本文主要是介绍AI误导游戏——LLM的危险幻觉,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在当今科技高速发展的时代,人工智能(AI)已成为日常生活和工作中不可或缺的一部分。特别是大语言模型(LLM)如GPT-4等,它们的智能表现令人惊叹,广泛应用于文本生成、语言翻译、情感分析等多个领域。然而,随着这些技术的快速发展,一个被广泛忽视的问题逐渐显现出来:大模型所具有的“幻觉”现象。这些幻觉可能会导致误导信息的产生,引发一系列社会、法律和伦理上的问题。
什么是幻觉
随着大语言模型(LLM)的兴起,基于这些大模型开发的应用层出不穷。然而,公众对这些应用的接纳程度仍显谨慎。其中一个主要原因是大型模型所固有的“幻觉”问题。
所谓“大模型幻觉”是什么呢?根据近期发表的综述文章 《Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models》,在自然语言处理领域,幻觉指的是模型生成无关或对来源内容不忠实的内容。文章将大模型的幻觉归结为三大类:
1. 输入冲突型幻觉:模型生成的内容与用户提供的源输入不符;
2. 上下文冲突型幻觉:模型生成的内容与之前生成的信息相冲突;
3. 事实冲突型幻觉:模型生成的内容与已知的世界知识不符。
尽管某些幻觉易于辨识,但有些幻觉,特别是在需要深入数据分析才能得出结论的情境中,却不易迅速识别。在法律等行业,这种幻觉的潜在后果可能是灾难性的。例如,一名纽约律师在联邦法院提交的法律简报中引用了由 ChatGPT 生成的虚假案例,可能因此面临制裁。原告律师 Steven A. Schwartz 表示,他在准备一项驳回动议的回应时咨询了 ChatGPT 进行法律研究。然而,法官 Kevin Castel 发现提交的案例中包含六起似乎是虚构的司法判决,带有虚假引用和引文,这是一个前所未有的情况。这一事件表明,大模型应用中的幻觉问题可能成为阻碍其广泛应用的重大挑战。
这些幻觉是如何产生的?
大模型产生幻觉的原因可从数据和模型两个层面理解。在数据层面,幻觉的一个主要原因是训练数据的质量和多样性问题。若训练数据含有错误或偏见,例如通过众包或网络爬虫收集的不准确信息,模型可能会学习并记忆这些不准确内容。此外,数据中的重复信息也可能导致模型对某些模式或信息产生偏见,影响输出的准确性。因此,数据质量直接关系到模型的可靠性和输出真实性。
在模型层面,幻觉的产生与模型结构、解码算法及训练过程中的偏差相关。例如,较弱的模型架构(如早期的RNN)可能导致严重的幻觉问题,尽管在当前的大模型中,这种情况较少见。解码算法也起关键作用,高不确定性的采样算法(如top-p采样)会增加幻觉风险。此外,训练和测试阶段的不匹配(即暴露偏差),特别是在生成长篇回应时,也可能导致模型产生幻觉。最后,模型在预训练阶段可能学习到的错误知识,在后续应用中也可能导致幻觉问题。因此,模型设计和训练策略对减少幻觉同样至关重要。
目前都有哪些辨别幻觉的工作进展
各路研究机构已经开始了对大模型的幻觉问题的研究和探索。近期产生了许多对目前各种流行大模型的幻觉测试。
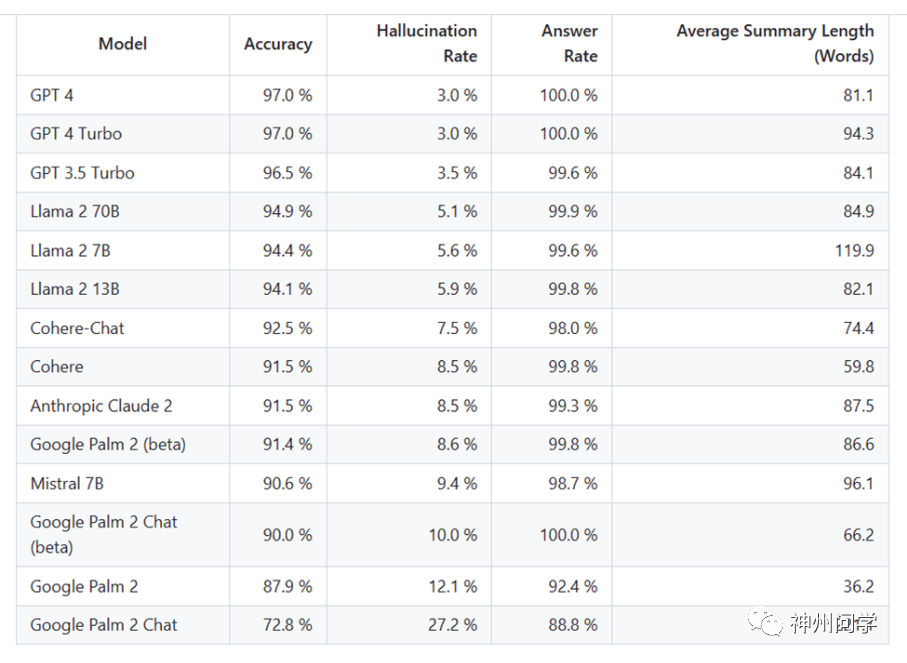
上个月,Vectara 发布了一个 AI 幻觉排行榜,该排行榜根据各种主流 AI 聊天机器人避免“幻觉”的能力进行排名。排行榜旨在对比公开的大模型的幻觉程度,检测 AI 聊天机器人编造事实来填补信息空白的倾向。
Vectara 为了评估大模型在处理摘要任务时的准确性和幻觉率,向各个模型提供了 1000 篇短文档,并要求它们仅使用文档中的事实进行总结。在这些文档中,只有 831 篇被所有模型总结,其余因内容限制被至少一个模型拒绝。Vectara 基于这些文档计算了每个模型的总体准确性和幻觉率,并在“回答率”栏中详细记录了模型拒绝回应的频率。
这项测试专注于摘要的准确性而非整体事实的准确性,因为这允许将模型的响应与原始信息进行比较。由于不可能确切知道每个大模型接受了哪些数据的训练,因此 Vectara 认为任何临时问题都不能用来确定幻觉。此外,随着大模型越来越多地被用于 RAG(检索增强生成)系统中,如 Bing Chat 和 Google 的聊天集成,大模型在其中被用作搜索结果的摘要器。因此,Vectara 认为这个排行榜也是衡量模型在 RAG 系统中使用时准确性的一个好指标。
目前的结果显示,GPT-4 在避免幻觉方面表现最佳,具有最低的幻觉率和最高的准确性。相反,谷歌的 Palm 模型的幻觉率较高,为 27%。此外 Vectara 期待对马斯克发布的 Grok 模型进行次 AI 幻觉评估。但是 Grok 目前以测试版形式发布,其创造者描述它为具有幽默和讽刺性质,但这可以解读为是对其不准确性和相关错误的一种借口。
推进到本月,又有另一款工具 BSChecker 对众多开源大模型进行了幻觉测试。
BSChecker是由亚马逊上海人工智能研究院开发的工具,用于检测和分析如GPT-4生成的文本中的不准确或虚假信息。它通过分解文本为知识三元组(主语、谓词、宾语),实现了细粒度的幻觉检测。不同于传统的真/假二分类,BSChecker将声明分类为蕴涵、矛盾或中性,提高了检测精确度,并有助于自然语言推理。其模块化设计包括声明抽取器、幻觉检测器和聚合规则,具有灵活性和扩展性,适用于不同应用场景。策划预训练语料库:这一策略涉及对训练大模型所用数据进行精心选择和清理。通过排除不可靠或无法验证的数据,训练过程更加专注于高质量、基于事实的信息,从而降低产生幻觉的风险。
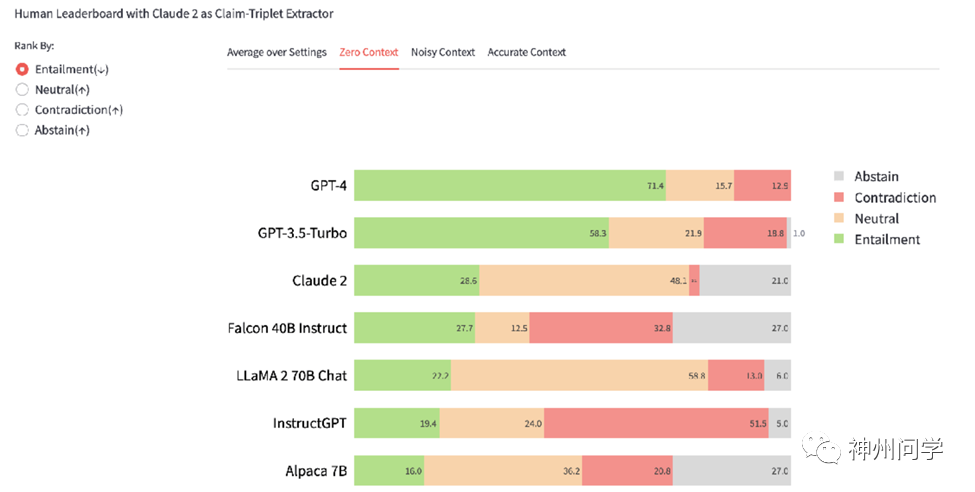
BSChecker目前包含2100个由7个主流大模型(如GPT-4、Claude 2、LLaMA 2等)产生的细粒度人工标注文本。基于这些数据,作者创建了一个交互式排行榜。排行榜包含两个互动选项:1)三种任务场景及其平均结果;2)评估指标。排行榜展示了基于蕴含排名的结果。

根据人工评估,可以看出上下文信息对输出真实文本至关重要。从无上下文到带噪声的上下文,再到准确上下文,矛盾比例从21%降至11%,再降至5%。在真实性方面,最新商业闭源大模型(如Claude 2、GPT-4、GPT-3.5-Turbo)比大多数开源模型更强,特别是在准确上下文场景中,例如GPT-4在这一场景中几乎没有幻觉(0.9%矛盾和1.2%中性)。LLaMA-2-70B的排名接近商业模型,特别是在提供上下文的情况下。
即使对于最新的商业模型,无上下文场景仍具挑战性。GPT-4和Claude 2虽然在很大程度上领先于开源模型,但GPT-4仍有超过10%的错误比例,而Claude 2虽然犯错较少,但经常提供无法验证的输出。
随着谷歌发布了他们的Gemini模型,他们使用BSChecker的自动检测框架对Gemini进行幻觉检测,并以GPT-4作为声明抽取器和幻觉检测器,按照无上下文场景下的矛盾比例排名,得到的结果与Gemini报告一致。他们还对10个输出文本进行了人工标注,包含118个声明三元组,显示自动检测与人工标注的一致性达到90.7%。
如何去减轻大模型出现幻觉现象?
既然大模型会因为数据和模型的质量产生幻觉现象。那么我们也应该对症下药,在数据和模型的方面改善。根据综述中的介绍,我们可以列出以下几点:
● 诚实导向的监督微调:该策略包括将模型的局限性纳入训练数据。它提供了一系列示例,其中模型明确承认自身的局限性或知识匮乏,从而促进更为诚实和可靠的响应模式。
● 基于人类反馈的强化学习(RLHF):RLHF包括训练一个反映人类偏好的奖励模型,并使用它来微调LLM。这种方法使得模型的响应更符合人类的期望,强调有用性、诚实性和无害性等标准。高级模型如GPT-4采用RLHF,包括使用合成幻觉数据进行训练,以提升准确度。
● 改进推理策略:这种方法着重于调整模型的生成策略,如通过调整解码算法,在回应的多样性和事实准确性之间找到平衡。为了提高响应的事实性,已经开发了包括事实核心抽样和验证链(COVE)框架在内的多种策略。
● 利用模型不确定性:这包括识别和标示模型不确定或缺乏相关知识的情况。这可以通过逻辑、口述和一致性等多种不确定性估计方法实现,它们通过标记或纠正高不确定性水平的响应,帮助识别和减轻幻觉。
● 知识检索和事实核查:通过实施模型从可靠来源检索和验证信息的方法,可以显著降低幻觉的发生。这涉及到利用外部知识库、搜索引擎和其他工具,以提供补充证据或纠正错误信息。例如,WebGPT和ReACT等模型就采用了这种方法。
● 其他方法还包括多代理互动(即多个LLM协作以达成共识)、提示工程(设计提示以减少幻觉)、分析LLM内部状态以预测真实性、人在回路系统以细化用户查询,以及优化模型架构以减少幻觉的发生。
这些策略针对LLM的开发和操作的不同方面,从最初的数据准备到实时互动,旨在增强模型的可靠性,减少生成虚假或误导性信息的可能性。
结言
在应对大型模型应用中的幻觉问题方面,一个重要的发展方向是改进模型的设计和训练方法。这包括开发更先进的算法和训练技术,以减少误解和错误,提升语言理解能力、精确的上下文分析,以及有效的错误检测和纠正机制。同时,提高训练数据的质量和多样性也至关重要,以确保数据在文化、语言和地域上的广泛覆盖,并增加少数群体的代表性,这有助于提升模型的准确性和鲁棒性。
另一个重要方向是加强模型的解释性和透明度,以便用户和开发者更好地理解模型的决策过程和潜在偏见。这可能通过可视化技术和改进的模型解释工具实现。同时,确保模型的伦理和责任也变得越来越重要,这包括建立强化的伦理框架和准则,并在设计和部署过程中考虑潜在的社会影响。此外,通过用户反馈和迭代改进,以及跨领域合作,如结合语言学、心理学和社会学的知识,也是应对这些挑战的关键途径。
END
参考材料链接:
GitHub - amazon-science/bschecker
Siren's Song in the AI Ocean
GitHub - vectara/hallucination-leaderboard
*本文部 分图片由AI生成
这篇关于AI误导游戏——LLM的危险幻觉的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








