称为“幻觉”[2][3]。这种现象不仅可能导致信息的误传,还可能对社会造成误导和伤害[3]。因此,提高LLMs的事实性成为了一个重要的研究方向。 为了提高LLMs的事实性,研究人员提出了多种方法。一种方法是通过对模型进行微调,使其更加注重事实性,而无需人工标

读天才与算法:人脑与AI的数学思维笔记05_算法的幻觉
1. 自下而上 1.1. 代码在未来可以自主学习、适应并进行自我改进 1.2. 程序员通过编程教会计算机玩游戏,而计算机却会比教它的人玩得更好,这种输入寡而输出众的事情不大可能实现 1.3. 早在20世纪50年代,计算机科学家们就模拟该过程创造了感知器 1.3.1. 其原理是:神经元就像一个逻辑门,接收输入的信息,然后通过计算来判断是否触发并产生兴奋反应 1.3.2. 通过调整权值

谁来治好AI的「幻觉」?面对众多对抗样本攻击,深度神经网络该何去何从
选自Wired 作者:Tom Simonite 机器之心编译 参与:路雪、黄小天 2 月 3 日,来自 MIT、UC Berkeley 的 Athalye 等人宣布其研究攻破了 ICLR 2018 大会的接收论文中的 7 篇有关防御对抗样本的研究。之前,轻微扰动导致停车标志被无视、把熊猫认成长臂猿、把校车认成鸵鸟等等各种案例层出不穷。那么关于


大语言模型(LLM)为什么会产生幻觉?
一、幻觉的概念 在大语言模型(LLM)的语境之下,“幻觉”(hallucination)指的是模型在没有足够证据支持的情况下,生成的错误或虚构的信息。这种现象在自然语言处理(NLP)任务中尤其突出,如文本生成、摘要、对话系统等。大语言模型如GPT系列,在生成连贯、流畅的文本的同时,也可能产生与事实不符的内容,这就是所谓的"幻觉" 二、幻觉的特点 根据我们使用ChatGPT的常用场景,我总结了
脏读 不可重复读 幻像(幻觉读)
脏读 脏读包含未提交数据的读。例如,事务1 更改了某行。事务2 在事务1 提交更改之前读取已更改的行。如果事务1 回滚更改,则事务2 便读取了逻辑上从未存在过的行。 脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是脏数据,依据脏数据所做

浅谈大模型“幻觉”问题
大模型的幻觉大概来源于算法对于数据处理的混乱,它不像人类一样可以by the book,它没有一个权威的对照数据源。 什么是大模型幻觉 大模型的幻觉(Hallucination)是指当人工智能模型生成的内容与提供的源内容不符或没有意义的现象。这可能包括逻辑错误、捏造事实、数据驱动的偏见等。产生幻觉的原因主要是由于训练数据的压缩以及信息的不一致、受限或过时造成的。为了减轻幻觉,可以采取

一份全面的大模型「幻觉」综述
文章目录 一份全面的大模型「幻觉」综述1. 幻觉的分类2. 幻觉的来源2.1 幻觉来自数据2.2 幻觉来自训练2.3 幻觉来自生成/推理 3. 幻觉的检测3.1 事实性幻觉的检测3.2 忠实性幻觉的检测 4. 幻觉的评估5. 幻觉的解决 一份全面的大模型「幻觉」综述 相信大家在使用ChatGPT或者其他大模型时会遇到这样的情况,模型答非所问甚至自相矛盾。 虽然大语言模型(LL

Woodpecker: Hallucination Correction for Multimodal Large Language Models----啄木鸟:多模态大语言模型的幻觉校正
Abstract 幻觉是笼罩在快速发展的多模态大语言模型(MLLM)上的一个大阴影,指的是生成的文本与图像内容不一致的现象。为了减轻幻觉,现有的研究主要采用指令调整的方式,需要用特定的数据重新训练模型。在本文中,我们开辟了一条不同的道路,引入了一种名为 Woodpecker 的免训练方法。就像啄木鸟治愈树木一样,它从生成的文本中挑选并纠正幻觉。具体来说,啄木鸟由五个阶段组成:关键概念提取、问题制

人工智能产生的幻觉问题真的能被看作是创造力的另一种表现形式吗?
OpenAI的首席执行官山姆·奥特曼(Sam Altman)曾声称,人工智能产生的“幻觉”其实未尝不是一件好事,因为实际上GPT的优势正在于其非凡的创造力。 目录 一.幻觉问题的概念 二.幻觉产生的原因 三.幻觉的分类 四.减轻AI的幻觉问题到底应如何着手 一.幻觉问题的概念 人工智能的幻觉问题是指其在没有充分训练数据支持的情况下自信地做出的响应。这种响应可能是由于数据不完
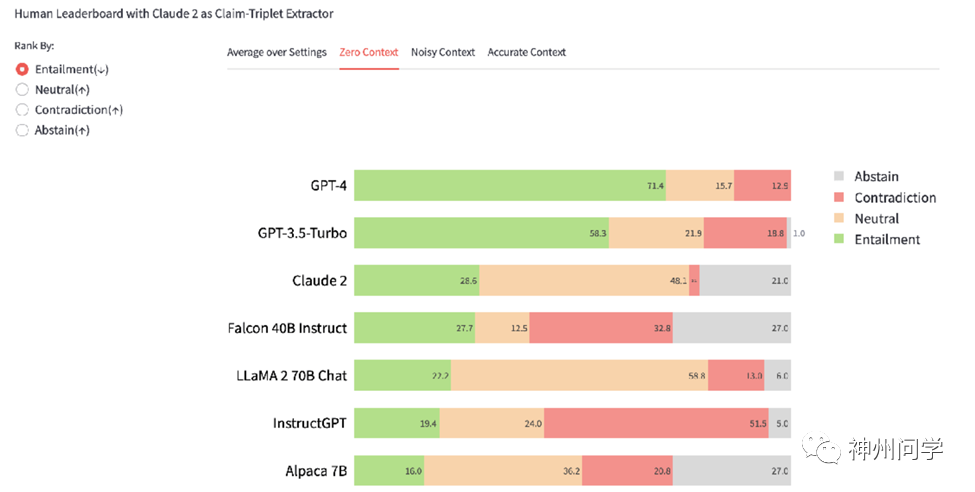
AI误导游戏——LLM的危险幻觉
在当今科技高速发展的时代,人工智能(AI)已成为日常生活和工作中不可或缺的一部分。特别是大语言模型(LLM)如GPT-4等,它们的智能表现令人惊叹,广泛应用于文本生成、语言翻译、情感分析等多个领域。然而,随着这些技术的快速发展,一个被广泛忽视的问题逐渐显现出来:大模型所具有的“幻觉”现象。这些幻觉可能会导致误导信息的产生,引发一系列社会、法律和伦理上的问题。 什么是幻觉
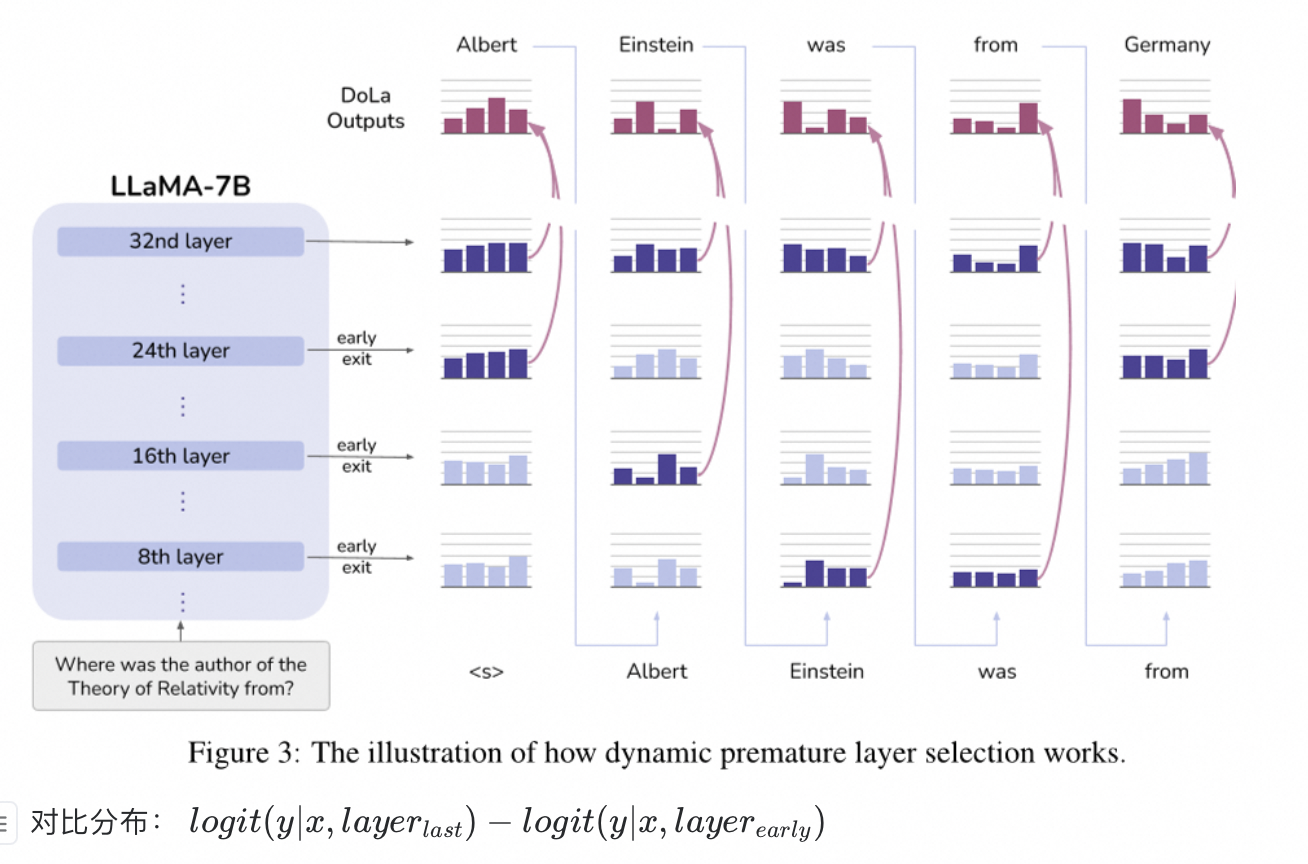
对比不同Layer输出,在解码阶段消除大模型幻觉
实现方式 对比最后一层出来的logit,和前面Layer出来的logit,消除差异过大的分布,从而降低幻觉: 最后一层Layer出来的logit容易的得到; 选择与最后一层的logit最不相似的分布的那层结果 实现原理 也是很简单的对比方式,最终的logit由最后一层的Layer输出的logit,减去前期选择的层的logit, 得到最终的logit 地址 https
![[机缘参悟-130] :《洞见》:为什么佛学是真的 -1-人的感觉、感受是自然选择的结果,是为基因传承服务的,苦和烦等各种感觉是个性化的幻觉,从心理学看佛学](https://img-blog.csdnimg.cn/direct/67aceeeb029b4ea6aea32299b18b8e10.png)
[机缘参悟-130] :《洞见》:为什么佛学是真的 -1-人的感觉、感受是自然选择的结果,是为基因传承服务的,苦和烦等各种感觉是个性化的幻觉,从心理学看佛学
目录 一、心理学对人的感觉的解释 1.1 感觉、知觉/感知、思维 =》意识结果 1.2 感觉与其种类 1.3 知觉 1.4 感知 1.5 思维 1.6 意识 1.7 潜意识:灵修关注的领域 1.8 情绪 二、情绪管理 2.1 情绪管理的方法 2.2 积极的思维方式 2.3 情绪管理的本质 三、进化心理学对感知和情绪的解释 3.1 概述 3.2 进化心理学解释为什么人

【知识图谱+大模型的紧耦合新范式】Think-on-Graph:解决大模型在医疗、法律、金融等垂直领域的幻觉
Think-on-Graph:解决大模型在医疗、法律、金融等垂直领域的幻觉 Think-on-Graph 原理ToG 算法步骤:想想再查,查查再想实验结果 论文:https://arxiv.org/abs/2307.07697 代码:https://github.com/IDEA-FinAI/ToG Think-on-Graph 原理 幻觉是什么:大模型的

翻译: GPT-4 Vision征服LLM幻觉hallucinations 升级Streamlit六
GPT-4 Vision 系列: 翻译: GPT-4 with Vision 升级 Streamlit 应用程序的 7 种方式一翻译: GPT-4 with Vision 升级 Streamlit 应用程序的 7 种方式二翻译: GPT-4 Vision静态图表转换为动态数据可视化 升级Streamlit 三翻译: GPT-4 Vision从图像转换为完全可编辑的表格 升级Streamlit四翻

AI解读视频张口就来?这种「幻觉」难题Vista-LLaMA给解决了
AI解读视频张口就来?这种「幻觉」难题Vista-LLaMA给解决了 Vista-LLaMA 在处理长视频内容方面的显著优势,为视频分析领域带来了新的解决框架。 近年来,大型语言模型如 GPT、GLM 和 LLaMA 等在自然语言处理领域取得了显著进展,基于深度学习技术能够理解和生成复杂的文本内容。然而,将这些能力扩展到视频内容理解领域则是一个全新的挑战 —— 视频不仅包含丰富多变的视觉
向量数据库如何解决大语言模型的“幻觉”问题
向量数据库如何解决大语言模型的“幻觉”问题 向量数据库在解决大语言模型的“幻觉”问题方面可以发挥一定的作用。这个问题通常指的是大型语言模型在生成文本时过度依赖于训练数据,导致生成的内容过于特定,缺乏广泛的泛化性。以下是向量数据库可能采取的一些方法: 多样性的文本表示: 向量数据库存储了大量的文本数据,包括来自多个领域和主题的文本。这些文本的多样性可以为大型语言模型提供更广泛的语境

如何解决LLM(大型语言模型)幻觉问题
LLM幻觉问题是什么? LLM(大型语言模型)幻觉问题指的是当大型语言模型(如我这样的)在处理请求时产生的不准确或虚构的信息。这些幻觉可能是因为模型的训练数据不足、错误或偏见,或者是因为模型在处理某些特定类型的问题时的局限性。具体来说,这些问题可能包括: 生成虚假或不准确的信息:模型可能会生成与现实不符或完全虚构的答案。过度自信:即使提供的信息不准确或虚假,模型也可能表现出过度的自信。重复或矛